瘋子C++笔记
瘋耔C++笔记
欢迎关注瘋耔新浪微博:http://weibo.com/cpjphone
参考:C++程序设计(谭浩强)
参考:http://c.biancheng.net/cpp/biancheng/cpp/rumen_8/
博客原文:http://www.cnblogs.com/Ph-one/p/3974707.html
C++主要比C多了继承,多态,模板等特性;
一.C++初步认识
1.C++输入、输出、头文件解释
#include<iostream>
using namespace std ;
int mian()
{
cout << “This is a C++ program”;
return 0;
}
程序运行结果:This is a C++ program
(1)"<<"的作用是将引号中的内容插入到输出的队列cout中(输出队列也称作“输出流”)相当于C语言中的printf。
(2)标准C++规定main函数必须声明为int型。
(3)程序正常执行,则先系统返回数值 0;
(4)文件iostream的作用是向程序提供输入输出时所需要的一些信息。
(5)">>"输入流对象。如(int a,b; cin >> a >> b;第一个输入赋给a,第二个输入赋给b)
(6)cout << “a + b =”<< sum << endl;(“endl:换行,及end line的缩写”)
(7)
#include<iostream>
using namespace std ;
等价于
#include<iostream.h>
2.类
#include<iostream>
using namespace std ;
class Student //声明一个类,类的名字为 Student
{
private: //此名称表示下面为私有部分(只有在该类里面可以使用)
int num; //私有变量num
int score; //私有变量score
public: //一下为类中公用部分
void setdata() //定义公用函数setdata
{
cin >> num; //输入num的值
cin >> score; //输入score的值
}
void display() //定义公用函数dispaly
{
cout << "num = " << num << endl; //输出num的值
cout << "score = " << score << endl; //输出score的值
};
};
//解析:一个类有两部分1.数据2.函数
Student stud1,stud2;
int mian()
{
stud1.setdata(); //调用对象stud1的setdata函数
stud2.setdata();
stud1.display();
stud2.dispaly();
return 0;
}
1.具有“类”类型特征的变量称为“对象”(object)
对象是占实际存储空间的,而类型并不占实际存储空间,它只是给出一种“模型”,供用户定义实际的对象。
2.对于“.”是一个“成员运算符”
3.用于高级语言编写的程序属于“源程序”(source program)。C++的源程序是以.cpp作为后缀的(cpp是 c plus plus的缩写)。
二.数据类型(易遗忘和混淆的)
1.布尔型(bool):逻辑型0、1
2.空类型(void):无值型
3.切记:如果指定为signed,则数值以补码形式存放(高位表示符号位,因此和unsigned相比,正数范围小了一倍)
4.常量:数值型常量和字符常量,两个单撇号之间的为字符常量如:'a','X',从字面形式即可识别的常量称为“字面常量”或“直接常量”。cout << 'a';输出的是一个字母“a”,而不是3个字符“ ‘ a ’ ”;
5.在整形常量后加l或L,则认为是 long int;加f或F,单精度浮点型
6.对于转义字符来讲:cout << i <<' '<< j << '\n'; “ \n ”只占用一个字符
7.cout << c1 << '' << c2 << endl;(加C后可输出字符)
8.一个“ \ ”续行符,这样两者更亲密,如:
cout << "I say \“Thank you!\”\n" 析:!后面的“\”要在引号中
9.常变量:在变量的基础上加上一个限定:存储单元中的值不允许变化,因此常变量又称为只读变量
10.不同类型的整形数据间的赋值归根到底就是一条:按存储单元中的存储形式直接传送
三.C++运算符
1. “.”成员运算符
2.“->”指向成员运算符
3.逻辑常量:false(假)、true(真);洛基变量:bool(他的值只有false、true)
| 控制符 | 作用 |
| dec | 设置数值的基数为10 |
| hex | 设置数值的基数为16 |
| oct | 设置数值的基数为8 |
| setfill(c) | 设置填充字符c,c可以是字符常量或字符变量 |
| setprecision(n) | 设置浮点数的精度为n位。在以一般十进制小数形式输出时,n代表有效数字。在以fixed(固定小数位)形式和scientific(指数)形式输出时,n为小数位数 |
| setw(n) | 设置字段宽度为n位 |
| setiosflags(ios::fixed) | 设置浮点数以固定的小数位显示 |
| setiosflags(ios::scientific) | 设置浮点数以科学计数法(即指数形式)显示 |
| setiosflags(ios::left) | 输出数据左对齐 |
| setiosflags(ios::right) | 输出数据右对齐 |
| setiosflags(ios::skipws) | 忽略前导的空格 |
| setiosflags(ios::uppercase) | 数据以十六进制形式输出时字母以大写表示 |
|
setiosflags(ios::lowercase) |
数据以十六进制形式输出时字母以小写表示 |
| setiosflags(ios::showpos) | 输出正数时给出“+”号 |
举例:
1.对于浮点数
double a = 123.456789012345 对a赋初值
①cout << a; 输出123.456(默认精度为6)
②cout << setprecision(9) << a; 输出123.456789
③cout << setprecision(6); 恢复默认格式(精度为6)
④cout << setiosflags(ios::fixed); 输出123.456789(默认6位小数位)
⑤cout << setiosflags(ios::fixed)<< setprecision(8) << a; 输出123.45678901(8位小数位)
⑥cout << setiosflags(ios::scientific) << a; 输出1.234568e+02(默认小数位6位)
⑦cout << setiosflags(ios::scientific) << setprecision(4) << a; 输出1.2346e02
2.对于整数
int b = 123456;
①cout << b; 输出123456
②cout << hex << b; 输出:1e240(对应的16位数字大小)
③cout << setiosflags(ios::uppercase) << b; 输出:1E240(对应的16位数字大小大写字母)
④cout << setw(10) << b << ',' << b; 输出: ————123456,123456 (和setw(10)紧挨着的第一个前四位留4个空格,后一个没有)
⑤cout << setfill('*') << setw(10) << b; 输出:****123456
⑥cout << setiosflags(ios::showpos) << b; 输出:+123456
总结:
1.单setprecision(x) 精度为x位,默认6位;
2.见setiosflags精度按小数后算,默认也是6位;
一个简单的例子
求一元二次方程式ax2 +bx +c = 0 的跟

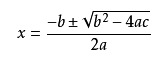
看如下程序:
#include <iostream>
#include <cmath> //等价于#include math.h
using namespace std;
int main()
{
float a,b,c,x1,x2;
cin >> a >> b >> c;
x1 = (-b + sqrt(b*b - 4*a*c))/(2*a);
x1 = (-b - sqrt(b*b - 4*a*c))/(2*a);
cout << "x1 = " << x1 << endl;
cout << "x2 = " << x2 << endl;
return 0;
}
运行结果:
4.5 8.8 2.4(输入)
x1 = -0.327612
x2 = -1.17794
四.与C语言不同的函数
与C语言相比C++不仅有嵌套、递归,还有内置函数、函数的仲裁
1.内置函数:
在函数调用之后,流程返回到先前记下的地址处,并且根据记下的信息“恢复现场”,然后继续执行。这些都需要花费时间。如果有的函数需要频繁使用,则所用时间会很长,从而降低程序的执行效率。
内置函数:在编译时将所调用函数的代码直接敲入到主函数中,而不是将流程转出去。(相当于把子函数里面的语句放到调用函数中,或者说就用max函数体的代码代替“max(i,j,k),同时将实参代替形参”)
#include <iostream>
using namespace std;
inline int max(int,int,int); //声明内置函数,注意左端有inline
int main()
{
int i = 10,j = 20,k = 30,m;
m = max(i,j,k);
cout << "max = " << m <<endl;
return 0;
}
inline int max(int a,int b,int c) //定义max为内置函数
{
if(b > a) a = b; //求a,b,c中的最大者
if(c > a) a = c;
return a;
}
同样在函数声明时加inline,而定义函数时不加inline。
使用内置函数可以节省运行时间,但却增加了目标程序的长度。
因此只将规模很小(一般5句以下)而使用频繁的函数(如定时采集数据的函数)声明为内置函数。
在函数规模很小的情况下,函数调用的时间开销可能相当于甚至超过执行函数本身的时间。
切记:内置函数中不能包括复杂的控制语句,如循环语句和switch语句。当然若不适合用inline,编译系统会忽略inline,而按普通函数处理。
2.函数的重载
定义:
重载函数的参数个数、参数类型、或参数顺序三者中必须至少有一种不同;函数的返回值类型可以相同也可以不同;
举例:
①个数不同:
#include <iostream>
using namespace std;
int max(int,int,int);
int main()
{
int max(int a,int b,int c);
int max(int a,int b);
int a = 8,b = -12,c = 27;
cout << "max (a,b,c) = " << max(a,b,c) <<endl;
cout << "max (a,b) = " << max(a,b) <<endl;
}
int max(int a,int b,int c)
{
if(b > a) a = b; //求a,b,c中的最大者
if(c > a) a = c;
return a;
}
int max(int a,int b) //定义max为内置函数
{
if(a>b) return a;
else return b;
}
运行结果:
max(a,b,c) = 27
max(a/b) = 8
②输入参数类型不同
#include<iostream>
using namespace std; int max(int a,int b)
{
return a>=b?a:b;
} double max(double a,double b)
{
return a>=b?a:b;
}
int main()
{
cout<<"max int is: "<<max(1,3)<<endl;
cout<<"max double is: "<<max(1.2,1.3)<<endl;
return 0;
}
3.函数模板
定义:因为函数的类型(输出)和参数类型(输入)各不相同,为更好的统一,引入函数模板,用一个虚拟的类型来代表;
例子:
#include <iostream>
using namespace std;
template<typename T> //模板声明,其中T为类型参数
T max(T a,T b,T c) //定义一个通用函数,用T作虚拟的类型名
{
if(b>a) a=b;
if(c>a) a=c;
return a;
} int main( )
{
int i1=,i2=-,i3=,i;
double d1=56.87,d2=90.23,d3=-3214.78,d;
long g1=,g2=-,g3=,g;
i=max(i1,i2,i3); //调用模板函数,此时T被int取代
d=max(d1,d2,d3); //调用模板函数,此时T被double取代
g=max(g1,g2,g3); //调用模板函数,此时T被long取代
cout<<"i_max="<<i<<endl;
cout<<"f_max="<<f<<endl;
cout<<"g_max="<<g<<endl;
return ;
}
运行结果:
输入:
185 -76 567
输出:
i_max = 567
-------------------
输入:
56.87 90.23 -3214.78
输出:
d_max = 90.23
-------------------
输入:
67854 -912456 673456
输出:
g_max = 673456
-------------------
定义函数模板的一般形式为:
template < typename T>
通用函数定义
通用函数定义
或(两者等价)
template <class T>(老版)
通用函数定义 通用函数定义
注意:
①类型名:(此处用typename 或class表示类型名,T只是一个符号(Type)可以换成其他的)
②类名 :
类型参数可以不只一个,可以根据需要确定个数。如:
template <class T1, typename
T2>
可以看到,用函数模板比函数重载更方便,程序更简洁。但应注意它只适用于函数的参数个数相同而类型不同,且函数体相同的情况,如果参数的个数不同,则不能用函数模板。
4.有默认参数的函数
函数声明时,填入输入参数
如:
①
float area(float r = 6.5);
调用时候:
area(); //相当于area(float r = 6.5);
②
声明
float volume(float h,float r = 12.5);
调用:
volume(45.6); //相当于volume(float 45.6,float r = 12.5);
③
特别注意
void f1(float a, int b = 0, int c, char d = 'a'); //错误
void f2(float a, int c, int b = 0, char d = 'a'); //正确
实参与形成的结合是从左至右进行的,所以为方便调用,指定默认的参数值必须放在形参列表中的最右端,否则出错。
默认函数定义时,参数赋值自右向左
④
一个函数不能既作重载函数,又作为有默认参数的函数。(编译系统无法区分)
五.特殊的变量声明
register:用register声明的变量不必从内存中读取,它是直接放在CPU中的,这样效率快很多(当然这些变量是及其常用的在运行当中)P117;
六.数组
1)
cout << str; //用字符数组名,输出一个字符串
cout << str[4]; //用数组元素名,输出一个字符
2)C++中提供了一种新的数据类型----------字符串类型(string类型)
如:
string string1; //定义字符串变量
string string2 = “China”;
3)
字符串变量的运算
①复制
string1 = string2;等价于 strcpy(string1,string2);
②相加
string1 = “C++”;
string2 = “Language”;
string1 = string1 + string2;
连接后string1 的内容为“C++ Language”。
③字符串数组
string name[5];
string name[5] = {“Zhang”,“Li”,“Sun”,“Wang”,“Tan”};
④字符串可直接比较大小。
七.类和对象特征
1)
类是对象的抽样(不占空间),对象是类的具体实例(instance)。
2)
如果在类的定义中即不指定private,也不指定public,则系统就默认为是私有的。
比如:
int 是个类型
int a;
a是个对象;(可能不恰当,但好理解)
class student
{
......
};
student stud1,stud2;
student(类型)相当于int;
stud1(对象)相当于 a;
3)在C++中可以用struct来声明一个类,和class声明的类所不同的是如果对其成员不作private或public的声明,
struct:系统将其默认为public(公用的)。 (当然在C语言中,结构体中没有见有函数的,类中却可以有函数)class :系统将其默认为private()。
4) 外置
在类外定义类当中成员函数
如:
class Student
{
public:
void display();
//inline void display();
private:
int num;
string name;
char sex;
};
void Student::display()
//inline void Student::display()
{
cout << "num = " << num << endl; //输出num的值
cout << "score = " << score << endl; //输出score的值
}
student stud1,stud2;
解释:
“::”是作用域限定符(field qualifier)或称 作用域运算符,用它声明函数属于哪个类中的,
Student::display()表示Student类中的display函数。说白了就是限定这个display函数是Student类中的。
5)内置
在类中的public中
void display();
//inline void display();
两者等效;
若在外声明inline void Student::display()
则需要类内部也写成显性;
并且类定义和成员函数的定义 放在同一个头文件中(或者同一个源文件中);
6)成员函数的存储方式
成员函数没有放在对象的存储空间中,但从逻辑的角度,成员函数是和数据一起封装在一个对象中的,只允许本对象中成员的函数访问同一对象中的私有数据。
7)类成员的引用
如:
stud1.num = 1001;
指针法:
stud1 t,*p;
p = &t;
cout << p -> hour;
8)三个名词:对象,方法(method),消息(message)
如:
stud1.display();是一个消息;
stud1 是对象;display()是方法(必须是对外的,公用的)。
八.对象的使用
1)对象的初始化
class Time
{
hour = ;
minute = ;
sec = ;
};
在类声明中对数据成员初始化是错误的!
class Time
{
hour ;
minute ;
sec ;
};
Time t1 = {,,};
这是正确的
2)构造函数实现数据成员的初始化
(法1)
#include<iostream>
using namespace std ; class Time //声明一个类,类的名字为 Student {
private: //此名称表示下面为私有部分(只有在该类里面可以使用)
int hour;
int minute;
int sec;
public: //一下为类中公用部分
Time()
{
hour = 0;
minute = 0;
sec = 0;
}
void set_time();
void show_time();
}; void Time::set_show()
{
cin >> hour;
cin >> minute;
cin >> sec;
} void Time::show_time()
{
cout << hour << ":" << minute << ":" << sec << endl;
} int mian() {
Time t1; //建立对象t1,同时调用构造函数t1.Time()
t1.set_time();
t1.show_time();
Time t2;
t2.show_time();
return ;
}
(法2)
#include<iostream>
using namespace std ; class Time //声明一个类,类的名字为 Student {
private: //此名称表示下面为私有部分(只有在该类里面可以使用)
int hour;
int minute;
int sec; public: //一下为类中公用部分
Time();
void set_time();
void show_time();
};
Time::Time()
{
hour = 0;
minute = 0;
sec = 0;
}
void Time::set_show()
{
cin >> hour;
cin >> minute;
cin >> sec;
} void Time::show_time()
{
cout << hour << ":" << minute << ":" << sec << endl;
} int mian() {
Time t1; //建立对象t1,同时调用构造函数t1.Time()
t1.set_time();
t1.show_time();
Time t2;
t2.show_time();
return ;
}
在类中定义了构造函数Time,它和所在的类同名。在建立对象时自动执行构造函数,赋值语句是写在构造函数的函数体中的,只有在调用构造函数时才执行这些赋值语句。
输入,输出如下:
10 25 54 (输入)
10:25:54(输出)
0:0:0
构造函数理解:
①建立对象时系统为该对象分配存储单元,此时执行构造函数,每建立一个对象,就调用一次构造函数。
②构造函数没有返回值,因此也没有类型,它的作用只是对 对象进行初始化。
不能写成:
int Time()
{......}
或
void Time()
{......}
③构造函数不需用户调用,也不能被用户调用。
t1.Time(); 错误
④可以用一个类对象初始化另一个类对象。
如:
Time t1; //建立对象t1,同时调用构造函数t1.Time()
Time t2 = t1; //建立对象t2,并用一个t1初始化t2
此时,把t1的各数据成员的值复制到t2相应各成员,而不调用构造函数t2.Time()。
⑤在构造函数内部不仅可以对数据成员赋初值(说白了内部怎么用和平常的函数每什么两样,只是函数类型是无类型)可以包含其他语句,例如cout语句。但一般不提倡在构造函数中加入其他与初始化无关的内容,以保持程序的清晰。
⑥如果用户自己没有定义构造函数,则C++系统会自动生成一个构造函数,只是这个构造函数的函数体是空的,也没有参数,不执行初始化操作。
3)带参数的构造函数
#include <iostream>
using namespace std;
class Box
{
public :
Box(int,int,int);
int volume( );
private :
int height;
int width;
int length;
};
//声明带参数的构造函数//声明计算体积的函数
Box::Box(int h,int w,int len) //在类外定义带参数的构造函数
{
height=h;
width=w;
length=len;
}
//Box::Box(int h,int w,int len):height(h),width(w), length(len){ } //或者用这个方法也可以
int Box::volume( ) //定义计算体积的函数
{
return (height*width*length);
}
int main( )
{
Box box1(12,25,30); //建立对象box1,并指定box1长、宽、高的值
cout<<"The volume of box1 is "<<box1.volume( )<<endl;
Box box2(,,); //建立对象box2,并指定box2长、宽、高的值
cout<<"The volume of box2 is "<<box2.volume( )<<endl;
return ;
}
程序运行结果如下:
The volume of box1 is 9000
The volume of box2 is
9450
可以知道:
- 带参数的构造函数中的形参,其对应的实参在定义对象时给定。
- 用这种方法可以方便地实现对不同的对象进行不同的初始化。
用参数初始化表对数据成员初始化
上面介绍的是在构造函数的函数体内通过赋值语句对数据成员实现初始化。C++还提供另一种初始化数据成员的方法——参数初始化表来实现对数据成员的初始化。这种方法不在函数体内对数据成员初始化,而是在函数首部实现。
例9.2中定义构造函数可以改用以下形式:
Box::Box(int h,int w,int len):height(h),width(w), length(len){
}
这种写法方便、简练,尤其当需要初始化的数据成员较多时更显其优越性。甚至可以直接在类体中(而不是在类外)定义构造函数。
4)构造函数的重载
#include <iostream>
using namespace std;
class Box
{
public :
Box( ); //声明一个无参的构造函数
//声明一个有参的构造函数,用参数的初始化表对数据成员初始化
Box(int h,int w,int len):height(h),width(w),length(len){ }
int volume( );
private :
int height;
int width;
int length;
};
Box::Box( ) //定义一个无参的构造函数
{
height=; width=; length=;
}
int Box::volume( ){
return (height*width*length);
}
int main( )
{
Box box1; //建立对象box1,不指定实参
cout<<"The volume of box1 is "<<box1.volume( )<<endl;
Box box2(,,); //建立对象box2,指定3个实参
cout<<"The volume of box2 is "<<box2.volume( )<<endl;
return ;
}
第一次输出 10 10 10
第二次输出 15 30 25
关于构造函数的重载的几点说明:
- 调用构造函数时不必给出实参的构造函数,称为默认构造函数(default constructor)。显然,无参的构造函数属于默认构造函数。一个类只能有一个默认构造函数。
- 如果在建立对象时选用的是无参构造函数,应注意正确书写定义对象的语句。
- 尽管在一个类中可以包含多个构造函数,但是对于每一个对象来说,建立对象时只执行其中一个构造函数,并非每个构造函数都被执行。
5)构造函数有默认参数
#include <iostream>
using namespace std;
class Box
{
public :
Box(int h=,int w=,int len=); //在声明构造函数时指定默认参数
int volume( );
private :
int height;
int width;
int length;
};
Box::Box(int h,int w,int len) //在定义函数时可以不指定默认参数
{
height=h;
width=w;
length=len;
}
int Box::volume( )
{
return (height*width*length);
}
int main( )
{
Box box1; //没有给实参
cout<<"The volume of box1 is "<<box1.volume( )<<endl;
Box box2(); //只给定一个实参 这样对二个,第三个参数还是 10 ;
cout<<"The volume of box2 is "<<box2.volume( )<<endl;
Box box3(,); //只给定2个实参
cout<<"The volume of box3 is "<<box3.volume( )<<endl;
Box box4(,,); //给定3个实参
cout<<"The volume of box4 is "<<box4.volume( )<<endl;
return ;
}
程序运行结果为:
The volume of box1 is 1000
The volume of box2 is 1500
The volume of box3 is 4500
The volume of box4 is 9000
程序中对构造函数的定义(第12-16行)也可以改写成参数初始化表的形式:
Box::Box(int h,int w,int len):height(h),width(w),length(len){ }
6)析构函数
创建对象时系统会自动调用构造函数进行初始化工作,同样,销毁对象时系统也会自动调用一个函数来进行清理工作(例如回收创建对象时消耗的各种资源),这个函数被称为析构函数。
析构函数(Destructor)也是一种特殊的成员函数,没有返回值,不需要用户调用,而是在销毁对象时自动执行。与构造函数不同的是,析构函数的名字是在类名前面加一个”~“符号。
注意:析构函数没有参数,不能被重载,因此一个类只能有一个析构函数。如果用户没有定义,那么编译器会自动生成。
析构函数举例:
#include <iostream>
using namespace std; class Student{
private:
char *name;
int age;
float score; public:
//构造函数
Student(char *, int, float);
//析构函数
~Student();
//普通成员函数
void say();
}; Student::Student(char *name1, int age1, float score1):name(name1), age(age1), score(score1){}
Student::~Student(){
cout<<name<<"再见"<<endl;
}
void Student::say(){
cout<<name<<"的年龄是 "<<age<<",成绩是 "<<score<<endl;
} int main(){
Student stu1("小明", , 90.5f);
stu1.say(); Student stu2("李磊", , );
stu2.say(); Student stu3("王爽", , 80.5f);
stu3.say(); cout<<"main 函数即将运行结束"<<endl; return ;
}
运行结果:
小明的年龄是 15,成绩是 90.5
李磊的年龄是 16,成绩是 95
王爽的年龄是 16,成绩是 80.5
main 函数即将运行结束
王爽再见
李磊再见
小明再见
可以看出,析构函数在 main 函数运行结束前被执行,并且调用顺序和构造函数正好相反,为了方便记忆,我们可以将之理解为一个栈,先入后出。
析构函数在对象被销毁前执行;要知道析构函数什么时候被调用,就要先知道对象什么时候被销毁。
对象可以认为是通过类这种数据类型定义的变量,它的很多特性和普通变量是一样的,例如作用域、生命周期等。由此可以推断,对象这种变量的销毁时机和普通变量是一样的。
析构函数的执行顺序
上面的例子中,我们依次创建了3个对象,分别是 stu1、stu2、stu3,但它们对应的析构函数的执行顺序却是相反的,这是为什么呢?
要搞清楚这个问题,首先要明白C++内存模型,也就是C++的代码和数据在内存中是如何存储的。C++内存模型和C语言相似(有部分细节不同),你可以参照C语言内存模型来理解。
在内存模型中有一块区域叫做栈区,它是由系统维护的(程序员无法操作),用来存储函数的参数、局部变量等,类似于数据结构中的栈,也是先进后出。
当遇到函数调用时,首先将下一条指令的地址压入栈区,然后将函数参数压入栈区,随着函数的执行,再将局部变量(或对象)按顺序压入栈区。栈区是先进后出的结构,当函数执行结束后,先把最后压入的变量(或对象)弹出,以此类推,最后把第一个压入的变量弹出。接下来,再按照先进后出的规则弹出函数参数,弹出下一条指令地址。有了下一条指令的地址,函数调用结束后才能够继续执行后面的代码。
所谓弹出变量,就是销毁变量,清空变量所占用的资源。如果这个变量是一个对象,那么就会执行析构函数。
上面的例子中,三个对象入栈的顺序依次是 stu1、stu2、stu3,出栈(销毁)的顺序依次是 stu3、stu2、stu1,它们对应的析构函数的执行顺序也就一目了然了。
总结起来,有下面几种情况:
1) 如果在一个函数中定义了一个对象(auto 局部变量),当这个函数运行结束时,对象就会被销毁,在对象被销毁前自动执行析构函数。
2) static 局部对象在函数调用结束时并不销毁,因此也不调用析构函数,只有在程序结束时(如 main 函数结束或调用 exit 函数)才调用 static 局部对象的析构函数。
3) 如果定义了一个全局对象,也只有在程序结束时才会调用该全局对象的析构函数。
4) 如果用 new 运算符动态地建立了一个对象,当用 delete 运算符释放该对象时,先调用该对象的析构函数。
如果你对 auto、static、extern 等关键字不理解,请猛击:C语言动态内存分配及变量存储类别
注意:析构函数的作用并不是删除对象,而是在撤销对象占用的内存之前完成一些清理工作,使这部分内存可以分配给新对象使用。
7)调用构造函数和析构造函数的顺序
在使用构造函数和析构函数时,需要特别注意对它们的调用时间和调用顺序。在一般情况下,调用析构函数的次序正好与调用构造函数的次序相反:最先被调用的构造函数,其对应的(同一对象中的)析构函数最后被调用,而最后被调用的构造函数,其对应的析构函数最先被调用。
可以简记为:先构造的后析构,后构造的先析构,它相当于一个栈,先进后出。
但是,并不是在任何情况下都是按这一原则处理的。我们已经介绍过作用域(请查看:C++局部变量和全局变量)和存储类别(请查看:C++变量的存储类别)的概念,这些概念对于对象也是适用的。对象可以在不同的作用域中定义,可以有不同的存储类别。这些会影响调用构造函数和析构函数的时机。
下面归纳一下什么时候调用构造函数和析构函数:
1) 在全局范围中定义的对象(即在所有函数之外定义的对象),它的构造函数在文件中的所有函数(包括main函数)执行之前调用。但如果一个程序中有多个文件,而不同的文件中都定义了全局对象,则这些对象的构造函数的执行顺序是不确定的。当main函数执行完毕或调用exit函数时(此时程序终止),调用析构函数。
2) 如果定义的是局部自动对象(例如在函数中定义对象),则在建立对象时调用其构造函数。如果函数被多次调用,则在每次建立对象时都要调用构造函数。在函数调用结束、对象释放时先调用析构函数。
3) 如果在函数中定义静态(static )局部对象,则只在程序第一次调用此函数建立对象时调用构造函数一次,在调用结束时对象并不释放,因此也不调用析构函数,只在main函数结束或调用exit函数结束程序时,才调用析构函数。
例如,在一个函数中定义了两个对象:
void fn(){
Student stud1; //定义自动局部对象
static Student stud2; //定义静态局部对象
}
在调用fn函数时,先调用stud1的构造函数,再调用stud2的构造函数,在fn调用结束时,stud1是要释放的(因为它是自动局部对象),因此调用stud1的析构函数。而stud2 是静态局部对象,在fn调用结束时并不释放,因此不调用stud2的析构函数。直到程序结束释放stud2时,才调用stud2的析构函数。可以看到stud2是后调用构造函数的,但并不先调用其析构函数。原因是两个对象的存储类别不同、生命周期不同。
(说白了还是根据变量的作用域,存储方式来决定先释放谁,当然总的逻辑是 先入后出)
8)对象数组
如果构造函数有3个参数,分别代表学号、年龄、成绩。则可以这样定义对象数组:
Student Stud[]={ //定义对象数组
Student(,,), //调用第1个元素的构造函数,为它提供3个实参
Student(,,), //调用第2个元素的构造函数,为它提供3个实参
Student(,,) //调用第3个元素的构造函数,为它提供3个实参
};
在建立对象数组时,分别调用构造函数,对每个元素初始化。每一个元素的实参分别用括号包起来,对应构造函数的一组形参,不会混淆。
[例9.6] 对象数组的使用方法。
#include <iostream>
using namespace std;
class Box
{
public :
//声明有默认参数的构造函数,用参数初始化表对数据成员初始化
Box(int h=,int w=,int len=): height(h),width(w),length(len){ }
int volume( );
private :
int height;
int width;
int length;
};
int Box::volume( )
{
return (height*width*length);
}
int main( )
{
Box a[]={ //定义对象数组
Box(,,), //调用构造函数Box,提供第1个元素的实参
Box(,,), //调用构造函数Box,提供第2个元素的实参
Box(,,) //调用构造函数Box,提供第3个元素的实参
};
cout<<"volume of a[0] is "<<a[].volume( )<<endl;
cout<<"volume of a[1] is "<<a[].volume( )<<endl;
cout<<"volume of a[2] is "<<a[].volume( )<<endl;
return ;
}
运行结果如下:
volume of a[0] is 1800
volume of a[1] is 5400
volume of a[2] is 8320
9)对象指针
指向对象的指针
在建立对象时,编译系统会为每一个对象分配一定的存储空间,以存放其成员。对象空间的起始地址就是对象的指针。可以定义一个指针变量,用来存放对象的指针。
class Time
{
public :
int hour;
int minute;
int sec;
void get_time( );
};
void Time::get_time( )
{
cout<<hour<<":"<<minute<<":"<<sec<<endl;
}
在此基础上有以下语句:
Time *pt; //定义pt为指向Time类对象的指针变量
Time t1; //定义t1为Time类对象
pt=&t1; //将t1的起始地址赋给pt
这样,pt就是指向Time类对象的指针变量,它指向对象t1。
定义指向类对象的指针变量的一般形式为:
类名 *对象指针名;
可以通过对象指针访问对象和对象的成员。如:
*pt //pt所指向的对象,即t1
(*pt).hour //pt所指向的对象中的hour成员,即t1.hour
pt->hour //pt所指向的对象中的hour成员,即t1.hour
(*pt).get_time ( ) //调用pt所指向的对象中的get_time函数,即t1.get_time
pt->get_time ( ) //调用pt所指向的对象中的get_time函数,即t1.get_time
上面第2, 3行的作用是等价的,第4, 5两行也是等价的。
指向对象成员的指针
对象有地址,存放对象初始地址的指针变量就是指向对象的指针变量。对象中的成员也有地址,存放对象成员地址的指针变量就是指向对象成员的指针变量。
1) 指向对象数据成员的指针
定义指向对象数据成员的指针变量的方法和定义指向普通变量的指针变量方法相同。例如:
int *p1; //定义指向整型数据的指针变量
定义指向对象数据成员的指针变量的一般形式为:
数据类型名 *指针变量名;
如果Time类的数据成员hour为公用的整型数据,则可以在类外通过指向对象数据成员的指针变量访问对象数据成员hour:
p1=&t1.hour; //将对象t1的数据成员hour的地址赋给p1,p1指向t1.hour
cout<<*p1<<endl; //输出t1.hour的值
2) 指向对象成员函数的指针
需要提醒读者注意: 定义指向对象成员函数的指针变量的方法和定义指向普通函数的指针变量方法有所不同。这里重温一个指向普通函数的指针变量的定义方法:
数据类型名 (*指针变量名) (参数表列);
如
void ( *p)( ); //p是指向void型函数的指针变量
可以使它指向一个函数,并通过指针变量调用函数:
p = fun; //将fun函数的人口地址传给指针变童p,p就指向了函数fn
(*P)( ); //调用fn函数
而定义一个指向对象成员函数的指针变量则比较复杂一些。如果模仿上面的方法将对象成员函数名赋给指针变最P:
p = t1.get_time;
则会出现编译错误。为什么呢?
成员函数与普通函数有一个最根本的区别: 它是类中的一个成员。编译系统要求在上面的赋值语句中,指针变量的类型必须与赋值号右侧函数的类型相匹配,要求在以下3方面都要匹配:
①函数参数的类型和参数个数;
②函数返回值的类型;
③所属的类。
现在3点中第①②两点是匹配的,而第③点不匹配。指针变量p与类无关,面get_ time函数却属于Time类。因此,要区别普通函数和成员函数的不同性质,不能在类外直接用成员函数名作为函数入口地址去调用成员函数。
那么,应该怎样定义指向成员函数的指针变量呢?应该采用下面的形式:
void (Time::*p2)( ); //定义p2为指向Time类中公用成员函数的指针变量
注意:(Time:: *p2) 两侧的括号不能省略,因为()的优先级高于*。如果无此括号,就相当于:
void Time::*(p2()) //这是返回值为void型指针的函数
定义指向公用成员函数的指针变量的一般形式为:
数据类型名 (类名::*指针变量名)(参数表列);
可以让它指向一个公用成员函数,只需把公用成员函数的入口地址赋给一个指向公用成员函数的指针变量即可。如:
p2=&Time::get_time;
使指针变量指向一个公用成员函数的一般形式为
指针变量名=&类名::成员函数名;
在VC++系统中,也可以不写&,以和C语言的用法一致,但建议在写C++程序时不要省略&。
[例9.7]有关对象指针的使用方法。
#include <iostream>
using namespace std;
class Time
{
public:
Time(int,int,int);
int hour;
int minute;
int sec;
void get_time( );
};
Time::Time(int h,int m,int s)
{
hour=h;
minute=m;
sec=s;
}
void Time::get_time( ) //声明公有成员函数
//定义公有成员函数
{
cout<<hour<<":"<<minute<<":" <<sec<<endl;
}
int main( )
{
Time t1(,,); //定义Time类对象t1
int *p1=&t1.hour; //定义指向整型数据的指针变量p1,并使p1指向t1.hour
cout<<* p1<<endl; //输出p1所指的数据成员t1.hour
t1.get_time( ); //调用对象t1的成员函数get_time
Time *p2=&t1; //定义指向Time类对象的指针变量p2,并使p2指向t1
p2->get_time( ); //调用p2所指向对象(即t1)的get_time函数
void (Time::*p3)( ); //定义指向Time类公用成员函数的指针变量p3
p3=&Time::get_time; //使p3指向Time类公用成员函数get_time
(t1.*p3)( ); //调用对象t1中p3所指的成员函数(即t1.get_time( ))
return ;
}
程序运行结果为:
10 (main函数第4行的输出)
10:13:56 (main函数第5行的输出)
10:13:56 (main函数第7行的输出)
10:13:56 (main函数第10行的输出)
可以看到为了输出t1中hour,minute和sec的值,可以采用3种不同的方法。
几点说明:
1) 从main函数第9行可以看出,成员函数的入口地址的正确写法是:
&类名::成员函数名
不应该写成:
p3 =&t1.get_time; //t1为对象名
成员函数不是存放在对象的空间中的,而是存放在对象外的空间中的。如果有多个同类的对象,它们共用同一个函数代码段。因此赋给指针变量p3的应是这个公用的函数代码段的入口地址。
调用t1的get_time函数可以用t1.get_time()形式,那是从逻辑的角度而言的,通过对象名能调用成员函数。而现在程序语句中需要的是地址,它是物理的,具体地址是和类而不是对象相联系的。
2) main函数第8, 9两行可以合写为一行:
void (Time::*p3)( )=&Time::get_time; //定义指针变量时指定其指向
10)this指针详解
this 是C++中的一个关键字,也是一个常量指针,指向当前对象(具体说是当前对象的首地址,使用中不是指针变量,它就是一个地址)。通过 this,可以访问当前对象的成员变量和成员函数。
所谓当前对象,就是正在使用的对象,例如对于
stu.say();,stu 就是当前对象,系统正在通过 stu 访问成员函数 say()。
下面的语句中,this 就和 pStu 的值相同:
Student stu; //通过Student类来创建对象
Student *pStu = &stu;
[示例] 通过 this 来访问成员变量:
class Student{
private:
char *name;
int age;
float score;
public:
void setname(char *);
void setage(int);
void setscore(float);
};
void Student::setname(char *name){
this->name = name;
}
void Student::setage(int age){
this->age = age;
}
void Student::setscore(float score){
this->score = score;
}
本例中,函数参数和成员变量重名是没有问题的,因为通过 this 访问的是成员变量,而没有 this 的变量是函数内部的局部变量。例如对于this->name = name;语句,赋值号左边是类的成员变量,右边是 setname 函数的局部变量,也就是参数。
下面是一个完整的例子:
#include <iostream>
using namespace std; class Student{
private:
char *name;
int age;
float score; public:
void setname(char *);
void setage(int);
void setscore(float);
void say();
}; void Student::setname(char *name){
this->name = name;
}
void Student::setage(int age){
this->age = age;
}
void Student::setscore(float score){
this->score = score;
}
void Student::say(){
cout<<this->name<<"的年龄是 "<<this->age<<",成绩是 "<<this->score<<endl;
} int main(){
Student stu1;
stu1.setname("小明");
stu1.setage();
stu1.setscore(90.5f);
stu1.say(); Student stu2;
stu2.setname("李磊");
stu2.setage();
stu2.setscore();
stu2.say(); return ;
}
运行结果:
小明的年龄是 15,成绩是 90.5
李磊的年龄是 16,成绩是 80
对象和普通变量类似;每个对象都占用若干字节的内存,用来保存成员变量的值,而且不同对象占用的内存互不重叠,所以操作对象A不会影响对象B。
上例中,创建对象 stu1 时,this 指针就指向了 stu1 所在内存的首字节,它的值和 &stu1 是相同的;创建对象 stu2 时,也是一样的。
我们不妨来证明一下,给 Student 类添加一个成员函数,输出 this 的值,如下所示:
void Student::printThis(){
cout<<this<<endl; //this就是该对象的首地址
}
然后在 main 函数中创建对象并调用 printThis:
Student stu1, *pStu1 = &stu1;
stu1.printThis();
cout<<pStu1<<endl; Student stu2, *pStu2 = &stu2;
stu2.printThis();
cout<<pStu2<<endl;
运行结果:
0x28ff30
0x28ff30
0x28ff10
0x28ff10
可以发现,this 确实指向了当前对象的首地址,而且对于不同的对象,this 的值也不一样。
几点注意:
- this 是常量指针,它的值是不能被修改的,一切企图修改该指针的操作,如赋值、递增、递减等都是不允许的。
- this 只能在成员函数内部使用,其他地方没有意义,也是非法的。
- 只有当对象被创建后 this 才有意义,因此不能在 static 成员函数中使用,后续会讲到。
this 到底是什么
实际上,this 指针是作为函数的参数隐式传递的。也就是说,this 并不出现在参数列表中,调用成员函数时,系统自动获取当前对象的地址,赋值给 this,完成参数的传递,无需用户干预。
this 只是隐式参数,不在对象的内存空间中,创建对象时也不为 this 分配内存,只有在发生成员函数调用时才会给 this 赋值,函数调用结束后,this 被销毁。
正因为 this 是参数,表示对象首地址,所以只能在函数内部使用,并且对象被实例化以后才有意义。
11)常对象(const的对象,相当于枚举)
C++虽然采取了不少有效的措施(如设private保护)以增加数据的安全性,但是有些数据却往往是共享的,人们可以在不同的场合通过不同的途径访问同一个数据对象。有时在无意之中的误操作会改变有关数据的状况,而这是人们所不希望出现的。
既要使数据能在一定范围内共享,又要保证它不被任意修改,这时可以使用const,即把有关的数据定义为常量。
常对象
在定义对象时指定对象为常对象。常对象必须要有初值,如:
Time const t1(12,34,46); //t1是常对象
这样,在所有的场合中,对象t1中的所有成员的值都不能被修改。凡希望保证数据成员不被改变的对象,可以声明为常对象。
定义常对象的一般形式为:
类名 const 对象名[(实参表列)];
也可以把const写在最左面:
const 类名 对象名[(实参表列)];
二者等价。
如果一个对象被声明为常对象,则不能调用该对象的非const型的成员函数(除了由系统自动调用的隐式的构造函数和析构函数)。例如,对于例9.7中已定义的Time类,如果有
const Time t1(10,15,36); //定义常对象t1
t1.get_time( ); //企图调用常对象t1中的非const型成员函数,非法
这是为了防止这些函数会修改常对象中数据成员的值。
不能仅依靠编程者的细心来保证程序不出错,编译系统充分考虑到可能出现的情况,对不安全的因素予以拦截。现在,编译系统只检查函数的声明,只要发现调用了常对象的成员函数,而且该函数未被声明为const,就报错,提请编程者注意。
引用常对象中的数据成员很简单,只需将该成员函数声明为const即可。如:
void get_time( ) const ; //将函数声明为const
这表示get_time是一个const型函数,即常成员函数。
常成员函数可以访问常对象中的数据成员,但仍然不允许修改常对象中数据成员的值。有时在编程时有要求,一定要修改常对象中的某个数据成员的值,ANSI C++考虑到实际编程时的需要,对此作了特殊的处理,对该数据成员声明为mutable,如:
mutable int count; (常对象中的变量用 mutable 声明)
把count声明为可变的数据成员,这样就可以用声明为const的成员函数来修改它的值。
常对象成员
可以将对象的成员声明为const,包括常数据成员和常成员函数。
1) 常数据成员
其作用和用法与一般常变量相似,用关键字const来声明常数据成员。常数据成员的值是不能改变的。
有一点要注意: 只能通过构造函数的参数初始化表对常数据成员进行初始化。如在类体中定义了常数据成员hour:
const int hour; //声明hour为常数据成员
不能采用在构造函数中对常数据成员赋初值的方法,下面的做法是非法的:
Time::Time(int h){
hour=h;
} // 非法
因为常数据成员是不能被赋值的。
在类外定义构造函数,应写成以下形式:
Time::Time(int h):hour(h){} //通过参数初始化表对常数据成员hour初始化
常对象的数据成员都是常数据成员,因此常对象的构造函数只能用参数初始化表对常数据成员进行初始化。
2) 常成员函数
前面已提到,一般的成员函数可以引用本类中的非const数据成员,也可以修改它们。如果将成员函数声明为常成员函数,则只能引用本类中的数据成员,而不能修改它们,例如只用于输出数据等。如
void get_time( ) const ; //注意const的位置在函数名和括号之后
const是函数类型的一部分,在声明函数和定义函数时都要有const关键字,在调用时不必加const。常成员函数可以引用const数据成员,也可以引用非const的数据成员。const数据成员可以被const成员函数引用,也可以被非const的成员函数引用。具体情况可以用表9.1表示。
| 数据成员 | 非const成员函数 | const成员函数 |
|---|---|---|
| 非const的数据成员 | 可以引用,也可以改变值 | 可以引用,但不可以改变值 |
| const数据成员 | 可以引用,但不可以改变值 | 可以引用,但不可以改变值 |
| const对象的数据成员 | 不允许 | 可以引用,但不可以改变值 |
那么怎样利用常成员函数呢?
- 如果在一个类中,有些数据成员的值允许改变,另一些数据成员的值不允许改变,则可以将一部分数据成员声明为const,以保证其值不被改变,可以用非const的成员函数引用这些数据成员的值,并修改非const数据成员的值。
- 如果要求所有的数据成员的值都不允许改变,则可以将所有的数据成员声明为const,或将对象声明为const(常对象),然后用const成员函数引用数据成员,这样起到“双保险”的作用,切实保证
- 如果已定义了一个常对象,只能调用其中的const成员函数,而不能调用非const成员函数(不论这些函数是否会修改对象中的数据)。这是为了保证数据的安全。如果需要访问对象中的数据成员,可将常对象中所有成员函数都声明为const成员函数,但应确保在函数中不修改对象中的数据成员。
不要误认为常对象中的成员函数都是常成员函数。常对象只保证其数据成员是常数据成员,其值不被修改。如果在常对象中的成员函数未加const声明,编译系统把它作为非const成员函数处理。
还有一点要指出,常成员函数不能调用另一个非const成员函数。
12)指向对象的常指针
将指针变量声明为const型,这样指针值始终保持为其初值,不能改变。(说白就是一个不变的地址)
如:
Time t1(10,12,15),t2; //定义对象
Time * const ptr1; //const位置在指针变量名前面,规定ptr1的值是常值
ptr1=&t1; //ptr1指向对象t1,此后不能再改变指向 (只能赋值一次,之后不变,这其实并不符合逻辑)
ptr1=&t2; //错误,ptr1不能改变指向
定义指向对象的常指针的一般形式为:
类名 * const 指针变量名;
也可以在定义指针变量时使之初始化,如将上面第2, 3行合并为:
Time * const ptr1=&t1; //指定ptr1指向t1
请注意,指向对象的常指针变量的值不能改变,即始终指向同一个对象,但可以改变其所指向对象(如t1)的值。
什么时候需要用指向对象的常指针呢?如果想将一个指针变量固定地与一个对象相联系(即该指针变量始终指向一个对象),可以将它指定为const型指针变量,这样可以防止误操作,增加安全性。
往往用常指针作为函数的形参,目的是不允许在函数执行过程中改变指针变量的值, 使其始终指向原来的对象。如果在函数执行过程中修改了该形参的值,编译系统就会发现错误,给出出错信息,这样比用人工来保证形参值不被修改更可靠。
13)指向常对象的指针变量(说白了就是 对象内容不变,指向他的指针可变可不变,下表也说明这点)
const char *ptr;
注意const的位置在最左侧,它与类型名char紧连,表示指针变量ptr指向的char变量是常变量,不能通过ptr来改变其值的。
定义指向常变量的指针变量的一般形式为:
const 类型名 *指针变量名;
几点说明:
1) 如果一个变量已被声明为常变量,只能用指向常变量的指针变量指向它,(这一点是不是有点扯淡啊?)而不能用一般的(指向非const型变量的)指针变量去指向它。如:
const char c[] ="boy"; //定义 const 型的 char 数组
const char * pi; //定义pi为指向const型的char变量的指针变量
pi =c; //合法,pi指向常变量(char数组的首元素)
char *p2=c; //不合法,p2不是指向常变量的指针变量
2) 指向常变量的指针变量除了可以指向常变量外,还可以指 向未被声明为const的变量。此时不能通过此指针变量改变该变量的值。如:
char cl ='a'; //定义字符变量cl,它并未声明为const
const char *p; //定义了一个指向常变量的指针变量p
p = &cl; //使p指向字符变量cl
*p = 'b'; //非法,不能通过p改变变量cl的值
cl = 'b'; //合法,没有通过p访问cl,cl不是常变量
3) 如果函数的形参是指向非const型变量的指针,实参只能用指向非const变量的指针,而不能用指向const变量的指针,这样,在执行函数的过程中可以改变形参指针变量所指向的变量(也就是实参指针所指向的变量)的值。
(上述三条说白了就是,常指针(const)和变指针绝对空间不一样)
如果函数的形参是指向const型变量的指针,在执行函数过程中显然不能改变指针变量所指向的变量的值,因此允许实参是指向const变量的指针,或指向非const变量的指针。如:
const char str[ ] = "boy"; //str 是 const 型数组名
void fun( char * ptr) ; //函数fun的形参是指向非const型变量的指针
fun(str); //调用fun函数,实参是const变量的地址,非法
因为形参是指向非const型变量的指针变量,按理说,在执行函数过程中它所指向的变量的值是可以改变的。但是形参指针和实参指针指向的是同一变量,而实参是const 变量的地址,它指向的变量的值是不可改变的。这就发生矛盾。因此C++要求实参用非const变量的地址(或指向非const变量的指针变量)。
| 形参 | 实参 | 合法否 | 改变指针所指向的变量的值 |
|---|---|---|---|
| 指向非const型变量的指针 | 非const变量的地址 | 合法 | 可以 |
| 指向非const型变量的指针 | const变量的地址 | 非法 | / |
| 指向const型变量的指针 | const变量的地址 | 合法 | 不可以 |
| 指向const型变量的指针 | 非const变量的地址 | 合法 | 不可以 |
上表的对应关系与在(2)中所介绍的指针变量和其所指向的变量的关系是一致的: 指向常变量的指针变量可以指向const和非const型的变量,而指向非const型变量的指针变量只能指向非const的变量。
以上介绍的是指向常变量的指针变量,指向常对象的指针变量的概念和使用是与此类似的,只要将“变量”换成“对象”即可。
1) 如果一个对象已被声明为常对象,只能用指向常对象的指针变量指向它,而不能用一般的(指向非const型对象的)指针变量去指向它。
2) 如果定义了一个指向常对象的指针变量,并使它指向一个非const的对象,则其指向的对象是不能通过指针来改变的。如:
Time t1(10,12,15); //定义Time类对象t1,它是非const型对象
const Time *p = &t1; //定义p是指向常对象的指针变量,并指向t1
t1.hour = 18; //合法,t1不是常变量
(* p).hour = 18; //非法,不齙通过指针变量改变t1的值
如果希望在任何情况下t1的值都不能改变,则应把它定义为const型,如:
const Time t1(lO,12,15);
请注意指向常对象的指针变量与指向对象的常指针变量在形式上和作用上的区别。
Time * const p; //指向对象的常指针变量
const Time *p; //指向常对象的指针变量
3) 指向常对象的指针最常用于函数的形参,目的是在保护形参指针所指向的对象,使它在函数执行过程中不被修改。
请记住这样一条规则: 当希望在调用函数时对象的值不被修改,就应当把形参定义为指向常对象的指针变量,同时用对象的地址作实参(对象可以是const或非const型)。如果要求该对象不仅在调用函数过程中不被改变,而且要求它在程序执行过程中都不改变,则应把它定义为const型。
4) 如果定义了一个指向常对象的指针变量,是不能通过它改变所指向的对象的值的,但是指针变量本身的值是可以改变的。
14)对象的常引用
我们知道,一个变量的引用就是变量的别名。实质上,变量名和引用名都指向同一段内存单元。
如果形参为变量的引用名,实参为变量名,则在调用函数进行虚实结合时,并不是为形参另外开辟一个存储空间(常称为建立实参的一个拷贝),而是把实参变量的地址传给形参(引用名),这样引用名也指向实参变量。
[例9.8] 对象的常引用。
#include <iostream>
using namespace std;
class Time
{
public:
Time(int,int,int);
int hour;
int minute;
int sec;
};
Time::Time(int h,int m,int s) //定义构造函数
{
hour=h;
minute=m;
sec=s;
}
void fun(Time &t)
{
t.hour=;
}
int main( )
{
Time t1(,,);
fun(t1);
cout<<t1.hour<<endl;
return ;
}
如果不希望在函数中修改实参t1的值,可以把引用变量t声明为const(常引用),函数原型为
void fun(const Time &t);
则在函数中不能改变t的值,也就是不能改变其对应的实参t1的值。
在C++面向对象程序设计中,经常用常指针和常引用作函数参数。这样既能保证数据安全,使数据不能被随意修改,在调用函数时又不必建立实参的拷贝。
每次调用函数建立实参的拷贝时,都要调用复制构造函数,要有时间开销。用常指针和常引用作函数参数,可以提高程序运行效率。
15)对象的动态建立和释放
使用类名定义的对象(请查看:C++类的声明和对象的定义)都是静态的,在程序运行过程中,对象所占的空间是不能随时释放的。但有时人们希望在需要用到对象时才建立对象,在不需要用该对象时就撤销它,释放它所占的内存空间以供别的数据使用。这样可提高内存空间的利用率。
在C++中,可以使用new运算符动态地分配内存,用delete运算符释放这些内存空间(请查看:C++动态分配内存(new)和撤销内存(delete))。这也适用于对象,可以用new运算符动态建立对象,用delete运算符撤销对象。
如果已经定义了一个Box类,可以用下面的方法动态地建立一个对象:
new Box;
编译系统开辟了一段内存空间,并在此内存空间中存放一个Box类对象,同时调用该类的构造函数,以使该对象初始化(如果已对构造函数赋予此功能的话)。
但是此时用户还无法访问这个对象,因为这个对象既没有对象名,用户也不知道它的地址。这种对象称为无名对象,它确实是存在的,但它没有名字。
用new运算符动态地分配内存后,将返回一个指向新对象的指针的值,即所分配的内存空间的起始地址。用户可以获得这个地址,并通过这个地址来访问这个对象。需要定义一个指向本类的对象的指针变量来存放该地址。如
Box *pt; //定义一个指向Box类对象的指针变量pt
pt=new Box; //在pt中存放了新建对象的起始地址
在程序中就可以通过pt访问这个新建的对象。如
cout<<pt->height; //输出该对象的height成员
cout<<pt->volume( ); //调用该对象的volume函数,计算并输出体积
C++还允许在执行new时,对新建立的对象进行初始化。如
Box *pt=new Box(12,15,18);
这种写法是把上面两个语句(定义指针变量和用new建立新对象)合并为一个语句,并指定初值。这样更精炼。
新对象中的height,width和length分别获得初值12,15,18。调用对象既可以通过对象名,也可以通过指针。
用new建立的动态对象一般是不用对象名的,是通过指针访问的,它主要应用于动态的数据结构,如链表。访问链表中的结点,并不需要通过对象名,而是在上一个结点中存放下一个结点的地址,从而由上一个结点找到下一个结点,构成链接的关系。
在执行new运算时,如果内存量不足,无法开辟所需的内存空间,目前大多数C++编译系统都使new返回一个0指针值。只要检测返回值是否为0,就可判断分配内存是否成功。
ANSI C++标准提出,在执行new出现故障时,就“抛出”一个“异常”,用户可根据异常进行有关处理。但C++标准仍然允许在出现new故障时返回0指针值。当前,不同的编译系统对new故障的处理方法是不同的。
在不再需要使用由new建立的对象时,可以用delete运算符予以释放。如
delete pt; //释放pt指向的内存空间
这就撤销了pt指向的对象。此后程序不能再使用该对象。
如果用一个指针变量pt先后指向不同的动态对象,应注意指针变量的当前指向,以免删错了对象。在执行delete运算符时,在释放内存空间之前,自动调用析构函数,完成有关善后清理工作。
16)对象赋值
对象赋值的一般形式为:
对象名1 = 对象名2;
注意对象名1和对象名2必须属于同一个类。例如
Student stud1,stud2; //定义两个同类的对象
stud2=stud1; //将stud1赋给stud2
通过下面的例子可以了解怎样进行对象的赋值。
[例9.9] 对象的赋值。
#include <iostream>
using namespace std;
class Box
{
public :
Box(int =,int =,int =); //声明有默认参数的构造函数
int volume( );
private :
int height;
int width;
int length;
};
Box::Box(int h,int w,int len)
{
height=h;
width=w;
length=len;
}
int Box::volume( )
{
return (height*width*length); //返回体积
}
int main( )
{
Box box1(,,),box2; //定义两个对象box1和box2
cout<<"The volume of box1 is "<<box1.volume( )<<endl;
box2=box1; //将box1的值赋给box2
cout<<"The volume of box2 is "<<box2.volume( )<<endl; return ;
}
运行结果如下:
The volume of box1 is 11250
The volume of box2 is 11250
说明:(谨记)
- 对象的赋值只对其中的数据成员赋值,而不对成员函数赋值。数据成员是占存储空间的,不同对象的数据成员占有不同的存储空间,赋值的过程是将一个对象的数据成员在存储空间的状态复制给另一对象的数据成员的存储空间。而不同对象的成员函数是同一个函数代码段,不需要、也无法对它们赋值。
- 类的数据成员中不能包括动态分配的数据,否则在赋值时可能出现严重后果 (在此不作详细分析,只需记住这一结论即可)。
17)对象的复制
有时需要用到多个完全相同的对象,例如,同一型号的每一个产品从外表到内部属性都是一样的,如果要对每一个产品分别进行处理,就需要建立多个同样的对象,并要进行相同的初始化,用以前的办法定义对象(同时初始化)比较麻烦。此外,有时需要将对象在某一瞬时的状态保留下来。
C++提供了克隆对象的方法,来实现上述功能。这就是对象的复制机制。
用一个已有的对象快速地复制出多个完全相同的对象。如
Box box2(box1); 1克隆2;
其作用是用已有的对象box1去克隆出一个新对象box2。(1克隆2,2和1一样)
其一般形式为:
类名 对象2(对象1);
用对象1复制出对象2。
可以看到,它与定义对象的方式类似,但是括号中给出的参数不是一般的变量,而是对象。在建立对象时调用一个特殊的构造函数——复制构造函数(copy constructor)。这个函数的形式是这样的:
//The copy constructor definition.
Box::Box(const Box& b)
{
height=b.height; width=b.width; length=b.length;
}
复制构造函数也是构造函数,但它只有一个参数,这个参数是本类的对象(不能是其他类的对象), 而且采用对象的引用的形式(一般约定加const声明,使参数值不能改变,以免在调用此函数时因不慎而使对象值被修改)。此复制构造函数的作用就是将实参对象的各成员值一一赋给新的对象中对应的成员。
复制对象的语句
Box box2(box1);
这实际上也是建立对象的语句,建立一个新对象box2。由于在括号内给定的实参是对象,因此编译系统就调用复制构造函数(它的形参也是对象), 而不会去调用其他构造函数。实参box1的地址传递给形参b(b是box1的引用),因此执行复制构造函数的函数体时,将box1对象中各数据成员的值赋给box2中各数据成员。
如果用户自己未定义复制构造函数,则编译系统会自动提供一个默认的复制构造函数,其作用只是简单地复制类中每个数据成员。C++还提供另一种方便用户的复制形式,用赋值号代替括号,如
Box box2=box1; //用box1初始化box2
其一般形式为
类名 对象名1 = 对象名2;
可以在一个语句中进行多个对象的复制。如
Box box2=box1,box3=box2;
按box1来复制box2和box3。可以看出,这种形式与变量初始化语句类似,请与下面定义变量的语句作比较:
int a=4,b=a;
这种形式看起来很直观,用起来很方便。但是其作用都是调用复制构造函数。
赋值:对象两者已经存在
复制:对象一方从无到有
可以对例9.7程序中的主函数作一些修改:
int main( )
{
Box box1(,,); //定义box1
cout<<"The volume of box1 is "<<box1.volume( )<<endl;
Box box2=box1,box3=box2; //按box1来复制box2,box3
cout<<"The volume of box2 is "<<box2.volume( )<<endl;
cout<<"The volume of box3 is "<<box3.volume( )<<endl;
}
执行完第3行后,3个对象的状态完全相同。
下面说一下普通构造函数和复制构造函数的区别。
1) 在形式上
类名(形参表列); //普通构造函数的声明,如Box(int h,int w,int len);
类名(类名& 对象名); //复制构造函数的声明,如Box(Box &b);
2) 在建立对象时,实参类型不同
系统会根据实参的类型决定调用普通构造函数或复制构造函数。如
Box box1(12,15,16); //实参为整数,调用普通构造函数
Box box2(box1); //实参是对象名,调用复制构造函数(在进行对象复制时候,对象调用的构造函数就不一样了)
3) 在什么情况下被调用
普通构造函数在程序中建立对象时被调用。复制构造函数在用已有对象复制一个新对象时被调用,在以下3种情况下需要克隆对象:
① 程序中需要新建立一个对象,并用另一个同类的对象对它初始化,如上面介绍的那样。
② 当函数的参数为类的对象时。在调用函数时需要将实参对象完整地传递给形参,也就是需要建立一个实参的拷贝,这就是按实参复制一个形参,系统是通过调用复制构造函数来实现的,这样能保证形参具有和实参完全相同的值。如
void fun(Box b) //形参是类的对象
{ }
int main( )
{
Box box1(,,);
fun(box1); //实参是类的对象,调用函数时将复制一个新对象b
return ;
}
③ 函数的返回值是类的对象。在函数调用完毕将返回值带回函数调用处时。此时需要将函数中的对象复制一个临时对象并传给该函数的调用处。如
Box f( ) //函数f的类型为Box类类型
{
Box box1(,,);
return box1; //返回值是Box类的对象
}
int main( )
{
Box box2; //定义Box类的对象box2
box2=f( ); //调用f函数,返回Box类的临时对象,并将它赋值给box2
}
以上几种调用复制构造函数都是由编译系统自动实现的,不必由用户自己去调用,读者只要知道在这些情况下需要调用复制构造函数就可以了。
18)C++ static静态成员变量和静态成员函数
如果想在同类的多个对象之间实现数据共享,也不要用全局变量,那么可以使用静态成员变量。
static静态成员变量
静态成员变量是一种特殊的成员变量,它以关键字 static 开头。例如:
class Student{
private:
char *name;
int age;
float score;
static int num; //将num定义为静态成员变量
public:
Student(char *, int, float);
void say();
};
这段代码声明了一个静态成员变量 num,用来统计学生的人数。
static 成员变量属于类,不属于某个具体的对象,这就意味着,即使创建多个对象,也只为 num 分配一份内存,所有对象使用的都是这份内存中的数据。当某个对象修改了 num,也会影响到其他对象。
static 成员变量必须先初始化才能使用,否则链接错误。例如:
int Student::num; //初始化
或者:
int Student::num = ; //初始化同时赋值
初始化时可以不加 static,但必须要有数据类型。被 private、protected、public 修饰的 static 成员变量都可以用这种方式初始化。
注意:static 成员变量的内存空间既不是在声明类时分配,也不是在创建对象时分配,而是在初始化时分配。
static 成员变量既可以通过对象来访问,也可以通过类来访问。通过类来访问的形式为:
类名::成员变量;
例如:
//通过类来访问
Student::num = ;
//通过对象来访问
Student stu;
stu.num = ;
这两种方式是等效的。
注意:static 成员变量与对象无关,不占用对象的内存,而是在所有对象之外开辟内存,即使不创建对象也可以访问。
下面来看一个完整的例子:
#include <iostream>
using namespace std; class Student{
private:
char *name;
int age;
float score;
static int num; //将num定义为静态成员变量 ① public:
Student(char *, int, float);
void say();
}; int Student::num = ; //初始化静态成员变量 ② 这时候分配内存 Student::Student(char *name, int age, float score){
this->name = name;
this->age = age;
this->score = score;
num++;
}
void Student::say(){
//在普通成员函数中可以访问静态成员变量 ③
cout<<name<<"的年龄是 "<<age<<",成绩是 "<<score<<"(当前共"<<num<<"名学生)"<<endl;
} int main(){
//使用匿名对象
(new Student("小明", , ))->say();
(new Student("李磊", , ))->say();
(new Student("张华", , ))->say();
(new Student("王康", , ))->say(); return ;
}
运行结果:
小明的年龄是 15,成绩是 90(当前共1名学生)
李磊的年龄是 16,成绩是 80(当前共2名学生)
张华的年龄是 16,成绩是 99(当前共3名学生)
王康的年龄是 14,成绩是 60(当前共4名学生)
本例中将 num 声明为静态成员变量,每次创建对象时,会调用构造函数,将 num 的值加 1。之所以使用匿名对象,是因为每次创建对象后只会使用它的 say 函数,不再进行其他操作。不过请注意,使用匿名对象有内存泄露的风险。
关于静态数据成员的几点说明:
1) 一个类中可以有一个或多个静态成员变量,所有的对象都共享这些静态成员变量,都可以引用它。
2) static 成员变量和普通 static 变量一样,编译时在静态数据区分配内存,到程序结束时才释放。这就意味着,static 成员变量不随对象的创建而分配内存,也不随对象的销毁而释放内存。而普通成员变量在对象创建时分配内存,在对象销毁时释放内存。
3) 静态成员变量必须初始化,而且只能在类体外进行。例如:
int Student::num = ;
初始化时可以赋初值,也可以不赋值。如果不赋值,那么会被默认初始化,一般是 0。静态数据区的变量都有默认的初始值,而动态数据区(堆区、栈区)的变量默认是垃圾值。
4) 静态成员变量既可以通过对象名访问,也可以通过类名访问,但要遵循 private、protected 和 public 关键字的访问权限限制。当通过对象名访问时,对于不同的对象,访问的是同一份内存。
static静态成员函数
在类中,static 除了声明静态成员变量,还可以声明静态成员函数。普通成员函数可以访问所有成员变量,而静态成员函数只能访问静态成员变量。
我们知道,当调用一个对象的成员函数(非静态成员函数)时,系统会把当前对象的起始地址赋给 this 指针。而静态成员函数并不属于某一对象,它与任何对象都无关,因此静态成员函数没有 this 指针。既然它没有指向某一对象,就无法对该对象中的非静态成员进行访问。this并不能指向一个静态变量;,静态成员函数无法对非静态变量进行访问;
可以说,静态成员函数与非静态成员函数的根本区别是:非静态成员函数有 this 指针,而静态成员函数没有 this 指针。由此决定了静态成员函数不能访问本类中的非静态成员。
静态成员函数可以直接引用本类中的静态数据成员,因为静态成员同样是属于类的,可以直接引用。在C++程序中,静态成员函数主要用来访问静态数据成员,而不访问非静态成员。
如果要在类外调用 public 属性的静态成员函数,要用类名和域解析符“::”。如:
Student::getNum();
当然也可以通过对象名调用静态成员函数,如:
stu.getNum();
下面是一个完整的例子,通过静态成员函数获得学生的平均成绩:
#include <iostream>
using namespace std; class Student{
private:
char *name;
int age;
float score;
static int num; //学生人数
static float total; //总分 public:
Student(char *, int, float);
void say();
static float getAverage(); //静态成员函数,用来获得平均成绩
}; int Student::num = ;
float Student::total = ; Student::Student(char *name, int age, float score){
this->name = name;
this->age = age;
this->score = score;
num++;
total += score;
}
void Student::say(){
cout<<name<<"的年龄是 "<<age<<",成绩是 "<<score<<"(当前共"<<num<<"名学生)"<<endl;
}
float Student::getAverage(){
return total / num; //里面只能用 静态变量
} int main(){
(new Student("小明", , ))->say();
(new Student("李磊", , ))->say();
(new Student("张华", , ))->say();
(new Student("王康", , ))->say(); cout<<"平均成绩为 "<<Student::getAverage()<<endl; return ;
}
运行结果:
小明的年龄是 15,成绩是 90(当前共1名学生)
李磊的年龄是 16,成绩是 80(当前共2名学生)
张华的年龄是 16,成绩是 99(当前共3名学生)
王康的年龄是 14,成绩是 60(当前共4名学生)
平均成绩为 82.25
上面的代码中,将 num、total 声明为静态成员变量,将 getAverage 声明为静态成员函数。在 getAverage 函数中,只使用了 total、num 两个静态成员变量。
19)静态成员函数
与数据成员类似,成员函数也可以定义为静态的,在类中声明函数的前面加static就成了静态成员函数。如
static int volume( );
和静态数据成员一样,静态成员函数是类的一部分,而不是对象的一部分。
如果要在类外调用公用的静态成员函数,要用类名和域运算符“::”。如
Box::volume( );
实际上也允许通过对象名调用静态成员函数,如
a.volume( );
但这并不意味着此函数是属于对象a的,而只是用a的类型而已。
与静态数据成员不同,静态成员函数的作用不是为了对象之间的沟通,而是为了能处理静态数据成员。
我们知道,当调用一个对象的成员函数(非静态成员函数)时,系统会把该对象的起始地址赋给成员函数的this指针。而静态成员函数并不属于某一对象,它与任何对象都无关,因此静态成员函数没有this指针。既然它没有指向某一对象,就无法对一个对象中的非静态成员进行默认访问(即在引用数据成员时不指定对象名)。
可以说,静态成员函数与非静态成员函数的根本区别是:非静态成员函数有this指针,而静态成员函数没有this指针。由此决定了静态成员函数不能访问本类中的非静态成员。
静态成员函数可以直接引用本类中的静态数据成员,因为静态成员同样是属于类的,可以直接引用。在C++程序中,静态成员函数主要用来访问静态数据成员,而不访问非静态成员。
假如在一个静态成员函数中有以下语句:
cout<<height<<endl; //若height已声明为static,则引用本类中的静态成员,合法
cout<<width<<endl; //若width是非静态数据成员,不合法
但是,并不是绝对不能引用本类中的非静态成员,只是不能进行默认访问,因为无法知道应该去找哪个对象。
如果一定要引用本类的非静态成员,应该加对象名和成员运算符“.”。如
cout<<a.width<<endl; //引用本类对象a中的非静态成员
假设a已定义为Box类对象,且在当前作用域内有效,则此语句合法。
通过例9.11可以具体了解有关引用非静态成员的具体方法。
[例9.11] 静态成员函数的应用。
#include <iostream>
using namespace std;
class Student //定义Student类
{
public:
Student(int n,int a,float s):num(n),age(a),score(s){ } //定义构造函数
void total( );
static float average( ); //声明静态成员函数
private:
int num;
int age;
float score;
static float sum; //静态数据成员
static int count; //静态数据成员
};
void Student::total( ) //定义非静态成员函数
{
sum+=score; //累加总分
count++; //累计已统计的人数
}
float Student::average( ) //定义静态成员函数
{
return(sum/count);
} float Student::sum=; //对静态数据成员初始化
int Student::count=; //对静态数据成员初始化 int main( )
{
Student stud[]={ //定义对象数组并初始化
Student(,,),
Student(,,),
Student(,,)
};
int n;
cout<<"please input the number of students:";
cin>>n; //输入需要求前面多少名学生的平均成绩
for(int i=;i<n;i++) //调用3次total函数
stud[i].total( );
cout<<"the average score of "<<n<<" students is "<<Student::average( )<<endl;
//调用静态成员函数
return ;
}
运行结果为:
please input the number of students:3↙
the average score of 3 students is 82.3333
关于静态成员函数成员的几点说明:
- 在主函数中定义了stud对象数组,为了使程序简练,只定义它含3个元素,分别存放3个学生的数据。程序的作用是先求用户指定的n名学生的总分,然后求平均成绩(n由用户输入)。
- 在Student类中定义了两个静态数据成员sum(总分)和count(累计需要统计的学生人数), 这是由于这两个数据成员的值是需要进行累加的,它们并不是只属于某一个对象元素,而是由各对象元素共享的,可以看出: 它们的值是在不断变化的,而且无论对哪个对象元素而言,都是相同的,而且始终不释放内存空间。
- total是公有的成员函数,其作用是将一个学生的成绩累加到sum中。公有的成员函数可以引用本对象中的一般数据成员(非静态数据成员),也可以引用类中的静态数据成员。score是非静态数据成员,sum和count是静态数据成员。
- average是静态成员函数,它可以直接引用私有的静态数据成员(不必加类名或对象名), 函数返回成绩的平均值。
- 在main函数中,引用total函数要加对象名(今用对象数组元素名), 引用静态成员函数average函数要用类名或对象名。
- 请思考,如果不将average函数定义为静态成员函数行不行?程序能否通过编译?需要作什么修改?为什么要用静态成员函数?请分析其理由。
最后请注意,作为C++程序员,最好养成这样的习惯:只用静态成员函数引用静态数据成员,而不引用非静态数据成员。这样思路清晰,逻辑清楚,不易出错。
20)C++友元函数和友元类
在一个类中可以有公用的(public)成员和私有的(private)成员,在类外可以访问公用成员,只有本类中的函数可以访问本类的私有成员。现在,我们来补充介绍一个例外——友元(friend)。
fnend 的意思是朋友,或者说是好友,与好友的关系显然要比一般人亲密一些。有的家庭可能会这样处理:客厅对所有来客开放,而卧室除了本家庭的成员可以进人以外,还允许好朋友进入。在C++中,这种关系以关键宇 friend 声明,中文多译为友元。友元可以访问与其有好友关系的类中的私有成员,友元包括友元函数和友元类。如果您对友元这个名词不习惯,可以按原文 friend 理解为朋友即可。
友元函数
在当前类以外定义的、不属于当前类的函数也可以在类中声明,但要在前面加 friend 关键字,这样就构成了友元函数。友元函数可以是不属于任何类的非成员函数,也可以是其他类的成员函数。
友元函数可以访问当前类中的所有成员,包括 private 属性的。
1) 将普通函数声明为友元函数。
#include<iostream>
using namespace std; class Student{
private:
char *name;
int age;
float score;
public:
Student(char*, int, float);
friend void display(Student &); //将display声明为友元函数
};
Student::Student(char *name, int age, float score){
this->name = name;
this->age= age;
this->score = score;
} //普通成员函数
void display(Student &stu){
cout<<stu.name<<"的年龄是 "<<stu.age<<",成绩是 "<<stu.score<<endl;
} int main(){
Student stu("小明", , 95.5f);
display(stu); return ;
}
运行结果:
小明的年龄是 16,成绩是 95.5
请注意 display 是一个在类外定义的且没有使用 Student 作限定的函数,它是非成员函数,不属于任何类,它的作用是输出学生的信息。如果在 Student 类中未声明 display 函数为 friend 函数,它是不能引用 Student 中的私有成员 name、age、score 的。大家可以亲测一下,将上面程序中的第11行删去,观察编译时的信息。
现在由于声明了 display 是 Student 类的 friend 函数,所以 display 可以使用 Student 中的私有成员 name、age、score。但注意在使用这些成员变量时必须加上对象名,不能写成:
cout<<name<<"的年龄是 "<<age<<",成绩是 "<<score<<endl; //错误
2) 将其他类的成员函数声明为友元函数
friend 函数不仅可以是普通函数(非成员函数),还可以是另一个类中的成员函数。请看下面的例子:
#include<iostream>
using namespace std; class Address; //对Address类的提前引用声明 //声明Student类
class Student{
private:
char *name;
int age;
float score;
public:
Student(char*, int, float);
void display(Address &);
}; //声明Address类
class Address{
private:
char *province;
char *city;
char *district;
public:
Address(char*, char*, char*);
//将Student类中的成员函数display声明为友元函数
friend void Student::display(Address &);
};
Address::Address(char *province, char *city, char *district){
this->province = province;
this->city = city;
this->district = district;
} //声明Student类成构造函数和成员函数
Student::Student(char *name, int age, float score){
this->name = name;
this->age= age;
this->score = score;
}
void Student::display(Address &add){
cout<<name<<"的年龄是 "<<age<<",成绩是 "<<score<<endl;
cout<<"家庭住址:"<<add.province<<"省"<<add.city<<"市"<<add.district<<"区"<<endl;
} int main(){
Student stu("小明", , 95.5f);
Address add("陕西", "西安", "雁塔");
stu.display(add); return ;
}
运行结果:
小明的年龄是 16,成绩是 95.5
家庭住址:陕西省西安市雁塔区
在本例中定义了两个类 Student 和 Address。程序第 26 行将 Student 类中的成员函数 display 声明为友元函数,由此,display 就可以访问 Address 类的私有成员变量了(只是这个函数可以访问address了)。
两点注意:
① 程序第4行对Address类进行了提前声明,是因为在Address类定义之前、在Student类中使用到了它,如果不提前声明,编译会报错,提示"Address" has not been declared。类的提前声明和函数的提前声明是一个道理。
② 程序中将 Student 类的声明和定义分开了,而将 Address 放在了中间,是因为 Student::display() 函数体中用到了 Address 类的成员,必须出现在 Address 类的类体之后(类体说明了有哪些成员)。
这里简单介绍一下类的提前声明。一般情况下,类必须在正式声明之后才能使用;但是某些情况下(如上例所示),只要做好提前声明,也可以先使用。
但是应当注意,类的提前声明的使用范围是有限的。只有在正式声明一个类以后才能用它去创建对象。如果在上面程序第4行后面增加一行:
Address obj; //企图定义一个对象
会在编译时出错。因为创建对象时是要为对象分配内存空间的,在正式声明类之前,编译系统无法确定应该为对象分配多大的空间。编译器只有在“见到”类体后(其实是见到成员变量),才能确定应该为对象预留多大的空间。在对一个类作了提前引用声明后,可以用该类的名字去定义指向该类型对象的指针变量或对象的引用变量(如在本例中,定义了Address类对象的引用变量)。这是因为指针变量和引用变量本身的大小是固定的,与它所指向的类对象的大小无关。
请注意程序是在定义 Student::display() 函数之前正式声明 Address 类的。这是因为在 Student::display() 函数体中要用到 Address 类的成员变量 province、city、district,如果不正式声明 Address 类,编译器就无法识别这些成员变量。
③ 一个函数可以被多个类声明为“朋友”,这样就可以引用多个类中的私有成员。
友元类
不仅可以将一个函数声明为一个类的“朋友”,而且可以将整个类(例如B类)声明为另一个类(例如A类)的“朋友”。这时B类就是A类的友元类。
友元类B中的所有函数都是A类的友元函数,可以访问A类中的所有成员。在A类的类体中用以下语句声明B类为其友元类:
friend B;
声明友元类的一般形式为:
friend 类名;
关于友元,有两点需要说明:
- 友元的关系是单向的而不是双向的。如果声明了 B类是A类的友元类,不等于A类是B类的友元类,A类中的成员函数不能访问B类中的私有数据。
- 友元的关系不能传递,如果B类是A类的友元类,C类是B类的友元类,不等于 C类是A类的友元类。
在实际开发中,除非确有必要,一般并不把整个类声明为友元类,而只将确实有需要的成员函数声明为友元函数,这样更安全一些。
21)类模块
有时,有两个或多个类,其功能是相同的,仅仅是数据类型不同,如下面语句声明了一个类:
class Compare_int
{
public :
Compare(int a,int b)
{
x=a;
y=b;
}
int max( )
{
return (x>y)?x:y;
}
int min( )
{
return (x<y)?x:y;
}
private :
int x,y;
};
其作用是对两个整数作比较,可以通过调用成员函数max和min得到两个整数中的大者和小者。
如果想对两个浮点数(float型)作比较,需要另外声明一个类:
class Compare_float
{
public :
Compare(float a,float b)
{
x=a;y=b;
}
float max( )
{
return (x>y)?x:y;
}
float min( )
{
return (x<y)?x:y;
}
private :
float x,y;
}
显然这基本上是重复性的工作,应该有办法减少重复的工作。
C++在发展的后期增加了模板(template )的功能,提供了解决这类问题的途径。可以声明一个通用的类模板,它可以有一个或多个虚拟的类型参数,如对以上两个类可以综合写出以下的类模板:
template <class numtype> //声明一个模板,虚拟类型名为numtype
class Compare //类模板名为Compare
{
public :
Compare(numtype a,numtype b)
{
x=a;y=b;
}
numtype max( )
{
return (x>y)?x:y;
}
numtype min( )
{
return (x<y)?x:y;
}
private :
numtype x,y;
};
请将此类模板和前面第一个Compare_int类作一比较,可以看到有两处不同。
1) 声明类模板时要增加一行
template <class 类型参数名>
template意思是“模板”,是声明类模板时必须写的关键字。在template后面的尖括号内的内容为模板的参数表列,关键字class表示其后面的是类型参数。在本例中numtype就是一个类型参数名。这个名宇是可以任意取的,只要是合法的标识符即可。这里取numtype只是表示“数据类型”的意思而已。此时,mimtype并不是一个已存在的实际类型名,它只是一个虚拟类型参数名。在以后将被一个实际的类型名取代。
2) 原有的类型名int换成虚拟类型参数名numtype。
在建立类对象时,如果将实际类型指定为int型,编译系统就会用int取代所有的numtype,如果指定为float型,就用float取代所有的numtype。这样就能实现“一类多用”。
由于类模板包含类型参数,因此又称为参数化的类。如果说类是对象的抽象,对象是类的实例,则类模板是类的抽象,类是类模板的实例。利用类模板可以建立含各种数据类型的类。
那么,在声明了一个类模板后,怎样使用它呢?怎样使它变成一个实际的类?
先回顾一下用类来定义对象的方法:
Compare_int cmp1(4,7); // Compare_int是已声明的类
其作用是建立一个Compare_int类的对象,并将实参4和7分别赋给形参a和b,作为进 行比较的两个整数。
用类模板定义对象的方法与此相似,但是不能直接写成
Compare cmp(4,7); // Compare是类模板名
Compare是类模板名,而不是一个具体的类,类模板体中的类型numtype并不是一个实际的类型,只是一个虚拟的类型,无法用它去定义对象。必须用实际类型名去取代虚拟的类型,具体的做法是:
Compare <int> cmp(4,7);
即在类模板名之后在尖括号内指定实际的类型名,在进行编译时,编译系统就用int取代类模板中的类型参数numtype,这样就把类模板具体化了,或者说实例化了。这时Compare<int>就相当于前面介绍的Compare_int类。
[例9.14] 声明一个类模板,利用它分别实现两个整数、浮点数和字符的比较,求出大数和小数。
#include <iostream>
using namespace std;
template <class numtype>
//定义类模板
class Compare
{
public :
Compare(numtype a,numtype b)
{x=a;y=b;}
numtype max( )
{return (x>y)?x:y;}
numtype min( )
{return (x<y)?x:y;}
private :
numtype x,y;
};
int main( )
{
Compare<int > cmp1(,); //定义对象cmp1,用于两个整数的比较
cout<<cmp1.max( )<<" is the Maximum of two integer numbers."<<endl;
cout<<cmp1.min( )<<" is the Minimum of two integer numbers."<<endl<<endl;
Compare<float > cmp2(45.78,93.6); //定义对象cmp2,用于两个浮点数的比较
cout<<cmp2.max( )<<" is the Maximum of two float numbers."<<endl;
cout<<cmp2.min( )<<" is the Minimum of two float numbers."<<endl<<endl;
Compare<char> cmp3(′a′,′A′); //定义对象cmp3,用于两个字符的比较
cout<<cmp3.max( )<<" is the Maximum of two characters."<<endl;
cout<<cmp3.min( )<<" is the Minimum of two characters."<<endl;
return ;
}
运行结果如下:
7 is the Maximum of two integers.
3 is the Minimum of two integers.
93.6 is the Maximum of two float numbers.
45.78 is the Minimum of two float numbers.
a is the Maximum of two characters.
A is the Minimum of two characters.
还有一个问题要说明: 上面列出的类模板中的成员函数是在类模板内定义的。如果改为在类模板外定义,不能用一般定义类成员函数的形式:
numtype Compare::max( ) {…} //不能这样定义类模板中的成员函数
而应当写成类模板的形式:
template <class numtype>
numtype Compare<numtype>::max( )
{
return (x>y)?x:y;
}
上面第一行表示是类模板,第二行左端的numtype是虚拟类型名,后面的Compare <numtype>是一个整体,是带参的类。表示所定义的max函数是在类Compare <numtype>的作用域内的。在定义对象时,用户当然要指定实际的类型(如int),进行编译时就会将类模板中的虚拟类型名numtype全部用实际的类型代替。这样Compare <numtype >就相当于一个实际的类。大家可以将例9.14改写为在类模板外定义各成员 函数。
归纳以上的介绍,可以这样声明和使用类模板:
1) 先写出一个实际的类。由于其语义明确,含义清楚,一般不会出错。
2) 将此类中准备改变的类型名(如int要改变为float或char)改用一个自己指定的虚拟类型名(如上例中的numtype)。
3) 在类声明前面加入一行,格式为:
template <class 虚拟类型参数>
如:
template <class numtype> //注意本行末尾无分号
class Compare
{…}; //类体
4) 用类模板定义对象时用以下形式:
类模板名<实际类型名> 对象名;
类模板名<实际类型名> 对象名(实参表列);
如:
Compare<int> cmp;
Compare<int> cmp(3,7);
5) 如果在类模板外定义成员函数,应写成类模板形式:
template <class 虚拟类型参数>
函数类型 类模板名<虚拟类型参数>::成员函数名(函数形参表列) {…}
关于类模板的几点说明:
1) 类模板的类型参数可以有一个或多个,每个类型前面都必须加class,如:
template <class T1,class T2>
class someclass
{…};
在定义对象时分别代入实际的类型名,如:
someclass<int,double> obj;
2) 和使用类一样,使用类模板时要注意其作用域,只能在其有效作用域内用它定义对象。
3) 模板可以有层次,一个类模板可以作为基类,派生出派生模板类。有关这方面的知识实际应用较少。
九.运算符重载
1)什么叫运算符重载
现在要讨论的问题是:用户能否根据自己的需要对C++已提供的运算符进行重载,赋予它们新的含义,使之一名多用。譬如,能否用”+”号进行两个复数的相加。在C++中不能在程序中直接用运算符”+”对复数进行相加运算。用户必须自己设法实现复数相加。例如用户可以通过定义一个专门的函数来实现复数相加。见例10.1
#include <iostream>
using namespace std;
class Complex //定义Complex类
{
public:
Complex( ){real=;imag=;} //定义构造函数
Complex(double r,double i){real=r;imag=i;} //构造函数重载
Complex complex_add(Complex &c2); //声明复数相加函数
void display( ); //声明输出函数
private:
double real; //实部
double imag; //虚部
}; Complex Complex::complex_add(Complex &c2)
{
Complex c;
c.real=real+c2.real;
c.imag=imag+c2.imag;
return c;
} void Complex::display( ) //定义输出函数
{
cout<<"("<<real<<","<<imag<<"i)"<<endl;
}
int main( )
{
Complex c1(,),c2(,-),c3;//定义3个复数对象
c3=c1.complex_add(c2); //调用复数相加函数
cout<<"c1="; c1.display( );//输出c1的值
cout<<"c2="; c2.display( );//输出c2的值
cout<<"c1+c2="; c3.display( );//输出c3的值
return ;
}
运行结果如下:
c1=(3+4i)
c2=(5-10i)
c1+c2=(8,-6i)
结果无疑是正确的,但调用方式不直观、太烦琐,使人感到很不方便。能否也和整数的加法运算一样,直接用加号”+”来实现复数运算呢?如
c3=c1+c2;
编译系统就会自动完成c1和c2两个复数相加的运算。如果能做到,就为对象的运算提供了很大的方便。这就需要对运算符”+“进行重载。
2)运算符重载方法
重载运算符的函数一般格式如下:
函数类型 operator 运算符名称 (形参表列)
{
// 对运算符的重载处理
}
例如,想将”+”用于Complex类(复数)的加法运算,函数的原型可以是这样的:
Complex operator+ (Complex& c1, Complex& c2);
在上面的一般格式中,operator是关键字,是专门用于定义重载运算符的函数的,运算符名称就是C++提供给用户的预定义运算符。注意,函数名是由operator和运算符组成,上面的operator+就是函数名,意思是“对运算符+重载”。只要掌握这点,就可以发现,这 类函数和其他函数在形式上没有什么区别。两个形参是Complex类对象的引用,要求实参为Complex类对象。
在定义了重载运算符的函数后,可以说,函数operator +重载了运算符+。在执行复数相加的表达式c1 + c2时(假设c1和c2都已被定义为Complex类对象),系统就会调用operator+函数,把c1和c2作为实参,与形参进行虚实结合。
为了说明在运算符重载后,执行表达式就是调用函数的过程,可以把两个整数相加也想像为调用下面的函数:
int operator + (int a, int b)
{
return (a+b);
}
如果有表达式5+8,就调用此函数,将5和8作为调用函数时的实参,函数的返回值为13。这就是用函数的方法理解运算符。可以在例10.1程序的基础上重载运算符“+”,使之用于复数相加。
[例10.2] 改写例10.1,重载运算符“+”,使之能用于两个复数相加。
#include <iostream>
using namespace std;
class Complex
{
public:
Complex( ){real=;imag=;}
Complex(double r,double i){real=r;imag=i;}
Complex operator+(Complex &c2);//声明重载运算符的函数 在对象中使用
void display( );
private:
double real;
double imag;
};
Complex Complex::operator+(Complex &c2) //定义重载运算符的函数
{
Complex c;
c.real=real+c2.real;
c.imag=imag+c2.imag;
return c;
} void Complex::display( )
{
cout<<"("<<real<<","<<imag<<"i)"<<endl;
} int main( )
{
Complex c1(,),c2(,-),c3;
c3=c1+c2; //运算符+用于复数运算
cout<<"c1=";c1.display( );
cout<<"c2=";c2.display( );
cout<<"c1+c2=";c3.display( );
return ;
}
运行结果与例10.1相同:
c1=(3+4i)
c2=(5-10i)
c1+c2=(8,-6i)
请比较例10.1和例10.2,只有两处不同:
1) 在例10.2中以operator+函数取代了例10.1中的complex_add函数,而且只是函数名不同,函数体和函数返回值的类型都是相同的。
2) 在main函数中,以“c3=c1+c2;”取代了例10.1中的“c3=c1.complex_add(c2);”。在将运算符+重载为类的成员函数后,C++编译系统将程序中的表达式c1+c2解释为
c1.operator+(c2) //其中c1和c2是Complex类的对象
即以c2为实参调用c1的运算符重载函数operator+(Complex &c2),进行求值,得到两个复数之和。
可以看到,两个程序的结构和执行过程基本上是相同的,作用相同,运行结果也相同。重载运算符是由相应的函数实现的。有人可能说,既然这样,何必对运算符重载呢?我们要从用户的角度来看问題,虽然重载运算符所实现的功能完全可以用函数实现,但是使用运算符重载能使用户程序易于编写、阅读和维护。在实际工作中,类的声明和类的使用往往是分离的。假如在声明Complex类时,对运算符+, -, *, /都进行了重载,那么使用这个类的用户在编程时可以完全不考虑函数是怎么实现的,放心大胆地直接使用+, -, *, /进行复数的运算即可,十分方便。
对上面的运算符重载函数operator+还可以改写得更简练一些:
Complex Complex::operator + (Complex &c2)
{return Complex(real+c2.real, imag+c2.imag);}
return语句中的Complex( real+c2.real, imag+c2.imag)是建立一个临时对象,它没有对名,是一个无名对象。在建立临时对象过程中调用构造函数。return语句将此临时对象作为函数返回值。
请思考,在例10.2中能否将一个常量和一个复数对象相加?如
c3=3+c2; //错误,与形参类型不匹配
应写成对象形式,如
c3 = Complex (3,0) +c2; //正确,类型均为对象
需要说明的是,运算符被重载后,其原有的功能仍然保留,没有丧失或改变。通过运算符重载,扩大了C++已有运算符的作用范围,使之能用于类对象。
运算符重载对C++有重要的意义,把运算符重载和类结合起来,可以在C++程序中定义出很有实用意义而使用方便的新的数据类型。运算符重载使C++具有更强大的功能、更好的可扩充性和适应性,这是C++最吸引人的特点之一。
3)运算符重载规则
1) C++不允许用户自己定义新的运算符,只能对已有的C++运算符进行重载。 例如,有人觉得BASIC中用“**“作为幂运算符很方便,也想在C++中将”**“定义为幂运算符,用”3**5“表示35,这样是不行的。
2) 重载不能改变运算符运算对象(即搡作数)的个数。如关系运算符“>”和“ <” 等是双目运算符,重载后仍为双目运算符,需要两个参数。运算符“ +”,“-”,“*”,“&”等既可以作为单目运算符,也可以作为双目运算符,可以分别将它们重载为单目运算符或双目运算符。
3) 重载不能改变运算符的优先级别。例如“*”和“/”优先于“ +”和“-”,不论怎样进行重载,各运算符之间的优先级别不会改变。有时在程序中希望改变某运算符的优先级,也只能使用加圆括号的办法强制改变重载运算符的运算顺序。
4) 重载不能改变运算符的结含性。如赋值运算符是右结合性(自右至左),重载后仍为右结合性。
5) 重载运算符的函数不能有默认的参数,否则就改变了运算符参数的个数,与前面第(2)点矛盾。
6) 重载的运算符必须和用户定义的自定义类型的对象一起使用,其参数至少应有一个是类对象(或类对象的引用)。也就是说,参数不能全部是C++的标准类型,以防止用户修改用于标准类型数据的运算符的性质,如下面这样是不对的:
int operator + (int a,int b)
{
retum(a-b);
}
原来运算符+的作用是对两个数相加,现在企图通过重载使它的作用改为两个数相减。 如果允许这样重载的话,如果有表达式4+3,它的结果是7呢还是1?显然,这是绝对禁止的。
如果有两个参数,这两个参数可以都是类对象,也可以一个是类对象,一个是C ++标准类型的数据,如
Complex operator + (int a,Complex&c)
{
return Complex(a +c.real, c.imag);
}
它的作用是使一个整数和一个复数相加。
7) 用于类对象的运算符一般必须重载,但有两个例外,运算符“=”和“&”不必重载。
①赋值运算符( = )可以用于每一个类对象,可以利用它在同类对象之间相互赋值。 我们知道,可以用赋值运算符对类的对象賦值,这是因为系统已为每一个新声明的类重载了一个赋值运算符,它的作用是逐个复制类的数据成员。用户可以认为它是系统提供的默认的对象赋值运算符,可以直接用于对象间的赋值,不必自己进行重载。但是有时系统提供的默认的对象赋值运算符不能满足程序的要求,例如,数据成员中包含指向动态分配内存的指针成员时,在复制此成员时就可能出现危险。在这种情况下, 就需要自己重载赋值运算符。
②地址运算符&也不必重载,它能返回类对象在内存中的起始地址。
8) 从理论上说,可以将一个运算符重载为执行任意的操作,如可以将加法运算符重载为输出对象中的信息,将“>”运算符重载为“小于”运算。但这样违背了运算符重载的初衷,非但没有提髙可读性,反而使人莫名其妙,无法理解程序。应当使重载运算符的功能类似于该运算符作用于标准类型数据时所实现的功能(如用“+”实现加法,用“>”实现“大于”的关系运算)一切都是为了方便,不是为了无理取闹。
9) 运算符重载函数可以是类的成员函数,也可以是类的友元函数,还可以是既非类的成员函数也不是友元函敝的普通函数。
以上这些规则是很容易理解的,不必死记。把它们集中在一起介绍,只是为了使读者有一个整体的概念,也便于查阅。
4)允许重载和不允许重载的运算符
C++中绝大部分的运算符允许重载,具体规定见表10.1。
| 双目算术运算符 | + (加),-(减),*(乘),/(除),% (取模) |
| 关系运算符 | ==(等于),!= (不等于),< (小于),> (大于>,<=(小于等于),>=(大于等于) |
| 逻辑运算符 | ||(逻辑或),&&(逻辑与),!(逻辑非) |
| 单目运算符 | + (正),-(负),*(指针),&(取地址) |
| 自增自减运算符 | ++(自增),--(自减) |
| 位运算符 | | (按位或),& (按位与),~(按位取反),^(按位异或),,<< (左移),>>(右移) |
| 赋值运算符 | =, +=, -=, *=, /= , % = , &=, |=, ^=, <<=, >>= |
| 空间申请与释放 | new, delete, new[ ] , delete[] |
| 其他运算符 | ()(函数调用),->(成员访问),->*(成员指针访问),,(逗号),[](下标) |
不能重载的运算符只有5个:
. (成员访问运算符)
.* (成员指针访问运算符)
:: (域运算符)
sizeof (长度运算符)
?: (条件运算符)
前两个运算符不能重载是为了保证访问成员的功能不能被改变,域运算符和sizeof 运算符的运算对象是类型而不是变量或一般表达式,不具备重载的特征。
5)运算符重载函数作为类成员函数和友元函数
[例10.3] 将运算符“+”重载为适用于复数加法,重载函数不作为成员函数,而放在类外,作为Complex类的友元函数。
#include <iostream>
using namespace std;
// 注意,该程序在VC 6.0中编译出错,将以上两行替换为 #include <iostream.h> 即可顺利通过
class Complex
{
public:
Complex( ){real=;imag=;}
Complex(double r,double i){real=r;imag=i;}
friend Complex operator + (Complex &c1,Complex &c2); //重载函数作为友元函数
void display( );
private:
double real;
double imag;
}; Complex operator + (Complex &c1,Complex &c2) //定义作为友元函数的重载函数
{
return Complex(c1.real+c2.real, c1.imag+c2.imag);
} void Complex::display( )
{
cout<<"("<<real<<","<<imag<<"i)"<<endl;
}
int main( )
{
Complex c1(,),c2(,-),c3;
c3=c1+c2;
cout<<"c1="; c1.display( );
cout<<"c2="; c2.display( );
cout<<"c1+c2 ="; c3.display( );
}
与例10.2相比较,只作了一处改动,将运算符函数不作为成员函数,而把它放在类外,在Complex类中声明它为友元函数。同时将运算符函数改为有两个参数。在将运算符“+”重载为非成员函数后,C++编译系统将程序中的表达式c1+c2解释为
operator+(c1, c2)
即执行c1+c2相当于调用以下函数:
Complex operator + (Complex &c1,Complex &c2)
{
return Complex(c1.real+c2.real, c1.imag+c2.imag);
}
求出两个复数之和。运行结果同例10.2。
为什么把运算符函数作为友元函数呢?因为运算符函数要访问Complex类对象中的成员。如果运算符函数不是Complex类的友元函数,而是一个普通的函数,它是没有权利访问Complex类的私有成员的。
在上节中曾提到过:运算符重载函数可以是类的成员函数,也可以是类的友元函数,还可以是既非类的成员函数也不是友元函数的普通函数。现在分别讨论这3种情况。
首先,只有在极少的情况下才使用既不是类的成员函数也不是友元函数的普通函数,原因是上面提到的,普通函数不能直接访问类的私有成员。
在剩下的两种方式中,什么时候应该用成员函数方式,什么时候应该用友元函数方式?二者有何区别呢?如果将运算符重载函数作为成员函数,它可以通过this指针自由地访问本类的数据成员,因此可以少写一个函数的参数。但必须要求运算表达式第一个参数(即运算符左侧的操作数)是一个类对象,而且与运算符函数的类型相同。因为必须通过类的对象去调用该类的成员函数,而且只有运算符重载函数返回值与该对象同类型,运算结果才有意义。在例10.2中,表达式c1+c2中第一个参数c1是Complex类对象,运算符函数返回值的类型也是Complex,这是正确的。如果c1不是Complex类,它就无法通过隐式this指针访问Complex类的成员了。如果函数返回值不是Complex类复数,显然这种运算是没有实际意义的。
如想将一个复数和一个整数相加,如c1+i,可以将运算符重载函数作为成员函数,如下面的形式:
Complex Complex∷operator+(int &i) //运算符重载函数作为Complex类的成员函数
{
return Complex(real+i,imag);
}
注意在表达式中重载的运算符“+”左侧应为Complex类的对象(切记这点),如:
c3=c2+i;
不能写成
c3=i+c2; //运算符“+”的左侧不是类对象,编译出错
如果出于某种考虑,要求在使用重载运算符时运算符左侧的操作数是整型量(如表达式i+c2,运算符左侧的操作数i是整数),这时是无法利用前面定义的重载运算符的,因为无法调用i.operator+函数。可想而知,如果运算符左侧的操作数属于C++标准类型(如int)或是一个其他类的对象,则运算符重载函数不能作为成员函数,只能作为非成员函数。如果函数需要访问类的私有成员,则必须声明为友元函数。可以在Complex类中声明:
friend Complex operator+(int &i,Complex &c); //第一个参数可以不是类对象
在类外定义友元函数:
Complex operator+(int &i, Complex &c) //运算符重载函数不是成员函数
{
return Complex(i+c.real, c.imag);
}
将双目运算符重载为友元函数时,在函数的形参表列中必须有两个参数,不能省略,形参的顺序任意,不要求第一个参数必须为类对象。但在使用运算符的表达式中,要求运算符左侧的操作数与函数第一个参数对应,运算符右侧的操作数与函数的第二个参数对应。如:
c3=i+c2; //正确,类型匹配 说白了就是参数前后类型保存一致
c3=c2+i; //错误,类型不匹配
请注意,数学上的交换律在此不适用。如果希望适用交换律,则应再重载一次运算符“+”。如
Complex operator+(Complex &c, int &i) //此时第一个参数为类对象
{
return Complex(i+c.real, c.imag);
} (重载一次,变量前后适用)
这样,使用表达式i+c2和c2+i都合法,编译系统会根据表达式的形式选择调用与之匹配的运算符重载函数。可以将以上两个运算符重载函数都作为友元函数,也可以将一个运算符重载函数(运算符左侧为对象名的) 作为成员函数,另一个(运算符左侧不是对象名的)作为友元函数。但不可能将两个都作为成员函数,原因是显然的。
C++规定,有的运算符(如赋值运算符、下标运算符、函数调用运算符)必须定义为类的成员函数,有的运算符则不能定义为类的成员函数(如流插入“<<”和流提取运算符“>>”、类型转换运算符)。
由于友元的使用会破坏类的封装,因此从原则上说,要尽量将运算符函数作为成员函数。但考虑到各方面的因素,一般将单目运算符重载为成员函数,将双目运算符重载为友元函数。在学习了本章第10.7节例10.9的讨论后,读者对此会有更深入的认识。
说明:有的C++编译系统(如Visual C++ 6.0)没有完全实现C++标准,它所提供不带后缀.h的头文件不支持把成员函数重载为友元函数。上面例10.3程序在GCC中能正常运行,而在Visual C++ 6.0中会编译出错。但是Visual C++所提供的老形式的带后缀.h的头文件可以支持此项功能,因此可以将程序头两行修改如下,即可顺利运行:
#include <iostream.h>
以后如遇到类似情况,亦可照此办理。
6)重载流插入运算符和流提取运算符
C++的流插入运算符“<<”和流提取运算符“>>”是C++在类库中提供的,所有C++编译系统都在类库中提供输入流类istream和输出流类ostream。cin和cout分别是istream类和ostream类的对象。在类库提供的头文件中已经对“<<”和“>>”进行了重载,使之作为流插入运算符和流提取运算符,能用来输出和输入C++标准类型的数据。因此,凡是用“cout<<”和“cin>>”对标准类型数据进行输入输出的,都要用#include 把头文件包含到本程序文件中。
用户自己定义的类型的数据,是不能直接用“<<”和“>>”来输出和输入的。如果想用它们输出和输入自己声明的类型的数据,必须对它们重载。
对“<<”和“>>”重载的函数形式如下:
istream & operator >> (istream &, 自定义类 &);
ostream & operator << (ostream &, 自定义类 &);
即重载运算符“>>”的函数的第一个参数和函数的类型都必须是istream&类型,第二个参数是要进行输入操作的类。重载“<<”的函数的第一个参数和函数的类型都必须是ostream&类型,第二个参数是要进行输出操作的类。因此,只能将重载“>>”和“<<”的函数作为友元函数或普通的函数,而不能将它们定义为成员函数。
重载流插入运算符“<<”
在程序中,人们希望能用插入运算符“<<”来输出用户自己声明的类的对象的信息,这就需要重载流插入运算符“<<”。
[例10.7] 在例10.2的基础上,用重载的“<<”输出复数。
#include <iostream>
using namespace std;
class Complex
{
public: (调用该类就会执行)
Complex( ){real=;imag=;}
Complex(double r,double i){real=r;imag=i;}
Complex operator + (Complex &c2); //运算符“+”重载为成员函数
friend ostream& operator << (ostream&,Complex&); //运算符“<<”重载为友元函数
private:
double real;
double imag;
}; Complex Complex::operator + (Complex &c2)//定义运算符“+”重载函数
{
return Complex(real+c2.real,imag+c2.imag);
}
ostream& operator << (ostream& output,Complex& c) //定义运算符“<<”重载函数
{
output<<"("<<c.real<<"+"<<c.imag<<"i)"<<endl;
return output;
} int main( )
{
Complex c1(,),c2(,),c3; //c1,c2,c3就叫对象了
c3=c1+c2;
cout<<c3;
return ;
}
注意,在Visual C++ 6.0环境下运行时,需将第一行改为#include <iostream.h>,并删去第2行,否则编译不能通过。运行结果为:
(8+14i)
可以看到在对运算符“<<”重载后,在程序中用“<<”不仅能输出标准类型数据,而且可以输出用户自己定义的类对象。用“cout<<c3”即能以复数形式输出复数对象c3的值。形式直观,可读性好,易于使用。
下面对怎样实现运算符重载作一些说明。程序中重载了运算符“<<”,运算符重载函数中的形参output是ostream类对象的引用,形参名output是用户任意起的。分析main函数最后第二行:
cout<<c3;
运算符“<<”的左面是cout,前面已提到cout是ostream类对象。“<<”的右面是c3,它是Complex类对象。由于已将运算符“<<”的重载函数声明为Complex类的友元函数,编译系统把“cout<<c3”解释为
operator<<(cout, c3)
即以cout和c3作为实参,调用下面的operator<<函数:
ostream& operator<<(ostream& output,Complex& c)
{
output<<"("<<c.real<<"+"<<c.imag<<"i)"<<endl;
return output;
}
调用函数时,形参output成为cout的引用,形参c成为c3的引用。因此调用函数的过程相当于执行:
cout<<″(″<<c3.real<<″+″<<c3.imag<<″i)″<<endl; return cout;
请注意,上一行中的“<<”是C++预定义的流插入符,因为它右侧的操作数是字符串常量和double类型数据。执行cout语句输出复数形式的信息。然后执行return语句。
请思考,return output的作用是什么?回答是能连续向输出流插入信息。output是ostream类的对象,它是实参cout的引用,也就是cout通过传送地址给output,使它们二者共享同一段存储单元,或者说output是cout的别名。因此,return output就是return cout,将输出流cout的现状返回,即保留输出流的现状。
请问返回到哪里?刚才是在执行
cout<<c3;
在已知cout<<c3的返回值是cout的当前值。如果有以下输出:
cout<<c3<<c2;
先处理
cout<<c3
即
(cout<<c3)<<c2;
而执行(cout<<c3)得到的结果就是具有新内容的流对象cout,因此,(cout<<c3)<<c2相当于cout(新值)<<c2。运算符“<<”左侧是ostream类对象cout,右侧是Complex类对象c2,则再次调用运算符“<<”重载函数,接着向输出流插入c2的数据。现在可以理解了为什么C++规定运算符“<<”重载函数的第一个参数和函数的类型都必须是ostream类型的引用,就是为了返回cout的当前值以便连续输出。
请读者注意区分什么情况下的“<<”是标准类型数据的流插入符,什么情况下的“<<”是重载的流插入符。如
cout<<c3<<5<<endl;
有下划线的是调用重载的流插入符,后面两个“<<”不是重载的流插入符,因为它的右侧不是Complex类对象而是标准类型的数据,是用预定义的流插入符处理的。
还有一点要说明,在本程序中,在Complex类中定义了运算符“<<”重载函数为友元函数,因此只有在输出Complex类对象时才能使用重载的运算符,对其他类型的对象是无效的。如
cout<<time1; //time1是Time类对象(因为Time类中没有定义该友元函数),不能使用用于Complex类的重载运算符
重载流提取运算符“>>”
C++预定义的运算符“>>”的作用是从一个输入流中提取数据,如“cin>>i;”表示从输入流中提取一个整数赋给变量i(假设已定义i为int型)。重载流提取运算符的目的是希望将“>>”用于输入自定义类型的对象的信息。
[例10.8] 在例10.7的基础上,增加重载流提取运算符“>>”,用“cin>>”输入复数,用“cout<<”输出复数。 (典 一个对象的输入输出)
#include <iostream>
using namespace std;
class Complex
{
public:
friend ostream& operator << (ostream&,Complex&); //声明重载运算符“<<”
friend istream& operator >> (istream&,Complex&); //声明重载运算符“>>”
private:
double real;
double imag;
};
ostream& operator << (ostream& output,Complex& c) //定义重载运算符“<<”
{
output<<"("<<c.real<<"+"<<c.imag<<"i)";
return output;
}
istream& operator >> (istream& input,Complex& c) //定义重载运算符“>>”
{
cout<<"input real part and imaginary part of complex number:";
input>>c.real>>c.imag;
return input;
}
int main( )
{
Complex c1,c2;
cin>>c1>>c2;
cout<<"c1="<<c1<<endl;
cout<<"c2="<<c2<<endl;
return ;
}
运行情况如下:
input real part and imaginary part of complex number:3 6↙
input real part and imaginary part of complex number:4 10↙
c1=(3+6i)
c2=(4+10i)
以上运行结果无疑是正确的,但并不完善。在输入复数的虚部为正值时,输出的结果是没有问题的,但是虚部如果是负数,就不理想,请观察输出结果。
input real part and imaginary part of complex number:3 6↙
input real part and imaginary part of complex number:4 -10↙
c1=(3+6i)
c2=(4+-10i)
根据先调试通过,最后完善的原则,可对程序作必要的修改。将重载运算符“<<”函数修改如下:
ostream& operator << (ostream& output,Complex& c)
{
output<<"("<<c.real;
if(c.imag>=) output<<"+";//虚部为正数时,在虚部前加“+”号
output<<c.imag<<"i)"<<endl; //虚部为负数时,在虚部前不加“+”号
return output;
}
这样,运行时输出的最后一行为c2=(4-10i) 。
可以看到,在C++中,运算符重载是很重要的、很有实用意义的。它使类的设计更加丰富多彩,扩大了类的功能和使用范围,使程序易于理解,易于对对象进行操作,它体现了为用户着想、方便用户使用的思想。有了运算符重载,在声明了类之后,人们就可以像使用标准类型一样来使用自己声明的类。类的声明往往是一劳永逸的,有了好的类,用户在程序中就不必定义许多成员函数去完成某些运算和输入输出的功能,使主函数更加简单易读。好的运算符重载能体现面向对象程序设计思想。
可以看到,在运算符重载中使用引用(reference)的重要性。利用引用作为函数的形参可以在调用函数的过程中不是用传递值的方式进行虚实结合,而是通过传址方式使形参成为实参的别名,因此不生成临时变量(实参的副本),减少了时间和空间的开销。此外,如果重载函数的返回值是对象的引用时,返回的不是常量,而是引用所代表的对象,它可以出现在赋值号的左侧而成为左值(left value),可以被赋值或参与其他操作(如保留cout流的当前值以便能连续使用“<<”输出)。但使用引用时要特别小心,因为修改了引用就等于修改了它所代表的对象。
7)数据类型转换以及转换构造函数
标准数据类型之间的转换
在C++中,某些不同类型数据之间可以自动转换,例如
int i = 6;
i = 7.5 + i;
编译系统对 7.5是作为double型数处理的,在求解表达式时,先将6转换成double型,然后与7.5相加,得到和为13.5,在向整型变量i赋值时,将13.5转换为整数13,然后赋给i。这种转换是由C++编译系统自动完成的,用户不需干预。这种转换称为隐式类型转换。
C++还提供显式类型转换,程序人员在程序中指定将一种指定的数据转换成另一指定的类型,其形式为:
类型名(数据)
如
int(89.5)
其作用是将89.5转换为整型数89。
以前我们接触的是标准类型之间的转换,现在用户自己定义了类,就提出了一个问题:一个自定义类的对象能否转换成标准类型? 一个类的对象能否转换成另外一个类的对象?譬如,能否将一个复数类数据转换成整数或双精度数?能否将Date类的对象转换成Time类的对象?
对于标准类型的转换,编译系统有章可循,知道怎样进行转换。而对于用户自己声明的类型,编译系统并不知道怎样进行转换。解决这个问题的关键是让编译系统知道怎样去进行这些转换,需要定义专门的函数来处理。
转换构造函数
转换构造函数(conversion constructor function) 的作用是将一个其他类型的数据转换成一个类的对象。这里回顾一下以前学习过的几种构造函数:
1) 默认构造函数。以Complex类为例,函数原型的形式为:
Complex( ); //没有参数
2) 用于初始化的构造函数。函数原型的形式为:
Complex(double r, double i); //形参表列中一般有两个以上参数
3) 用于复制对象的复制构造函数。函数原型的形式为:
Complex (Complex &c); //形参是本类对象的引用
现在介绍一种新的构造函数——转换构造函数。
转换构造函数只有一个形参,如
Complex(double r) {real=r;imag=0;}
其作用是将double型的参数r转换成Complex类的对象,将r作为复数的实部,虚部为0。用户可以根据需要定义转换构造函数,在函数体中告诉编译系统怎样去进行转换。
在类体中,可以有转换构造函数,也可以没有转换构造函数,视需要而定。以上几种构造函数可以同时出现在同一个类中,它们是构造函数的重载。编译系统会根据建立对象时给出的实参的个数与类型选择形参与之匹配的构造函数。
假如在Complex类中定义了上面的构造函数,在Complex类的作用域中有以下声明语句:
Complex cl(3.5) ; //建立对象cl,由于只有一个参数,调用转换构造函数
建立Comptex类对象cl,其real(实部)的值为3.5,imag(虚部)的值为0。它的作用就是将double型常数转换成一个名为cl的Complex类对象。也可以用声明语句建立一 个无名的Complex类对象。如
Complex(3.6) ; //用声明语句建立一个无名的对象,合法,但无法使用它
可以在一个表达式中使用无名对象,如:
cl =Complex(3.6); //假设cl巳被定义为Complex类对象
建立一个无名的Complex类对象,其值为(3.6+0i),然后将此无名对象的值賦给cl,cl 在赋值后的值是(3.6+0i)。
如果已对运算符“+”进行了重载,使之能进行两个Complex类对象的相加,若在程序中有以下表达式:
c = cl +2.5;
编译出错,因为不能用运算符“+”将一个Comptex类对象和一个浮点数相加。可以先将 2.5转换为Complex类无名对象,然后相加:
c = cl + Complex (2.5); //合法
请对比Complex(2.5)和int(2.5)。二者形式类似,int(2.5)是强制类型转换,将2.5转换为整数,int()是强制类型转换运算符。可以认为Complex(2.5)的作用也是强制类型 转换,将2.5转换为Complex类对象。
转换构造函数也是一种构造函数,它遵循构造函数的一般规则。通常把有一个参数的构造函数用作类型转换,所以,称为转换构造函数。其实,有一个参数的构造函数也可以不用作类型转换,如
Complex (double r){ cout<<r; } //这种用法毫无意义,没有人会这样用
转换构造函数的函数体是根据需要由用户确定的,务必使其有实际意义。例如也可 以这样定义转换构造函数:
Complex(double r){ real =0; imag = r; }
即实部为0,虚部为r。这并不违反语法,但没有人会这样做。应该符合习惯,合乎情理。
注意:转换构造函数只能有一个参数。如果有多个参数,就不是转换构造函数。原因是显然的,如果有多个参数的话,究竟是把哪个参数转换成Complex类的对象呢?
归纳起来,使用转换构造函数将一个指定的数据转换为类对象的方法如下:
1) 先声明一个类。
2) 在这个类中定义一个只有一个参数的构造函数,参数的类型是需要转换的类型,在函数体中指定转换的方法。
3) 在该类的作用域内可以用以下形式进行类型转换:
类名(指定类型的数据)
就可以将指定类型的数据转换为此类的对象。
不仅可以将一个标准类型数据转换成类对象,也可以将另一个类的对象转换成转换构造函数所在的类对象。如可以将一个学生类对象转换为教师类对象,可以在Teacher类中写出下面的转换构造函数:
Teacher(Student& s){ num=s.num;strcpy(name, s.name);sex=s.sex; }
但应注意,对象s中的num,name,sex必须是公用成员,否则不能被类外引用。
8)类型转换函数(类型转换运算符函数)
C++提供类型转换函数(type conversion function)来解决这个问题。类型转换函数的作用是将一个类的对象转换成另一类型的数据。如果已声明了一个Complex类,可以在Complex类中这样定义类型转换函数:
operator double( )
{
return real; //返回的是double型
}
函数返回double型变量real的值。它的作用是将一个Complex类对象转换为一个double型数据,其值是Complex类中的数据成员real的值。请注意,函数名是operator double,这点是和运算符重载时的规律一致的(在定义运算符“+”的重载函数时,函数名是operator +)。
类型转换函数的一般形式为:
operator 类型名( )
{
实现转换的语句
}
在函数名前面不能指定函数类型,函数没有参数。其返回值的类型是由函数名中指定的类型名来确定的。类型转换函数只能作为成员函数,因为转换的主体是本类的对象。不能作为友元函数或普通函数。
从函数形式可以看到,它与运算符重载函数相似,都是用关键字operator开头,只是被重载的是类型名。double类型经过重载后,除了原有的含义外,还获得新的含义(将一个Complex类对象转换为double类型数据,并指定了转换方法)。这样,编译系统不仅能识别原有的double型数据,而且还会把Complex类对象作为double型数据处理。
那么程序中的Complex类对具有双重身份,既是Complex类对象,又可作为double类型数据。Complex类对象只有在需要时才进行转换,要根据表达式的上下文来决定。转换构造函数和类型转换运算符有一个共同的功能:当需要的时候,编译系统会自动调用这些函数,建立一个无名的临时对象(或临时变量)。
[例10.9] 使用类型转换函数的简单例子。
#include <iostream>
using namespace std;
class Complex
{
public:
Complex( ){real=;imag=;}
Complex(double r,double i){real=r;imag=i;}
operator double( ) {return real;} //类型转换函数
private:
double real;
double imag;
}; int main( )
{
Complex c1(,),c2(,-),c3;
double d;
d=2.5+c1;//要求将一个double数据与Complex类数据相加
cout<<d<<endl;
return ;
}
对程序的分析:
1) 如果在Complex类中没有定义类型转换函数operator double,程序编译将出错。因为不能实现double 型数据与Complex类对象的相加。现在,已定义了成员函数 operator double,就可以利用它将Complex类对象转换为double型数据。请注意,程序中不必显式地调用类型转换函数,它是自动被调用的,即隐式调用。在什么情况下调用类型转换函数呢?编译系统在处理表达式 2.5 +cl 时,发现运算符“+”的左侧是double型数据,而右侧是Complex类对象,又无运算符“+”重载函数,不能直接相加,编译系统发现有对double的重载函数,因此调用这个函数,返回一个double型数据,然后与2.5相加。
2) 如果在main函数中加一个语句:
c3=c2;
请问此时编译系统是把c2按Complex类对象处理呢,还是按double型数据处理?由于赋值号两侧都是同一类的数据,是可以合法进行赋值的,没有必要把c2转换为double型数据。
3) 如果在Complex类中声明了重载运算符“+”函数作为友元函数:
Complex operator+ (Complex c1,Complex c2)//定义运算符“+”重载函数
{
return Complex(c1.real+c2.real, c1.imag+c2.imag);
}
若在main函数中有语句
c3=c1+c2;
由于已对运算符“+”重载,使之能用于两个Complex类对象的相加,因此将c1和c2按Complex类对象处理,相加后赋值给同类对象c3。如果改为
d=c1+c2; //d为double型变量
将c1与c2两个类对象相加,得到一个临时的Complex类对象,由于它不能赋值给double型变量,而又有对double的重载函数,于是调用此函数,把临时类对象转换为double数据,然后赋给d。
从前面的介绍可知,对类型的重载和对运算符的重载的概念和方法都是相似的,重载函数都使用关键字 operator。因此,通常把类型转换函数也称为类型转换运算符函数,由于它也是重载函数,因此也称为类型转换运算符重载函数(或称强制类型转换运算符重载函数)。
假如程序中需要对一个Complex类对象和一个double型变量进行+,-,*,/等算术运算,以及关系运算和逻辑运算,如果不用类型转换函数,就要对多种运算符进行重载,以便能进行各种运算。这样,是十分麻烦的,工作量较大,程序显得冗长。如果用类型转换函数对double进行重载(使Complex类对象转换为double型数据),就不必对各种运算符进行重载,因为Complex类对象可以被自动地转换为double型数据,而标准类型的数据的运算,是可以使用系统提供的各种运算符的。
[例10.10] 包含转换构造函数、运算符重载函数和类型转换函数的程序。先阅读以下程序,在这个程序中只包含转换构造函数和运算符重载函数。
#include <iostream>
using namespace std;
class Complex
{
public:
Complex( ){real=;imag=;} //默认构造函数
Complex(double r){real=r;imag=;}//转换构造函数
Complex(double r,double i){real=r;imag=i;}//实现初始化的构造函数
friend Complex operator + (Complex c1,Complex c2); //重载运算符“+”的友元函数
void display( );
private:
double real;
double imag;
};
Complex operator + (Complex c1,Complex c2)//定义运算符“+”重载函数
{
return Complex(c1.real+c2.real, c1.imag+c2.imag);
}
void Complex::display( )
{
cout<<"("<<real<<","<<imag<<"i)"<<endl;
}
int main( )
{
Complex c1(,),c2(,-),c3;
c3=c1+2.5; //复数与double数据相加
c3.display( );
return ;
}
注意,在Visual C++ 6.0环境下运行时,需将第一行改为#include <iostream.h>,并删去第2行,否则编译不能通过。
对程序的分析:
1) 如果没有定义转换构造函数,则此程序编译出错。
2) 现在,在类Complex中定义了转换构造函数,并具体规定了怎样构成一个复数。由于已重载了算符“+”,在处理表达式c1+2.5时,编译系统把它解释为
operator+(c1, 2.5)
由于2.5不是Complex类对象,系统先调用转换构造函数Complex(2.5),建立一个临时的Complex类对象,其值为(2.5+0i)。上面的函数调用相当于
operator+(c1, Complex(2.5))
将c1与(2.5+0i) 相加,赋给c3。运行结果为
(5.5+4i)
3) 如果把“c3=c1+2.5;”改为c3=2.5+c1; 程序可以通过编译和正常运行。过程与前相同。
从中得到一个重要结论,在已定义了相应的转换构造函数情况下,将运算符“+”函数重载为友元函数,在进行两个复数相加时,可以用交换律。
如果运算符函数重载为成员函数,它的第一个参数必须是本类的对象。当第一个操作数不是类对象时,不能将运算符函数重载为成员函数。如果将运算符“+”函数重载为类的成员函数,交换律不适用。(这个问题是在定义时需要注意的)
由于这个原因,一般情况下将双目运算符函数重载为友元函数。单目运算符则多重载为成员函数。
(运算符重载函数为类的成员函数时,第一个参数必须是本类的对象,当运算符重载函数是友元函数时,第一个参数没有限制)
4) 如果一定要将运算符函数重载为成员函数,而第一个操作数又不是类对象时,只有一个办法能够解决,再重载一个运算符“+”函数,其第一个参数为double型。当然此函数只能是友元函数,函数原型为
friend operator+(double, Complex &);
显然这样做不太方便,还是将双目运算符函数重载为友元函数方便些。
5) 在上面程序的基础上增加类型转换函数:
operator double( ){return real;}
此时Complex类的公用部分为:
public:
Complex( ){real=0;imag=0;}
Complex(double r){real=r;imag=0;} //转换构造函数
Complex(double r,double i){real=r;imag=i;}
operator double( ){return real;}//类型转换函数
friend Complex operator+ (Complex c1,Complex c2); //重载运算符“+”
void display( );
其余部分不变。程序在编译时出错,原因是出现二义性。
总结:
一)类型转换函数(类型转换运算符函数)
operator 类型名( )
{
实现转换的语句
}
例如:
operator double( )
{
return real; //返回的是double型
}
二)转换构造函数
如:
Complex(double r) {real=r;imag=0;}
特点:
1) 先声明一个类。
2) 在这个类中定义一个只有一个参数的构造函数,参数的类型是需要转换的类型,在函数体中指定转换的方法。
3) 在该类的作用域内可以用以下形式进行类型转换:
类名(指定类型的数据)
三)重载流插入运算符和流提取运算符
对“<<”和“>>”重载的函数形式如下:
istream & operator >> (istream &, 自定义类 &);
ostream & operator << (ostream &, 自定义类 &);
四)运算符重载方法
函数类型 operator 运算符名称 (形参表列)
{
// 对运算符的重载处理
}
特点:运算符重载函数为类的成员函数时,第一个参数必须是本类的对象,当运算符重载函数是友元函数时,第一个参数没有限制
十.继承与派生详解:C++派生类声明和构成、继承的意义
1)继承与派生的概念、什么是继承和派生
在C++中可重用性是通过继承(inheritance)这一机制来实现的。因此,继承是C++的一个重要组成部分。
前面介绍了类,一个类中包含了若干数据成员和成员函数。在不同的类中,数据成员和成员函数是不相同的。但有时两个类的内容基本相同或有一部分相同,例如巳声明了学生基本数据的类Student:
class Student
{
public:
void display( ) //对成员函数display的定义
{
cout<<"num: " <<num<<endl;
cout<<"name: "<< name <<endl;
cout <<"sex: "<<sex<<endl;
}
private:
int num;
string name;
char sex;
};
如果学校的某一部门除了需要用到学号、姓名、性别以外,还需要用到年龄、地址等信息。当然可以重新声明另一个类class Student1:
class Student1
{
public:
void display( ) //此行原来已有
{
cout<<"num: " <<num<<endl; //此行原来已有
cout<<"name: "<< name <<endl; //此行原来已有
cout <<"sex: "<<sex<<endl; //此行原来已有
cout <<"age: "<<age<<endl;
cout <<"address: "<<addr<<endl;
}
private:
int num; //此行原来已有
string name; //此行原来已有
char sex; //此行原来已有
int age;
char addr[];
};
可以看到有相当一部分是原来已经有的,可以利用原来声明的类Student作为基础,再加上新的内容即可,以减少重复的工作量。C++提供的继承机制就是为了解决这个问题。
在C++中,所谓“继承”就是在一个已存在的类的基础上建立一个新的类。已存在的类称为“基类(base class)”或“父类(father class)”,新建的类称为“派生类(derived class)”或“子类(son class )”。
一个新类从已有的类那里获得其已有特性,这种现象称为类的继承。通过继承,一个新建子类从已有的父类那里获得父类的特性。从另一角度说,从已有的类(父类)产生一个新的子类,称为类的派生。类的继承是用已有的类来建立专用类的编程技术。派生类继承了基类的所有数据成员和成员函数,并可以对成员作必要的增加或调整。一个基类可以派生出多个派生类,每一个派生类又可以作为基类再派生出新的派生类,因此基类和派生类是相对而言的。一代一代地派生下去,就形成类的继承层次结构。相当于一个大的家族,有许多分支,所有的子孙后代都继承了祖辈的基本特征,同时又有区别和发展。与之相仿,类的每一次派生,都继承了其基类的基本特征,同时又根据需要调整和扩充原 有的特征。
以上介绍的是最简单的情况:一个派生类只从一个基类派生,这称为单继承(single inheritance),这种继承关系所形成的层次是一个树形结构,如图11.3所示。

图 11.3
一个派生类不仅可以从一个基类派生,也可以从多个基类派生。也就是说,一个派生类可以有一个或者多个基类。一个派生类有两个或多个基类的称为多重继承(multiple inheritance)。关于基类和派生类的关系,可以表述为派生类是基类的具体化,而基类则是派生类的抽象。
2)派生类的声明方式(定义方式)
假设已经声明了一个基类Student(基类Student的定义见上节:C++继承与派生的概念),在此基础上通过单继承建立一个派生类Student1:
class Student1: public Student //声明基类是Student
{
public:
void display_1( ) //新增加的成员函数
{
cout<<"age: "<<age<<endl;
cout<<"address: "<<addr<<endl;
}
private:
int age; //新增加的数据成员
string addr; //新增加的数据成员
};
仔细观察第一行:
class Student1: public Student
在class后面的Student1是新建的类名,冒号后面的Student表示是已声明的基类。在Student之前有一关键宇public,用来表示基类Student中的成员在派生类Studeml中的继承方式。基类名前面有public的称为“公用继承(public inheritance)”。
请大家仔细阅读以上声明的派生类Student1和基类Student,并将它们放在一起进行分析。
声明派生类的一般形式为:
class 派生类名:[继承方式] 基类名
{
派生类新增加的成员
};
继承方式包括public (公用的)、private (私有的)和protected(受保护的),此项是可选的,如果不写此项,则默认为private(私有的)。
3)派生类的构成
派生类中的成员包括从基类继承过来的成员和自己增加的成员两大部分。从基类继承的成员体现了派生类从基类继承而获得的共性,而新增加的成员体现了派生类的个性。正是这些新增加的成员体现了派生类与基类的不同,体现了不同派生类之间的区别。
在基类中包括数据成员和成员函数 (或称数据与方法)两部分,派生类分为两大部分:一部分是从基类继承来的成员,另一部分是在声明派生类时增加的部分。每一部分均分别包括数据成员和成员函数。
实际上,并不是把基类的成员和派生类自己增加的成员简单地加在一起就成为派生类。构造一个派生类包括以下3部分工作。
1) 从基类接收成员
派生类把基类全部的成员(不包括构造函数和析构函数)接收过来,也就是说是没有选择的,不能选择接收其中一部分成员,而舍弃另一部分成员。 从定义派生类的一般形式中可以看出是不可选择的。
这样就可能出现一种情况:有些基类的成员,在派生类中是用不到的,但是也必须继承过来。这就会造成数据的冗余,尤其是在多次派生之后,会在许多派生类对象中存在大量无用的数据,不仅浪费了大量的空间,而且在对象的建立、赋值、复制和参数的传递中, 花费了许多无谓的时间,从而降低了效率。这在目前的C++标准中是无法解决的,要求我们根据派生类的需要慎重选择基类,使冗余量最小。不要随意地从已有的类中找一个作为基类去构造派生类,应当考虑怎样能使派生类有更合理的结构。事实上,有些类是专门作为基类而设计的,在设计时充分考虑到派生类的要求。
2) 调整从基类接收的成员
接收基类成员是程序人员不能选择的,但是程序人员可以对这些成员作某些调整。例如可以改变基类成员在派生类中的访问属性,这是通过指定继承方式来实现的。如可以通过继承把基类的公用成员指定为在派生类中的访问属性为私有(派生类外不能访问)。此外,可以在派生类中声明一个与基类成员同名的成员,则派生类中的新成员会覆盖基类的同名成员。但应注意,如果是成员函数,不仅应使函数名相同,而且函数的参数表(参数的个数和类型)也应相同,如果不相同,就成为函数的重载而不是覆盖了。用这样的方法可以用新成员取代基类的成员。
3) 在声明派生类时增加的成员
这部分内容是很重要的,它体现了派生类对基类功能的扩展。要根据需要仔细考虑应当增加哪些成员,精心设计。例如在前面例子中(请查看:C++派生类的声明方式),基类的display函数的作用是输出学号、姓名和性别,在派生类中要求输出学号、姓名、性别、年龄和地址,不必单独另写一个输出这5个数据的函数,而要利用基类的display 函数输出学号、姓名和性别,另外再定义一个display_1 函数输出年龄和地址,先后执行这两个函数。也可以在 display_1 函数中调用基类的display函数,再输出另外两个数据,在主函数中只需调用一个display_1函数即可,这样可能更清晰一些,易读性更好。
此外,在声明派生类时,一般还应当自己定义派生类的构造函数和析构函数,因为构造函数和析构函数是不能从基类继承的。
通过以上的介绍可以看出:派生类是基类定义的延续。可以先声明一个基类,在此基类中只提供某些最基本的功能,而另外有些功能并未实现,然后在声明派生类时加入某些具体的功能,形成适用于某一特定应用的派生类。通过对基类声明的延续,将一个抽象的基类转化成具体的派生类。因此,派生类是抽象基类的具体实现。
4)派生成员的访问属性
既然派生类中包含基类成员和派生类自己增加的成员,就产生了这两部分成员的关系和访问属性的问题。在建立派生类的时候,并不是简单地把基类的私有成员直接作为派生类的私有成员,把基类的公用成员直接作为派生类的公用成员。
实际上,对基类成员和派生类自己增加的成员是按不同的原则处理的。具体说,在讨论访问属性时,要考虑以下几种情况:
- 基类的成员函数访问基类成员。
- 派生类的成员函数访问派生类自己增加的成员。
- 基类的成员函数访问派生类的成员。(这样不对吧)
- 派生类的成员函数访问基类的成员。
- 在派生类外访问派生类的成员。
- 在派生类外访问基类的成员。
对于第(1)和第(2)种情况,比较简单,基类的成员函数可以访问基类成员,派生类的成员函数可以访问派生类成员。私有数据成员只能被同一类中的成员函数访问,公用成员可以被外界访问。
第(3)种情况也比较明确,基类的成员函数只能访问基类的成员,而不能访问派生类的成员。
第(5)种情况也比较明确,在派生类外可以访问派生类的公用成员,而不能访问派生类的私有成员。
对于第(4)和第(6)种情况,就稍微复杂一些,也容易混淆。譬如,有人提出这样的问题:
- 基类中的成员函数是可以访问基类中的任一成员的,那么派生类中新增加的成员是否可以同样地访问基类中的私有成员;
- 在派生类外,能否通过派生类的对象名访问从基类继承的公用成员。
这些牵涉到如何确定基类的成员在派生类中的访问属性的问题,不仅要考虑对基类成员所声明的访问属性,还要考虑派生类所声明的对基类的继承方式,根据这两个因素共同决定基类成员在派生类中的访问属性。
前面已提到,在派生类中,对基类的继承方式可以有public(公用的)、private (私有的)和protected(保护的)3种。不同的继承方式决定了基类成员在派生类中的访问属性。简单地说可以总结为以下几点。
1) 公用继承(public inheritance)
基类的公用成员和保护成员在派生类中保持原有访问属性,其私有成员仍为基类私有。
2) 私有继承(private inheritance)
基类的公用成员和保护成员在派生类中成了私有成员,其私有成员仍为基类私有。
3) 受保护的继承(protected inheritance)
基类的公用成员和保护成员在派生类中成了保护成员,其私有成员仍为基类私有。保护成员的意思是,不能被外界引用,但可以被派生类的成员引用。
5)公用继承
在定义一个派生类时将基类的继承方式指定为public的,称为公用继承,用公用继承方式建立的派生类称为公用派生类(public derived class ),其基类称为公用基类(public base class )。
采用公用继承方式时,基类的公用成员和保护成员在派生类中仍然保持其公用成员和保护成员的属性,而基类的私有成员在派生类中并没有成为派生类的私有成员,它仍然是基类的私有成员,只有基类的成员函数可以引用它,而不能被派生类的成员函数引用,因此就成为派生类中的不可访问的成员。公用基类的成员在派生类中的访问属性见表11.1。
| 公用基类的成员 | 私有成员 | 公用成员 | 保护成员 |
|---|---|---|---|
| 在公用派生类中的访问属性 | 不可访问 | 公用 | 保护 |
有人问,既然是公用继承,为什么不让访问基类的私有成员呢?要知道,这是C++中一个重要的软件工程观点。因为私有成员体现了数据的封装性,隐藏私有成员有利于测试、调试和修改系统。如果把基类所有成员的访问权限都原封不动地继承到派生类,使基类的私有成员在派生类中仍保持其私有性质,派生类成员能访问基类的私有成员,那么岂非基类和派生类没有界限了?这就破坏了基类的封装性。如果派生类再继续派生一个新的派生类,也能访问基类的私有成员,那么在这个基类的所有派生类的层次上都能访问基类的私有成员,这就完全丢弃了封装性带来的好处。保护私有成员是一条重要的原则。
[例11.1] 访问公有基类的成员。下面写出类的声明部分:
Class Student//声明基类
{
public: //基类公用成员
void get_value( )
{
cin>>num>>name>>sex;
}
void display( )
{
cout<<" num: "<<num<<endl;
cout<<" name: "<<name<<endl;
cout<<" sex: "<<sex<<endl;
}
private: //基类私有成员
int num;
string name;
char sex;
}; class Student1: public Student //以public方式声明派生类Student1
{
public:
void display_1( )
{
cout<<" num: "<<num<<endl; //企图引用基类的私有成员,错误
cout<<" name: "<<name<<endl; //企图引用基类的私有成员,错误
cout<<" sex: "<<sex<<endl; //企图引用基类的私有成员,错误
cout<<" age: "<<age<<endl; //引用派生类的私有成员,正确
cout<<" address: "<<addr<<endl;
} //引用派生类的私有成员,正确
private:
int age;
string addr;
};
由于基类的私有成员对派生类来说是不可访问的,因此在派生类中的display_1函数中直接引用基类的私有数据成员num,name和sex是不允许的。只能通过基类的公用成员函数来引用基类的私有数据成员。可以将派生类Student1的声明改为
class Student1: public Student //以public方式声明派生类Student1
{
public:
void display_1( )
{
cout<<" age: "<<age<<endl; //引用派生类的私有成员,正确
cout<<" address: "<<addr<<endl; //引用派生类的私有成员,正确
}
private:
int age; string addr;
};
然后在main函数中分别调用基类的display函数和派生类中的display_1函数,先后输出5个数据。
可以这样写main函数(假设对象stud中已有数据):
int main( )
{
Student1 stud;//定义派生类Student1的对象stud
stud.display( ); //调用基类的公用成员函数,输出基类中3个数据成员的值
stud.display_1(); //调用派生类公用成员函数,输出派生类中两个数据成员的值
return ;
}
请根据上面的分析,写出完整的程序,程序中应包括输入数据的函数。
实际上,程序还可以改进,在派生类的display_1函数中调用基类的display函数,在主函数中只要写一行:
stud.display_1();
即可输出5个数据。
6)私有继承
在声明一个派生类时将基类的继承方式指定为private的,称为私有继承,用私有继承方式建立的派生类称为私有派生类(private derived class ), 其基类称为私有基类(private base class )。
私有基类的公用成员和保护成员在派生类中的访问属性相当于派生类中的私有成员,即派生类的成员函数能访问它们,而在派生类外不能访问它们。私有基类的私有成员在派生类中成为不可访问的成员,只有基类的成员函数可以引用它们。一个基类成员在基类中的访问属性和在派生类中的访问属性可能是不同的。私有基类的成员在私有派生类中的访问属性见表11.2。
| 私有基类中的成员 | 在私有派生类中的访问属性 |
|---|---|
| 私有成员 | 不可访问 |
| 公用成员 | 私有 |
| 保护成员 | 私有 |
上表不必死记硬背,只需理解:既然声明为私有继承,就表示将原来能被外界引用的成员隐藏起来,不让外界引用,因此私有基类的公用成员和保护成员理所当然地成为派生类中的私有成员。
私有基类的私有成员按规定只能被基类的成员函数引用,在基类外当然不能访问他们,因此它们在派生类中是隐蔽的,不可访问的。
对于不需要再往下继承的类的功能可以用私有继承方式把它隐蔽起来,这样,下一层的派生类无法访问它的任何成员。可以知道,一个成员在不同的派生层次中的访问属性可能是不同的,它与继承方式有关。
[例11.2] 将例11.1中的公用继承方式改为用私有继承方式(基类Student不改)。可以写出私有派生类如下:
class Student1: private Student//用私有继承方式声明派生类Student1
{
public:
void display_1( ) //输出两个数据成员的值
{
cout<<"age: "<<age<<endl; //引用派生类的私有成员,正确
cout<<"address: "<<addr<<endl;
} //引用派生类的私有成员,正确
private:
int age;
string addr;
};
请分析下面的主函数:
int main( )
{
Student1 stud1;//定义一个Student1类的对象stud1
stud1.display(); //错误,私有基类的公用成员函数在派生类中是私有函数
stud1.display_1( );//正确,Display_1函数是Student1类的公用函数
stud1.age=; //错误,外界不能引用派生类的私有成员
return ;
}
可以看到:
- 不能通过派生类对象(如stud1)引用从私有基类继承过来的任何成员(如stud1.display()或stud1.num)。
- 派生类的成员函数不能访问私有基类的私有成员,但可以访问私有基类的公用成员(如stud1.display_1函数可以调用基类的公用成员函数display,但不能引用基类的私有成员num)。
不少读者提出这样一个问題:私有基类的私有成员mun等数据成员只能被基类的成员函数引用,而私有基类的公用成员函数又不能被派生类外调用,那么,有没有办法调用私有基类的公用成员函数,从而引用私有基类的私有成员呢?有。
应当注意到,虽然在派生类外不能通过派生类对象调用私有基类的公用成员函数,但可以通过派生类的成员函数调用私有基类的公用成员函数(此时它是派生类中的私有成员函数,可以被派生类的任何成员函数调用)。
可将上面的私有派生类的成员函数定义改写为:
void display_1( )//输出5个数据成员的值
{
display(): //调用基类的公用成员函数,输出3个数据成员的值
cout<<"age: "<<age<<endl; //输出派生类的私有数据成员
cout<<"address: "<<addr<<endl;
} //输出派生类的私有数据成员
main函数可改写为:
int main( )
{
Student1 stud1;
stud1.display_1( );//display_1函数是派生类Student1类的公用函数
return ;
}
这样就能正确地引用私有基类的私有成员。可以看到,本例采用的方法是:
- 在main函数中调用派生类中的公用成员函数stud1.display_1;
- 通过该公用成员函数调用基类的公用成员函数display(它在派生类中是私有函数,可以被派生类中的任何成员函数调用);
- 通过基类的公用成员函数display引用基类中的数据成员。
请根据上面的要求,补充和完善上面的程序,使之成为完整、正确的程序,程序中应包括输入数据的函数。
由于私有派生类限制太多,使用不方便,一般不常使用。
7)保护成员和保护继承
protected 与 public 和 private 一样是用来声明成员的访问权限的。由protected声明的成员称为“受保护的成员”,或简称“保护成员”。从类的用户角度来看,保护成员等价于私有成员。但有一点与私有成员不同,保护成员可以被派生类的成员函数引用。
如果基类声明了私有成员,那么任何派生类都是不能访问它们的,若希望在派生类中能访问它们,应当把它们声明为保护成员。如果在一个类中声明了保护成员,就意味着该类可能要用作基类,在它的派生类中会访问这些成员。
在定义一个派生类时将基类的继承方式指定为protected的,称为保护继承,用保护继承方式建立的派生类称为保护派生类(protected derived class ), 其基类称为受保护的基类(protected base class ),简称保护基类。
保护继承的特点是:保护基类的公用成员和保护成员在派生类中都成了保护成员,其私有成员仍为基类私有。也就是把基类原有的公用成员也保护起来,不让类外任意访问。
| 基类中的成员 | 在公用派生类中的访问属性 | 在私有派生类中的访问属性 | 在保护派生类中的访问属性 |
|---|---|---|---|
| 私有成员 | 不可访问 | 不可访问 | 不可访问 |
| 公用成员 | 公用 | 私有 | 保护 |
| 保护成员 | 保护 | 私有 | 保护 |
☆☆☆
保护基类的所有成员在派生类中都被保护起来,类外不能访问,其公用成员和保护成 员可以被其派生类的成员函数访问。
保护基类的所有成员在派生类中都被保护起来,类外不能访问,其公用成员和保护成员可以被其派生类的成员函数访问。
比较一下私有继承和保护继承(也就是比较在私有派生类中和在保护派生类中的访问属性), 可以发现,在直接派生类中,以上两种继承方式的作用实际上是相同的:在类外不能访问任何成员,而在派生类中可以通过成员函数访问基类中的公用成员和保护成员。但是如果继续派生,在新的派生类中,两种继承方式的作用就不同了。
例如,如果以公用继承方式派生出一个新派生类,原来私有基类中的成员在新派生类中都成为不可访问的成员,无论在派生类内或外都不能访问,而原来保护基类中的公用成员和保护成员在新派生类中为保护成员,可以被新派生类的成员函数访问。
大家需要记住:基类的私有成员被派生类继承(不管是私有继承、公有继承还是保护继承)后变为不可访问的成员,派生类中的一切成员均无法访问它们。如果需要在派生类中引用基类的某些成员,应当将基类的这些成员声明为protected,而不要声明为private。
如果善于利用保护成员,可以在类的层次结构中找到数据共享与成员隐蔽之间的结合点。既可实现某些成员的隐蔽,又可方便地继承,能实现代码重用与扩充。
通过以上的介绍,可以知道以下几点。
1) 在派生类中,成员有4种不同的访问属性:
- 公用的,派生类内和派生类外都可以访问。
- 受保护的,派生类内可以访问,派生类外不能访问,其下一层的派生类可以访问。
- 私有的,派生类内可以访问,派生类外不能访问。
- 不可访问的,派生类内和派生类外都不能访问。
| 派生类中的成员 | 在派生类中 | 在派生类外部 | 在下层公用派生类中 |
|---|---|---|---|
| 派生类中访问属性为公用的成员 | 可以 | 可以 | 可以 |
| 派生类中访问属性为受保护的成员 | 可以 | 不可以 | 可以 |
| 派生类中访问属性为私有的成员 | 可以 | 不可以 | 不可以 |
| 在派生类中不可访问的成员 | 不可以 | 不可以 | 不可以 |
☆☆☆
需要说明的是:
- 这里所列出的成员的访问属性是指在派生类中所获得的访问属性。
- 所谓在派生类外部,是指在建立派生类对象的模块中,在派生类范围之外。
- 如果本派生类继续派生,则在不同的继承方式下,成员所获得的访问属性是不同的,在本表中只列出在下一层公用派生类中的情况,如果是私有继承或保护继承,大家可以从表11.3中找到答案。
2) 类的成员在不同作用域中有不同的访问属性,对这一点要十分清楚。一个成员的访问属性是有前提的,要看它在哪一个作用域中。有的读者问:“一个基类的公用成 员,在派生类中变成保护的,究竟它本身是公用的还是保护的?”应当说:这是同一个成员在不同的作用域中所表现出的不同特征。例如,学校人事部门掌握了全校师生员工的资 料,学校的领导可以查阅任何人的材料,学校下属的系只能从全校的资料中得到本系师生员工的资料,而不能查阅其他部门任何人的材料。如果你要问:能否查阅张某某的材料, 无法一概而论,必须查明你的身份,才能决定该人的材料能否被你“访问”。
在未介绍派生类之前,类的成员只属于其所属的类,不涉及其他类,不会引起歧义。 在介绍派生类后,就存在一个问题:在哪个范围内讨论成员的特征,同一个成员在不同 的继承层次中有不同的特征。为了说明这个概念,可以打个比方,汽车驾驶证是按地区核发的,北京的驾驶证在北京市范围内畅通无阻,如果到了外地,可能会受到某些限制,到了外国就无效了。同一个驾驶员在不同地区的权利是不同的。又譬如,到医院探视病人,如 果允许你进人病房近距离地看望病人并与之交谈,则可对病人了解比较深人;如果只允许你在玻璃门窗外探视,在一定距离外看到病人,只能对病人状况有粗略的印象;如果只允许在病区的走廊里通过电视看病人活动的片段镜头,那就更间接了。人们在不同的场合下对同一个病人,得到不同的信息,或者说,这个病人在不同的场合下的“可见性”不同。
平常,人们常习惯说某类的公用成员如何如何,这在一般不致引起误解的情况下是可以的。但是决不要误认为该成员的访问属性只能是公用的而不能改变。在讨论成员的访问属性时,一定要说明是对什么范围而言的,如基类的成员a,在基类中的访问属性是公用的,在私有派生类中的访问属性是私有的。
下面通过一个例子说明怎样访问保护成员。
[例11.3] 在派生类中引用保护成员。
#include <iostream>
#include <string>
using namespace std;
class Student//声明基类
{
public:
//基类公用成员
void display( );
protected:
//基类保护成员
int num;
string name;
char sex;
};
//定义基类成员函数
void Student::display( )
{
cout<<"num: "<<num<<endl;
cout<<"name: "<<name<<endl;
cout<<"sex: "<<sex<<endl;
}
class Student1: protected
Student //用protected方式声明派生类Student1
{
public:
void display1( );//派生类公用成员函数
private:
int age;//派生类私有数据成员
string addr;//派生类私有数据成员
};
void Student1::display1( )//定义派生类公用成员函数
{
cout<<"num: "<<num<<endl;//引用基类的保护成员,合法
cout<<"name: "<<name<<endl;//引用基类的保护成员,合法
cout<<"sex: "<<sex<<endl;//引用基类的保护成员,合法
cout<<"age: "<<age<<endl;//引用派生类的私有成员,合法
cout<<"address: "<<addr<<endl; //引用派生类的私有成员,合法
}
int main( )
{
Student1 stud1; //stud1是派生类Student1类的对象
stud1.display1( ); //合法,display1是派生类中的公用成员函数
stud1.num=; //错误,外界不能访问保护成员
return ;
}
总结:
①类的继承中,私有部分永远只能被自身类使用
②
共用继承:父类中的公用成员在子类为公用成员
私有继承:父类中的公用成员在子类为私有成员
受保护继承: 父类的保护成员在子类中任为保护成员,只能在类中引用,不可对外使用。
8)类多级派生时的访问属性
在实际项目开发中,经常会有多级派生的情况。如图11.9所示的派生关系:类A为基类,类B是类A 的派生类,类C是类B的派生类,则类C也是类A的派生类;类B称为类A 的直接派生类,类C称为类A的间接派生类;类A是类B的直接基类,是类 C的间接基类。

图 11.9
在多级派生的情况下,各成员的访问属性仍按以上原则确定。
为了把多重继承说的更加详细,请大家先看下面的几个继承的类。
[例11.4] 如果声明了以下的类:
class A //基类
{
public:
int i;
protected:
void f2( );
int j;
private:
int k;
};
class B: public A //public方式
{
public:
void f3( );
protected:
void f4( );
private:
int m;
};
class C: protected B //protected方式
{
public:
void f5( );
private:
int n;
};
类A是类B的公用基类,类B是类C的保护基类。各成员在不同类中的访问属性如下:
| i | f2 | j | k | f3 | f4 | m | f5 | n | |
| 基类A | 公用 | 保护 | 保护 | 私有 | |||||
| 公用派生类B | 公用 | 保护 | 保护 | 不可访问 | 公用 | 保护 | 私有 | ||
| 保护派生类C | 保护 | 保护 | 保护 | 不可访问 | 保护 | 保护 | 不可访问 | 公用 | 私有 |
9)派生类的构造函数
基类的构造函数不能被继承,在声明派生类时,对继承过来的成员变量的初始化工作也要由派生类的构造函数来完成。所以在设计派生类的构造函数时,不仅要考虑派生类新增的成员变量,还要考虑基类的成员变量,要让它们都被初始化。
解决这个问题的思路是:在执行派生类的构造函数时,调用基类的构造函数。
下面的例子展示了如何在派生类的构造函数中调用基类的构造函数。
#include<iostream>
using namespace std; //基类
class People{
protected:
char *name;
int age;
public:
People(char*, int);
};
People::People(char *name, int age): name(name), age(age){} //派生类
class Student: public People{
private:
float score;
public:
Student(char*, int, float);
void display();
};
//调用了基类的构造函数
Student::Student(char *name, int age, float score): People(name, age){ //People(name,age)是基类中的公共函数,此处也就是对它的初始化了,并且也是一次调用。形参可以直接给值
this->score = score;
}
void Student::display(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
} int main(){
Student stu("小明", , 90.5);
stu.display(); return ;
}
运行结果为:
小明的年龄是16,成绩是90.5
请注意代码第23行:
Student::Student(char *name, int age, float score): People(name, age)
这是派生类 Student 的构造函数的写法。冒号前面是派生类构造函数的头部,这和我们以前介绍的构造函数的形式一样,但它的形参列表包括了初始化基类和派生类的成员变量所需的数据;冒号后面是对基类构造函数的调用,这和普通构造函数的参数初始化表非常类似。
实际上,你可以将对基类构造函数的调用和参数初始化表放在一起,如下所示:
Student::Student(char *name, int age, float score): People(name, age), score(score){}
基类构造函数和初始化表用逗号隔开。
需要注意的是:冒号后面是对基类构造函数的调用,而不是声明,所以括号里的参数是实参,它们不但可以是派生类构造函数总参数表中的参数,还可以是局部变量、常量等。如下所示:
Student::Student(char *name, int age, float score): People("李磊", ) //是直接调用
基类构造函数调用规则
事实上,通过派生类创建对象时必须要调用基类的构造函数,这是语法规定。也就是说,定义派生类构造函数时最好指明基类构造函数;如果不指明,就调用基类的默认构造函数(不带参数的构造函数);如果没有默认构造函数,那么编译失败。
请看下面的例子:
#include<iostream>
using namespace std; //基类
class People{
protected:
char *name;
int age;
public:
People();
People(char*, int);
};
People::People(){
this->name = "xxx";
this->age = ;
}
People::People(char *name, int age): name(name), age(age){} //派生类
class Student: public People{
private:
float score;
public:
Student();
Student(char*, int, float);
void display();
};
Student::Student(){
this->score = 0.0;
}
Student::Student(char *name, int age, float score): People(name, age){
this->score = score;
}
void Student::display(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
} int main(){
Student stu1;
stu1.display(); Student stu2("小明", , 90.5);
stu2.display(); return ;
}
运行结果:
xxx的年龄是0,成绩是0
小明的年龄是16,成绩是90.5
创建对象 stu1 时,执行派生类的构造函数 Student::Student(),它并没有指明要调用基类的哪一个构造函数,从运行结果可以很明显地看出来,系统默认调用了不带参数的构造函数,也就是 People::People()。
创建对象 stu2 时,执行派生类的构造函数 Student::Student(char *name, int age, float score),它指明了基类的构造函数。
在第31行代码中,如果将 People(name, age) 去掉,也会调用默认构造函数,stu2.display() 的输出结果将变为:
xxx的年龄是0,成绩是90.5
如果将基类 People 中不带参数的构造函数删除,那么会发生编译错误,因为创建对象 stu1 时没有调用基类构造函数。
总结:如果基类有默认构造函数,那么在派生类构造函数中可以不指明,系统会默认调用;如果没有,那么必须要指明,否则系统不知道如何调用基类的构造函数。
构造函数的调用顺序
为了搞清这个问题,我们不妨先来看一个例子:
#include<iostream>
using namespace std; //基类
class People{
protected:
char *name;
int age;
public:
People();
People(char*, int);
};
People::People(): name("xxx"), age(){
cout<<"PeoPle::People()"<<endl;
}
People::People(char *name, int age): name(name), age(age){
cout<<"PeoPle::People(char *, int)"<<endl;
} //派生类
class Student: public People{
private:
float score;
public:
Student();
Student(char*, int, float);
};
Student::Student(): score(0.0){
cout<<"Student::Student()"<<endl;
}
Student::Student(char *name, int age, float score): People(name, age), score(score){
cout<<"Student::Student(char*, int, float)"<<endl;
} int main(){
Student stu1;
cout<<"--------------------"<<endl;
Student stu2("小明", , 90.5); return ;
}
运行结果:
PeoPle::People()
Student::Student() //这是第一次调用生成的,建立对象时只执行一个构造函数
--------------------
PeoPle::People(char *, int)
Student::Student(char*, int, float)
从运行结果可以清楚地看到,当创建派生类对象时,先调用基类构造函数,再调用派生类构造函数。如果继承关系有好几层的话,例如:
A --> B --> C
那么则创建C类对象时,构造函数的执行顺序为:
A类构造函数 --> B类构造函数 --> C类构造函数
构造函数的调用顺序是按照继承的层次自顶向下、从基类再到派生类的。
10)有子对象的派生类的构造函数
类的数据成员不但可以是标准型(如int、char)或系统提供的类型(如string),还可以包含类对象,如可以在声明一个类时包含这样的数据成员:
Student s1; //Student是已声明的类名,s1是Student类的对象
这时,s1就是类对象中的内嵌对象,称为子对象(subobject),即对象中的对象。
通过例子来说明问题。在例11.5(具体代码请查看:C++派生类的构造函数)中的派生类Studentl中,除了可以在派生类中要增加数据成员age和address外,还可以增加“班长”一项,即学生数据中包含他们的班长的姓名和其他基本情况,而班长本身也是学生,他也属于Student类型,有学号和姓名等基本数据,这样班长项就是派生类Student1中的子对象。在下面程序的派生类的数据成员中, 有一项monitor(班长),它是基类Student的对象,也就是派生类Student1的子对象。
那么,在对数据成员初始化时怎样对子对象初始化呢?请仔细分析下面程序,特别注意派生类构造函数的写法。
[例11.6] 包含子对象的派生类的构造函数。为了简化程序以易于阅读,这里设基类Student的数据成员只有两个,即num和name。
#include <iostream>
#include <string>
using namespace std;
class Student//声明基类
{
public: //公用部分
Student(int n, string nam ) //基类构造函数,与例11.5相同
{
num=n;
name=nam;
}
void display( ) //成员函数,输出基类数据成员
{
cout<<"num:"<<num<<endl<<"name:"<<name<<endl;
}
protected: //保护部分
int num;
string name;
};
class Student1: public Student //声明公用派生类Student1
{
public:
Student1(int n, string nam,int n1, string nam1,int a, string ad):Student(n,nam),monitor(n1,nam1) //派生类构造函数
{
age=a;
addr=ad;
}
void show( )
{
cout<<"This student is:"<<endl;
display(); //输出num和name
cout<<"age: "<<age<<endl; //输出age
cout<<"address: "<<addr<<endl<<endl; //输出addr
}
void show_monitor( ) //成员函数,输出子对象
{
cout<<endl<<"Class monitor is:"<<endl;
monitor.display( ); //调用基类成员函数
}
private: //派生类的私有数据
Student monitor; //定义子对象(班长) 还是个对象而已!是个对象就行,无所谓语法而已
int age;
string addr;
};
int main( )
{
Student1 stud1(,"Wang-li",,"Li-sun",,"115 Beijing Road,Shanghai");
stud1.show( ); //输出学生的数据
stud1.show_monitor(); //输出子对象的数据
return ;
}
运行时的输出如下:
This student is:
num: 10010
name: Wang-li
age: 19
address:115 Beijing Road,Shanghai
Class monitor is:
num:10001
name:Li-sun
请注意在派生类Student1中有一个数据成员:
Student monitor; //定义子对象 monitor(班长)
“班长”的类型不是简单类型(如int、char、float等),它是Student类的对象。我们知道, 应当在建立对象时对它的数据成员初始化。那么怎样对子对象初始化呢?显然不能在声明派生类时对它初始化(如Student monitor(10001, "Li-fun");),因为类是抽象类型,只是一个模型,是不能有具体的数据的,而且每一个派生类对象的子对象一般是不相同的(例如学生A、B、C的班长是A,而学生D、E、F的班长是F)。因此子对象的初始化是在建立派生类时通过调用派生类构造函数来实现的。
派生类构造函数的任务应该包括3个部分:
- 对基类数据成员初始化;
- 对子对象数据成员初始化;
- 对派生类数据成员初始化。
程序中派生类构造函数首部如下:
Student1(int n, string nam,int n1, string nam1,int a, string ad):
Student(n,nam),monitor(n1,nam1)
在上面的构造函数中有6个形参,前两个作为基类构造函数的参数,第3、第4个作为子对象构造函数的参数,第5、第6个是用作派生类数据成员初始化的。
归纳起来,定义派生类构造函数的一般形式为:
派生类构造函数名(总参数表列): 基类构造函数名(参数表列), 子对象名(参数表列)
{
派生类中新增数成员据成员初始化语句
}
执行派生类构造函数的顺序是:
- 调用基类构造函数,对基类数据成员初始化;
- 调用子对象构造函数,对子对象数据成员初始化;
- 再执行派生类构造函数本身,对派生类数据成员初始化。
派生类构造函数的总参数表列中的参数,应当包括基类构造函数和子对象的参数表列中的参数。基类构造函数和子对象的次序可以是任意的,如上面的派生类构造函数首部可以写成
Student1(int n, string nam,int n1, string nam1,int a, string ad): monitor(n1,nam1),Student(n,nam)
编译系统是根据相同的参数名(而不是根据参数的顺序)来确立它们的传递关系的。但是习惯上一般先写基类构造函数。
如果有多个子对象,派生类构造函数的写法依此类推,应列出每一个子对象名及其参数表列。
11)多层派生时的构造函数
一个类不仅可以派生出一个派生类,派生类还可以继续派生,形成派生的层次结构。在上面叙述的基础上,不难写出在多级派生情况下派生类的构造函数。
通过例下面的程序,读者可以了解在多级派生情况下怎样定义派生类的构造函数。相信大家完全可以自己看懂这个程序。
#include <iostream>
#include<string>
using namespace std;
class Student//声明基类
{
public://公用部分
Student(int n, string nam)//基类构造函数
{
num=n;
name=nam;
}
void display( )//输出基类数据成员
{
cout<<"num:"<<num<<endl;
cout<<"name:"<<name<<endl;
}
protected://保护部分
int num;//基类有两个数据成员
string name;
};
class Student1: public Student//声明公用派生类Student1
{
public:
Student1(int n,char nam[],int a):Student(n,nam)//派生类构造函数
{age=a;}//在此处只对派生类新增的数据成员初始化
void show( ) //输出num,name和age
{
display( ); //输出num和name
cout<<"age: "<<age<<endl;
}
private://派生类的私有数据
int age; //增加一个数据成员
};
class Student2:public Student1 //声明间接公用派生类Student2
{
public://下面是间接派生类构造函数
Student2(int n, string nam,int a,int s):Student1(n,nam,a) {score=s;}
void show_all( ) //输出全部数据成员
{
show( ); //输出num和name
cout<<"score:"<<score<<endl; //输出age
}
private:
int score; //增加一个数据成员
};
int main( )
{
Student2 stud(,"Li",,);
stud.show_all( ); //输出学生的全部数据
return ;
}
运行时的输出如下:
num:10010
name:Li
age:17
score:89
请注意基类和两个派生类的构造函数的写法。
基类的构造函数首部:
Student(int n, string nam)
派生类Student1的构造函数首部:
Student1(int n, string nam],int a):Student(n,nam)
派生类Student2的构造函数首部:
Student2(int n, string nam,int a,int s):Student1(n,nam,a)
注意不要写成:
Student2(int n, string nam,int a,int s):Student1(n,nam),student1(n, nam, a)
不要列出每一层派生类的构造函数,只需写出其上一层派生类(即它的直接基类)的构造函数即可。在声明Student2类对象时,调用Student2构造函数;在执行Student2构造函数时,先调用Student1构造函数;在执行Student1构造函数时,先调用基类Student构造函数。初始化的顺序是:
- 先初始化基类的数据成员num和name。
- 再初始化Student1的数据成员age。
- 最后再初始化Student2的数据成员score。
12)派生类构造函数的特殊形式
在使用派生类构造函数时,有以下特殊的形式。
1) 当不需要对派生类新增的成员进行任何初始化操作时,派生类构造函数的函数体可以为空,即构造函数是空函数,如例11.6(具体代码请查看:C++有子对象的派生类的构造函数)程序中派生类Student1构造函数可以改写为:
Student1(int n, strin nam,int n1, strin nam1): Student(n,nam),monitor(n1,nam1) { }
可以看到,函数体为空。此时,派生类构造函数的参数个数等于基类构造函数和子对象的参数个数之和,派生类构造函数的全部参数都传递给基类构造函数和子对象,在调用派生类构造函数时不对派生类的数据成员初始化。此派生类构造函数的作用只是为了将参数传递给基类构造函数和子对象,并在执行派生类构造函数时调用基类构造函数和子对象构造函数。在实际工作中常见这种用法。
2) 如果在基类中没有定义构造函数,或定义了没有参数的构造函数,那么在定义派生类构造函数时可不写基类构造函数。因为此时派生类构造函数没有向基类构造函数传递参数的任务。调用派生类构造函数时系统会自动首先调用基类的默认构造函数。
如果在基类和子对象类型的声明中都没有定义带参数的构造函数,而且也不需对派生类自己的数据成员初始化,则可以不必显式地定义派生类构造函数。因为此时派生类构造函数既没有向基类构造函数和子对象构造函数传递参数的任务,也没有对派生类数据成员初始化的任务。
在建立派生类对象时,系统会自动调用系统提供的派生类的默认构造函数,并在执行派生类默认构造函数的过程中,调用基类的默认构造函数和子对象类型默认构造函数。
如果在基类或子对象类型的声明中定义了带参数的构造函数,那么就必须显式地定义派生类构造函数,并在派生类构造函数中写出基类或子对象类型的构造函数及其参数表。
如果在基类中既定义无参的构造函数,又定义了有参的构造函数(构造函数重载),则在定义派生类构造函数时,既可以包含基类构造函数及其参数,也可以不包含基类构造函数。
在调用派生类构造函数时,根据构造函数的内容决定调用基类的有参的构造函数还是无参的构造函数。编程者可以根据派生类的需要决定采用哪一种方式。
13)派生类的析构函数
和构造函数类似,析构函数也是不能被继承的。
创建派生类对象时,构造函数的调用顺序和继承顺序相同,先执行基类构造函数,然后再执行派生类的构造函数。但是对于析构函数,调用顺序恰好相反,即先执行派生类的析构函数,然后再执行基类的析构函数(但会有一定的语法关系,导致不是完全倒序)。
请看下面的例子:
#include <iostream>
using namespace std; class A{
public:
A(){cout<<"A constructor"<<endl;}
~A(){cout<<"A destructor"<<endl;}
}; class B: public A{
public:
B(){cout<<"B constructor"<<endl;}
~B(){cout<<"B destructor"<<endl;}
}; class C: public B{
public:
C(){cout<<"C constructor"<<endl;}
~C(){cout<<"C destructor"<<endl;}
}; int main(){
C test;
return ;
}
运行结果:
A constructor
B constructor
C constructor
C destructor
B destructor
A destructor
从运行结果可以很明显地看出来,构造函数和析构函数的执行顺序是相反的。
需要注意的是,一个类只能有一个析构函数,调用时不会出现二义性,所以析构函数不需要显式地调用。
14)类的多继承
在前面的例子中,派生类都只有一个基类,称为单继承。除此之外,C++也支持多继承,即一个派生类可以有两个或多个基类。
多继承容易让代码逻辑复杂、思路混乱,一直备受争议,中小型项目中较少使用,后来的 Java、C#、PHP 等干脆取消了多继承。想快速学习C++的读者可以不必细读。
多继承的语法也很简单,将多个基类用逗号隔开即可。例如已声明了类A、类B和类C,那么可以这样来声明派生类D:
class D: public A, private B, protected C{
//类D新增加的成员
}
D是多继承的派生类,它以共有的方式继承A类,以私有的方式继承B类,以保护的方式继承C类。D根据不同的继承方式获取A、B、C中的成员,确定各基类的成员在派生类中的访问权限。
D获取了 A、B、C不同的资源,可以叫做吸心大法
多继承下的构造函数
多继承派生类的构造函数和单继承类基本相同,只是要包含多个基类构造函数。如:
D类构造函数名(总参数表列): A构造函数(实参表列), B类构造函数(实参表列), C类构造函数(实参表列){
新增成员初始化语句
}
各基类的排列顺序任意。
派生类构造函数的执行顺序同样为:先调用基类的构造函数,再调用派生类构造函数。基类构造函数的调用顺序是按照声明派生类时基类出现的顺序。
下面的定义了两个基类,BaseA类和BaseB类,然后用多继承的方式派生出Sub类。
#include <iostream>
using namespace std; //基类
class BaseA{
protected:
int a;
int b;
public:
BaseA(int, int);
};
BaseA::BaseA(int a, int b): a(a), b(b){} //基类
class BaseB{
protected:
int c;
int d;
public:
BaseB(int, int);
};
BaseB::BaseB(int c, int d): c(c), d(d){} //派生类
class Sub: public BaseA, public BaseB{
private:
int e;
public:
Sub(int, int, int, int, int);
void display();
};
Sub::Sub(int a, int b, int c, int d, int e): BaseA(a, b), BaseB(c, d), e(e){}
void Sub::display(){
cout<<"a="<<a<<endl;
cout<<"b="<<b<<endl;
cout<<"c="<<c<<endl;
cout<<"d="<<d<<endl;
cout<<"e="<<e<<endl;
} int main(){
(new Sub(, , , , )) -> display();
return ;
}
运行结果:
a=1
b=2
c=3
d=4
e=5
从基类BaseA和BaseB继承来的成员变量,在 Sub::display() 中都可以访问。
命名冲突
当两个基类中有同名的成员时,就会产生命名冲突,这时不能直接访问该成员,需要加上类名和域解析符。
假如在基类BaseA和BaseB中都有成员函数 display(),那么下面的语句是错误的:
Sub obj;
obj.display();
由于BaseA和BaseB中都有display(),系统将无法判定到底要调用哪一个类的函数,所以报错。
应该像下面这样加上类名和域解析符:
Sub obj;
obj.BaseA::display();
obj.BaseB::display();
通过这个举例可以发现:在多重继承时,从不同的基类中会继承一些重复的数据。如果有多个基类,问题会更突出,所以在设计派生类时要细致考虑其数据成员,尽量减少数据冗余。
15)多重继承的二义性问题
多重继承可以反映现实生活中的情况,能够有效地处理一些较复杂的问题,使编写程序具有灵活性,但是多重继承也引起了一些值得注意的问题,它增加了程序的复杂度,使 程序的编写和维护变得相对困难,容易出错。其中最常见的问题就是继承的成员同名而产生的二义性(ambiguous)问题。
如果类A和类B中都有成员函数display和数据成员a,类C是类A和类B的直接派生类。分别讨论下列3种情况。
1) 两个基类有同名成员
代码如下所示:
class A
{
public:
int a;
void display();
}; class B
{
public:
int a;
void display ();
}; class C: public A, public B
{
public:
int b;
void show();
};
如果在main函数中定义C类对象cl,并调用数据成员a和成员函数display :
C cl;
cl.a=3;
cl.display();
由于基类A和基类B都有数据成员a和成员函数display,编译系统无法判别要访问的是哪一个基类的成员,因此程序编译出错。那么,应该怎样解决这个问题呢?可以用基类名来限定:
cl.A::a=3; //引用cl对象中的基类A的数据成员a
cl.A::display(); //调用cl对象中的基类A的成员函数display
如果是在派生类C中通过派生类成员函数show访问基类A的display和a,可以不 必写对象名而直接写
A::a = 3; //指当前对象
A::display();
2) 两个基类和派生类三者都有同名成员
将上面的C类声明改为:
class C: public A, public B
{
int a;
void display();
};
如果在main函数中定义C类对象cl,并调用数据成员a和成员函数display:
C cl;
cl.a = 3;
cl.display();
此时,程序能通过编译,也可以正常运行。请问:执行时访问的是哪一个类中的成员?答案是:访问的是派生类C中的成员。规则是:基类的同名成员在派生类中被屏蔽,成为“不可见”的,或者说,派生类新增加的同名成员覆盖了基类中的同名成员。因此如果在定义派生类对象的模块中通过对象名访问同名的成员,则访问的是派生类的成员。请注意:不同的成员函数,只有在函数名和参数个数相同、类型相匹配的情况下才发生同名覆盖,如果只有函数名相同而参数不同,不会发生同名覆盖,而属于函数重载。
有些读者可能对同名覆盖感到不大好理解。为了说明问题,举个例子,例如把中国作为基类,四川则是中国的派生类,成都则是四川的派生类。基类是相对抽象的,派生类是相对具体的,基类处于外层,具有较广泛的作用域,派生类处于内层,具有局部的作用域。若“中国”类中有平均温度这一属性,四川和成都也都有平均温度这一属性,如果没有四川和成都这两个派生类,谈平均温度显然是指全国平均温度。如果在四川,谈论当地的平均温度显然是指四川的平均温度;如果在成都,谈论当地的平均温度显然是指成都的平均温度。这就是说,全国的“平均温度”在四川省被四川的“平均温度”屏蔽了,或者说,四川的“平均温度”在当地屏蔽了全国的“平均温度”。四川人最关心的是四川的温度,当然不希望用全国温度覆盖四川的平均温度。
如果在四川要查全国平均温度,一定要声明:我要查的是全国的平均温度。同样,要在派生类外访问基类A中的成员,应指明作用域A,写成以下形式:
cl.A::a=3; //表示是派生类对象cl中的基类A中的数据成员a
cl.A::display(); //表示是派生类对象cl中的基类A中的成员函数display
3) 类A和类B是从同一个基类派生的
代码如下所示:
class N
{
public:
int a;
void display(){ cout<<"A::a="<<a<<endl; }
}; class A: public N
{
public:
int al;
}; class B: public N
{
public:
int a2;
}; class C: public A, public B
{
public:
int a3;
void show(){ cout<<"a3="<<a3<<endl; }
} int main()
{
C cl; //定义C类对象cl
// 其他代码
}
在类A和类B中虽然没有定义数据成员a和成员函数display,但是它们分别从类N继承了数据成员a和成员函数display,这样在类A和类B中同时存在着两个同名的数据成员a和成员函数display。它们是N类成员的拷贝。类A和类B中的数据成员a代表两个不同的存储单元,可以分别存放不同的数据。在程序中可以通过类A和类B的构造函数去调用基类N的构造函数,分别对类A和类B的数据成员a初始化。
怎样才能访问类A中从基类N继承下来的成员呢?显然不能用
cl.a = 3; cl.display();
或
cl.N::a = 3; cl. N::display(); 无法得到获取途径
因为这样依然无法区别是类A中从基类N继承下来的成员,还是类B中从基类N继承下来的成员。应当通过类N的直接派生类名来指出要访问的是类N的哪一个派生类中的基类成员。如
cl.A::a=3; cl.A::display(); //要访问的是类N的派生类A中的基类成员
16)虚基类
多继承时很容易产生命名冲突,即使我们很小心地将所有类中的成员变量和成员函数都命名为不同的名字,命名冲突依然有可能发生,比如非常经典的菱形继承层次。如下图所示:
类A派生出类B和类C,类D继承自类B和类C,这个时候类A中的成员变量和成员函数继承到类D中变成了两份,一份来自 A-->B-->D 这一路,另一份来自 A-->C-->D 这一条路。
在一个派生类中保留间接基类的多份同名成员,虽然可以在不同的成员变量中分别存放不同的数据,但大多数情况下这是多余的:因为保留多份成员变量不仅占用较多的存储空间,还容易产生命名冲突,而且很少有这样的需求。
为了解决这个问题,C++提供了虚基类,使得在派生类中只保留间接基类的一份成员。
声明虚基类只需要在继承方式前面加上 virtual 关键字,请看下面的例子:
#include <iostream>
using namespace std; class A{
protected:
int a;
public:
A(int a):a(a){}
}; class B: virtual public A{ //声明虚基类
protected:
int b;
public:
B(int a, int b):A(a),b(b){}
}; class C: virtual public A{ //声明虚基类
protected:
int c;
public:
C(int a, int c):A(a),c(c){}
}; class D: virtual public B, virtual public C{ //声明虚基类
private:
int d;
public:
D(int a, int b, int c, int d):A(a),B(a,b),C(a,c),d(d){}
void display();
};
void D::display(){
cout<<"a="<<a<<endl;
cout<<"b="<<b<<endl;
cout<<"c="<<c<<endl;
cout<<"d="<<d<<endl;
} int main(){
(new D(, , , )) -> display();
return ;
}
运行结果:
a=1
b=2
c=3
d=4
本例中我们使用了虚基类,在派生类D中只有一份成员变量 a 的拷贝,所以在 display() 函数中可以直接访问 a,而不用加类名和域解析符。
请注意派生类D的构造函数,与以往的用法有所不同。以往,在派生类的构造函数中只需负责对其直接基类初始化,再由其直接基类负责对间接基类初始化。现在,由于虚基类在派生类中只有一份成员变量,所以对这份成员变量的初始化必须由派生类直接给出。如果不由最后的派生类直接对虚基类初始化,而由虚基类的直接派生类(如类B和类C)对虚基类初始化,就有可能由于在类B和类C的构造函数中对虚基类给出不同的初始化参数而产生矛盾。所以规定:在最后的派生类中不仅要负责对其直接基类进行初始化,还要负责对虚基类初始化。
有的读者会提出:类D的构造函数通过初始化表调了虚基类的构造函数A,而类B和类C的构造函数也通过初始化表调用了虚基类的构造函数A,这样虚基类的构造函数岂非被调用了3次?大家不必过虑,C++编译系统只执行最后的派生类对虚基类的构造函数的调用,而忽略虚基类的其他派生类(如类B和类C)对虚基类的构造函数的调用,这就保证了虚基类的数据成员不会被多次初始化。
最后请注意:为了保证虚基类在派生类中只继承一次,应当在该基类的所有直接派生类中声明为虚基类,否则仍然会出现对基类的多次继承。
可以看到:使用多重继承时要十分小心,经常会出现二义性问题。上面的例子是简单的,如果派生的层次再多一些,多重继承更复杂一些,程序员就很容易陷人迷 魂阵,程序的编写、调试和维护工作都会变得更加困难。因此很多程序员不提倡在程序中使用多重继承,只有在比较简单和不易出现二义性的情况或实在必要时才使用多重继承,能用单一继承解决的问题就不要使用多重继承。也正由于这个原因,C++之后的很多面向对象的编程语言(如Java、Smalltalk、C#、PHP等)并不支持多重继承。
虚基类并不是不占地址,只是保证了类似于菱形继承数据的独立性;
17)基类与派生类的转换
在公用继承、私有继承和保护继承中,只有公用继承能较好地保留基类的特征,它保留了除构造函数和析构函数以外的基类所有成员,基类的公用或保护成员的访问权限在派生类中全部都按原样保留下来了,在派生类外可以调用基类的公用成员函数访问基类的私有成员。因此,公用派生类具有基类的全部功能,所有基类能够实现的功能, 公用派生类都能实现。而非公用派生类(私有或保护派生类)不能实现基类的全部功能(例如在派生类外不能调用基类的公用成员函数访问基类的私有成员)。因此,只有公用派生类才是基类真正的子类型,它完整地继承了基类的功能。
不同类型数据之间在一定条件下可以进行类型的转换,例如整型数据可以赋给双精度型变量,在赋值之前,把整型数据先转换成为双精度型数据,但是不能把一个整型数据赋给指针变量。这种不同类型数据之间的自动转换和赋值,称为赋值兼容。现在要讨论 的问题是:基类与派生类对象之间是否也有赋值兼容的关系,可否进行类型间的转换?
回答是可以的。基类与派生类对象之间有赋值兼容关系,由于派生类中包含从基类继承的成员,因此可以将派生类的值赋给基类对象,在用到基类对象的时候可以用其子类对象代替。具体表现在以下几个方面。
1) 派生类对象可以向基类对象赋值
可以用子类(即公用派生类)对象对其基类对象赋值。如
A a1; //定义基类A对象a1
B b1; //定义类A的公用派生类B的对象b1
a1=b1; //用派生类B对象b1对基类对象a1赋值
在赋值时舍弃派生类自己的成员。也就是“大材小用”,如图11.26所示。

图 11.26
实际上,所谓赋值只是对数据成员赋值,对成员函数不存在赋值问题。
请注意,赋值后不能企图通过对象a1去访问派生类对象b1的成员,因为b1的成员与a1的成员是不同的。假设age是派生类B中增加的公用数据成员,分析下面的用法:
a1.age=23; //错误,a1中不包含派生类中增加的成员
b1.age=21; //正确,b1中包含派生类中增加的成员
应当注意,子类型关系是单向的、不可逆的。B是A的子类型,不能说A是B的子类型。只能用子类对象对其基类对象赋值,而不能用基类对象对其子类对象赋值,理由是显然的,因为基类对象不包含派生类的成员,无法对派生类的成员赋值。同理,同一基类的不同派生类对象之间也不能赋值。
2) 派生类对象可以替代基类对象向基类对象的引用进行赋值或初始化
如已定义了基类A对象a1,可以定义a1的引用变量:
A a1; //定义基类A对象a1
B b1; //定义公用派生类B对象b1
A& r=a1; //定义基类A对象的引用变量r,并用a1对其初始化
这时,引用变量r是a1的别名,r和a1共享同一段存储单元。也可以用子类对象初始化引用变量r,将上面最后一行改为
A& r=b1; //定义基类A对象的引用变量r,并用派生类B对象b1对其初始化
或者保留上面第3行“A& r=a1;”,而对r重新赋值:
r=b1; //用派生类B对象b1对a1的引用变量r赋值
注意,此时r并不是b1的别名,也不与b1共享同一段存储单元。它只是b1中基类部分的别名,r与b1中基类部分共享同一段存储单元,r与b1具有相同的起始地址。
3) 如果函数的参数是基类对象或基类对象的引用,相应的实参可以用子类对象。
如有一函数:
fun: void fun(A& r) //形参是类A的对象的引用变量
{
cout<<r.num<<endl;
} //输出该引用变量的数据成员num
函数的形参是类A的对象的引用变量,本来实参应该为A类的对象。由于子类对象与派生类对象赋值兼容,派生类对象能自动转换类型,在调用fun函数时可以用派生类B的对象b1作实参:
fun(b1);
输出类B的对象b1的基类数据成员num的值。
与前相同,在fun函数中只能输出派生类中基类成员的值。
4) 派生类对象的地址可以赋给指向基类对象的指针变量,也就是说,指向基类对象的指针变量也可以指向派生类对象。
[例11.10] 定义一个基类Student(学生),再定义Student类的公用派生类Graduate(研究生), 用指向基类对象的指针输出数据。本例主要是说明用指向基类对象的指针指向派生类对象,为了减少程序长度,在每个类中只设很少成员。学生类只设num(学号),name(名字)和score(成绩)3个数据成员,Graduate类只增加一个数据成员pay(工资)。程序如下:
#include <iostream>
#include <string>
using namespace std;
class Student//声明Student类
{
public:
Student(int, string,float); //声明构造函数
void display( ); //声明输出函数
private:
int num;
string name;
float score;
}; Student::Student(int n, string nam,float s) //定义构造函数
{
num=n;
name=nam;
score=s;
} void Student::display( ) //定义输出函数
{
cout<<endl<<"num:"<<num<<endl;
cout<<"name:"<<name<<endl;
cout<<"score:"<<score<<endl;
} class Graduate:public Student //声明公用派生类Graduate
{
public:
Graduate(int, string ,float,float); //声明构造函数
void display( ); //声明输出函数
private:
float pay; //工资
}; //定义构造函数
Graduate::Graduate(int n, string nam,float s,float p):Student(n,nam,s),pay(p){ }
void Graduate::display() //定义输出函数
{
Student::display(); //调用Student类的display函数
cout<<"pay="<<pay<<endl;
} int main()
{
Student stud1(,"Li",87.5); //定义Student类对象stud1
Graduate grad1(,"Wang",98.5,563.5); //定义Graduate类对象grad1
Student *pt=&stud1; //定义指向Student类对象的指针并指向stud1
pt->display( ); //调用stud1.display函数
pt=&grad1; //指针指向grad1
pt->display( ); //调用grad1.display函数
}
下面对程序的分析很重要,请大家仔细阅读和思考。
很多读者会认为,在派生类中有两个同名的display成员函数,根据同名覆盖的规则,被调用的应当是派生类Graduate对象的display函数,在执行Graduate::display函数过程中调用Student::display函数,输出num,name,score,然后再输出pay的值。
事实上这种推论是错误的,先看看程序的输出结果:
num:1001
name:Li
score:87.5
num:2001
name:wang
score:98.5
前3行是学生stud1的数据,后3行是研究生grad1的数据,并没有输出pay的值。
问题在于pt是指向Student类对象的指针变量,即使让它指向了grad1,但实际上pt指向的是grad1中从基类继承的部分。(可能是空间长度不够)
通过指向基类对象的指针,只能访问派生类中的基类成员,而不能访问派生类增加的成员。所以pt->display()调用的不是派生类Graduate对象所增加的display函数,而是基类的display函数,所以只输出研究生grad1的num,name,score3个数据。
如果想通过指针输出研究生grad1的pay,可以另设一个指向派生类对象的指针变量ptr,使它指向grad1,然后用ptr->display()调用派生类对象的display函数。但这不大方便。
通过本例可以看到,用指向基类对象的指针变量指向子类对象是合法的、安全的,不会出现编译上的错误。但在应用上却不能完全满足人们的希望,人们有时希望通过使用基类指针能够调用基类和子类对象的成员。如果能做到这点,程序人员会感到方便。后续章节将会解决这个问题。办法是使用虚函数和多态性。
18)继承与组合详解
我们知道,在一个类中可以用类对象作为数据成员,即子对象(详情请查看:C++有子对象的派生类的构造函数)。实际上,对象成员的类型可以是本派生类的基类,也可以是另外一个已定义的类。在一个类中以另一个类的对象作为数据成员的,称为类的组合(composition)。
例如,声明Professor(教授)类是Teacher(教师)类的派生类,另有一个类BirthDate(生日),包含year,month,day等数据成员。可以将教授生日的信息加入到Professor类的声明中。如:
class Teacher //教师类
{
public:
// Some Code
private:
int num;
string name;
char sex;
};
class BirthDate //生日类
{
public:
// Some Code
private:
int year;
int month;
int day;
};
class Professor:public Teacher //教授类
{
public:
// Some Code
private:
BirthDate birthday; //BirthDate类的对象作为数据成员 前面的写法是用过的
};
类的组合和继承一样,是软件重用的重要方式。组合和继承都是有效地利用已有类的资源。但二者的概念和用法不同。通过继承建立了派生类与基类的关系,它是一种 “是”的关系,如“白猫是猫”,“黑人是人”,派生类是基类的具体化实现,是基类中的一 种。通过组合建立了成员类与组合类(或称复合类)的关系,在本例中BirthDate是成员类,Professor是组合类(在一个类中又包含另一个类的对象成员)。它们之间不是‘‘是”的 关系,而是“有”的关系。不能说教授(Professor)是一个生日(BirthDate),只能说教授(Professor)有一个生日(BirthDate)的属性。
Professor类通过继承,从Teacher类得到了num,name,age,sex等数据成员,通过组合,从BirthDate类得到了year,month,day等数据成员。继承是纵向的,组合是横向的。
如果定义了Professor对象prof1,显然prof1包含了生日的信息。通过这种方法有效地组织和利用现有的类,大大减少了工作量。如果有
void fun1(Teacher &);
void fun2(BirthDate &);
在main函数中调用这两个函数:
fun1(prof1); //正确,形参为Teacher类对象的引用,实参为Teacher类的子类对象,与之赋值兼容
fun2(prof1.birthday); //正确,实参与形参类型相同,都是BirthDate类对象
fun2(prof1); //错误,形参要求是BirthDate类对象,而prof1是Professor类型,不匹配
如果修改了成员类的部分内容,只要成员类的公用接口(如头文件名)不变,如无必要,组合类可以不修改。但组合类需要重新编译。
十一.多态性的概念和纯虚数的定义
1)多态性的概念
多态性(polymorphism)是面向对象程序设计的一个重要特征。如果一种语言只支持类而不支持多态,是不能被称为面向对象语言的,只能说是基于对象的,如Ada、VB就属此类。C++支持多态性,在C++程序设计中能够实现多态性。利用多态性可以设计和实现一个易于扩展的系统。
顾名思义,多态的意思是一个事物有多种形态。多态性的英文单词polymorphism来源于希腊词根poly(意为“很多”)和morph(意为“形态”)。在C ++程序设计中,多态性是指具有不同功能的函数可以用同一个函数名,这样就可以用一个函数名调用不同内容的函数。在面向对象方法中一般是这样表述多态性的:向不同的对象发送同一个消息, 不同的对象在接收时会产生不同的行为(即方法)。也就是说,每个对象可以用自己的方式去响应共同的消息。所谓消息,就是调用函数,不同的行为就是指不同的实现,即执行不同的函数。
其实,我们已经多次接触过多态性的现象,例如函数的重载、运算符重载都是多态现象。只是那时没有用到多态性这一专门术语而已。例如,使用运算符“+”使两个数值相加,就是发送一个消息,它要调用operator +函数。实际上,整型、单精度型、双精度型的加法操作过程是互不相同的,是由不同内容的函数实现的。显然,它们以不同的行为或方法来响应同一消息。
在现实生活中可以看到许多多态性的例子。如学校校长向社会发布一个消息:9月1日新学年开学。不同的对象会作出不同的响应:学生要准备好课本准时到校上课;家长要筹集学费;教师要备好课;后勤部门要准备好教室、宿舍和食堂……由于事先对各种人的任务已作了规定,因此,在得到同一个消息时,各种人都知道自己应当怎么做,这就是 多态性。可以设想,如果不利用多态性,那么校长就要分别给学生、家长、教师、后勤部门等许多不同的对象分别发通知,分别具体规定每一种人接到通知后应该怎么做。显然这是一件十分复杂而细致的工作。一人包揽一切,吃力还不讨好。现在,利用了多态性机制,校长在发布消息时,不必一一具体考虑不同类型人员是怎样执行的。至于各类人员在接到消息后应气做什么,并不是临时决定的,而是学校的工作机制事先安排决定好的。校长只需不断发布各种消息,各种人员就会按预定方案有条不紊地工作。
同样,在C++程序设计中,在不同的类中定义了其响应消息的方法,那么使用这些类 时,不必考虑它们是什么类型,只要发布消息即可。正如在使用运算符“ ”时不必考虑相加的数值是整型、单精度型还是双精度型,直接使用“+”,不论哪类数值都能实现相加。可以说这是以不变应万变的方法,不论对象千变万化,用户都是用同一形式的信息去调用它们,使它们根据事先的安排作出反应。
从系统实现的角度看,多态性分为两类:静态多态性和动态多态性。以前学过的函数重载和运算符重载实现的多态性属于静态多态性,在程序编译时系统就能决定调用的是哪个函数,因此静态多态性又称编译时的多态性。静态多态性是通过函数的重载实现的(运算符重载实质上也是函数重载)。动态多态性是在程序运行过程中才动态地确定操作所针对的对象。它又称运行时的多态性。动态多态性是通过虚函数(Virtual fiinction)实现的。
有关静态多态性的应用,即函数的重载(请查看:C++函数重载)和运算符重载(请查看:C++运算符重载),已经介绍过了,这里主要介绍动态多态性和虚函数。要研究的问题是:当一个基类被继承为不同的派生类时,各派生类可以使用与基类成员相同的成员名,如果在运行时用同一个成员名调用类对象的成员,会调用哪个对象的成员?也就是说,通过继承而产生了相关的不同的派生类,与基类成员同名的成员在不同的派生类中有不同的含义。也可以说,多态性是“一个接口,多种 方法”。
例子:
下面是一个承上启下的例子。一方面它是有关继承和运算符重载内容的综合应用的例子,通过这个例子可以进一步融会贯通前面所学的内容,另一方面又是作为讨论多态性的一个基础用例。
希望大家耐心、深入地阅读和消化这个程序,弄清其中的每一个细节。
[例12.1] 先建立一个Point(点)类,包含数据成员x,y(坐标点)。以它为基类,派生出一个Circle(圆)类,增加数据成员r(半径),再以Circle类为直接基类,派生出一个Cylinder(圆柱体)类,再增加数据成员h(高)。要求编写程序,重载运算符“<<”和“>>”,使之能用于输出以上类对象。
这个例题难度不大,但程序很长。对于一个比较大的程序,应当分成若干步骤进行。先声明基类,再声明派生类,逐级进行,分步调试。
1) 声明基类Point
类可写出声明基类Point的部分如下:
#include <iostream>
//声明类Point
class Point
{
public:
Point(float x=,float y=); //有默认参数的构造函数
void setPoint(float ,float); //设置坐标值
float getX( )const {return x;} //读x坐标
float getY( )const {return y;} //读y坐标
friend ostream & operator <<(ostream &,const Point &); //重载运算符“<<”
protected: //受保护成员
float x, y;
};
//下面定义Point类的成员函数
Point::Point(float a,float b) //Point的构造函数
{ //对x,y初始化
x=a;
y=b;
}
void Point::setPoint(float a,float b) //设置x和y的坐标值
{ //为x,y赋新值
x=a;
y=b;
}
//重载运算符“<<”,使之能输出点的坐标
ostream & operator <<(ostream &output, const Point &p)
{
output<<"["<<p.x<<","<<p.y<<"]"<<endl;
return output;
}
以上完成了基类Point类的声明。
为了提高程序调试的效率,提倡对程序分步调试,不要将一个长的程序都写完以后才统一调试,那样在编译时可能会同时出现大量的编译错误,面对一个长的程序,程序人员往往难以迅速准确地找到出错位置。要善于将一个大的程序分解为若干个文件,分别编译,或者分步调试,先通过最基本的部分,再逐步扩充。
现在要对上面写的基类声明进行调试,检查它是否有错,为此要写出main函数。实际上它是一个测试程序。
int main( )
{
Point p(3.5,6.4); //建立Point类对象p
cout<<"x="<<p.getX( )<<",y="<<p.getY( )<<endl; //输出p的坐标值
p.setPoint(8.5,6.8); //重新设置p的坐标值
cout<<"p(new):"<<p<<endl; //用重载运算符“<<”输出p点坐标
return ;
}
getX和getY函数声明为常成员函数,作用是只允许函数引用类中的数据,而不允许修改它们,以保证类中数据的安全。数据成员x和y声明为protected,这样可以被派生类访问(如果声明为private,派生类是不能访问的)。
程序编译通过,运行结果为:
x=3.5,y=6.4
p(new):[8.5,6.8]
测试程序检查了基类中各函数的功能,以及运算符重载的作用,证明程序是正确的。
2)声明派生类Circle
在上面的基础上,再写出声明派生类Circle的部分:
class Circle:public Point //circle是Point类的公用派生类
{
public:
Circle(float x=,float y=,float r=); //构造函数
void setRadius(float ); //设置半径值
float getRadius( )const; //读取半径值
float area ( )const; //计算圆面积
friend ostream &operator <<(ostream &,const Circle &); //重载运算符“<<”
private:
float radius;
};
//定义构造函数,对圆心坐标和半径初始化
Circle::Circle(float a,float b,float r):Point(a,b),radius(r){}
//设置半径值
void Circle::setRadius(float r){radius=r;}
//读取半径值
float Circle::getRadius( )const {return radius;}
//计算圆面积
float Circle::area( )const
{
return 3.14159*radius*radius;
}
//重载运算符“<<”,使之按规定的形式输出圆的信息
ostream &operator <<(ostream &output,const Circle &c)
{
output<<"Center=["<<c.x<<","<<c.y<<"],r="<<c.radius<<",area="<<c.area( )<<endl;
return output;
}
为了测试以上Circle类的定义,可以写出下面的主函数:
int main( )
{
Circle c(3.5,6.4,5.2); //建立Circle类对象c,并给定圆心坐标和半径
cout<<"original circle:\\nx="<<c.getX()<<", y="<<c.getY()<<", r="<<c.getRadius( )<<", area="<<c.area( )<<endl; //输出圆心坐标、半径和面积
c.setRadius(7.5); //设置半径值
c.setPoint(,); //设置圆心坐标值x,y
cout<<"new circle:\\n"<<c; //用重载运算符“<<”输出圆对象的信息
Point &pRef=c; //pRef是Point类的引用变量,被c初始化
cout<<"pRef:"<<pRef; //输出pRef的信息
return ;
}
程序编译通过,运行结果为:
original circle:(输出原来的圆的数据)
x=3.5, y=6.4, r=5.2, area=84.9486
new circle:(输出修改后的圆的数据)
Center=[5,5], r=7.5, area=176.714
pRef:[5,5] (输出圆的圆心“点”的数据)
可以看到,在Point类中声明了一次运算符“ <<”重载函数,在Circle类中又声明了一次运算符“ <<”,两次重载的运算符“<<”内容是不同的,在编译时编译系统会根据输出项的类型确定调用哪一个运算符重载函数。main函数第7行用“cout<< ”输出c,调用的是在Circle类中声明的运算符重载函数。
请注意main函数第8行:
Point & pRef = c;
定义了 Point类的引用变量pRef,并用派生类Circle对象c对其初始化。前面我们已经讲过,派生类对象可以替代基类对象为基类对象的引用初始化或赋值(详情请查看:C++基类与派生类的转换)。现在 Circle是Point的公用派生类,因此,pRef不能认为是c的别名,它得到了c的起始地址, 它只是c中基类部分的别名,与c中基类部分共享同一段存储单元。所以用“cout<<pRef”输出时,调用的不是在Circle中声明的运算符重载函数,而是在Point中声明的运算符重载函数,输出的是“点”的信息,而不是“圆”的信息。
3) 声明Circle的派生类Cylinder
前面已从基类Point派生出Circle类,现在再从Circle派生出Cylinder类。
class Cylinder:public Circle// Cylinder是Circle的公用派生类
{
public:
Cylinder (float x=,float y=,float r=,float h=); //构造函数
void setHeight(float ); //设置圆柱高
float getHeight( )const; //读取圆柱高
loat area( )const; //计算圆表面积
float volume( )const; //计算圆柱体积
friend ostream& operator <<(ostream&,const Cylinder&); //重载运算符<<
protected:
float height;//圆柱高
};
//定义构造函数
Cylinder::Cylinder(float a,float b,float r,float h):Circle(a,b,r),height(h){}
//设置圆柱高
void Cylinder::setHeight(float h){height=h;}
//读取圆柱高
float Cylinder::getHeight( )const {return height;}
//计算圆表面积
float Cylinder::area( )const { return *Circle::area( )+*3.14159*radius*height;}
//计算圆柱体积
float Cylinder::volume()const {return Circle::area()*height;}
ostream &operator <<(ostream &output,const Cylinder& cy)
{
output<<"Center=["<<cy.x<<","<<cy.y<<"],r="<<cy.radius<<",h="<<cy.height <<"\\narea="<<cy.area( )<<", volume="<<cy.volume( )<<endl;
return output;
} //重载运算符“<<”
可以写出下面的主函数:
int main( )
{
Cylinder cy1(3.5,6.4,5.2,);//定义Cylinder类对象cy1
cout<<"\\noriginal cylinder:\\nx="<<cy1.getX( )<<", y="<<cy1.getY( )<<", r="
<<cy1.getRadius( )<<", h="<<cy1.getHeight( )<<"\\narea="<<cy1.area()
<<",volume="<<cy1.volume()<<endl;//用系统定义的运算符“<<”输出cy1的数据
cy1.setHeight();//设置圆柱高
cy1.setRadius(7.5);//设置圆半径
cy1.setPoint(,);//设置圆心坐标值x,y
cout<<"\\nnew cylinder:\\n"<<cy1;//用重载运算符“<<”输出cy1的数据
Point &pRef=cy1;//pRef是Point类对象的引用变量
cout<<"\\npRef as a Point:"<<pRef;//pRef作为一个“点”输出
Circle &cRef=cy1;//cRef是Circle类对象的引用变量
cout<<"\\ncRef as a Circle:"<<cRef;//cRef作为一个“圆”输出
return ;
}
运行结果如下:
original cylinder:(输出cy1的初始值)
x=3.5, y=6.4, r=5.2, h=10 (圆心坐标x,y。半径r,高h)
area=496.623, volume=849.486 (圆柱表面积area和体积volume)
new cylinder: (输出cy1的新值)
Center=[5,5], r=7.5, h=15 (以[5,5]形式输出圆心坐标)
area=1060.29, volume=2650.72(圆柱表面积area和体积volume)
pRef as a Point:[5,5] (pRef作为一个“点”输出)
cRef as a Circle:Center=[5,5], r=7.5, area=176.714(cRef作为一个“圆”输出)
说明:在Cylinder类中定义了 area函数,它与Circle类中的area函数同名,根据前面我们讲解的同名覆盖的原则(详情请查看:C++多重继承的二义性问题),cy1.area( ) 调用的是Cylinder类的area函数(求圆柱表面积),而不是Circle类的area函数(圆面积)。请注意,这两个area函数不是重载函数,它们不仅函数名相同,而且函数类型和参数个数都相同,两个同名函数不在同 —个类中,而是分别在基类和派生类中,属于同名覆盖。重载函数的参数个数和参数类型必须至少有一者不同,否则系统无法确定调用哪一个函数。
main函数第9行用“cout<<cy1”来输出cy1,此时调用的是在Cylinder类中声明的重载运算符“<<”,按在重载时规定的方式输出圆柱体cy1的有关数据。
main函数中最后4行的含义与在定义Circle类时的情况类似。pRef是Point类的引用变量,用cy1对其初始化,但它不是cy1的别名,只是cy1中基类Point部分的别名,在输出pRef时是作为一个Point类对象输出的,也就是说,它是一个“点”。同样,cRef是Circle类的引用变量,用cy1对其初始化,但它只是cy1中的直接基类Circle部分的别名, 在输出 cRef 时是作为Circle类对象输出的,它是一个"圆”,而不是一个“圆柱体”。从输 出的结果可以看出调用的是哪个运算符函数。
在本例中存在静态多态性,这是运算符重载引起的(注意3个运算符函数是重载而不是同名覆盖,因为有一个形参类型不同)。可以看到,在编译时编译系统即可以判定应调用哪个重载运算符函数。
2)虚函数、虚函数的作用和使用方法
我们知道,在同一类中是不能定义两个名字相同、参数个数和类型都相同的函数的,否则就是“重复定义”。但是在类的继承层次结构中,在不同的层次中可以出现名字相同、参数个数和类型都相同而功能不同的函数。例如在例12.1(具体代码请查看:C++多态性的一个典型例子)程序中,在Circle类中定义了 area函数,在Circle类的派生类Cylinder中也定义了一个area函数。这两个函数不仅名字相同,而且参数个数相同(均为0),但功能不同,函数体是不同的。前者的作用是求圆面积,后者的作用是求圆柱体的表面积。这是合法的,因为它们不在同一个类中。 编译系统按照同名覆盖的原则决定调用的对象。在例12.1程序中用cy1.area( ) 调用的是派生类Cylinder中的成员函数area。如果想调用cy1 中的直接基类Circle的area函数,应当表示为 cy1.Circle::area()。用这种方法来区分两个同名的函数。但是这样做 很不方便。
人们提出这样的设想,能否用同一个调用形式,既能调用派生类又能调用基类的同名函数。在程序中不是通过不同的对象名去调用不同派生层次中的同名函数,而是通过指针调用它们。例如,用同一个语句“pt->display( );”可以调用不同派生层次中的display函数,只需在调用前给指针变量 pt 赋以不同的值(使之指向不同的类对象)即可。
打个比方,你要去某一地方办事,如果乘坐公交车,必须事先确定目的地,然后乘坐能够到达目的地的公交车线路。如果改为乘出租车,就简单多了,不必查行车路线,因为出租车什么地方都能去,只要在上车后临时告诉司机要到哪里即可。如果想访问多个目的地,只要在到达一个目的地后再告诉司机下一个目的地即可,显然,“打的”要比乘公交车 方便。无论到什么地方去都可以乘同—辆出租车。这就是通过同一种形式能达到不同目的的例子。
C++中的虚函数就是用来解决这个问题的。虚函数的作用是允许在派生类中重新定义与基类同名的函数,并且可以通过基类指针或引用来访问基类和派生类中的同名函数。
请分析例12.2。这个例子开始时没有使用虚函数,然后再讨论使用虚函数的情况。
[例12.2] 基类与派生类中有同名函数。在下面的程序中Student是基类,Graduate是派生类,它们都有display这个同名的函数。
#include <iostream>
#include <string>
using namespace std;
//声明基类Student
class Student
{
public:
Student(int, string,float); //声明构造函数
void display( );//声明输出函数
protected: //受保护成员,派生类可以访问
int num;
string name;
float score;
};
//Student类成员函数的实现
Student::Student(int n, string nam,float s)//定义构造函数
{
num=n;
name=nam;
score=s;
}
void Student::display( )//定义输出函数
{
cout<<"num:"<<num<<"\nname:"<<name<<"\nscore:"<<score<<"\n\n";
}
//声明公用派生类Graduate
class Graduate:public Student
{
public:
Graduate(int, string, float, float);//声明构造函数
void display( );//声明输出函数
private:float pay;
};
// Graduate类成员函数的实现
void Graduate::display( )//定义输出函数
{
cout<<"num:"<<num<<"\nname:"<<name<<"\nscore:"<<score<<"\npay="<<pay<<endl;
}
Graduate::Graduate(int n, string nam,float s,float p):Student(n,nam,s),pay(p){}
//主函数
int main()
{
Student stud1(,"Li",87.5);//定义Student类对象stud1
Graduate grad1(,"Wang",98.5,563.5);//定义Graduate类对象grad1
Student *pt=&stud1;//定义指向基类对象的指针变量pt
pt->display( );
pt=&grad1;
pt->display( );
return ;
}
运行结果如下:
num:1001(stud1的数据)
name:Li
score:87.5
num:2001 (grad1中基类部分的数据)
name:wang
score:98.5
假如想输出grad1的全部数据成员,当然也可以采用这样的方法:通过对象名调用display函数,如grad1.display(),或者定义一个指向Graduate类对象的指针变量ptr,然后使ptr指向gradl,再用ptr->display()调用。这当然是可以的,但是如果该基类有多个派生类,每个派生类又产生新的派生类,形成了同一基类的类族。每个派生类都有同名函数display,在程序中要调用同一类族中不同类的同名函数,就要定义多个指向各派生类的指针变量。这两种办法都不方便,它要求在调用不同派生类的同名函数时采用不同的调用方式,正如同前面所说的那样,到不同的目的地要乘坐指定的不同的公交车,一一 对应,不能搞错。如果能够用同一种方式去调用同一类族中不同类的所有的同名函数,那就好了。
用虚函数就能顺利地解决这个问题。下面对程序作一点修改,在Student类中声明display函数时,在最左面加一个关键字virtual,即
virtual void display( );
这样就把Student类的display函数声明为虚函数。程序其他部分都不改动。再编译和运行程序,请注意分析运行结果:
num:1001(stud1的数据)
name:Li
score:87.5
num:2001 (grad1中基类部分的数据)
name:wang
score:98.5
pay=1200 (这一项以前是没有的)
看!这就是虚函数的奇妙作用。现在用同一个指针变量(指向基类对象的指针变量),不但输出了学生stud1的全部数据,而且还输出了研究生grad1的全部数据,说明已调用了grad1的display函数。用同一种调用形式“pt->display()”,而且pt是同一个基类指针,可以调用同一类族中不同类的虚函数。这就是多态性,对同一消息,不同对象有 不同的响应方式。
说明:本来基类指针是用来指向基类对象的,如果用它指向派生类对象,则进行指针类型转换,将派生类对象的指针先转换为基类的指针,所以基类指针指向的是派生类对象中的基类部分。在程序修改前,是无法通过基类指针去调用派生类对象中的成员函数的。虚函数突破了这一限制,在派生类的基类部分中,派生类的虚函数取代了基类原来的虚函数,因此在使基类指针指向派生类对象后,调用虚函数时就调用了派生类的虚函数。 要注意的是,只有用virtual声明了虚函数后才具有以上作用。如果不声明为虚函数,企图通过基类指针调用派生类的非虚函数是不行的。
虚函数的以上功能是很有实用意义的。在面向对象的程序设计中,经常会用到类的继承,目的是保留基类的特性,以减少新类开发的时间。但是,从基类继承来的某些成员函数不完全适应派生类的需要,例如在例12.2中,基类的display函数只输出基类的数据,而派生类的display函数需要输出派生类的数据。过去我们曾经使派生类的输出函数与基类的输出函数不同名(如display和display1),但如果派生的层次多,就要起许多不同的函数名,很不方便。如果采用同名函数,又会发生同名覆盖。
利用虚函数就很好地解决了这个问题。可以看到:当把基类的某个成员函数声明为虚函数后,允许在其派生类中对该函数重新定义,赋予它新的功能,并且可以通过指向基类的指针指向同一类族中不同类的对象,从而调用其中的同名函数。由虚函数实现的动态多态性就是:同一类族中不同类的对象,对同一函数调用作出不同的响应。
虚函数的使用方法是:
- 在基类用virtual声明成员函数为虚函数。
这样就可以在派生类中重新定义此函数,为它赋予新的功能,并能方便地被调用。在类外定义虚函数时,不必再加virtual。 - 在派生类中重新定义此函数,要求函数名、函数类型、函数参数个数和类型全部与基类的虚函数相同,并根据派生类的需要重新定义函数体。
C++规定,当一个成员函数被声明为虚函数后,其派生类中的同名函数都自动成为虚函数。因此在派生类重新声明该虚函数时,可以加virtual,也可以不加,但习惯上一般在每一层声明该函数时都加virtual,使程序更加清晰。如果在派生类中没有对基类的虚函数重新定义,则派生类简单地继承其直接基类的虚函数。 - 定义一个指向基类对象的指针变量,并使它指向同一类族中需要调用该函数的对象。
- 通过该指针变量调用此虚函数,此时调用的就是指针变量指向的对象的同名函数。
通过虚函数与指向基类对象的指针变量的配合使用,就能方便地调用同一类族中不同类的同名函数,只要先用基类指针指向即可。如果指针不断地指向同一类族中不同类的对象,就能不断地调用这些对象中的同名函数。这就如同前面说的,不断地告诉出租车司机要去的目的地,然后司机把你送到你要去的地方。
需要说明;有时在基类中定义的非虚函数会在派生类中被重新定义(如例12.1中的area函数),如果用基类指针调用该成员函数,则系统会调用对象中基类部分的成员函数;如果用派生类指针调用该成员函数,则系统会调用派生类对象中的成员函数,这并不是多态性行为(使用的是不同类型的指针),没有用到虚函数的功能。
以前介绍的函数重载处理的是同一层次上的同名函数问题,而虚函数处理的是不同派生层次上的同名函数问题,前者是横向重载,后者可以理解为纵向重载。但与重载不同的是:同一类族的虚函数的首部是相同的,而函数重载时函数的首部是不同的(参数个数或类型不同)。
使用虚函数时,有两点要注意:
- 只能用virtual声明类的成员函数,使它成为虚函数,而不能将类外的普通函数声明为虚函数。因为虚函数的作用是允许在派生类中对基类的虚函数重新定义。显然,它只能用于类的继承层次结构中。(个人理解:虚构函数说白了是把对应地址虚构,在后续工作中可以多该地址经行重新整合,声明成虚构函数后,该操作更消耗硬件资源)
- 一个成员函数被声明为虚函数后,在同一类族中的类就不能再定义一个非virtual的但与该虚函数具有相同的参数(包括个数和类型)和函数返回值类型的同名函数。
根据什么考虑是否把一个成员函数声明为虚函数呢?主要考虑以下几点:
- 首先看成员函数所在的类是否会作为基类。然后看成员函数在类的继承后有无可能被更改功能,如果希望更改其功能的,一般应该将它声明为虚函数。
- 如果成员函数在类被继承后功能不需修改,或派生类用不到该函数,则不要把它声明为虚函数。不要仅仅考虑到要作为基类而把类中的所有成员函数都声明为虚函数。
- 应考虑对成员函数的调用是通过对象名还是通过基类指针或引用去访问,如果是通过基类指针或引用去访问的,则应当声明为虚函数。
- 有时,在定义虚函数时,并不定义其函数体,即函数体是空的。它的作用只是定义了一个虚函数名,具体功能留给派生类去添加。(这种理解倒是更够味)
需要说明的是:使用虚函数,系统要有一定的空间开销。当一个类带有虚函数时,编译系统会为该类构造一个虚函数表(virtual function table,简称vtable),它是一个指针数组,存放每个虚函数的入口地址。系统在进行动态关联时的时间开销是很少的,因此,多态性是高效的。
3)静态关联与动态关联、C++是怎样实现多态性的
这一节将探讨C++是怎样实现多态性的。
从例12.2(具体代码请查看:什么是C++虚函数)中修改后的程序可以看到, 同一个display函数在不同对象中有不同的作用,呈现了多态。计算机系统应该能正确地选择调用对象。
在现实生活中,多态性的例子是很多的。我们分析一下人是怎样处理多 态性的。例如,新生被录取人大学,在人学报到时,先有一名工作人员审查材料,他的职责是甄别资格,然后根据录取通知书上注明的录取的系和专业,将材料转到有关的系和专业,办理具体的注册人学手续,也可以看作调用不同部门的处理程序办理入学手续。在学 生眼里,这名工作人员是总的人口,所有新生办入学手续都要经过他。学生拿的是统一的录取通知书,但实际上分属不同的系,要进行不同的注册手续,这就是多态。那么,这名工 作人员怎么处理多态呢?凭什么把它分发到哪个系呢?就是根据录取通知书上的一个信 息(你被录取入本校某某专业)。可见,要区分就必须要有相关的信息,否则是无法判别的。
同样,编译系统要根据已有的信息,对同名函数的调用作出判断。例如函数的重载, 系统是根据参数的个数和类型的不同去找与之匹配的函数的。对于调用同一类族中的虚函数,应当在调用时用一定的方式告诉编译系统,你要调用的是哪个类对象中的函数。例如可以直接提供对象名,如studl.display()或grad1.display()。这样编译系统在对程序进行编译时,即能确定调用的是哪个类对象中的函数。
确定调用的具体对象的过程称为关联(binding)。binding原意是捆绑或连接,即把两样东西捆绑(或连接)在一起。在这里是指把一个函数名与一个类对象捆绑在一起,建立关联。一般地说,关联指把一个标识符和一个存储地址联系起来。在计算机字典中可以査到,所谓关联,是指计算机程序中不同的部分互相连接的过程。有些书中把binding译为联编、编联、束定、或兼顾音和意,称之为绑定。作者认为:从意思上说,关联比较确切, 也好理解。但是有些教程中用了联编这个术语。 大家在看到这个名词时,应当知道指的就是本节介绍的关联。
顺便说一句题外话,计算机领域中大部分术语是从外文翻译过来的,有许多译名是译得比较好的,能见名知意的。但也有一些则令人费解,甚至不大确切。例如在某些介绍计算机语言的书籍中,把project译为“工程”,使人难以理解,其实译为“项目”比较确切。 有些介绍计算机应用的书中充斥大量的术语,初听起来好像很唬人、很难懂,许多学习 C++的人往往被大量的专门术语吓住了,又难以理解其真正含义,不少人“见难而退”。 这个问题成为许多人学习C++的拦路虎。因此,应当提倡用通俗易懂的方法去阐明复杂的概念。其实,有许多看起来深奥难懂的概念和术语,捅破窗户纸后是很简单的。建议读者在初学时千万不要纠缠于名词术语的字面解释上,而要掌握其精神实质和应用方法。
说明:与其他编程语言相比,例如Java、C#等,C++的语法是最丰富最灵活的,同样也是最难掌握的,大家要循序渐进,莫求速成,在编程实践中不断翻阅和记忆。
前面所提到的函数重载和通过对象名调用的虚函数,在编译时即可确定其调用的虚函数属于哪一个类,其过程称为静态关联(static binding),由于是在运行前进行关联的, 故又称为早期关联(early binding)。函数重载属静态关联。
从例12.2我们中看到了怎样使用虚函数,在调用虚函数时并没有指定对象名,那么系统是怎样确定关联的呢?读者可以看到,是通过基类指针与虚函数的结合来实现多态性的。先定义了一个指向基类的指针变量,并使它指向相应的类对象,然后通过这个基类指针去调用虚函数(例如“pt->display()”)。显然,对这样的调用方式,编译系统在编译该行时是无法确定调用哪一个类对象的虚函数的。因为编译只作静态的语法检査,光从语句形式(例如“pt->display();”)是无法确定调用对象的。
在这样的情况下,编译系统把它放到运行阶段处理,在运行阶段确定关联关系。在运行阶段,基类指针变量先指向了某一个类对象,然后通过此指针变量调用该对象中的函数。此时调用哪一个对象的函数无疑是确定的。例如,先使pt指向grad1,再执行“pt->display()”,当然是调用grad1中的display函数。由于是在运行阶段把虚函数和类对象“绑定”在一起的,因此,此过程称为动态关联(dynamic binding)。这种多态性是动态的多态性,即运行阶段的多态性。
在运行阶段,指针可以先后指向不同的类对象,从而调用同一类族中不同类的虚函数。由于动态关联是在编译以后的运行阶段进行的,因此也称为滞后关联(late binding) 。
4)虚析构函数详解
我们已经介绍过析构函数(详情请查看:C++析构函数),它的作用是在对象撤销之前做必要的“清理现场”的工作。
当派生类的对象从内存中撤销时一般先调用派生类的析构函数,然后再调用基类的析构函数。但是,如果用new运算符建立了临时对象,若基类中有析构函数,并且定义了一个指向该基类的指针变量。在程序用带指针参数的delete运算符撤销对象时,会发生一个情况:系统会只执行基类的析构函数,而不执行派生类的析构函数。
[例12.3] 基类中有非虚析构函数时的执行情况。为简化程序,只列出最必要的部分。
#include <iostream>
using namespace std;
class Point //定义基类Point类
{
public:
Point( ){} //Point类构造函数
~Point(){cout<<"executing Point destructor"<<endl;} //Point类析构函数
};
class Circle:public Point //定义派生类Circle类
{
public:
Circle( ){} //Circle类构造函数
~Circle( ){cout<<"executing Circle destructor"<<endl;} //Circle类析构函数
private:
int radius;
};
int main( )
{
Point *p=new Circle; //用new开辟动态存储空间
delete p; //用delete释放动态存储空间
return ;
}
这只是一个示意的程序。p是指向基类的指针变量,指向new开辟的动态存储空间,希望用detele释放p所指向的空间。但运行结果为:
executing Point destructor
表示只执行了基类Point的析构函数,而没有执行派生类Circle的析构函数。
如果希望能执行派生类Circle的析构函数,可以将基类的析构函数声明为虚析构函数,如:
virtual ~Point(){cout<<″executing Point destructor″<<endl;}
程序其他部分不改动,再运行程序,结果为:
executing Circle destructor
executing Point destructor
先调用了派生类的析构函数,再调用了基类的析构函数,符合人们的愿望。
当基类的析构函数为虚函数时,无论指针指的是同一类族中的哪一个类对象,系统会采用动态关联,调用相应的析构函数,对该对象进行清理工作。
如果将基类的析构函数声明为虚函数时,由该基类所派生的所有派生类的析构函数也都自动成为虚函数,即使派生类的析构函数与基类的析构函数名字不相同。
最好把基类的析构函数声明为虚函数。这将使所有派生类的析构函数自动成为虚函数。这样,如果程序中显式地用了delete运算符准备删除一个对象,而delete运算符的操作对象用了指向派生类对象的基类指针,则系统会调用相应类的析构函数。
虚析构函数的概念和用法很简单,但它在面向对象程序设计中却是很重要的技巧。
专业人员一般都习惯声明虚析构函数,即使基类并不需要析构函数,也显式地定义一个函数体为空的虚析构函数,以保证在撤销动态分配空间时能得到正确的处理。
构造函数不能声明为虚函数。这是因为在执行构造函数时类对象还未完成建立过程,当然谈不上函数与类对象的绑定。
5)纯虚函数详解 (作用:类中函数延展作用)
有时在基类中将某一成员函数定为虚函数,并不是基类本身的要求,而是考虑到派生类的需要,在基类中预留了一个函数名,具体功能留给派生类根据需要去定义。
例如在前边的例12.1(详情请查看:什么是C++虚函数)程序中,基类Point中没有求面积的area函数,因为“点”是没有面积的,也就是说,基类本身不需要这个函数,所以在例12.1程序中的Point类中没有定义area函数。
但是,在其直接派生类Circle和间接派生类Cylinder中都需要有area函数,而且这两个area函数的功能不同,一个是求圆面积,一个是求圆柱体表面积。
有的读者自然会想到,在这种情况下应当将area声明为虚函数。可以在基类Point中加一个area函数,并声明为虚函数:
virtual float area( )const {return 0;}
其返回值为0,表示“点”是没有面积的。
其实,在基类中并不使用这个函数,其返回值也是没有意义的。为简化,可以不写出这种无意义的函数体,只给出函数的原型,并在后面加上“=0”,如:
virtual float area( )const =0; //纯虚函数
这就将area声明为一个纯虚函数(pure virtual function)。
纯虚函数是在声明虚函数时被“初始化”为0的函数。声明纯虚函数的一般形式是
virtual 函数类型 函数名 (参数表列) = 0;
关于纯虚函数需要注意的几点:
- 纯虚函数没有函数体;
- 最后面的“=0”并不表示函数返回值为0,它只起形式上的作用,告诉编译系统“这是纯虚函数”;
- 这是一个声明语句,最后应有分号。
纯虚函数只有函数的名字而不具备函数的功能,不能被调用。它只是通知编译系统:“在这里声明一个虚函数,留待派生类中定义”。在派生类中对此函数提供定义后,它才能具备函数的功能,可被调用。
纯虚函数的作用是在基类中为其派生类保留一个函数的名字,以便派生类根据需要对它进行定义。
如果在基类中没有保留函数名字,则无法实现多态性。如果在一个类中声明了纯虚函数,而在其派生类中没有对该函数定义,则该虚函数在派生类中仍然为纯虚函数。
6)抽象类
如果声明了一个类,一般可以用它定义对象。但是在面向对象程序设计中,往往有一些类,它们不用来生成对象。定义这些类的惟一目的是用它作为基类去建立派生类。它们作为一种基本类型提供给用户,用户在这个基础上根据自己的需要定义出功能各异的派生类。用这些派生类去建立对象。
打个比方,汽车制造厂往往向客户提供卡车的底盘(包括发动机、传动部分、车轮等),组装厂可以把它组装成货车、公共汽车、工程车或客车等不同功能的车辆。底盘本身不是车辆,要经过加工才能成为车辆,但它是车辆的基本组成部分。它相当于基类。在现代化的生产中,大多采用专业化的生产方式,充分利用专业化工厂生产的部件,加工集成为新品种的产品。生产公共汽车的厂家决不会从制造发动机到生产轮胎、制造车厢都由本厂完成。其实,不同品牌的电脑里面的基本部件是一样的或相似的。这种观念对软件开发是十分重要的。一个优秀的软件工作者在开发一个大的软件时,决不会从头到尾都由自己编写程序代码,他会充分利用已有资源(例如类库)作为自己工作的基础。
这种不用来定义对象而只作为一种基本类型用作继承的类,称为抽象类(abstract class ),由于它常用作基类,通常称为抽象基类(abstract base class )。凡是包含纯虚函数的类都是抽象类。因为纯虚函数是不能被调用的,包含纯虚函数的类是无法建立对象的。
抽象类的作用是作为一个类族的共同基类,或者说,为一个类族提供一个公共接口。一个类层次结构中当然也可不包含任何抽象类,每一层次的类都是实际可用的,可以用来建立对象的。
但是,许多好的面向对象的系统,其层次结构的顶部是一个抽象类,甚至顶部有好几层都是抽象类。
如果在抽象类所派生出的新类中对基类的所有纯虚函数进行了定义,那么这些函数就被赋予了功能,可以被调用。这个派生类就不是抽象类,而是可以用来定义对象的具体类(concrete class )。
如果在派生类中没有对所有纯虚函数进行定义,则此派生类仍然是抽象类,不能用来定义对象。虽然抽象类不能定义对象(或者说抽象类不能实例化),但是可以定义指向抽象类数据的指针变量。当派生类成为具体类之后,就可以用这种指针指向派生类对象,然后通过该指针调用虚函数,实现多态性的操作。
实例:
我们在例12.1(具体代码请查看:C++多态性的一个典型例子)介绍了以Point为基类的点—圆—圆柱体类的层次结构。现在要对它进行改写,在程序中使用虚函数和抽象基类。类的层次结构的顶层是抽象基类Shape(形状)。Point(点), Circle(圆), Cylinder(圆柱体)都是Shape类的直接派生类和间接派生类。
下面是一个完整的程序,为了便于阅读,分段插入了一些文字说明。程序如下:
第(1)部分
#include <iostream>
using namespace std;
//声明抽象基类Shape
class Shape
{
public:
virtual float area( )const {return 0.0;} //虚函数
virtual float volume()const {return 0.0;} //虚函数 体积
virtual void shapeName()const =; //纯虚函数
};
Shape类有3个成员函数,没有数据成员。3个成员函数都声明为虚函数,其中shapeName声明为纯虚函数,因此Shape是一个抽象基类。shapeName函数的作用是输出具体的形状(如点、圆、圆柱体)的名字,这个信息是与相应的派生类密切相关的,显然这不应当在基类中定义,而应在派生类中定义。所以把它声明为纯虚函数。Shape虽然是抽象基类,但是也可以包括某些成员的定义部分。类中两个函数area(面积)和volume (体积)包括函数体,使其返回值为0(因为可以认为点的面积和体积都为0)。由于考虑到在Point类中不再对area和volume函数重新定义,因此没有把area和volume函数也声明为纯虚函数。在Point类中继承了Shape类的area和volume函数。这3个函数在各派生类中都要用到。
第(2)部分
//声明Point类
class Point:public Shape//Point是Shape的公用派生类
{
public:
Point(float=,float=);
void setPoint(float ,float );
float getX( )const {return x;}
float getY( )const {return y;}
virtual void shapeName( )const {cout<<"Point:";}//对虚函数进行再定义
friend ostream & operator <<(ostream &,const Point &);
protected:
float x,y;
}; //定义Point类成员函数
Point::Point(float a,float b)
{x=a;y=b;}
void Point::setPoint(float a,float b)
{x=a;y=b;}
ostream & operator <<(ostream &output,const Point &p)
{
output<<"["<<p.x<<","<<p.y<<"]";
return output;
}
Point从Shape继承了3个成员函数,由于“点”是没有面积和体积的,因此不必重新定义area和volume。虽然在Point类中用不到这两个函数,但是Point类仍然从Shape类继承了这两个函数,以便其派生类继承它们。shapeName函数在Shape类中是纯虚函数, 在Point类中要进行定义。Point类还有自己的成员函数( setPoint, getX, getY)和数据成 员(x和y)。
第(3)部分
//声明Circle类
class Circle:public Point
{
public:
Circle(float x=,float y=,float r=);
void setRadius(float );
float getRadius( )const;
virtual float area( )const;
virtual void shapeName( )const {cout<<"Circle:";}//对虚函数进行再定义
friend ostream &operator <<(ostream &,const Circle &);
protected:
float radius;
};
//声明Circle类成员函数
Circle::Circle(float a,float b,float r):Point(a,b),radius(r){}
void Circle::setRadius(float r):radius(r){}
float Circle::getRadius( )const {return radius;}
float Circle::area( )const {return 3.14159*radius*radius;}
ostream &operator <<(ostream &output,const Circle &c)
{
output<<"["<<c.x<<","<<c.y<<"], r="<<c.radius;
return output;
}
在Circle类中要重新定义area函数,因为需要指定求圆面积的公式。由于圆没有体积,因此不必重新定义volume函数,而是从Point类继承volume函数。shapeName函数是虚函数,需要重新定义,赋予新的内容(如果不重新定义,就会继承Point类中的 shapeName函数)。此外,Circle类还有自己新增加的成员函数(setRadius, getRadius)和数据成员(radius)。
第(4)部分
//声明Cylinder类
class Cylinder:public Circle
{
public:
Cylinder (float x=,float y=,float r=,float h=);
void setHeight(float );
virtual float area( )const;
virtual float volume( )const;
virtual void shapeName( )const {
cout<<"Cylinder:";
}//对虚函数进行再定义
friend ostream& operator <<(ostream&,const Cylinder&);
protected:
float height;
};
//定义Cylinder类成员函数
Cylinder::Cylinder(float a,float b,float r,float h):Circle(a,b,r),height(h){}
void Cylinder::setHeight(float h){height=h;}
float Cylinder::area( )const{
return *Circle::area( )+*3.14159*radius*height;
}
float Cylinder::volume( )const{
return Circle::area( )*height;
}
ostream &operator <<(ostream &output,const Cylinder& cy){
output<<"["<<cy.x<<","<<cy.y<<"], r="<<cy.radius<<", h="<<cy.height;
return output;
}
Cylinder类是从Circle类派生的。由于圆柱体有表面积和体积,所以要对area和 volume函数重新定义。虚函数shapeName也需要重新定义。此外,Cylinder类还有自已 的成员函数setHeight和数据成员radius。
第(5)部分
//main函数
int main( )
{
Point point(3.2,4.5); //建立Point类对象point
Circle circle(2.4,1.2,5.6);
//建立Circle类对象circle
Cylinder cylinder(3.5,6.4,5.2,10.5);
//建立Cylinder类对象cylinder
point.shapeName();
//静态关联
cout<<point<<endl;
circle.shapeName(); //静态关联
cout<<circle<<endl;
cylinder.shapeName(); //静态关联
cout<<cylinder<<endl<<endl;
Shape *pt; //定义基类指针
pt=&point; //指针指向Point类对象
pt->shapeName( ); //动态关联
cout<<"x="<<point.getX( )<<",y="<<point.getY( )<<"\narea="<<pt->area( )
<<"\nvolume="<<pt->volume()<<"\n\n";
pt=&circle; //指针指向Circle类对象
pt->shapeName( ); //动态关联
cout<<"x="<<circle.getX( )<<",y="<<circle.getY( )<<"\narea="<<pt->area( )
<<"\nvolume="<<pt->volume( )<<"\n\n";
pt=&cylinder; //指针指向Cylinder类对象
pt->shapeName( ); //动态关联
cout<<"x="<<cylinder.getX( )<<",y="<<cylinder.getY( )<<"\narea="<<pt->area( )
<<"\nvolume="<<pt->volume( )<<"\n\n";
return ;
}
在主函数中调用有关函数并输出结果。先分别定义了 Point类对象point,Circle类对象circle和Cylinder类对象cylinder。然后分别通过对象名point, circle和cylinder调用 了shapeNanme函数,这是属于静态关联,在编译阶段就能确定应调用哪一个类的 shapeName函数。同时用重载的运箅符“<<”来输出各对象的信息,可以验证对象初始化是否正确。
再定义一个指向基类Shape对象的指针变量pt,使它先后指向3个派生类对象 point, Circle和cylinder,然后通过指针调用各函数,如 pt->shapeName( ),pt ->area(), pt->volume( )。这时是通过动态关联分别确定应该调用哪个函数。分别输出不同类对象的信息。
程序运行结果如下:
Point:[3.2,4.5](Point类对象point的数据:点的坐标)
Circle:[2.4,1.2], r=5.6 (Circle类对象circle的数据:圆心和半径)
Cylinder:[3.5,6.4], r=5.5, h=10.5 (Cylinder类对象cylinder的数据: 圆心、半径和高)
Point:x=3.2,y=4.5 (输出Point类对象point的数据:点的坐标)
area=0 (点的面积)
volume=0 (点的体积)
Circle:x=2.4,y=1.2 (输出Circle类对象circle的数据:圆心坐标)
area=98.5203 (圆的面积)
volume=0 (圆的体积)
Cylinder:x=3.5,y=6.4 (输出Cylinder类对象cylinder的数据:圆心坐标)
area=512.595 (圆的面积)
volume=891.96 (圆柱的体积)
从本例可以进一步明确以下结论:
- 一个基类如果包含一个或一个以上纯虚函数,就是抽象基类。抽象基类不能也不必要定义对象。
- 抽象基类与普通基类不同,它一般并不是现实存在的对象的抽象(例如圆形(Circle)就是千千万万个实际的圆的抽象),它可以没有任何物理上的或其他实际意义方面的含义。
- 在类的层次结构中,顶层或最上面的几层可以是抽象基类。抽象基类体现了本类族中各类的共性,把各类中共有的成员函数集中在抽象基类中声明。
- 抽象基类是本类族的公共接口。或者说,从同一基类派生出的多个类有同一接口。
- 区别静态关联和动态关联。如果是通过对象名调用虚函数(如point.shapeName()),在编译阶段就能确定调用的是哪一个类的虚函数,所以属于静态关联。 如果是通过基类指针调用虚函数(如pt ->shapeName()),在编译阶段无法从语句本身确定调用哪一个类的虚函数,只有在运行时,pt指向某一类对象后,才能确定调用的是哪 一个类的虚函数,故为动态关联。
- 如果在基类声明了虚函数,则在派生类中凡是与该函数有相同的函数名、函数类型、参数个数和类型的函数,均为虚函数(不论在派生类中是否用virtual声明)。
- 使用虚函数提高了程序的可扩充性。把类的声明与类的使用分离。这对于设计类库的软件开发商来说尤为重要。
开发商设计了各种各样的类,但不向用户提供源代码,用户可以不知道类是怎样声明的,但是可以使用这些类来派生出自己的类。利用虚函数和多态性,程序员的注意力集中在处理普遍性,而让执行环境处理特殊性。
多态性把操作的细节留给类的设计者(他们多为专业人员)去完成,而让程序人员(类的使用者)只需要做一些宏观性的工作,告诉系统做什么,而不必考虑怎么做,极大地简化了应用程序的编码工作,大大减轻了程序员的负担,也降低了学习和使用C++编程的难度,使更多的人能更快地进入C++程序设计的大门。
------------------
瘋子C++笔记的更多相关文章
- 瘋子C语言笔记(指针篇)
指针篇 1.基本指针变量 (1)定义 int i,j; int *pointer_1,*pointer_2; pointer_1 = &i; pointer_2 = &j; 等价于 i ...
- 瘋子C语言笔记(结构体/共用体/枚举篇)
(一)结构体类型 1.简介: 例: struct date { int month; int day; int year; }; struct student { int num; char name ...
- 瘋子C语言笔记 (string)
1.strstr() 函数 搜索一个字符串在另一个字符串中的第一次出现.找到所搜索的字符串,则该函数返回第一次匹配的字符串的地址:如果未找到所搜索的字符串,则返回NULL. 2.strcat() 函数 ...
- 瘋耔java语言笔记
一◐ java概述 1.1 ...
- A9系统时钟用外部
问个笨蛋的问题,,电脑主板的主频是由外部时钟倍频得来,还是内部时钟倍频?? [ARM11]瘋子 2015/5/5 19:08:16 @蓝凌风 [x86]蓝凌 2015/5/5 19:08:25 外部 ...
- DMA(STM32)
1.DMA:data memory access //实际的内存存储 注:DMA干活的时候是不须要CPU干涉的 2. ①内存(定义的变量)---外设(寄存器). ②内存---内存 ③外设---外 ...
- FSMC(STM32)
(一)FSMC:Flexible Static Memory Controller,可变(灵活)静态存储控制器 小容量产品是指闪存存储器容量在1 6K至32K 字节之间的STM32F101xx.STM ...
- sudo fdisk -l
施其振 2015/1/31 22:06:26 第一行十大5 施其振 2015/1/31 22:06:39 第一行sda5 施其振 2015/1/31 22:06:49 是你的固态硬盘 施其振 20 ...
- 超时空英雄传说2复仇魔神完全攻略&秘技
╓─╥───────────────────────────────────────────────────╥─╖ ║ ║ 超 時 空 英 雄 傳 說 2 ║ ║ ║ ║ --復 仇 魔 神-- ║ ...
随机推荐
- Image模块
1.创建一个新的图片 Image.new(mode,size) Image.new(mode,size,color) 2.层叠图片 层叠两个图片,img1和img2,alpha是一个介于[0,1]的浮 ...
- centos6.7安装Redis
1.创建安装目录 mkdir /usr/local/redis cd /usr/local/src 2.获取安装包:wget http://download.redis.io/releases/red ...
- Redis 3.2 Linux 环境集群搭建与java操作
redis 采用 redis-3.2.4 版本. 安装过程 1. 下载并解压 cd /usr/local wget http://download.redis.io/releases/redis-3. ...
- 去掉无用的多余的空格(string1.前后空格,2.中间空格)
1.使用NSString中的stringByTrimmingCharactersInSet:[NSCharacterSet whitespaceCharacterSet]]方法只是去掉左右两边的空格: ...
- 用mac的terminal通过公私钥和ssh登录Linux
刚开始使用mac,会觉得很难用,在网上找的方法也差强人意,经过自己的实践,找到下面这种方法,很好用,步骤也很简单 1.在mac本的个人目录下创建一个文件夹:.ssh. 在这个文件夹下使用ssh- ...
- CS193P - 2016年秋 第三讲 Swift 语言及 Foundation 框架
这一讲介绍一些 Swift 的重点概念.特别是一些有别于其它语言的地方.但本质上还都是语法糖. 想充分理解这一讲的内容,最好的方式就是 打开 playgound,亲自动手来实验. 1,Optional ...
- nginx 配置优化(简单)
配置文件 正常运行的必备配置: 1.user username [groupname]:(推荐nginx) 以那个用户身份运行,以在configure指定的用户 ...
- AutoBundle in asp.net mvc 5
using System.Collections.Concurrent; using System.Text; namespace System.Web.Optimization { public s ...
- cygwin E437
这个简单错误居然查到了 报错E437: terminal capability "cm" required 执行:# export TERM=xterm
- Vim命令
多行缩进: shift+v >或者< 撤销: :u