Hadoop 服务SYS CPU过高导致宕机问题
最近某hadoop集群多次出现机器宕机,现象为瞬间机器的sys cpu增长至100%,机器无法登录。只能硬件重启,ganglia cpu信息如下:
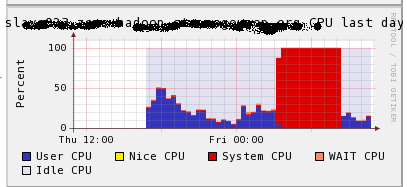
首先怀疑有用户启动了比较奇葩的job,导致不合理的系统调用出现的问题。随后加了ps及pidstat信息收集job信息(公共集群蛋疼的地方),然后出现问题的时候,各类脚本已经无法工作,
一直没有抓到现场。
终于在某一次看到一台机器sys 瞬间增长,且机器还能登录。立马查看现场,发现竟然元凶是datanode:datanode一个进程占用cpu 1600%,sys cpu占用超过40%
Datanode的进程栈信息,大量dataxceiver线程block,并且都是在发送数据块过程中 getVisibleLength操作:
"DataXceiver for client /10.16.136.65:34464 [sending block blk_341818443393496218_612191861]" daemon prio=10 tid=0x00007f7500a33000 nid=0x4135 waiting for monitor entry [0x00007f74ec5a5000]
java.lang.Thread.State: BLOCKED (on object monitor)
at org.apache.hadoop.hdfs.server.datanode.FSDataset.getVisibleLength(FSDataset.java:1116)
- waiting to lock <0x000000051237f860> (a org.apache.hadoop.hdfs.server.datanode.FSDataset)
at org.apache.hadoop.hdfs.server.datanode.BlockSender.<init>(BlockSender.java:118)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.readBlock(DataXceiver.java:271)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:176)
Locjava:118)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.writeBlock(DataXceiver.java:394)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:184)
Locked ownable synchronizers:
- None
从这里看,似乎并没有什么问题,只是大量线程堵塞在文件的操作上。问题依然没有进展。
这样大概持续了一段时间,发现出问题的机器有一个共同点,dmesg信息有大量此类log:
shrink_slab: xfs_buftarg_shrink+0x0/0x160 [xfs] negative objects to delete nr=-6
参考:http://www.ibm.com/developerworks/cn/linux/l-cn-pagerecycle/
函数 shrink_slab()
函数 shrink_slab() 是用来回收磁盘缓存所占用的页面的。Linux 操作系统并不清楚这类页面是如何使用的,所以如果希望操作系统回收磁盘缓存所占用的页面,那么必须要向操作系统内核注册 shrinker 函数,shrinker 函数会在内存较少的时候主动释放一些该磁盘缓存占用的空间。函数 shrink_slab() 会遍历 shrinker 链表,从而对所有注册了 shrinker 函数的磁盘缓存进行处理。
从实现上来看,shrinker 函数和 slab 分配器并没有固定的联系,只是当前主要是 slab 缓存使用 shrinker 函数最多。
也就是这些dmesg信息应该是在内存回收磁盘缓存页面阶段出现的。
而看到某数字公司的一篇文章,同为hadoop服务sys cpu过高:
作者追查的原因为compact_zone,同样为内存管理。
并且IBM提到了CFS对java性能的影响:
http://www-01.ibm.com/support/docview.wss?uid=swg21372909
处理的办法是/proc/sys/kernel/sched_compat_yield置为1,而RHEL6上面貌似这个参数已经不生效。
综上,可以基本推断出,这个问题跟RHEL6的内存管理密切相关。我们对RHEL6内存管理相关的的参数调整:
(1) 关闭大页内存:echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag && echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled
(2) Vfs_cache置为零:/sbin/sysctl vm.vfs_cache_pressure=0
于是从内存管理入手,首先调整了vm.vfs_cache_pressure,将其改回默认值100,观察一天,果然dmesg里shrink_slab相关信息消失,并且改过的机器没有出现过宕机。因此问题定位为
内存cache回收。此参数在RHEL5上运行时一直置为0并运行平稳,RHEL6真是坑人啊。。
我们将vm.vfs_cache_pressure置为0,目的是让系统不要主动回收cache,以使hadoop进程有足够多的内存cache。对datanode和task性能有比较好的提升。如果恢复回默认值,性能会有很大的下降,用户又不干了。于是经过测试,将vm.vfs_cache_pressure调整为5--10,这样系统会倾向于主动回收一部分cache,同时hadoop也有足够的cache供进程用。也再没有出现sys cpu升高导致的宕机问题。
Hadoop 服务SYS CPU过高导致宕机问题的更多相关文章
- ORA-04031错误导致宕机案例分析
今天遇到一起ORACLE数据库宕机案例,下面是对这起数据库宕机案例的原因进行分析.解读.分析过程中顺便记录一下这个案例的前因后果,攒点经验值,培养一下分析.解决问题的能力. 案例环境: 操作系统 ...
- Centos7.5调试/etc/sysctl.conf文件导致宕机
今天安装greenplus数据库,需要调试一个核心文件/etc/sysctl.conf文件,结果导致系统异常宕机,出现的问题就是使用任何命令都不能输出正确的结果,只有这个显示: 不知道是什么原因,ls ...
- PHP CGI 进程占用CPU过高导致CPU使用达到100%的另类原因
由于使用的华为云的CDN加速,结果发现我的阿里云服务器突然卡顿,网页打开极慢.登陆华为云CDN管理后台发现最高带宽占用30M,流量短时间内达到10GB以上,这么大的流量我的服务器肯定扛不住啊.于是还跟 ...
- 性能分析 | Java进程CPU占用高导致的网页请求超时的故障排查
一.发现问题的系统检查: 一个管理平台门户网页进统计页面提示请求超时,随进服务器操作系统检查load average超过4负载很大,PID为7163的进程占用到了800%多. 二.定位故障 根据这种故 ...
- AZURE云上 mkfs.ext4 /dev/sdc 导致宕机问题解决纪实
)开机启动挂载配置 [root@pldb2 ~]# vim /etc/fstab You have new mail in /var/spool/mail/root [root@pldb2 ~]# m ...
- 记-ItextPDF+freemaker 生成PDF文件---导致服务宕机
摘要:已经上线的项目,出现服务挂掉的情况. 介绍:该服务是专门做打印的,业务需求是生成PDF文件进行页面预览,主要是使用ItextPDF+freemaker技术生成一系列PDF文件,其中生成流程有:解 ...
- memcache占用CPU过高的解决办法
Simon最近为公司服务器操碎了心 , 先是mysqld进程占用CPU过高 , 导致服务器性能变低 ,网站打开太慢.通过增加max_connections及table_cache解决了问题 ,随后发现 ...
- MySQL - 高可用性:少宕机即高可用?
我们之前了解了复制.扩展性,接下来就让我们来了解可用性.归根到底,高可用性就意味着 "更少的宕机时间". 老规矩,讨论一个名词,首先要给它下个定义,那么什么是可用性? 1 什么是可 ...
- 关于解决Tomcat服务器Connection reset by peer 导致的宕机
org.apache.catalina.connector.ClientAbortException: java.io.IOException: Connection reset by peer at ...
随机推荐
- [CF585E]Marbles
Description: 给定一个序列 \(a_i\) ,每次可以交换相邻两个元素,求使序列变成若干个极大连续段,每个极大连续段内部的值相同且任意两个极大连续段的值互不相同. \(n\le 4\tim ...
- GraphQL入门有这一篇就足够了
GraphQL入门有这一篇就足够了:https://blog.csdn.net/qq_41882147/article/details/82966783 版权声明:本文为博主原创文章,遵循 CC 4. ...
- 不是我吹,Lambda这个坑你肯定不知道!
上周有小伙伴反馈zk连接很慢.整理出zk连接的关键逻辑如下: public class ClientZkAgent { //单例模式 private static final ClientZk ...
- [BZOJ 3771] Triple(FFT+容斥原理+生成函数)
[BZOJ 3771] Triple(FFT+生成函数) 题面 给出 n个物品,价值为别为\(w_i\)且各不相同,现在可以取1个.2个或3个,问每种价值和有几种情况? 分析 这种计数问题容易想到生成 ...
- 六、JVM — JDK 监控和故障处理工具
JDK 监控和故障处理工具总结 JDK 命令行工具 jps:查看所有 Java 进程 jstat: 监视虚拟机各种运行状态信息 jinfo: 实时地查看和调整虚拟机各项参数 jmap:生成堆转储快照 ...
- Javascript高级面试
原型 异步 一.什么是单线程,和异步有什么关系 单线程:只有一个线程,同一时间只能做一件事原因:避免DOM渲染的冲突解决方案:异步 为什么js只有一个线程:避免DOM渲染冲突 浏览器需要渲染DOM J ...
- 【ES6】迭代器与可迭代对象
ES6 新的数组方法.集合.for-of 循环.展开运算符(...)甚至异步编程都依赖于迭代器(Iterator )实现.本文会详解 ES6 的迭代器与生成器,并进一步挖掘可迭代对象的内部原理与使用方 ...
- 二: Jvm内存模型
因为每个对象生命周期不一样,jvm在做内存管理的时候,就帮我们分成了三个区域: 1. 新生代(回收频率高) 新生和老年默认大小比例为1:2 2. 老年代(回收频率低) 最好所有的对象都 ...
- Chrome开发者工具详解(二)之使用断点调试代码下
JS调试技巧 技巧一:格式化压缩代码 技巧二:快速跳转到某个断点的位置 右侧的Breakpoints会汇总你在JS文件所有打过的断点,点击跟checkbox同一行的会暂时取消这个断点,若是点击chec ...
- 2019 湖湘杯 Reverse WP
0x01 arguement 下载链接:https://www.lanzous.com/i7atyhc 1.准备 获取到信息: 32位的文件 upx加密文件 在控制台打开文件 使用"upx ...