Kylin-2.6.2集群部署
1. 集群节点规划与说明
rzx1 all
rzx2 query
rzx3 query
说明:
Kylin节点角色有三种:
all: 包含query和job
query: 查询节点
job: 工作节点
2. Kylin依赖的其他大数据组件非常多,下列列表是安装kylin需要的组件
JDK 1.8<必须项>
HADOOP<必须项,hdfs作为数据存储基础,这里版本是hadoop-2.7.7>
ZOOKEERER<必须项,集群协调,这里版本zookeeper-3.4.13>
HBASE<必须项,可以理解为数据中间件,这里版本hbase-2.0.4>
HIVE<必须项,kylin OLAP基础数仓或可以理解为OLAP数据源,这里版本hive-2.3.4>
KAFKA<可选项,这里不安装>
3. 在已下载解压好的目录下
<下载地址: https://archive.apache.org/dist/kylin/>
在rzx1节点下:
vim conf/kylin.properties:
kylin.server.mode=all
kylin.server.cluster-servers=rzx1:7070,rzx2:7070,rzx3:7070
kylin.coprocessor.local.jar=/home/bigdata/software/kylin-2.6.2/lib/kylin-coprocessor-2.6.2.jar
说明:开发测试环境目前只安装简易版,该配置文件配置参数非常多,实际生产环境需要根据实际情况来配置
4. 在rzx1节点下将上面配置好的kylin目录scp到rzx2,rzx3节点上
在kylin当前目录的上一层目录上:
scp -r kylin-2.6.2 root@rzx2:/home/bigdata/software/
scp -r kylin-2.6.2 root@rzx2:/home/bigdata/software/
将rzx2,rzx3节点kylin目录下conf/kylin.properties的
kylin.server.mode改为query
kylin.server.mode=query
5. 配置kylin环境变量
前提配置好kylin依赖的组件的环境变量
export KYLIN_HOME=/home/bigdata/software/kylin-2.6.2
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZK_HOME/bin:$KAFKA_HOME/bin:$HBASE_HOME/bin:$HCAT_HOME/bin:$KYLIN_HOME/bin:$PATH
这里为了方便kylin依赖的完整组件的环境变量,贴出我的全部环境变量配置:
export JAVA_HOME=/home/bigdata/software/jdk1.8.0_201
export HADOOP_HOME=/home/bigdata/software/hadoop-2.7.7
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export HIVE_HOME=/home/bigdata/software/hive-2.3.4
export HIVE_CONF_DIR=/home/bigdata/software/hive-2.3.4/conf
export HCAT_HOME=$HIVE_HOME/hcatalog
export ZK_HOME=/home/bigdata/software/zookeeper-3.4.13
export KAFKA_HOME=/home/bigdata/software/kafka_2.11-2.0.0
export HBASE_HOME=/home/bigdata/software/hbase-2.0.4
export KYLIN_HOME=/home/bigdata/software/kylin-2.6.2
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/natvie
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib:${HADOOP_HOME}/lib/native"
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZK_HOME/bin:$KAFKA_HOME/bin:$HBASE_HOME/bin:$HCAT_HOME/bin:$KYLIN_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
6. 上面配置完成无误后,启动kylin依赖检测
前提:检测前要确保hadoop,zookeeper,hbase,hive正常启动
检测依次执行以下命令:
# 执行下面的检查命令会在 hdfs 上创建 kylin 目录
./check-env.sh
# 检查数据源 hive 和数据存储 hbase
./find-hive-dependency.sh
./find-hbase-dependency.sh
说明:如果环境变量配置不正确,依赖组件不能正常启动,检测是不会通过的,只能一项项去排查了
7. 在每个节点上都启动kylin集群
kylin.sh start
说明:执行启动命令后kylin会去自动检测它需要的相关组件的相关依赖,如下图提示
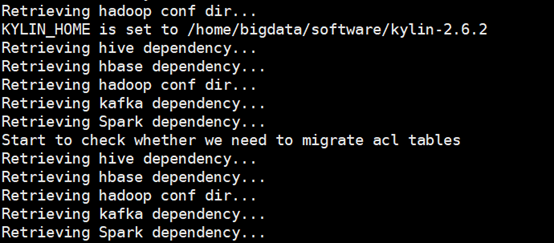
这里需要主要,如果你没有安装spark,kylin就回检测它依赖的执行引擎的相关依赖不存在,所以会提示用本身提供的脚本去下载,如果你的大数据计算引擎不是spark按照提示下载即可,如果是只需要正确配置就可以了,在kylin的bin目录下提供了下载spark的脚本
bin/download-spark.sh
这里事先下载好了所以不会提示
8. 验证
在第7部启动结束末尾提示

证明启动无误,注意三个节点都需要得到该提示才会证明完全成功,不然就会出现query和job能力缺少导致功能不能使用
进一步根据提示通过图形化界面确认
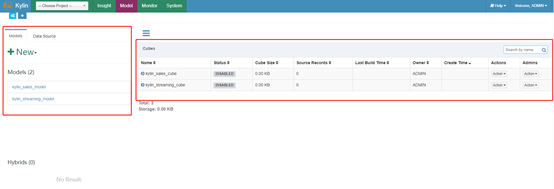
注意:表红框的地方在正确无误启动后不会立即有,因为这是数据及模型,所有启动成功后Models,Datasour,Cubes都是空的
9. 加入数据及模型
Kylin很贴心,知道你第一次不会,所以提供了一个实例化kylin三个核心Models,Datasour,Cubes的脚本,该脚本在kylin目录下bin目录下
bin/sample.sh
正确启动后再执行bin/sample.sh,这个过程需要一些时间,当看到下面信息,证明正确创建了一个kylin instance
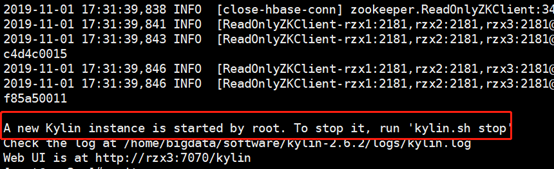
根据提示,需要重启kylin实例才能生效,所以重启kylin
注意:kylin提供的命令不支持
kylin.sh restart
所以只能先
kylin.sh stop
再
kylin.sh start
注意是每个节点
进行如上操作后再查看可视化界面:
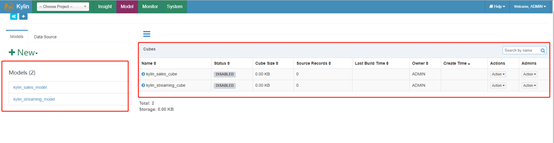
至此kylin部署配置,启动,添加样例实例全部成功
10. 还可以验证hive上是否有kylin相关数据实例的表
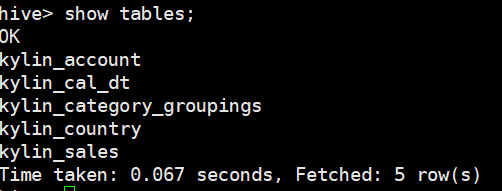
说明: 这里只是简易的开发测试集群搭建配置,实际数据量过大的生产环境配置可能相对复杂些
Kylin-2.6.2集群部署的更多相关文章
- hbase-2.0.4集群部署
hbase-2.0.4集群部署 1. 集群节点规划: rzx1 HMaster,HRegionServer rzx2 HRegionServer rzx3 HRegionServer 前提:搭建好ha ...
- Quartz.net持久化与集群部署开发详解
序言 我前边有几篇文章有介绍过quartz的基本使用语法与类库.但是他的执行计划都是被写在本地的xml文件中.无法做集群部署,我让它看起来脆弱不堪,那是我的罪过. 但是quart.net是经过许多大项 ...
- Openfire 集群部署和负载均衡方案
Openfire 集群部署和负载均衡方案 一. 概述 Openfire是在即时通讯中广泛使用的XMPP协议通讯服务器,本方案采用Openfire的Hazelcast插件进行集群部署,采用Hapro ...
- 基于Tomcat的Solr3.5集群部署
基于Tomcat的Solr3.5集群部署 一.准备工作 1.1 保证SOLR库文件版本相同 保证SOLR的lib文件版本,slf4j-log4j12-1.6.1.jar slf4j-jdk14-1.6 ...
- jstorm集群部署
jstorm集群部署下载 Install JStorm Take jstorm-0.9.6.zip as an example unzip jstorm-0.9.6.1.zip vi ~/.bashr ...
- CAS 集群部署session共享配置
背景 前段时间,项目计划搞独立的登录鉴权中心,由于单独开发一套稳定的登录.鉴权代码,工作量大,最终的方案是对开源鉴权中心CAS(Central Authentication Service)作适配修改 ...
- Windows下ELK环境搭建(单机多节点集群部署)
1.背景 日志主要包括系统日志.应用程序日志和安全日志.系统运维和开发人员可以通过日志了解服务器软硬件信息.检查配置过程中的错误及错误发生的原因.经常分析日志可以了解服务器的负荷,性能安全性,从而及时 ...
- 理解 OpenStack + Ceph (1):Ceph + OpenStack 集群部署和配置
本系列文章会深入研究 Ceph 以及 Ceph 和 OpenStack 的集成: (1)安装和部署 (2)Ceph RBD 接口和工具 (3)Ceph 物理和逻辑结构 (4)Ceph 的基础数据结构 ...
- HBase集成Zookeeper集群部署
大数据集群为了保证故障转移,一般通过zookeeper来整体协调管理,当节点数大于等于6个时推荐使用,接下来描述一下Hbase集群部署在zookeeper上的过程: 安装Hbase之前首先系统应该做通 ...
- SolrCloud-5.2.1 集群部署及测试
一. 说明 Solr5内置了Jetty服务,所以不用安装部署到Tomcat了,网上部署Tomcat的资料太泛滥了. 部署前的准备工作: 1. 将各主机IP配置为静态IP(保证各主机可以正常通信,为避免 ...
随机推荐
- PHP curl_pause函数
curl_pause — 暂停及恢复连接. 说明 int curl_pause ( resource $ch , int $bitmask ) 参数 ch 由 curl_init() 返回的 cURL ...
- jdbc 事物
package transaction; import jdbc.utils.*; import java.sql.Connection; import java.sql.PreparedStatem ...
- 提供 web前端、H5、html页面 技术服务
如有前端页面的需求请在评论区留言 第一时间进行回复
- Eclipse ALT+/ 代码没有提示功能
第一种配置如下: 第二: 第三: 以上三种方式是关于eclipse代码提示
- XAMPP安装和配置
一.XAMPP安装: 下载地址:https://www.apachefriends.org/zh_cn/index.html 二.修改MySQL数据库 1.更改Apache中数据库端口号 保存后重新启 ...
- kafka manager遇到的一些问题
1.启动后第一个报错如下: [error] k.m.a.c.BrokerViewCacheActor - Failed to get broker metrics for BrokerIdentity ...
- JdbcTemplate 的oracle分页
@Autowired private JdbcTemplate jd; int ps1=Integer.valueOf(pageSize); int cp1=Integer.valueOf(currP ...
- Openstack组件部署 — keystone(domain, projects, users, and roles)
目录 目录 前文列表 Create a domain projects users and roles domain projects users and roles的意义和作用 Create the ...
- ORA-06550/PLS-00103
原因是单引号‘是需要加转义字符的(即‘—>“)
- 2.Prometheus安装部署
环境准备 2台Linux操作系统(基于centos7) docker环境 配置 IP 角色 版本 192.168.229.139 prometheus-server 2.10 192.168.229. ...