2-prometheus各组件安装
相关下载:
https://prometheus.io/download/
https://github.com/prometheus/
相关文档
https://songjiayang.gitbooks.io/prometheus/content/alertmanager/wechat.html #此文档最全 https://github.com/yunlzheng/prometheus-book
https://github.com/prometheus/
prometheus安装和简单配置
tar -xf prometheus-2.2.0.linux-amd64.tar.gz
mv prometheus-2.2.0.linux-amd64 /opt/prometheus
mkdir -p /opt/prometheus/{bin,data,log}
mv /opt/prometheus/prometheus /opt/prometheus/bin/
useradd -M -s /sbin/nologin prometheus
chown -R prometheus.prometheus /opt/prometheus
prometheus简单配置
vim /opt/prometheus/prometheus.yml
==================================
# my global config
global:
scrape_interval: 15s
evaluation_interval: 15s
#配置alertmanager
#alerting:
# alertmanagers:
# - static_configs:
# - targets:
# - 172.16.0.10:9093
#配置告警规则
rule_files:
# - "/opt/prometheus/test.yml"
# - "second_rules.yml"
#监控主机9090是prometheus服务端,9100prometheus客户端
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['0.0.0.0:9090']
labels:
instance: 'prometheus'
==================================
prometheus systemctl脚本
/etc/systemd/system/prometheus.service
==================================
[Unit]
Description=prometheus service
After=syslog.target network.target remote-fs.target nss-lookup.target
[Service]
LimitNOFILE=1000000
User=prometheus
ExecStart=/opt/prometheus/run_prometheus.sh
Restart=always
RestartSec=15s
[Install]
WantedBy=multi-user.target
==================================
prometheus 运行脚本
/opt/prometheus/run_prometheus.sh
==================================
#!/bin/bash
set -e
ulimit -n 1000000
DEPLOY_DIR=/opt/prometheus
cd "${DEPLOY_DIR}" || exit 1
# WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
exec 1>> /opt/prometheus/log/prometheus.log 2>> /opt/prometheus/log/prometheus.log
exec bin/prometheus \
--config.file="/opt/prometheus/prometheus.yml" \
--web.listen-address=":9090" \
--web.external-url="http://192.168.55.33:9090/" \
--web.enable-admin-api \
--log.level="info" \
--storage.tsdb.path="/opt/prometheus/data" \
--storage.tsdb.retention="15d"
==================================
chmod a+x /opt/prometheus/run_prometheus.sh
#启动prometheus
systemctl daemon-reload #添加或更改脚本需要执行
systemctl start prometheus
systemctl enable prometheus
netstat -lnp | grep prometheus #查看启动的端口
#重新加载配置文件
kill -1 prometheus_pid
#页面访问
x.x.x.x:9090
启动成功以后我们可以通过Prometheus内置了web界面访问,http://ip:9090 ,如果出现以下界面,说明配置成功

node_exporter安装
tar -xf node_exporter-0.15.0.linux-amd64.tar.gz
mv node_exporter-0.15.0.linux-amd64 /opt/node_exporter
mkdir -p /opt/node_exporter/{bin,log}
mv /opt/node_exporter/node_exporter /opt/node_exporter/bin/
chown -R prometheus.prometheus /opt/node_exporter
#systemctl 脚本
vim /etc/systemd/system/node_exporter.service
==============================================
[Unit]
Description=node_exporter service
After=syslog.target network.target remote-fs.target nss-lookup.target
[Service]
LimitNOFILE=1000000
User=prometheus
ExecStart=/opt/node_exporter/run_node_exporter.sh
Restart=always
RestartSec=15s
[Install]
WantedBy=multi-user.target
===============================================
#运行脚本
/opt/node_exporter/run_node_exporter.sh
================================================
#!/bin/bash
set -e
ulimit -n 1000000
# WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
DEPLOY_DIR=/opt/node_exporter
cd "${DEPLOY_DIR}" || exit 1
exec 1>> /opt/node_exporter/log/node_exporter.log 2>> /opt/node_exporter/log/node_exporter.log
exec bin/node_exporter --web.listen-address=":9100" \
--log.level="info"
================================================
chmod a+x /opt/node_exporter/run_node_exporter.sh
#启动node_exporter
systemctl daemon-reload #添加或更改脚本需要执行
systemctl start node_exporter
systemctl enable node_exporter
netstat -lnp | grep 9100 #查看启动的端口
alertmanager安装
alertmanager安装
tar -xf alertmanager-0.14.0.linux-amd64.tar.gz
mv alertmanager-0.14.0.linux-amd64 /opt/alertmanager
mkdir -p /opt/alertmanager/{bin,log,data}
mv /opt/alertmanager/alertmanager /opt/alertmanager/bin/
chown -R prometheus.prometheus /opt/alertmanager
systemctl启动脚本:
cat /etc/systemd/system/alertmanager.service
=============================================
[Unit]
Description=alertmanager service
After=syslog.target network.target remote-fs.target nss-lookup.target
[Service]
LimitNOFILE=1000000
User=prometheus
ExecStart=/opt/alertmanager/run_alertmanager.sh
Restart=always
RestartSec=15s
[Install]
WantedBy=multi-user.target
=============================================
run启动脚本
cat /opt/alertmanager/run_alertmanager.sh
=============================================
#!/bin/bash
set -e
ulimit -n 1000000
DEPLOY_DIR=/opt/alertmanager
cd "${DEPLOY_DIR}" || exit 1
# WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
exec 1>> /opt/alertmanager/log/alertmanager.log 2>> /opt/alertmanager/log/alertmanager.log
exec bin/alertmanager \
--config.file="/opt/alertmanager/alertmanager.yml" \
--storage.path="/opt/alertmanager/data" \
--data.retention=120h \
--log.level="info" \
--web.listen-address=":9093"
=============================================
chmod a+x /opt/alertmanager/run_alertmanager.sh
cat alertmanager.yml #配置alertmanager文件
=============================================
global:
smtp_smarthost: 'smtp.sina.com:25'
smtp_from: 'xgmxgmxm@sina.com'
smtp_auth_username: 'xgmxgmxm@sina.com'
smtp_auth_password: 'xxxxxxxx'
templates:
- '/opt/alertmanager/template/*.tmpl'
route:
group_by: ['alertname', 'cluster', 'service']
group_wait: 30s
group_interval: 1m
repeat_interval: 2m
receiver: default-receiver
receivers:
- name: 'default-receiver'
email_configs:
- to: 'hanxiaohui@prosysoft.com'
=============================================
#启动alertmanager
systemctl daemon-reload #添加或更改脚本需要执行
systemctl start alertmanager
systemctl enable alertmanager
ps -ef | grep alertmanager #查看启动的进程
邮件告警
alertmanager配置
cat /opt/alertmanager/alert.yml
=============================================
global:
smtp_smarthost: 'smtp.sina.com:25'
smtp_from: 'xgmxgmxm@sina.com'
smtp_auth_username: 'xgmxgmxm@sina.com'
smtp_auth_password: 'xxxxxxxx' templates:
- '/opt/alertmanager/template/*.tmpl' route:
group_by: ['alertname', 'cluster', 'service']
group_wait: 30s
group_interval: 1m
repeat_interval: 2m
receiver: default-receiver receivers:
- name: 'default-receiver'
email_configs:
- to: 'hanxiaohui@prosysoft.com'
============================================= prometheus配置
vim /opt/prometheus/prometheus.yml
===========================================
# my global config
global:
scrape_interval: 15s
evaluation_interval: 15s #配置alertmanager连接
alerting:
alertmanagers:
- static_configs:
- targets:
- 172.16.0.10:9093 #配置告警规则
rule_files:
- "/opt/prometheus/test.yml"
# - "second_rules.yml" #监控主机9090是prometheus服务端,9100prometheus客户端
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['0.0.0.0:9090']
labels:
instance: 'prometheus'
- job_name: 'node_prometheus'
static_configs:
- targets: ['0.0.0.0:9100']
labels:
instance: 'node_prometheus'
=========================================== ##规则配置
cat /opt/prometheus/test.yml
=============================================
groups:
- name: test-rule
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal - (node_memory_MemFree+node_memory_Buffers+node_memory_Cached )) / node_memory_MemTotal * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 80% (current value is: {{ $value }}"
=============================================
微信告警
cat /opt/alertmanager/alert.yml #内容如下
route:
group_by: ['alertname']
receiver: 'wechat' receivers:
- name: 'wechat'
wechat_configs:
- corp_id: 'xxxxxx' #企业微信账号唯一 ID, 可以在我的企业中查看
to_party: 'x' #需要发送的组
agent_id: 'xxxxxx' #第三方企业应用的 ID,可以在自己创建的第三方企业应用详情页面查看
api_secret: 'xxxxxxx' #第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看。
告警分组
[root@prometheus rules]# cat /opt/prometheus/prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every seconds. Default is every minute.
evaluation_interval: 15s # Evaluate rules every seconds. The default is every minute. 报警规则间隔 # Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 172.16.0.22: # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/opt/prometheus/rules/node.yml" #中指定规则文件(可使用通配符,如rules/*.yml)
# - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' # metrics_path defaults to '/metrics'
# scheme defaults to 'http'. static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets:
- '172.16.0.20:9100'
- '172.16.0.21:9100'
- '172.16.0.22:9100' ===================================================== [root@prometheus rules]# cat /opt/prometheus/rules/node.yml
groups:
- name: node
rules:
- alert: server_status
expr: up{job="node"} == 0 #job='node' 实现分组
for: 15s
labels:
severity: warning
team: node #分组
annotations:
summary: "{{ $labels.instance }} is down"
- name: memUsage
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal - (node_memory_MemFree+node_memory_Buffers+node_memory_Cached )) / node_memory_MemTotal * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 80% (current value is: {{ $value }}" #配置文件设置好后,需要让prometheus重新读取,有两种方法:
通过HTTP API向/-/reload发送POST请求,例:curl -X POST http://localhost:9090/-/reload
向prometheus进程发送SIGHUP信号.例 : kill -1 prometheus进程id =========================================
[root@alert alertmanager]# cat /opt/alertmanager/alert.yml
#route属性用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
global:
smtp_smarthost: 'smtp.sina.com:25'
smtp_from: 'xxxxxxx@sina.com'
smtp_auth_username: 'xxxxxxx@sina.com'
smtp_auth_password: 'xxxxxxxxx'
route:
group_wait: 30s
group_interval: 1m
repeat_interval: 1m
group_by: [alertname]
receiver: 'wechat'
routes:
- receiver: mail
match:
team: node #rules.yml里相同team的告警 从这里发出 receivers:
- name: 'wechat'
wechat_configs:
- corp_id: 'xxxxx'
to_party: 'xxx' #'5|1'多组发送
agent_id: 'xxxxx'
api_secret: 'xxxxxx'
- name: 'mail'
email_configs:
- to: 'xxxxxx@prosysoft.com'
- to: 'xxxxxx@163.com'
Grafana安装,展示
##依赖
yum install fontconfig freetype* urw-fonts
## 安装依赖grafana运行需要go环境
yum install go -y
## 安装 grafana
yum install https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-4.6.1-1.x86_64.rpm -y 安装包信息:
二进制文件: /usr/sbin/grafana-server
init.d 脚本: /etc/init.d/grafana-server
环境变量文件: /etc/sysconfig/grafana-server
配置文件: /etc/grafana/grafana.ini
启动项: grafana-server.service
日志文件:/var/log/grafana/grafana.log
默认配置的sqlite3数据库:/var/lib/grafana/grafana.db 编辑配置文件/etc/grafana/grafana.ini ,修改dashboards.json段落下两个参数的值:
[dashboards.json]
enabled = true
path = /var/lib/grafana/dashboards 安装仪表盘JSON模版:
git clone https://github.com/percona/grafana-dashboards.git
cp -r grafana-dashboards/dashboards /var/lib/grafana/ 启动grafana,并设置开机启动:
systemctl daemon-reload
systemctl start grafana-server
systemctl status grafana-server
systemctl enable grafana-server.service
页面访问:
x.x.x.x:3000 #默认账号密码admin/admin
添加数据源
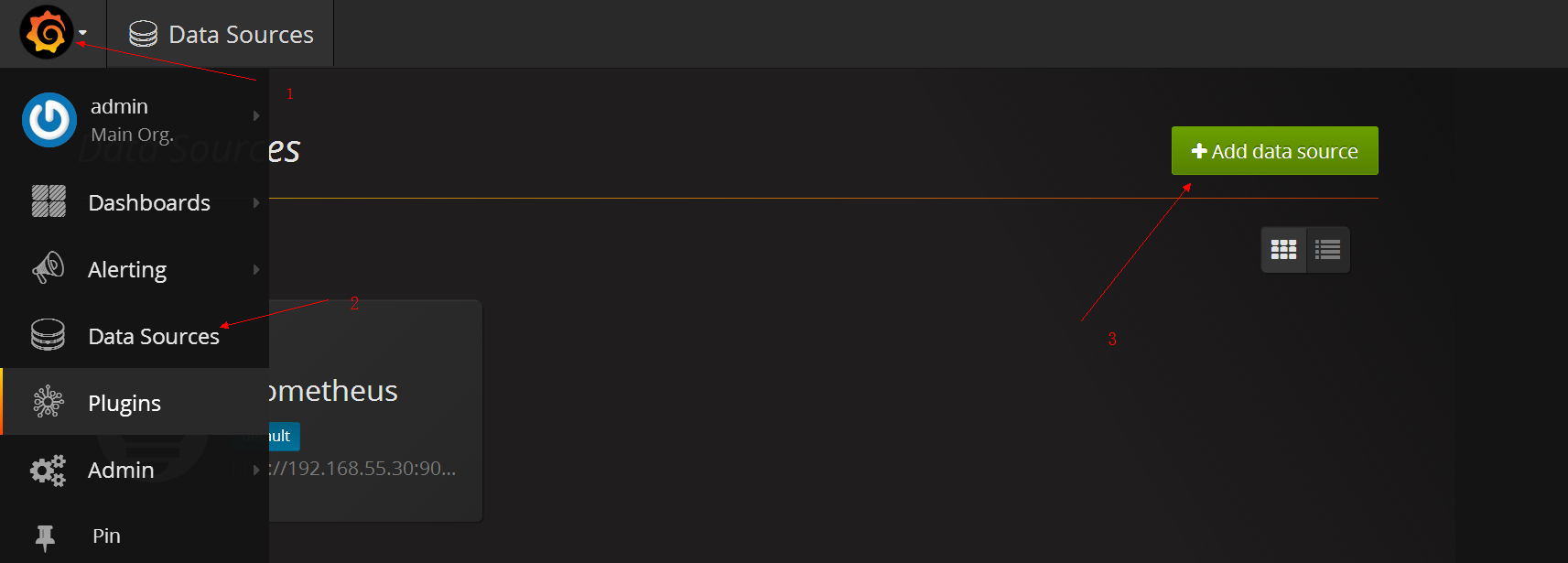
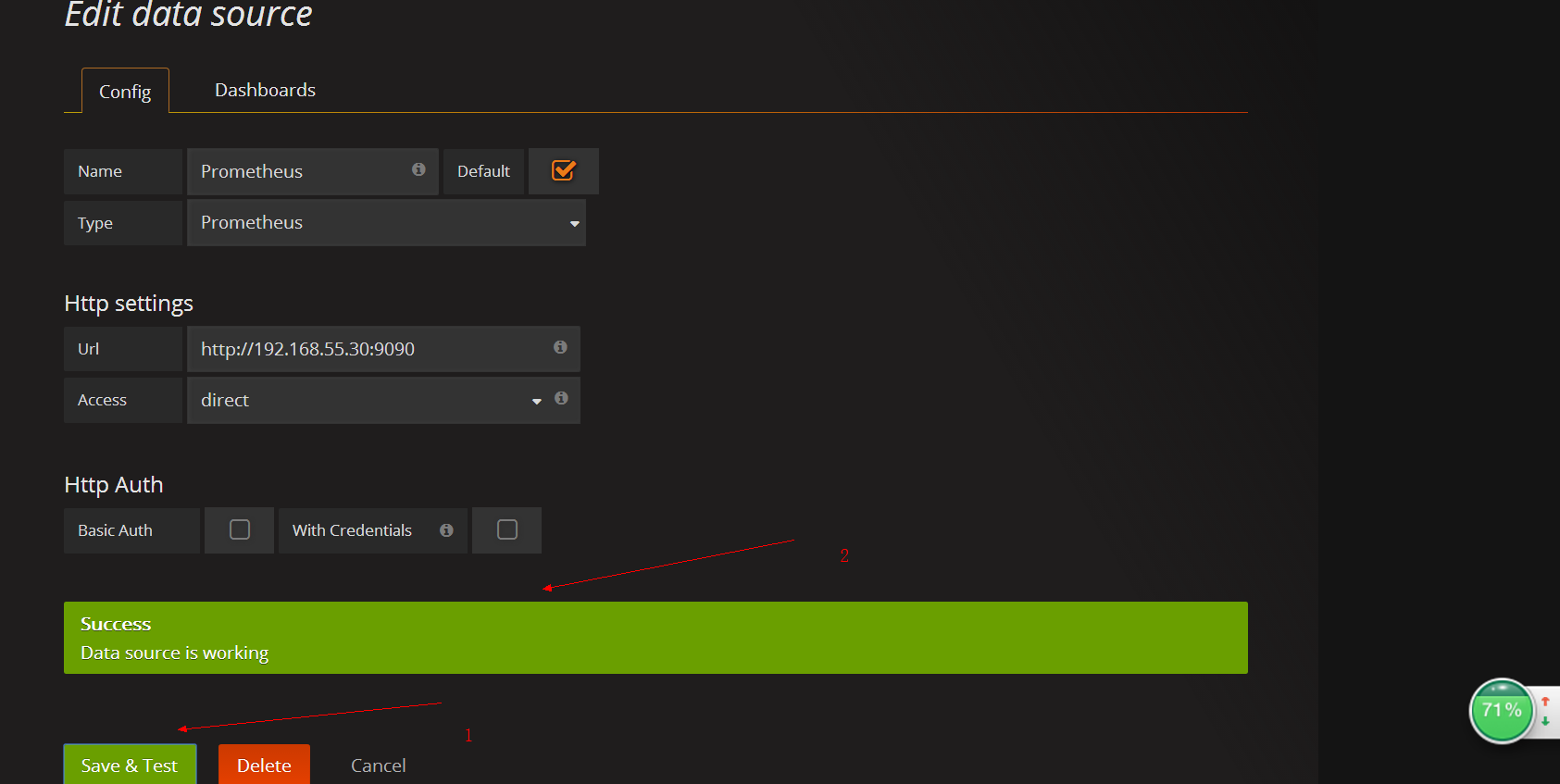
查看数据
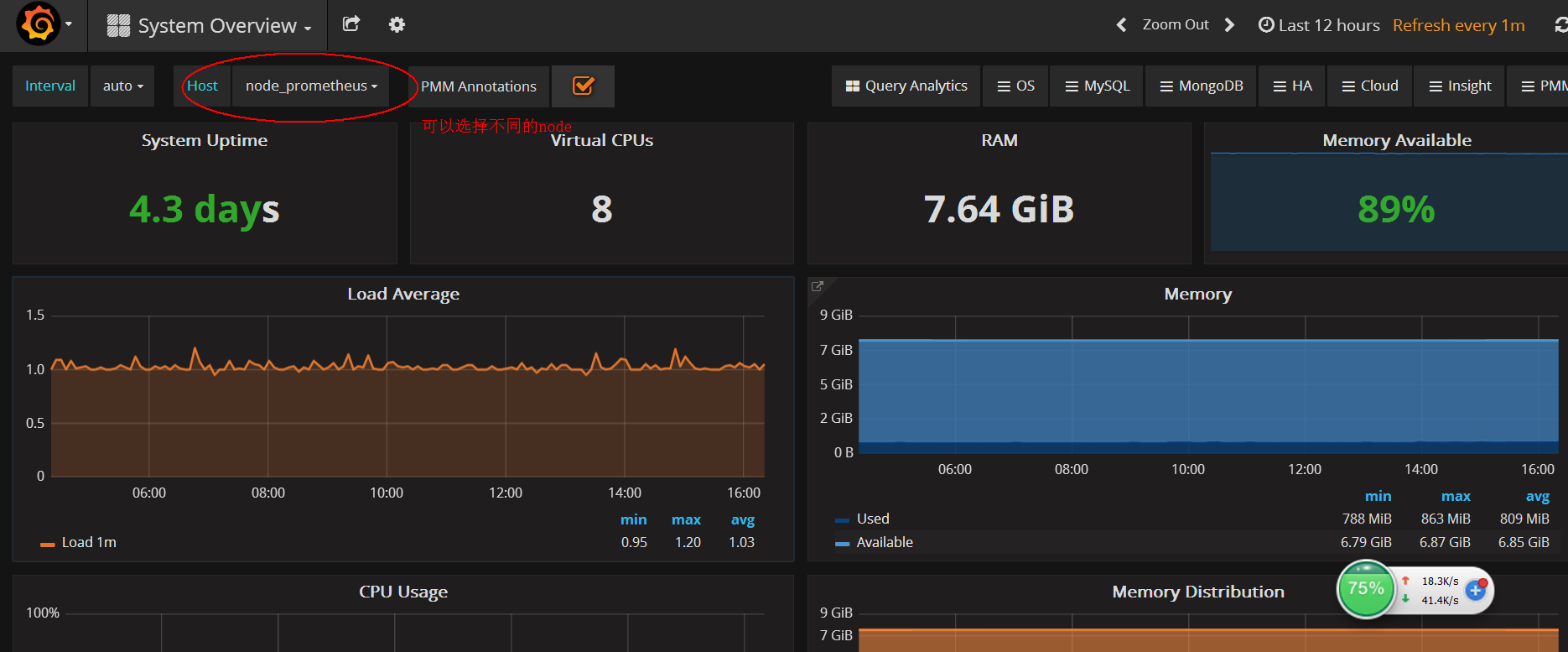
blackbox_exporter安装和配置
blackbox_exporter安装和配置 tar -xf blackbox_exporter-0.12..linux-amd64.tar.gz
mv blackbox_exporter-0.12..linux-amd64 /opt/blackbox_exporter
mkdir -p /opt/blackbox_exporter/{bin,log}
mv /opt/blackbox_exporter/blackbox_exporter /opt/blackbox_exporter/bin/ #systemd脚本
vim /etc/systemd/system/blackbox_exporter.service
=================================================
[Unit]
Description=blackbox_exporter service
After=syslog.target network.target remote-fs.target nss-lookup.target [Service]
LimitNOFILE=
User=root
ExecStart=/opt/blackbox_exporter/run_blackbox_exporter.sh
Restart=always
RestartSec=15s [Install]
WantedBy=multi-user.target
================================================= run脚本
vim /opt/blackbox_exporter/run_blackbox_exporter.sh
=================================================
#!/bin/bash
set -e
ulimit -n # WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
DEPLOY_DIR=/opt/blackbox_exporter
cd "${DEPLOY_DIR}" || exit exec >> /opt/blackbox_exporter/log/blackbox_exporter.log >> /opt/blackbox_exporter/log/blackbox_exporter.log exec bin/blackbox_exporter --web.listen-address=":9115" \
--log.level="info" \
--config.file="/opt/blackbox_exporter/blackbox.yml"
================================================= chown -R prometheus.prometheus /opt/blackbox_exporter
chmod a+x /opt/blackbox_exporter/run_blackbox_exporter.sh blackbox.yml配置
vim /opt/blackbox_exporter/blackbox.yml
=================================================
modules:
http_2xx:
prober: http
http:
method: GET
http_post_2xx:
prober: http
http:
method: POST
tcp_connect:
prober: tcp
pop3s_banner:
prober: tcp
tcp:
query_response:
- expect: "^+OK"
tls: true
tls_config:
insecure_skip_verify: false
ssh_banner:
prober: tcp
tcp:
query_response:
- expect: "^SSH-2.0-"
irc_banner:
prober: tcp
tcp:
query_response:
- send: "NICK prober"
- send: "USER prober prober prober :prober"
- expect: "PING :([^ ]+)"
send: "PONG ${1}"
- expect: "^:[^ ]+ 001"
icmp:
prober: icmp
timeout: 5s
icmp:
preferred_ip_protocol: "ip4"
================================================= 启动(注意:需要使用root来启动,不然icmp会有ping socket permission denied 的错误)
systemctl daemon-reload
systemctl start blackbox_exporter
systemctl enable blackbox_exporter
ps -ef | grep blackbox_exporter 结合prometheus
/opt/prometheus/prometheus.yml 配置
======================================================
- job_name: "blackbox_exporter_http"
scrape_interval: 30s
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- 'http://192.168.55.33:9090/metrics'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.55.33: - job_name: "app_port_tcp"
scrape_interval: 30s
metrics_path: /probe
params:
module: [tcp_connect]
static_configs:
- targets:
- '192.168.55.33:9100'
- '192.168.55.34:9100'
labels:
group: 'node'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.55.33: - job_name: "blackbox_exporter_192.168.55.33_icmp"
scrape_interval: 6s
metrics_path: /probe
params:
module: [icmp]
static_configs:
- targets:
- '192.168.55.33'
- '192.168.55.34'
relabel_configs:
- source_labels: [__address__]
regex: (.*)(:)?
target_label: __param_target
replacement: ${}
- source_labels: [__param_target]
regex: (.*)
target_label: ping
replacement: ${}
- source_labels: []
regex: .*
target_label: __address__
replacement: 192.168.55.33:
- job_name: "blackbox_exporter_192.168.55.34_icmp"
scrape_interval: 6s
metrics_path: /probe
params:
module: [icmp]
static_configs:
- targets:
- '192.168.55.33'
- '192.168.55.34'
relabel_configs:
- source_labels: [__address__]
regex: (.*)(:)?
target_label: __param_target
replacement: ${}
- source_labels: [__param_target]
regex: (.*)
target_label: ping
replacement: ${}
- source_labels: []
regex: .*
target_label: __address__
replacement: 192.168.55.34:
====================================================== rules告警配置
vim /opt/prometheus/rules/blackbox_rules.yml
======================================================
groups:
- name: alert.rules
rules:
- alert: node_exporter_is_down
expr: probe_success{group="node"} ==
for: 1m
labels:
env: test-cluster
level: emergency
expr: probe_success{group="node"} ==
annotations:
description: 'alert: instance: {{ $labels.instance }} values: {{ $value }}'
value: '{{ $value }}'
summary: Syncer server is down - alert: prometheus_metrics_interface
expr: probe_success{job="blackbox_exporter_http"} ==
for: 1m
labels:
env: puyi-cluster
level: emergency
expr: probe_success{job="blackbox_exporter_http"} ==
annotations:
description: 'alert: instance: {{ $labels.instance }} values: {{ $value }}'
value: '{{ $value }}'
summary: prometheus metrics interface is down - alert: BLACKER_ping_latency_more_than_1s
expr: max_over_time(probe_duration_seconds{job=~"blackbox_exporter.*_icmp"}[1m]) >
for: 1m
labels:
env: puyi-cluster
level: warning
expr: max_over_time(probe_duration_seconds{job=~"blackbox_exporter.*_icmp"}[1m]) >
annotations:
description: 'alert: instance: {{ $labels.instance }} values: {{ $value }}'
value: '{{ $value }}'
summary: blackbox_exporter ping latency more than 1s
====================================================== blackbox_exporter PromQL 语句
=====================================================
probe_success{job="blackbox_exporter_http"} #http 状态1是正常
max_over_time(probe_duration_seconds{job=~"blackbox_exporter.*_icmp"}[1m]) #icmp 状态1是正常
probe_success{group="node"} #node tcp_connect 状态1是正常 =====================================================
pushgateway安装和配置
安装配置
tar -xf pushgateway-0.5..linux-amd64.tar.gz
mv pushgateway-0.5..linux-amd64 /opt/pushgateway
mkdir -p /opt/pushgateway/{bin,log}
mv /opt/pushgateway/pushgateway /opt/pushgateway/bin/ systemd脚本
vim /etc/systemd/system/pushgateway.service
===========================================
[Unit]
Description=pushgateway service
After=syslog.target network.target remote-fs.target nss-lookup.target [Service]
LimitNOFILE=
User=prometheus
ExecStart=/opt/pushgateway/run_pushgateway.sh
Restart=always
RestartSec=15s [Install]
WantedBy=multi-user.target
=========================================== run脚本
vim /opt/pushgateway/run_pushgateway.sh
===========================================
#!/bin/bash
set -e
ulimit -n DEPLOY_DIR=/opt/pushgateway
cd "${DEPLOY_DIR}" || exit # WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
exec >> /opt/pushgateway/log/pushgateway.log >> /opt/pushgateway/log/pushgateway.log exec bin/pushgateway \
--log.level="info" \
--web.listen-address=":9091"
=========================================== chown -R prometheus.prometheus /opt/pushgateway chmod a+x /opt/pushgateway/run_pushgateway.sh 启动
systemctl daemon-reload
systemctl start pushgateway
systemctl enable pushgateway
systemctl status pushgateway 往pushgateway写入数据
echo "some_metric 3.14" | curl --data-binary @- http://192.168.55.33:9091/metrics/job/test
访问192.168.55.:/metrics
可以看到 some_metric{instance="",job="test"} 3.14 注意:使用pushgateway0..1版本收集 tidb的数据会报错(has label dimensions inconsistent with previously collected metrics in the same metric family),用0.4或0.3.1 pushgateway结合prometheus
vim /etc/prometheus/prometheus.yml #添加pushgateway job
====================================
- job_name: 'pushgateway'
scrape_interval: 3s
honor_labels: true # 从而避免收集数据本身的 job 和 instance 被覆盖
static_configs:
- targets:
- '192.168.55.33:9091'
==================================== 结合tidb
tidb.toml添加
=================
[status]
metrics-addr = "192.168.55.33:9091" #设为 Push Gateway 的地址
metrics-interval = #为 push 的频率,单位为秒,默认值为
report-status = true
================= 结合pd
pd.toml添加
==================
[metric]
address = "192.168.55.33:9091" #设为 Push Gateway 的地址
interval = "15s"
================== 结合tikv
tikv.toml添加
===================
[metric]
interval = "15s" #为 push 的频率,单位为秒,默认值为
address = "192.168.55.33:9091" #设为 Push Gateway 的地址
job = "tikv"
===================
PromQL
Node Exporter 常用查询语句
========================================= #例如,基于2小时的样本数据,来预测主机可用磁盘空间的是否在4个小时候被占满,可以使用如下表达式
predict_linear(node_filesystem_free{fstype="btrfs",instance="192.168.55.33:9100"}[2h], * ) < CPU 使用率:
- (avg by (instance) (irate(node_cpu{instance="xxx", mode="idle"}[5m])) * ) CPU 各 mode 占比率:
avg by (instance, mode) (irate(node_cpu{instance="xxx"}[5m])) * 机器平均负载:
node_load1{instance="xxx"} // 1分钟负载
node_load5{instance="xxx"} // 5分钟负载
node_load15{instance="xxx"} // 15分钟负载 内存使用率:
- ((node_memory_MemFree{instance="xxx"}+node_memory_Cached{instance="xxx"}+node_memory_Buffers{instance="xxx"})/node_memory_MemTotal) * 磁盘使用率:
- node_filesystem_free{instance="xxx",fstype!~"rootfs|selinuxfs|autofs|rpc_pipefs|tmpfs|udev|none|devpts|sysfs|debugfs|fuse.*"} / node_filesystem_size{instance="xxx",fstype!~"rootfs|selinuxfs|autofs|rpc_pipefs|tmpfs|udev|none|devpts|sysfs|debugfs|fuse.*"} * 网络 IO:
// 上行带宽
sum by (instance) (irate(node_network_receive_bytes{instance="xxx",device!~"bond.*?|lo"}[5m])/)
// 下行带宽
sum by (instance) (irate(node_network_transmit_bytes{instance="xxx",device!~"bond.*?|lo"}[5m])/) 网卡出/入包:
// 入包量
sum by (instance) (rate(node_network_receive_bytes{instance="xxx",device!="lo"}[5m]))
// 出包量
sum by (instance) (rate(node_network_transmit_bytes{instance="xxx",device!="lo"}[5m])) #磁盘io
avg by(instance) (irate(node_cpu{instance="192.168.55.201:9100",mode="iowait"}[5m]))* ========================================= 内置函数:
=========================================
rate (last值-first值)/时间差s #求每秒增长值
例如: rate(http_requests_total[5m]) == last-first/ irate: (last - last前一个值 )/时间差s
irate(v range-vector)函数, 输入:范围向量,输出:key: value = 度量指标: (last值-last前一个值)/时间戳差值。它是基于最后两个数据点,自动调整单调性, increase: #last - first (增加值)
increase(v range-vector)函数, 输入一个范围向量,返回:key:value = 度量指标:last值-first值,自动调整单调性,如:服务实例重启,则计数器重置。与delta()不同之处在于delta是求差值,而increase返回最后一个减第一个值,可为正为负。
========================================== 匹配符
========================================
=
例: http_requests_total{instance="localhost:9090"}
!=
例: http_requests_total{instance!="localhost:9090"}
=~
例: http_requests_total{environment=~"staging|testing|development",method!="GET"}
!~
例: http_requests_total{method!~"get|post"}
======================================== 范围查询
================================
http_requests_total{}[5m] #该表达式将会返回查询到的时间序列中最近5分钟的所有样本数据
================================ 时间位移操作
================================
而如果我们想查询,5分钟前的瞬时样本数据,或昨天一天的区间内的样本数据呢? 这个时候我们就可以使用位移操作,位移操作的关键字为offset
http_requests_total{} offset 5m #5分钟前的瞬时数据
http_requests_total{}[2m] offset 2m #2分钟前 2分钟的数据
================================ 时间单位
================================
除了使用m表示分钟以外,PromQL的时间范围选择器支持其它时间单位:
s - 秒
m - 分钟
h - 小时
d - 天
w - 周
y - 年
=================================
自定义exporter
----------------------------python_client--------------------------------
#Counter实例(只增不减)
==============================================================
from prometheus_client import start_http_server, Counter
import random
import time c = Counter('my_failures_total', 'Description of counter',['job','status'])
def my_failures_total(t): c.labels(job='test',status='ok').inc(t) #计数器增加(只增不减)
time.sleep() if __name__ == '__main__':
start_http_server()
for num in range(,):
my_failures_total(num) http://xxxxxxx:8000/metrics
================================================================ #Gauge实例 (有增有减,有set)
==================================================================
#g = Gauge('my_g_value', 'g value') 【my_g_value是监控指标 'g value'是描述】
from prometheus_client import start_http_server, Gauge
import random
import time g = Gauge('my_g_value', 'g value',['job','status'])
def my_g_value(t):
g.labels(job='test',status='ok').set(t) #设置g值
time.sleep() if __name__ == '__main__':
start_http_server()
for num in range(,):
my_g_value(num) http://xxxxxxx:8000/metrics
===================================================================
2-prometheus各组件安装的更多相关文章
- Kubernetes实战(二):k8s v1.11.1 prometheus traefik组件安装及集群测试
1.traefik traefik:HTTP层路由,官网:http://traefik.cn/,文档:https://docs.traefik.io/user-guide/kubernetes/ 功能 ...
- Prometheus Operator 的安装
Prometheus Operator 的安装 接下来我们用自定义的方式来对 Kubernetes 集群进行监控,但是还是有一些缺陷,比如 Prometheus.AlertManager 这些组件服务 ...
- Microsoft Visual Studio Web 创作组件安装失败的解决方法
在网上查一下说是Office2007的问题.我把Office2007卸载了还是不行. 然后用Windows Install Clean Up工具清理,还是不行. 郁闷了.然后在安装包中的下面路径下找到 ...
- Gulp及组件安装构建
Gulp 是一款基于任务的设计模式的自动化工具,通过插件的配合解决全套前端解决方案,如静态页面压缩.图片压缩.JS合并.SASS同步编译并压缩CSS.服务器控制客户端同步刷新. Gulp安装 全局安装 ...
- Linux下的暴力密码在线破解工具Hydra安装及其组件安装-使用
Linux下的暴力密码在线破解工具Hydra安装及其组件安装-使用 hydra可以破解: http://www.thc.org/thc-hydra,可支持AFP, Cisco AAA, Cisco a ...
- delphi 组件安装教程详解
学习安装组件的最好方法,就是自己编写一个组件并安装一遍,然后就真正明白其中的原理了. 本例,编写了两个BPL, dclSimpleEdit.bpl 与 SimpleLabel.bpl ,其中,dc ...
- 云计算OpenStack:云计算介绍及组件安装(一)--技术流ken
云计算介绍 当用户能够通过互联网方便的获取到计算.存储等服务时,我们比喻自己使用到了“云计算”,云计算并不能被称为是一种计算技术,而更像是一种服务模式.每个运维人员心里都有一个对云计算的理解,而最普遍 ...
- OpenStack基础组件安装keystone身份认证服务
域名解析 vim /etc/hosts 192.168.245.172 controller01 192.168.245.171 controller02 192.168.245.173 contro ...
- 一、OpenStack环境准备及共享组件安装
一.OpenStack部署环境准备: 1.关闭防火墙所有虚拟机都要操作 # setenforce 0 # systemctl stop firewalld 2.域名解析所有虚拟机都要操作 # cat ...
- VS2008安装“Visual Studio Web 创作组件”安装失败的解决方法
VS2008安装“Visual Studio Web 创作组件”安装失败的解决方法 今天在单位电脑安装VS2008,当安装到“Visual Studio Web 创作组件”时出现错误. 准备手动安装 ...
随机推荐
- 安装mysql数据库-centos7
mysql官网下载地址:https://dev.mysql.com/downloads/mysql/ 参考安装:https://blog.51cto.com/snowlai/2140451?sourc ...
- 大数据学习笔记之Zookeeper(三):Zookeeper理论篇(二)
文章目录 3.1 数据结构 3.2 节点类型 3.3 特点 3.4 选举机制 3.5 stat结构体 3.6 监听器原理 3.1 数据结构 ZooKeeper数据模型的结构与Unix文件系统很类似,整 ...
- HeightCharts柱状图和饼状图
HTML: <div id="container1" style="height:350px; " ></div> <di ...
- python可变数据类型和不可变数据类型
1.可变数据类型:在id不变的情况下,value可改变(列表和字典是可变类型,但是字典中的key值必须是不可变类型) 2.不可变数据类型:value改变,id也跟着改变.(数字,字符串,布尔类型,都是 ...
- solr的moreLikeThis实现“相似数据”功能
在我们使用网页搜索时,会注意到每一个结果都包含一个 “相似页面” 链接,单击该链接,就会发布另一个搜索请求,查找出与起初结果类似的文档.Solr 使用 MoreLikeThisComponent(ML ...
- Spring学习(二)--装配Bean
一.Spring装配机制 Spring提供了三种主要的装配机制: 1.在XML中进行显示配置 2.在Java中进行显示配置 3.隐式的bean发现机制和自动装配--自动化装配bean Spring可以 ...
- 什么是SpringMvc
1.什么是SpringMvc? SpringMvc是spring的一个模块 基于MVC的一个框架 无需中间整合层来整合 什么是MVC ?mvc在b/s下的应用: 首先请求发送request请求到C(c ...
- spring-第八篇之容器中的bean的生命周期
1.容器中的bean的生命周期 spring容器可以管理singleton作用域的bean的生命周期,包括bean何时被创建.何时初始化完成.何时被销毁.客户端代码不能控制该类型bean的销毁.spr ...
- Spring Boot 静态资源处理,妙!
作者:liuxiaopeng https://www.cnblogs.com/paddix/p/8301331.html 做web开发的时候,我们往往会有很多静态资源,如html.图片.css等.那如 ...
- [fw]Linux下tty/pty/pts/ptmx详解
基本概念: 1> tty(终端设备的统称):tty一词源于Teletypes,或者teletypewriters,原来指的是电传打字机,是通过串行线用打印机键盘通过阅读和发送信息的东西,后来这东 ...