Gradient Vanishing Problem in Deep Learning
在所有依靠Gradient Descent和Backpropagation算法来学习的Neural Network中,普遍都会存在Gradient Vanishing Problem。Backpropagation的运作过程是,根据Cost Function进行反向传播,利用Chain Rule去计算n层之前某一weight上的梯度,从而更新该weight。而事实上,在网络层次较深的情况下,我们获得的weight梯度,随着反向传播层次的深入,会呈现越来越小的状态。从而,在靠近输出端的Layers中,weight可以被很好的更新,因为可以获得不错的gradient,而在靠近输入端的Layers中,weight则更新缓慢。
举个最简单的例子,来说明该问题。如下的神经网络有四层,每层有一个node:

我们可知w是weight,b是bias,每一层的节点输入是z,输出是a,activation function是a=σ(z),我们可以得出:
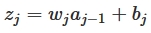
当我们已知Cost Function时,我们利用Backpropagation计算weight:
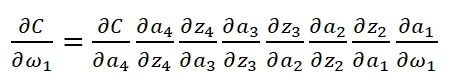
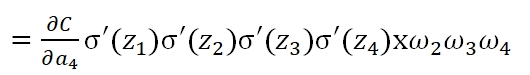
可以看到,第一层的weight梯度,依赖于之后各层activation function的一阶导数之积。而对于Machine Learning中常用的Sigmoid及tanh激励函数,其derivative图像如下:
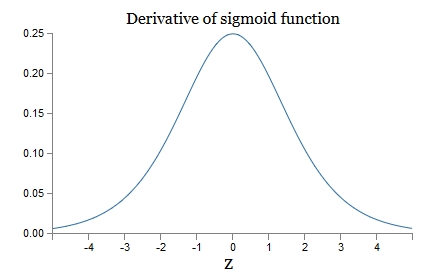
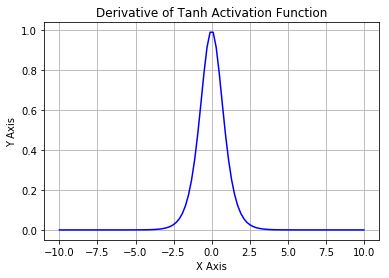
Sigmoid的derivative是[0,0.25]的,而tanh的derivative是[0,1]的。通过上式,我们看出,通过Backpropagation求梯度时,每往回传播一层,就要多乘以一项δ‘(z),也就是说,随着向回传递的深入,梯度会呈指数级的衰减,直至缩减到0,导致前层的权重无法更新。tanh要略好于sigmoid,但依然难以解决Gradient Vanishing的问题。所以Relu Function应运而生,并且在Deep Learning方面取得了巨大成功。Relu的表达式及图形如下:
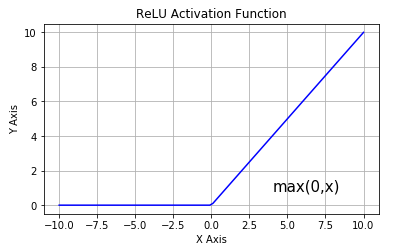
其当x>0时,derivative是1,小于0时,derivative为0。该函数很好的解决了Gradient Vanishing Problem,在大多数情况下,我们构建Deep Learning时可以使用Relu作为默认的Activation Function。
Gradient Vanishing Problem in Deep Learning的更多相关文章
- (转)WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE
Main Menu Fortune.com E-mail Tweet Facebook Linkedin Share icons By Roger Parloff Illustration ...
- Growing Pains for Deep Learning
Growing Pains for Deep Learning Advances in theory and computer hardware have allowed neural network ...
- Deep Learning Libraries by Language
Deep Learning Libraries by Language Tweet Python Theano is a python library for defining and ...
- Deep learning with Python
一.导论 1.1 人工智能.机器学习.深度学习 人工智能.机器学习 人工智能:1980年代达到高峰的是专家系统,符号AI是之前的,但不能解决模糊.复杂的问题. 机器学习是把数据.答案做输入,规则作输出 ...
- This instability is a fundamental problem for gradient-based learning in deep neural networks. vanishing exploding gradient problem
The unstable gradient problem: The fundamental problem here isn't so much the vanishing gradient pro ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Assignment(Gradient Checking)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. Gradient Checking Welcome to the final assignment for this week! In ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第一周(Practical aspects of Deep Learning) —— 4.Programming assignments:Gradient Checking
Gradient Checking Welcome to this week's third programming assignment! You will be implementing grad ...
- Deep Learning专栏--强化学习之从 Policy Gradient 到 A3C(3)
在之前的强化学习文章里,我们讲到了经典的MDP模型来描述强化学习,其解法包括value iteration和policy iteration,这类经典解法基于已知的转移概率矩阵P,而在实际应用中,我们 ...
- Deep Learning in a Nutshell: History and Training
Deep Learning in a Nutshell: History and Training This series of blog posts aims to provide an intui ...
随机推荐
- Fiddler用法整理
目 录 1 Fiddler的基本介绍 1.1 下载安装 1.2 适用平台 2 Fiddler的工作原理 3 同类工具 4 捕获非IE浏览器的会话 5 捕获不同请求的设置方法 5.1 Web HTTPS ...
- SpringBootTest单元测试及日志
springboot系列学习笔记全部文章请移步值博主专栏**: spring boot 2.X/spring cloud Greenwich. 由于是一系列文章,所以后面的文章可能会使用到前面文章的项 ...
- XMLHttpRequest.setRequestHeader()
在AJAX中,如果需要像 HTML 表单那样 POST 数据,需要使用 setRequestHeader() 方法来添加 HTTP 头. 然后在 send() 方法中规定需要希望发送的数据: setR ...
- Nodejs的模块化
Node.js中的模块化 好处: 复用性高,一次定义,多次使用 前端模块化 AMD AMD的实现需要使用 require.js CMD CMD的实现需要使用 sea.js [ 不更新 ] Common ...
- 【转】SPI FLASH与NOR FLASH的区别 详解SPI FLASH与NOR FLASH的不一样
转自:http://m.elecfans.com/article/778203.html 本文主要是关于SPI FLASH与NOR FLASH的相关介绍,并着重对SPI FLASH与NOR FLASH ...
- python 日期生成和时间格式化
记录下日期时间的转换和生成:1.这个是使用datetime 函数生成往后几天的时间,比如当前日期是2019-07-01 那么控制days=1然后再和当前的时间相加,就能得到明天的日期def time_ ...
- 【leetcode】449. Serialize and Deserialize BST
题目如下: Serialization is the process of converting a data structure or object into a sequence of bits ...
- 对logistic回归分析的两重认识
logistic回归,回归给人的直观印象只是要求解一个模型的系数,然后可以预测某个变量的回归值.而logistic回归在应用中多了一层含义,它经常应用于分类中.第一重认识:logistic是给真正的回 ...
- orm中 如何模糊匹配某一年的用户和某一事时间段的用户
导入Q查询
- BZOJ 4408: [Fjoi 2016]神秘数 主席树 + 神题
Code: #include<bits/stdc++.h> #define lson ls[x] #define mid ((l+r)>>1) #define rson rs[ ...