集成学习-Adaboost 进阶
adaboost 的思想很简单,算法流程也很简单,但它背后有完整的理论支撑,也有很多扩展。
权重更新
在算法描述中,权重如是更新
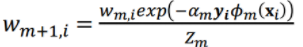
其中 wm,i 是m轮样本i的权重,αm是错误率,Øm是第m个基学习器的输出,Zm是归一化因子
当预测值与真实值相同时,yØ=1,-αyØ<0,exp(-αyØ)<1,权重降低;
当预测值与真实值不同时,yØ=-1,-αyØ>0,exp(-αyØ)>1,权重增加;
而且变化幅度由α确定;
这样可以说得通,但是这个式子是怎么来的呢?
原理推导
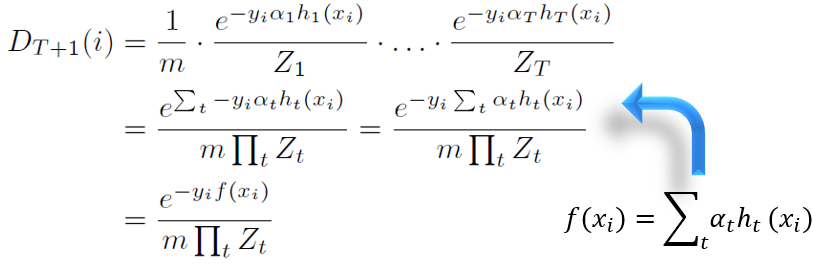
第一个式子表示权重的连乘,每个乘子是第t轮的权重,前T个乘子就是 DT,用DT乘以最后一项就是最开始的式子。
f(x)是组合分类器的输出,yi是个常数,所以上式如是变形。
这里要注意,h(x)是基分类器的输出,其值域为{-1,1},而f(x)是组合分类器的输出,其值域不是{-1,1}
错误上界
Abdboost 一个很重要的特性就是拥有错误上界,而且随着迭代的增加,上界逐渐降低。
首先

这里的 H(x) 是 adaboost 最后的输出,f(x)为组合分类器的输出,H(x)=sign(f(x)),很容易推出 yf(x)≤0
[H(x)≠y] 表示当 [ ] 内成立时,值为1,否则为0,显然
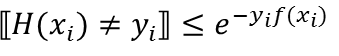

m为样本个数
显然不等号左边就是错误率
由【权重更新】的公式可得
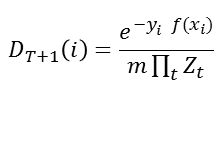
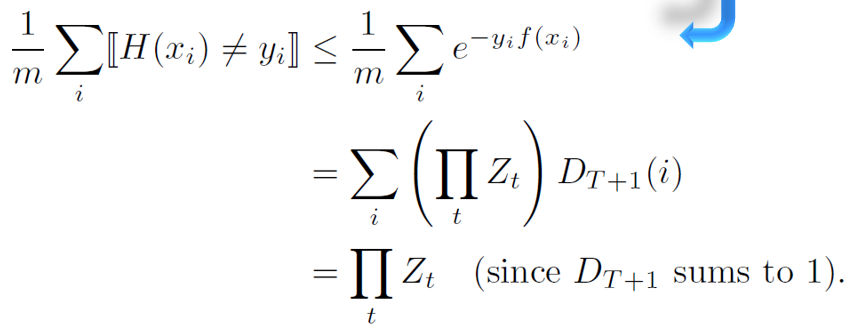
D是归一化的,ΣD和为1
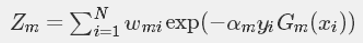
错误上界就是 ∏Z
感性理解:Z是权重 x 损失,基分类器越好,Z越小,基分类器越多,ΠZ越小
损失函数
错误率存在上界ΠZ,其实就是损失函数
指数损失函数
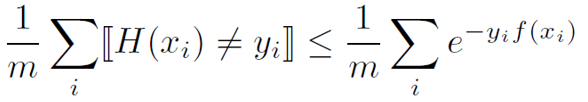
实际上Adaboost的损失函数为指数损失函数
指数损失函数有个特性:分错时,损失很大,分对时,损失很小,指数级增加,这使得减小损失的重点放在分错的样本上。
这就是 Adaboost 的思想。
到这你可能认为这个指数损失来的蹊跷,明明是ΠZ啊,确实如此,Adaboost作者的说法是,指数损失函数并不是算法设计的初衷,但是它更好的解释了算法,并提供了扩展空间。
为什么是加性模型
最终的损失函数为 ΠZ
这个损失函数是连乘,且乘子之间存在串行关系,这很难通过梯度下降等方法获取最优解。
采用贪心策略,保证每个Z最小,那就认为 ΠZ 最小。
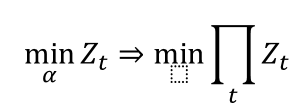
这就是 Adaboost 为什么是加性模型。
梯度下降
每一步最小化损失 Z
先对 exp(-αyh(x)) 实施一个很常用的变形
当 y=h(x) 时,exp(-αyh(x))=exp(-α)
当 y≠h(x) 时,exp(-αyh(x))=exp(α)
只能取两个值
那么 exp(-αyh(x)) 到底等于 exp(-α) 还是 exp(α),或者说以一定概率等于 exp(-α) 和 exp(α)
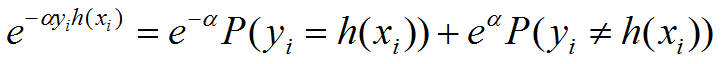
二分类,两个概率和为1
对Z进行梯度下降
Z对应了一个固定的分类器,预使Z最小,能改变的只有α,于是对α求导,令导数等于0
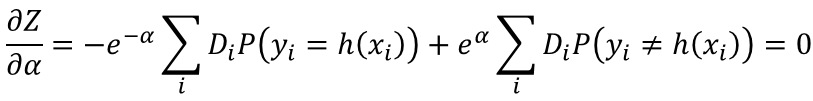
P(y≠h(x)) 即错误的概率,也就是错误率,用ε表示
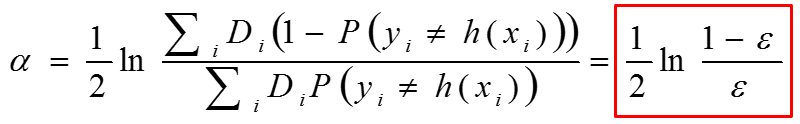
α 就是加性模型的系数
也就是算法流程中基分类器的系数。
为什么错误率要小于0.5
有人说错误率大于0.5,还不如瞎猜,基分类器太渣,有一定道理
但从数学角度来考虑,当ε<0.5时,α<0,也就是说这个分类器只起到了反作用,请问你是来捣乱的吗?轰出去
处理方式有两种,一是直接结束迭代,二是放弃这个基分类器,重新训练一个,这种适合带随机的Adaboost。
此时再来看Adaboost的算法流程

每一步是不是很清楚。
多分类
原始的 Adaboost 是二分类模型,是因为最后的 sign 只能映射到2个类。
那能否实现多分类呢?当然可以,并且有多种方法
Adaboost.M1
纵观上面的原理推导,只有在对Z求导时,用到了二分类,即两个概率和为1,
但是对一个样本而言,它的预测值只有等和不等真实值两种情况,所以不管是多分类还是二分类,求导方法相同。
再来看看求导过程
确实如上所说。
M1的思路和Adaboost完全相同,只是把基分类器由二分类器改成了多分类器,最后的sign函数肯定要换掉

其实就是统计哪个类被分的最多,只是计数时要乘以权重。
缺点:Adaboost 要求基分类器错误率小于0.5,这对二分类器来说很正常,但是对于多分类器过于严格。
Adaboost.SAMME
M1的改进版
与Adaboost算法流程相同,只是改变了分类器权重的计算
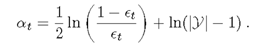
其他基本同M1,算法大致如下

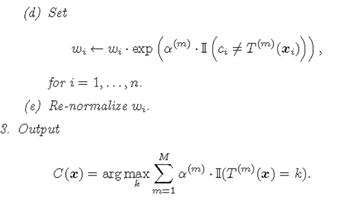
要使 α>0
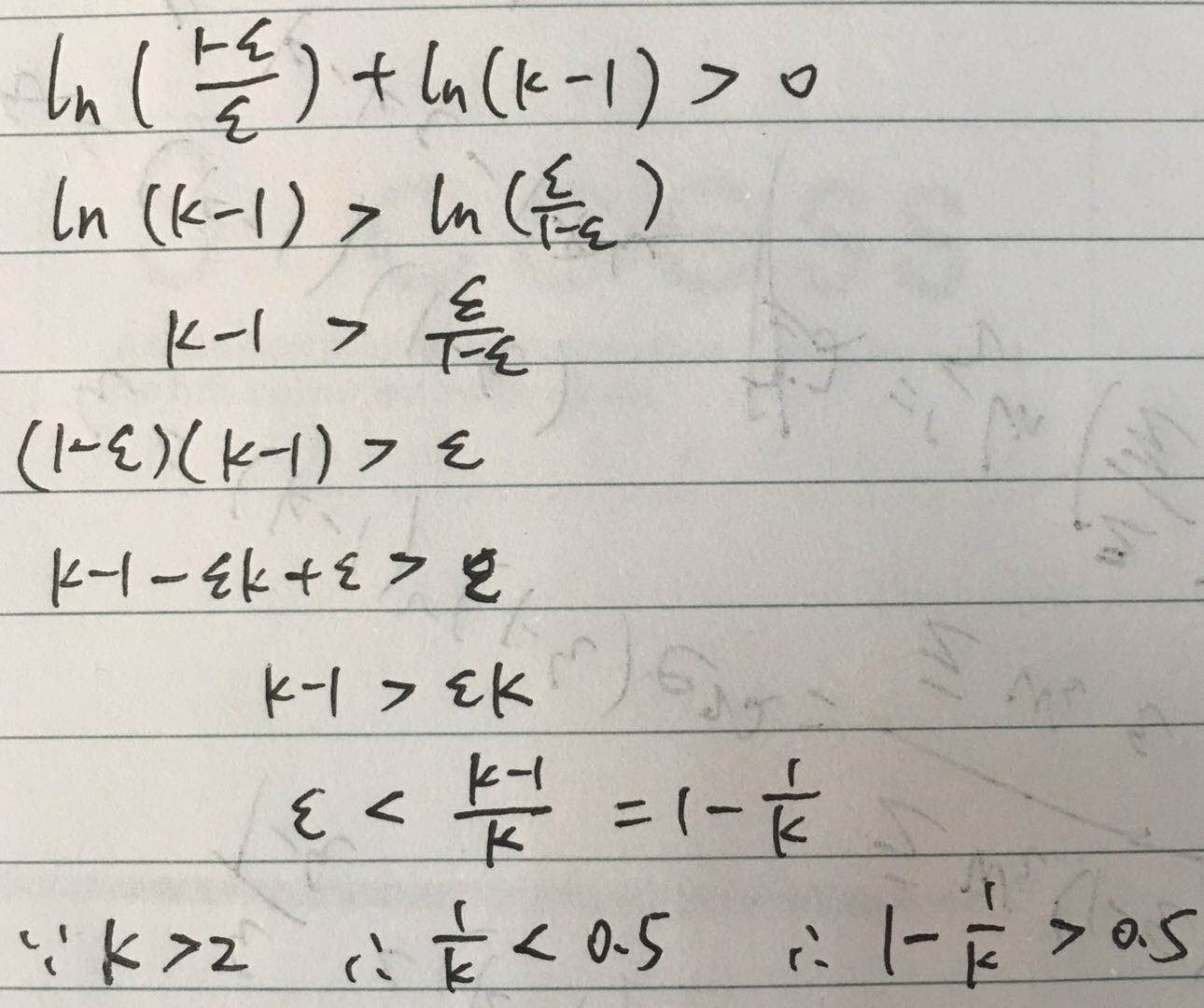
此时 错误率 不是小于0.5,而是1-1/k,如0.8,0.9等,更为宽松,解决了M1的问题。
Adaboost.SAMME.R
该算法类似 Adaboost.SAMME,只是它使用的基分类器输出为概率。
具体请百度
Adaboost.MH
采用一对多的思想,见我的博客 二分类实现多分类
还有其他实现多分类的方法,不再赘述。
VS 随机森林
随机森林,每棵树是个强分类器,甚至过拟合,偏差很小,方差很大,模型目标主要是降低方差;
Adaboost,每棵树是个弱分类器,偏差很大,方差很小,模型目标主要是降低偏差。 【偏差降低后,模型目的达到,就成了强分类器】
参考资料:
https://zhuanlan.zhihu.com/p/34842057
https://zhuanlan.zhihu.com/p/25096501
https://www.zhihu.com/search?type=content&q=adaboost%20%20mh
集成学习-Adaboost 进阶的更多相关文章
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 集成学习-Adaboost
Adaboost 中文名叫自适应提升算法,是一种boosting算法. boosting算法的基本思想 对于一个复杂任务来说,单个专家的决策过于片面,需要集合多个专家的决策得到最终的决策,通俗讲就是三 ...
- 机器学习算法总结(三)——集成学习(Adaboost、RandomForest)
1.集成学习概述 集成学习算法可以说是现在最火爆的机器学习算法,参加过Kaggle比赛的同学应该都领略过集成算法的强大.集成算法本身不是一个单独的机器学习算法,而是通过将基于其他的机器学习算法构建多个 ...
- 集成学习AdaBoost算法——学习笔记
集成学习 个体学习器1 个体学习器2 个体学习器3 ——> 结合模块 ——>输出(更好的) ... 个体学习器n 通常,类似求平均值,比最差的能好一些,但是会比最好的差. 集成可能提 ...
- 集成学习——Adaboost(手推公式)
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 集成学习原理:Adaboost
集成学习通过从大量的特征中挑出最优的特征,并将其转化为对应的弱分类器进行分类使用,从而达到对目标进行分类的目的. 核心思想 它是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器), ...
- 集成学习之Boosting —— AdaBoost原理
集成学习大致可分为两大类:Bagging和Boosting.Bagging一般使用强学习器,其个体学习器之间不存在强依赖关系,容易并行.Boosting则使用弱分类器,其个体学习器之间存在强依赖关系, ...
随机推荐
- 安装MongoDB到CentOS 6
MongoDB是一个面向海量文档存数据动态存储的NoSQL型数据库.是一个除了用于关系型数据库如MySQL,PostgreSQL数据库表格的格式,和微软SQL以外的一种数据模型存储形式.他的功能包括了 ...
- unittest详解(六) 断言
我们在执行测试用例时,怎么来判断这条用例是否通过呢?唯一的办法就是拿实际结果和预期结果进行比较,如果一致用例就是通过的,否则用例就是失败的.在python中这种比较的方法就叫做断言,unittest框 ...
- UMG里没有"Prefab"怎么办?
大家知道在Unity里做UI,利用Prefab是少不了的,但是在UE4里如何做呢? 这是实际工作中遇到的问题,我Google关键词“UMG Prefab","UMG resuabl ...
- HUD 1166:敌兵布阵(线段树 or 树状数组)
敌兵布阵 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Problem Des ...
- @Transient使用心得
使用注解@Transient使表中没有此字段 注意,实体类中要使用org.springframework.data.annotation.Transient 在写实体类时发现有加@Transient注 ...
- HomeBrew安装MongoDB如何启动
1.先安装HomeBrew 安装(需要 Ruby): ruby -e "$(curl -fsSL https://raw.github.com/Homebrew/homebrew/go/in ...
- android gradle,groovy--https://blog.csdn.net/hebbely/article/details/79074460
android grale,groovyhttps://blog.csdn.net/hebbely/article/details/79074460 Gradle编译时报错:gradle:peer n ...
- vs2015使用低版本编译的openssl问题
用Vs2005编译的openssl,在vs2015中使用就悲剧了,报如下错误 >libeay32.lib(cryptlib.obj) : error LNK2019: 无法解析的外部符号 __v ...
- 异步上传&预览图片-不压缩图片
本例使用ajaxFileUpload异步上传预览图片 <bean id="multipartResolver" class="org.springframework ...
- C# 隐藏显示桌面图标
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...