adam优化
AdaGrad (Adaptive Gradient,自适应梯度)
对每个不同的参数调整不同的学习率,
对频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长进行更新。

gt表示第t时间步的梯度(向量,包含各个参数对应的偏导数,gt,i表示第i个参数t时刻偏导数)
gt2表示第t时间步的梯度平方(向量,由gt各元素自己进行平方运算所得,即Element-wise)
优势:数据稀疏时,能利用稀疏梯度的信息,比标准的SGD算法更有效地收敛。
缺点:母项的对梯度平方不断累积,随之时间步地增加,分母项越来越大,最终导致学习率收缩到太小无法进行有效更新。

Adam更新规则
计算t时间步的梯度:
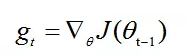
1.计算梯度的指数移动平均数,m0 初始化为0
β1 系数为指数衰减率,控制权重分配(动量与当前梯度),通常取接近于1的值。默认为0.9

2.计算梯度平方的指数移动平均数,v0初始化为0。
β2 系数为指数衰减率,控制之前的梯度平方的影响情况。默认为0.999
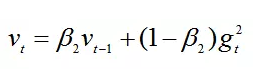
3.由于m0初始化为0,会导致mt偏向于0,对其进行纠正
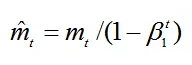
4.v0初始化为0导致训练初始阶段vt偏向0,对其进行纠正
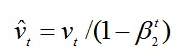
5.更新参数,其中默认学习率α=0.001ε=10^-8,避免除数变为0。

6.代码
class Adam:
def __init__(self,loss,weights,lr=0.001,beta1=0.9,beta2=0.999,epislon=1e-8):
self.loss=loss
self.theta=weights
self.lr=lr
self.beta1=beta1
self.beta2=beta2
self.epislon=epislon
self.get_gradient=grad(loss)
self.m=0
self.v=0
self.t=0
def minimize_raw(self):
self.t+=1
g=self.get_gradient(self.theta)
self.m=self.beta1*self.m+(1-self.beta1)*g
self.v=self.beta2*self.v+(1-self.beta2)*(g*g)
self.m_cat=self.m/(1-self.beta1**self.t)
self.v_cat=self.v/(1-self.beta2**self.t)
self.theta-=self.lr*self.m_cat/(self.v_cat**0.5+self.epislon)
print("step{:4d} g:{} lr:{} m:{} v:{} theta{}".format(self.t, g, self.lr, self.m, self.v, self.theta))
def minimize(self):
self.t+=1
g=self.get_gradient(self.theta)
lr=self.lr*(1-self.beta2**self.t)**0.5/(1-self.beta1**self.t)
self.m=self.beta1*self.m+(1-self.beta1)*g
self.v=self.beta2*self.v+(1-self.beta2)*(g*g)
self.theta-=lr.self.m/(self.v**0.5+self.epislon)
print("step{:4d} g:{} lr:{} m:{} v:{} theta{}".format(self.t, g, lr, self.m, self.v, self.theta))
adam优化的更多相关文章
- Adam优化算法
Question? Adam 算法是什么,它为优化深度学习模型带来了哪些优势? Adam 算法的原理机制是怎么样的,它与相关的 AdaGrad 和 RMSProp 方法有什么区别. Adam 算法应该 ...
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
- 跟我学算法-吴恩达老师(mini-batchsize,指数加权平均,Momentum 梯度下降法,RMS prop, Adam 优化算法, Learning rate decay)
1.mini-batch size 表示每次都只筛选一部分作为训练的样本,进行训练,遍历一次样本的次数为(样本数/单次样本数目) 当mini-batch size 的数量通常介于1,m 之间 当 ...
- 简单认识Adam优化器
转载地址 https://www.jianshu.com/p/aebcaf8af76e 基于随机梯度下降(SGD)的优化算法在科研和工程的很多领域里都是极其核心的.很多理论或工程问题都可以转化为对目标 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- (五) Keras Adam优化器以及CNN应用于手写识别
视频学习来源 https://www.bilibili.com/video/av40787141?from=search&seid=17003307842787199553 笔记 Adam,常 ...
- PyTorch-Adam优化算法原理,公式,应用
概念:Adam 是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重.Adam 最开始是由 OpenAI 的 Diederik Kingma 和多伦多大学的 Jim ...
- 深度学习剖根问底: Adam优化算法的由来
在调整模型更新权重和偏差参数的方式时,你是否考虑过哪种优化算法能使模型产生更好且更快的效果?应该用梯度下降,随机梯度下降,还是Adam方法? 这篇文章介绍了不同优化算法之间的主要区别,以及如何选择最佳 ...
- 神经网络优化算法:Dropout、梯度消失/爆炸、Adam优化算法,一篇就够了!
1. 训练误差和泛化误差 机器学习模型在训练数据集和测试数据集上的表现.如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不⼀定更准确.这是为什么呢 ...
随机推荐
- leetcode-mid-math-29. Divide Two Integers-NO
mycode 91.28% class Solution(object): def divide(self, dividend, divisor): """ :typ ...
- hibernate缓存机制与N+1问题
在项目中遇到的趣事 本文基于hibernate缓存机制与N+1问题展开思考, 先介绍何为N+1问题 再hibernate中用list()获得对象: /** * 此时会发出一条sql,将30个学生全部查 ...
- 构造Map并对其排序
#构造Map并对其排序 attr_tul = ['a','b','c','d','e','f'] one_tul = [,,,,,] one_dic = {} for i in range(len(a ...
- python学习之requests基础
学习地址:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html#id2 使用requests发送网络请求 一.导入requ ...
- 设置了responseType:Blob之后,如果返回json错误信息,如果获取?
最近做了一个文件下载功能,于是设置了responseType: Blob的方式, 什么是Blob呢,MDN官方解释:Blob 对象表示一个不可变.原始数据的类文件对象.Blob 表示的不一定是Java ...
- Matlab——数值计算——单个代数方程 代数方程组
方程求解 求解单个代数方程 MATLAB具有求解符号表达式的工具,如果表达式不是一个方程式(不含等 号),则在求解之前函数solve将表达式置成等于0. >> syms a syms b ...
- QA的工作职责是什么?
目前不知道,后续一点一点查资料补充吧 QA不管做什么的类型的测试,最基础的功能测试,需要搭建测试环境:进阶部分的性能压力测试,对搭建环境的要求更高:接口功能测试,搭建测试环境,和功能测试的差不多: 测 ...
- expect实战
1.测试主机是否在线 #!/bin/bash#创建一个IP地址文件.>ip.txt (清空文本)#使用for循环ping测试主机是否在线.for i in {2..254}do ...
- numpy添加新的维度
原文链接:https://blog.csdn.net/xtingjie/article/details/72510834 numpy中包含的newaxis可以给原数组增加一个维度 np.newaxis ...
- call 和 apply的定义和区别?
1.方法定义 call方法: 语法:call([thisObj[,arg1[, arg2[, [,.argN]]]]]) 定义:调用一个对象的一个方法,以另一个对象替换当前对象. 说明: call ...