java中的集合类详情解析以及集合和数组的区别
数组和链表
- 数组:所谓数组就是相同数据类型的元素按照一定顺序排列的集合。
它的存储区间是连续的,占用内存严重,所以空间复杂度很大,为o(n),但是数组的二分查找时间复杂度很小为o(1)。
特点是大小固定,不可变,在同一个数组中只能存放同一个类型的数据,寻址容易,插入和删除困难。 - 链表:所谓链表就是一种物理存储单元上非连续的,非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针实现的。链表是由一系列节点(链表中每个元素称为节点)组成的,节点是可以动态生成的。每个节点包括两部分:一个是存储数据元素的数据域,另一个是存储下一个节点地址的指针域。
链表的特点:链表存储区间离散,占用内存较少,所以空间复杂度小,但是时间复杂度大o(n),寻址困难,但是插入和删除元素很容易。 - 集合:可以操作数量可变和类型不同的一组数据。所有的java集合都在java.util包中,java集合只能存放引用类型的数据,不能存放基本类型数据。
ArrayList的底层实现方式
- ArrayList底层是通过数组实现的,实例化ArrayList无参构造函数默认数组初始化长度为10。
- add方法底层实现如果增加的元素个数超过了10个,那么ArrayList底层会新生成一个数组,长度变为原数组的1.5倍+1,然后将原始数组的元素复制到新数组中,并且后续增加的元素都会放到新数组中。当新数组也无法满足元素大小时,继续重复这个扩容的过程。只要元素长度超过了容量就开始扩容。扩容数组调用的方法为ArrayList.copyOf(objArr,objArr.length+1)。
ArrayList和Vector的区别
ArrayList和vector都实现了list接口(list接口继承了collection接口),他们都是有序集合,并且允许有重复的元素存在。他们相当于是一种动态的数组,所以可以通过下标的方式取出某一个元素。
他们的区别主要体现在以下两个方面:
- 同步性
vector是线程安全的,也就是说它的方法之间是线程同步的,而ArrayList是线程不安全的,它的方法之间是线程不同步的。如果只有一个线程会访问到集合,那么可以使用ArrayList,因为它不考虑线程安全问题,效率比较高。如果多个线程要访问到集合,那么最好是用vector,因为它是线程安全的,不用我们去考虑线程问题。 - 数据增长策略
ArrayList和vector都有一个初始容量大小,当数据长度超过了这个容量大小就需要扩容。vector默认增长为原来数据长度的2倍,而ArrayList是增长为原来的1.5倍。
ArrayList和vector都可以设置初始空间的大小,此外vector还可以设置增长的空间大小,而ArrayList没有提供设置增长空间的方法。
LinkedList的底层实现方式
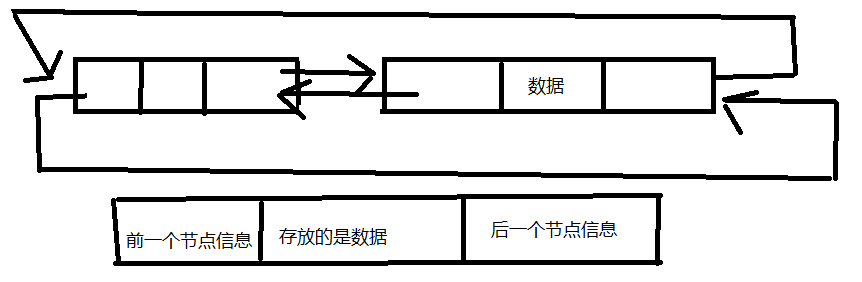
linkedlist底层的数据结构是基于双向循环链表实现的,并且头结点中不存放数据。
如下图(图太丑了,将就着看,不讲究了):
hashmap的底层实现原理
hashmap是map集合的实现类之一,
它的特点有:
- 以键值对的形式存储值
- 键不能重复而值可以重复
- 允许有null的键和值
- 并且线程不安全所以效率很快,方法也不是同步的。
hashmap是基于hashing原理,用put(key,value)存储对象到hashmap中,使用get(key)从hashmap中获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashcode()方法来计算hashcode,然后找到bucket位置来存储值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。hashmap是在bucket中存储键对象和值对象的。
如果hashmap的大小超过了负载因子(load factor)定义的容量(默认为0.75),它将会像其他集合类一样采取扩容,将会创建原来hashmap大小2倍的bucket数组,来重新调整map的大小,并且将原来的对象放入新的bucket数组中。这个过程叫做rehashing。因为它会调用hash方法找到新的bucket数组位置。hashmap使用链表来解决碰撞问题,当发生了碰撞,对象将会存储在链表的下一个节点中。hashmap在每个链表节点中存储键值对对象。
详情参见:https://www.cnblogs.com/java-jun-world2099/p/9258605.html
hashmap和hashtable的区别
- hashmap是线程不安全的,允许有null的键和值,效率较高,方法不是Synchronize的需要提供外同步,它有containsvalue和containskey方法。
- hashtable是线程安全的,不允许有null的键和值,效率低下,方法是同步的,它有containsvalue和containskey方法。
List,Set,Map的区别
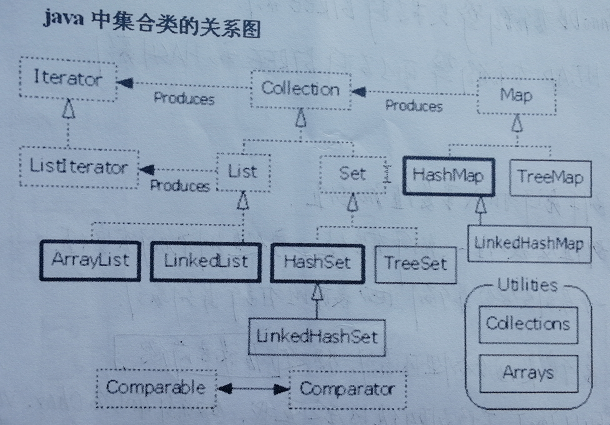
java中的集合包括三大类,分别为list,set,map,他们都处于java.util包中,list,set,map都是接口,他们都有各自的实现类。set的实现类主要hashSet和treeSet,list的实现类主要有ArrayList和linkedlist,map的主要实现类有hashMap和treeMap。如下图所示
Set中的对象不按特定的方式排序,并且没有重复的元素。但是它的有些实现类能对集合中的对象按特定的方式排序,例如treeSet实现类,它可以按照默认排序,也可以通过java.util.Comparator接口来自定义排序方式。set有两个实现类,hashSet和treeSet,他们有一定的区别,hashSet中元素不能重复并且没有顺序,treeSet中元素不能重复但是有顺序,如果需要排序使用treeSet,不需要排序使用hashSet,它的速度比treeSet快。
- List中对象按照索引位置排序,可以有重复的对象。允许按照对象在集合中的索引位置来检索对象。例如通过list.get(i)的方式来获得集合中的某一个对象。
Map中的每一个元素都包括一个key和value值,它是以键值对的形式存在,键值不允许重复,值可以重复。
Set集合中的元素是不能重复的,那么用什么方法区分重复与否?是用==还是equals方法,他们有什么区别呢?
可以参见这篇博文:https://www.cnblogs.com/qf123/p/8574582.html
equals方法是String类从他的超类object中继承过来的,用于检测两个对象是否相等,即两个对象的内容是否相等。
==用于比较引用和比较基本类型时有不同的功能:
- 比较基本数据类型时,如果两个值相同则为true
- 比较引用时,如果两个引用指向内存中的同一个对象则为true。
HashMap,LinkedHashMap和TreeMap的区别
- 共同点
他们都是map的实现类。 - 不同点
HashMap里面存入的键值对在取出的时候是随机的。
TreeMap取出来的是排序后的键值对,如果需要按自然顺序或者自定义顺序键,那么TreeMap更好。
LinkedHaspMap是HashMap的一个子类,如果需要输出的顺序和输入的顺序相同,那么可以使用LinkedHashMap实现。
java中的集合类详情解析以及集合和数组的区别的更多相关文章
- java中的集合类总结
在使用Java的时候,我们都会遇到使用集合(Collection)的时候,但是Java API提供了多种集合的实现,我在使用和面试的时候频 频遇到这样的“抉择” . :)(主要还是面试的时候) 久而久 ...
- Java中的static关键字解析
Java中的static关键字解析 static关键字是很多朋友在编写代码和阅读代码时碰到的比较难以理解的一个关键字,也是各大公司的面试官喜欢在面试时问到的知识点之一.下面就先讲述一下static关键 ...
- Java中的static关键字解析 转载
原文链接:http://www.cnblogs.com/dolphin0520/p/3799052.html Java中的static关键字解析 static关键字是很多朋友在编写代码和阅读代码时碰到 ...
- Java中的static关键字解析(转自海子)__为什么main方法必须是static的,因为程序在执行main方法的时候没有创建任何对象,因此只有通过类名来访问。
Java中的static关键字解析 static关键字是很多朋友在编写代码和阅读代码时碰到的比较难以理解的一个关键字,也是各大公司的面试官喜欢在面试时问到的知识点之一.下面就先讲述一下static关键 ...
- 【Java学习笔记之十五】Java中的static关键字解析
Java中的static关键字解析 static关键字是很多朋友在编写代码和阅读代码时碰到的比较难以理解的一个关键字,也是各大公司的面试官喜欢在面试时问到的知识点之一.下面就先讲述一下static关键 ...
- 【转】Java中的static关键字解析
一.static关键字的用途 在<Java编程思想>P86页有这样一段话: “static方法就是没有this的方法.在static方法内部不能调用非静态方法,反过来是可以的.而且可以在没 ...
- Java中泛型的详细解析,深入分析泛型的使用方式
泛型的基本概念 泛型: 参数化类型 参数: 定义方法时有形参 调用方法时传递实参 参数化类型: 将类型由原来的具体的类型参数化,类似方法中的变量参数 类型定义成参数形式, 可以称为类型形参 在使用或者 ...
- Java集合和数组的区别
参考:Java集合和数组的区别 集合和容器都是Java中的容器. 区别 数组特点:大小固定,只能存储相同数据类型的数据 集合特点:大小可动态扩展,可以存储各种类型的数据 转换 数组转换为集合: A ...
- java中把list列表转为arrayList以及arraylist数组截取的简单方法
java中把list列表转为arrayList以及arraylist数组截取的简单方法 package xiaobai; import java.util.ArrayList; import java ...
随机推荐
- JVM----堆上为对象动态分配内存
jvm中内存划分: 如上图,一共分为五块,其中: 线程共享区域为: 1.java堆 2.方法区 线程私有区域为: 3.JVM栈 4.本地方法栈 5.程序计数器 java技术体 ...
- 2018092609-2 选题 Scrum立会报告+燃尽图 04
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2019fall/homework/8682 一.小组情况组长:贺敬文组员:彭思雨 王志文 位军营 杨萍队名:胜 ...
- 第11组 Beta冲刺(2/5)
第11组 Beta冲刺(2/5) 队名 不知道叫什么团队 组长博客 https://www.cnblogs.com/xxylac/p/11997386.html 作业博客 https://edu.cn ...
- android 播放音乐媒体文件(四)
mMediaPlayer 播放网络mp31.异步准备使用 mMediaPlayer.prepareAsync(); 2.监听prepareAsync结果使用MediaPlayer.OnPrepared ...
- java多线程系列1:Sychronized关键字
1.Synchronized使用范围: 同步普通方法:锁的是当前对象 //包含synchronized修饰的同步方法的类addCountClass public class addCountClass ...
- 1. 参数的传入和添加 argparse.ArgumentParser()
# Edit configuration 传入的参数使用的是--file_dir picture, 获取使用的是argv.file_dir import argparse, sys def parse ...
- 1.1 DAL数据访问层
分布式(Distributed)数据访问层(Data Access Layer),简称DAL,是利用MySQL Proxy.Memcached.集群等技术优点而构建的一个架构系统.主要目的是解决高并发 ...
- 转 Cookie、Session
https://www.cnblogs.com/liwenzhou/p/8343243.html Cookie的由来 大家都知道HTTP协议是无状态的. 无状态的意思是每次请求都是独立的,它的执行情况 ...
- python中unicode utf-8的互换
比较简单明了,直接上例子 # -*- coding: utf-8 -*- t0 = u'测试' #u'\u6d4b\u8bd5' t1 = '测试' #'\xe6\xb5\x8b\xe8\xaf\x9 ...
- Linux_RHEL7_YUM
目录 目录 前言 RPM rpm常用指令 YUM yum常用指令RHEL7 最后 前言 yum:yellow dog updater modifier(黄狗包管理器),是RHEL默认的基于RPM包的软 ...