HBase备份还原OpenTSDB数据之Export/Import(增量+全量)
前言
本文基于伪分布式搭建 hadoop+zookeeper+hbase+opentsdb之后,文章链接:https://www.cnblogs.com/yybrhr/p/11128149.html,对于Hbase数据备份和恢复的几种方法已经有很多大神说明了很多(https://www.cnblogs.com/ballwql/p/hbase_data_transfer.html对hbase迁移数据的4种机制都做了说明),我就不做过多描述。本文主要实战Export 本地备份还原opentsdb数据,以及数据的迁移。
- opentsdb在hbase中生成4个表,其用途和特点参考网址https://www.cnblogs.com/276815076/p/5479070.html,我总结如下:
tsdb:存储数据点,该表只有一条数据,只有一列,值为0x17,即十进制23,即该metric的值。
tsdb-uid:存储name和UID(metric,tagk,tagv)的映射关系,都是成组出现的,即给定一个name和uid,会保存(name,uid)和(uid,name)两条记录。
tsdb-meta:存储时间序列索引和元数据。这是一个可选特性,默认不开启,可通过配置文件来启用该特性。
tsdb-tree:树形表,用来以树状层次关系来表示metric的结构,只有在配置文件开启该特性后,才会使用此表。
由此可见,备份还原时,直接备份还原tsdb表即可。
1、全量备份
本文测试本地备份服务器hostname:hbase3,ip为192.168.0.214。
- # 备份表:tsdb,本地存放路径/opt/soft/hbase/hbase_bak/hbase_bak_1562252298
- hbase org.apache.hadoop.hbase.mapreduce.Export -Dhbase.export.scanner.batch=2000 -D mapred.output.compress=true tsdb file:///opt/soft/hbase/hbase_bak/hbase_bak_1562252298
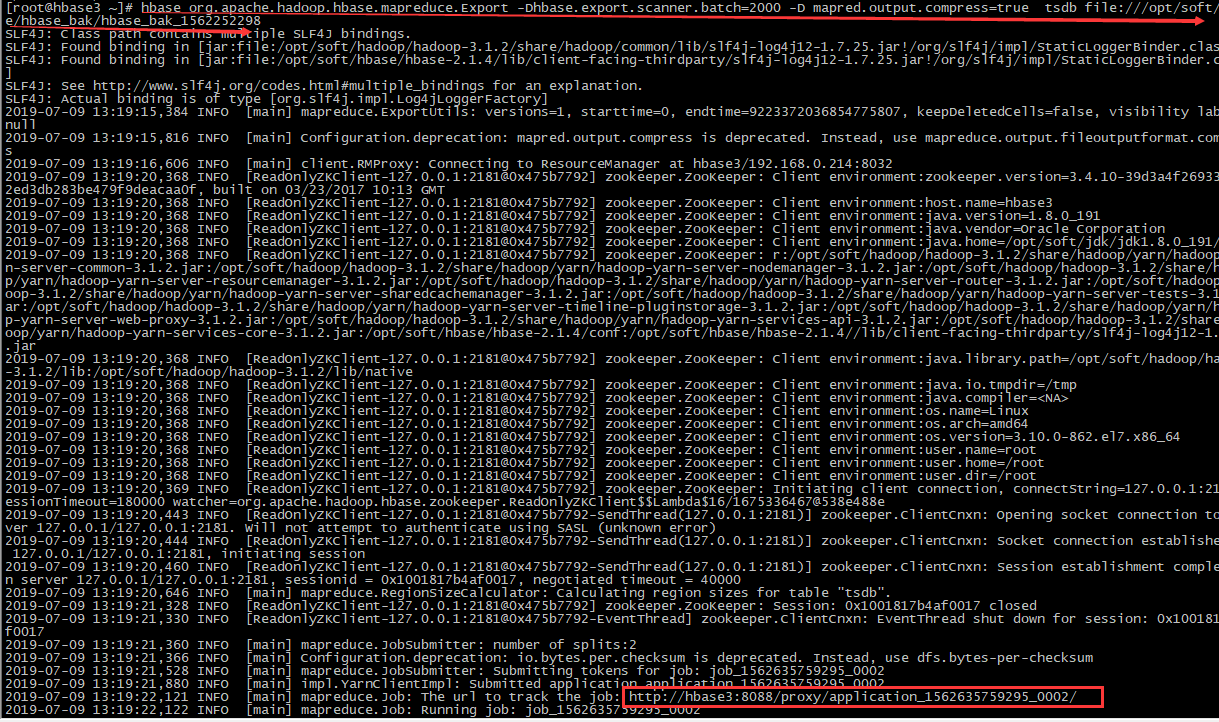
2、跟踪进度
- #根据提示:可以通过 http://hbase3:8088 跟踪进度
- http://hbase3:8088
- #问题:但是无法访问 http://hbase3:8088,但http://192.168.0.214:8088/cluster则访问
- http://192.168.0.214:8088
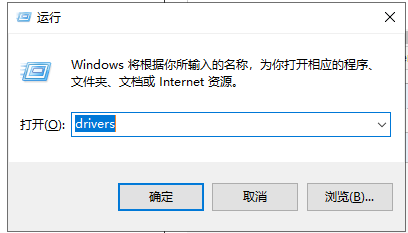
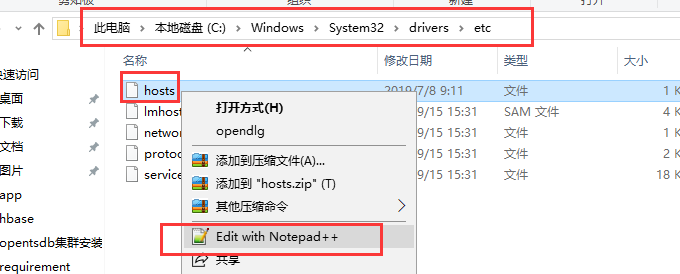
- #解决:配置hosts,映射hbase3(WIN+R——>输入:drivers——>进入子路径:/etc/hosts——>添加 192.168.0.214 hbase3)
- 192.168.0.214 hbase3
- # 问题
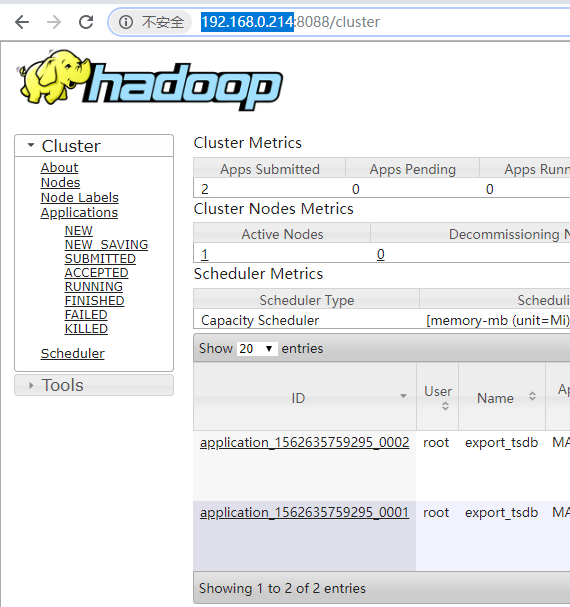

# 解決:状态与进度跟踪

# 验证
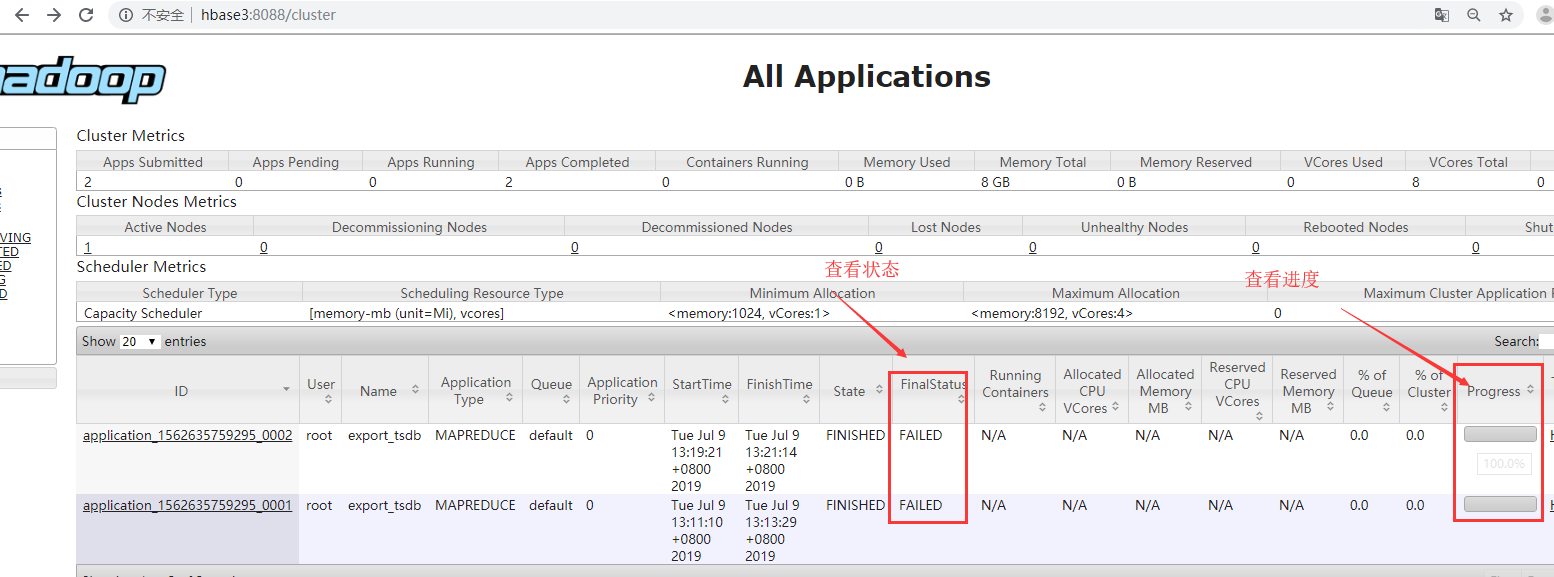
3、错误解决:
is running 17037824B beyond the 'VIRTUAL' memory limit. Current usage: 207.8 MB of 1 GB physical memory used; 2.1 GB of 2.1 GB virtual memory used. Killing container
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
【1】错误log日志
- 后台日志:提示可以在web上查看
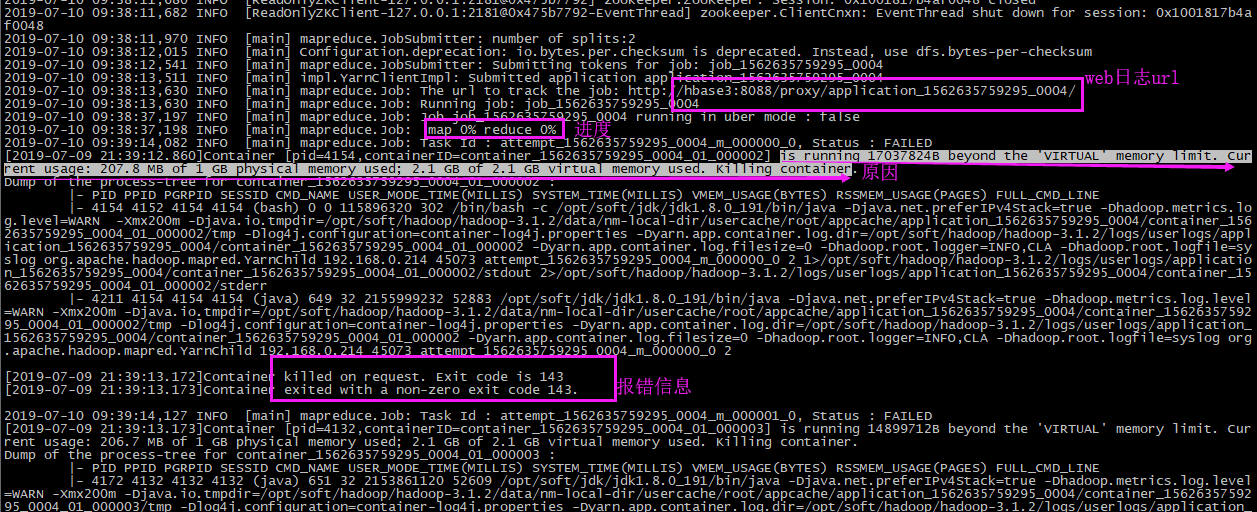
- web日志:

【2】异常分析
我们在后台日志可以看到,is running 17037824B beyond the 'VIRTUAL' memory limit. Current usage: 207.8 MB of 1 GB physical memory used; 2.1 GB of 2.1 GB virtual memory used. Killing container.这句话其实就告诉了原因:
207.8 MB: 任务所占的物理内存
1 GB : 是hadoop的mapred-site.xml配置文件中设置的mapreduce.map.memory.mb 的值。
2.1 GB : 第一个2.1GB是程序占用的虚拟内存
2.1 GB : 是hadoop的mapred-site.xml配置文件中设置的mapreduce.map.memory.mb 的值 乘以 yarn.nodemanager.vmem-pmem-ratio 的值得到的。
其中yarn.nodemanager.vmem-pmem-ratio 是 虚拟内存和物理内存比例,在yarn-site.xml中设置,默认是2.1GB,
很明显,这句话的意思是:分配给container虚拟内存只有2.1GB,但是目前container已经占用了2.1GB。所以kill掉了这个container。
上面只是map中产生的报错,当然也有可能在reduce中报错,如果是reduce中,那么就是对应mapreduce.reduce.memory.mb 和 yarn.nodemanager.vmem-pmem-ratio。
【3】解决方案
参考网址:
- # 进入目录
- cd /opt/soft/hadoop/hadoop-3.1.2/etc/hadoop/
- # 进入编辑
- vim mapred-site.xml
- # 添加以下内容:
- <!--虚拟内存和真实物理内存的比率,这参数默认值为2.1。-->
- <property>
- <name>yarn.nodemanager.vmem-pmem-ratio</name>
- <value>2</value>
- </property>
- <!--指定map和reduce task的内存大小,该值应该在RM的最大最小container之间。如果不设置,则默认用以下规则进行计算:max{MIN_Container_Size,(Total Available RAM/containers)}。一般地,reduce设置为map的2倍。-->
- <property>
- <name>mapreduce.map.memory.mb</name>
- <value>4096</value>
- </property>
【4】结果验证
- # 添加重启hadoop、hbase:注意先停habse,并且不要要kill,因为hadoop在不断的切割,用stop停止,它会记录下来,下次启动继续切割
stop-hbase.sh
stop-all.sh
start-all.sh
start-hbase.sh
- ## 验证:
- # 1、先删除本地之前的备份文件
- rm -fr /opt/soft/hbase/hbase_bak/hbase_bak1562252298
- # 2、再次备份
- hbase org.apache.hadoop.hbase.mapreduce.Export -Dhbase.export.scanner.batch=2000 -D mapred.output.compress=true tsdb file:///opt/soft/hbase/hbase_bak/hbase_bak1562252298
- # 3、结果查看:进入备份文件路径查看内容(一般成功会生成_SUCCESS和若干part-m-文件)
- cd /opt/soft/hbase/hbase_bak/hbase_bak1562252298
- ll
在web上可以查看进度和状态:
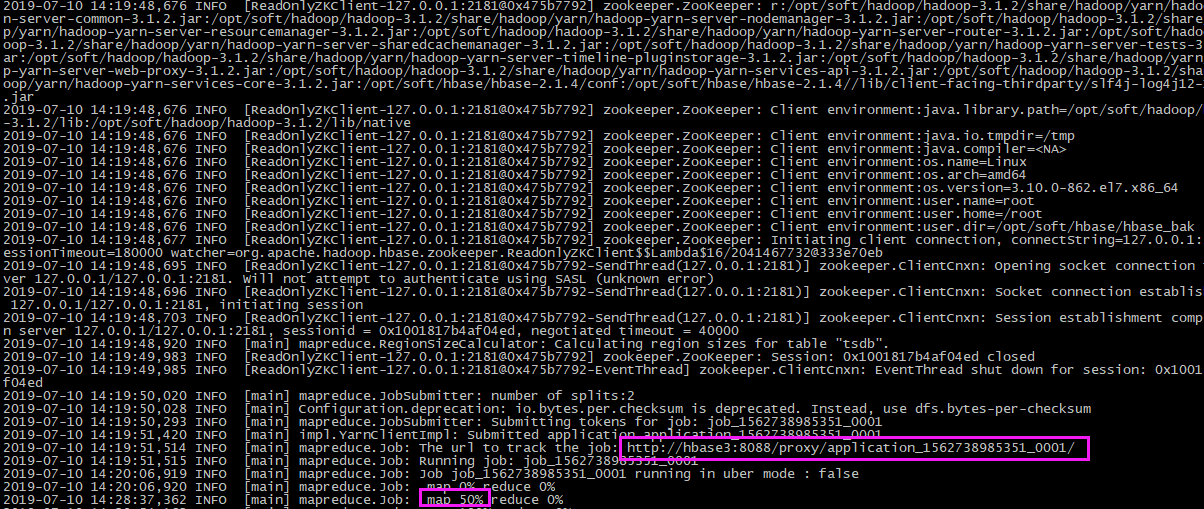

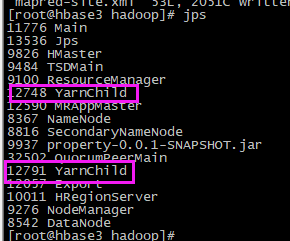
- 在运行的时候会生成两个YarnChild进程
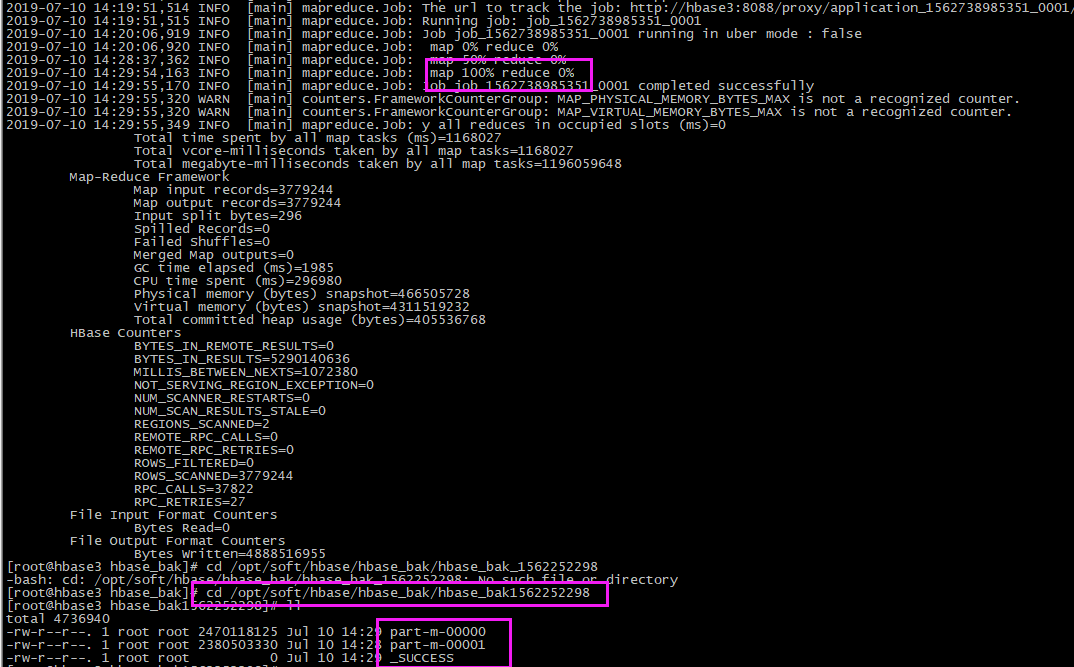
4、还原
【1】停止写入程序
【2】清空表
- # 进入到shell命令
- hbase shell
- # 清空要还原的表,只留表结构
- truncate 'tsdb'
- # 查看表
- scan 'tsdb'

【3】还原
- # 此步骤在非shell命令下执行,因此需要exit退出shell命令,我这里重开一个窗口做
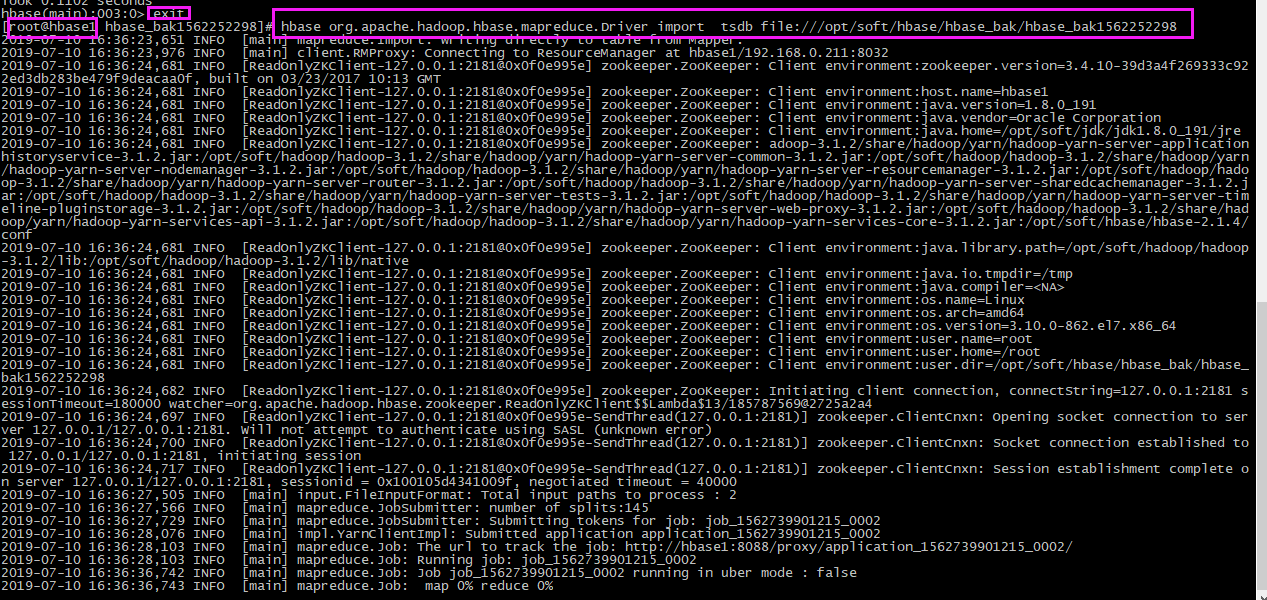
- hbase org.apache.hadoop.hbase.mapreduce.Driver import tsdb file:///opt/soft/hbase/hbase_bak/hbase_bak1562252298
查看进度

【4】验证
当进度达到100%时,检查数据。
(1)hbase shell进行验证
- # 进入shell命令
- hbase shell
- # 查看数据
- scan 'tsdb'

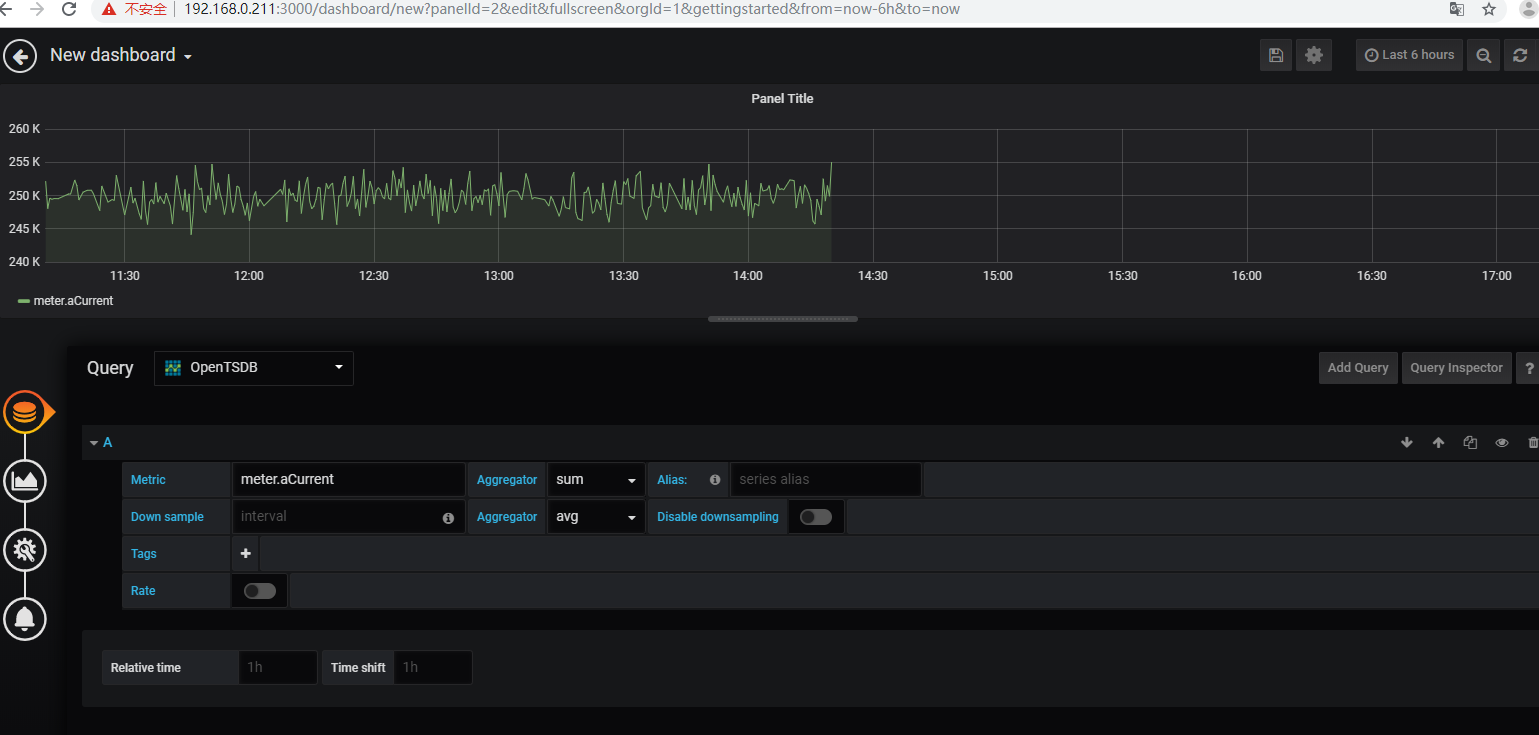
(2)grafana验证
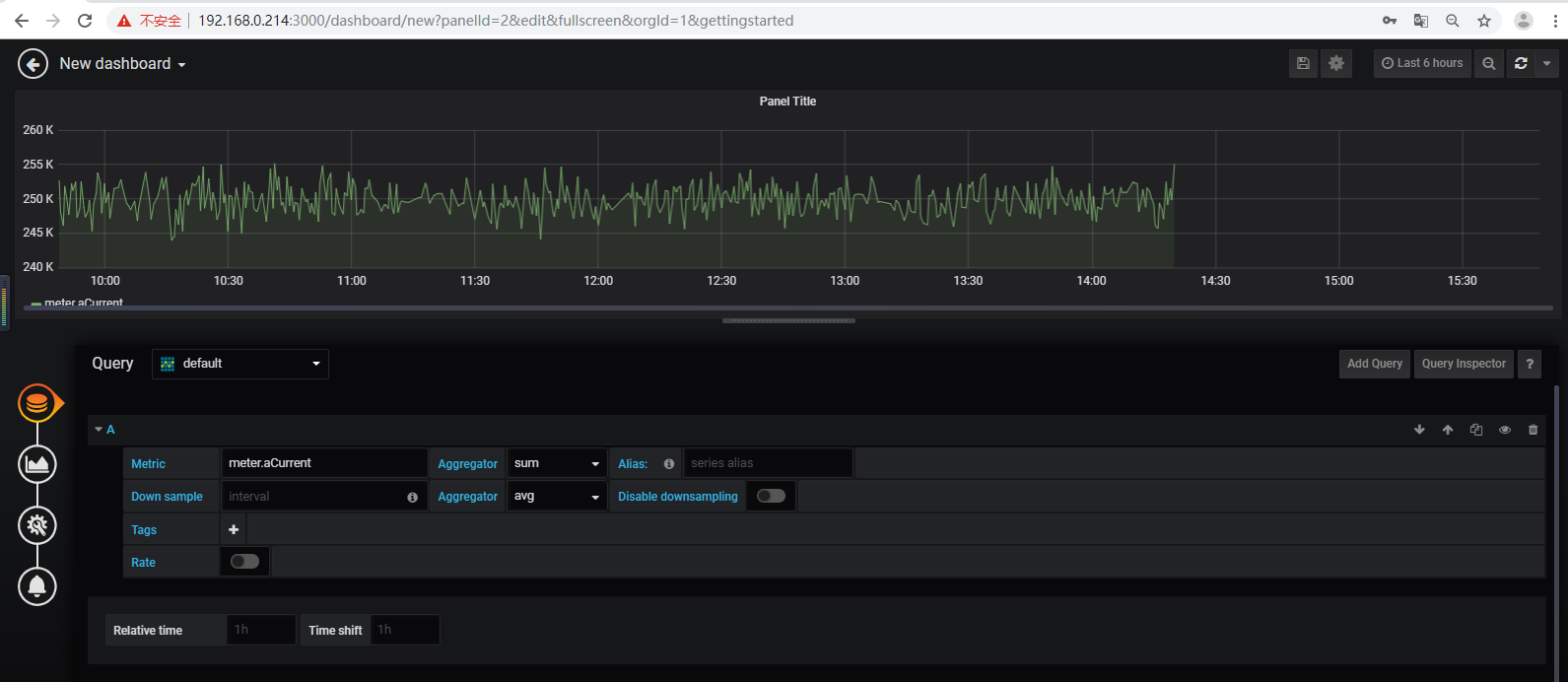
5、数据迁移:从一台服务器迁移到另一台服务器
本文从hbase3(ip:192.168.0.214)迁移到hbase1(ip:192.168.0.211),这两台服务器搭建的环境一样,并且做了互相免密登录。
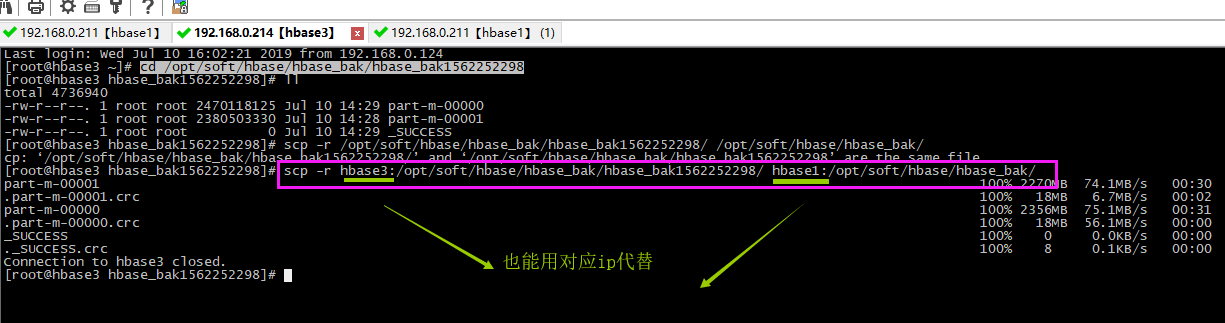
【1】将刚刚hbase3备份的数据复制给hbase1
- scp -r hbase3:/opt/soft/hbase/hbase_bak/hbase_bak1562252298/ hbase1:/opt/soft/hbase/hbase_bak/
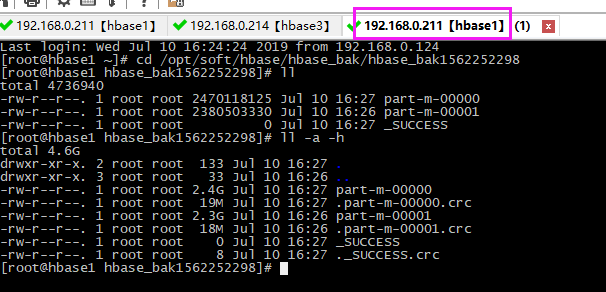
【2】清空hbase1原本tsdb的数据
hbase1原本数据
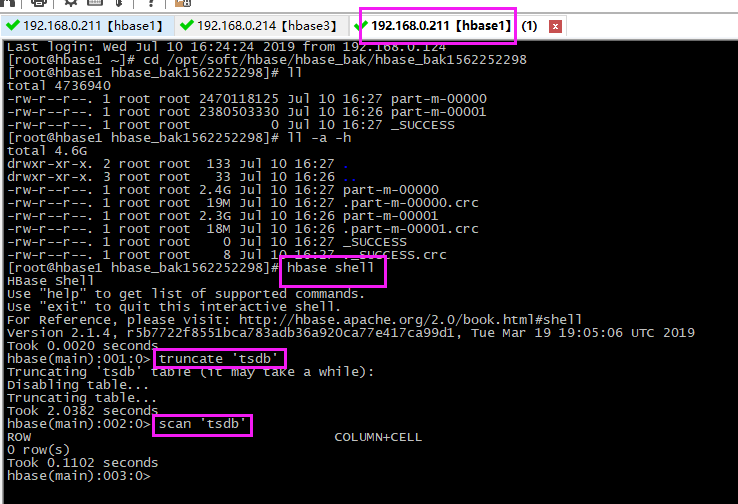
清空
- # 进入到shell命令
- hbase shell
- # 清空要还原的表,只留表结构
- truncate 'tsdb'
- # 查看表
- scan 'tsdb'
【3】还原
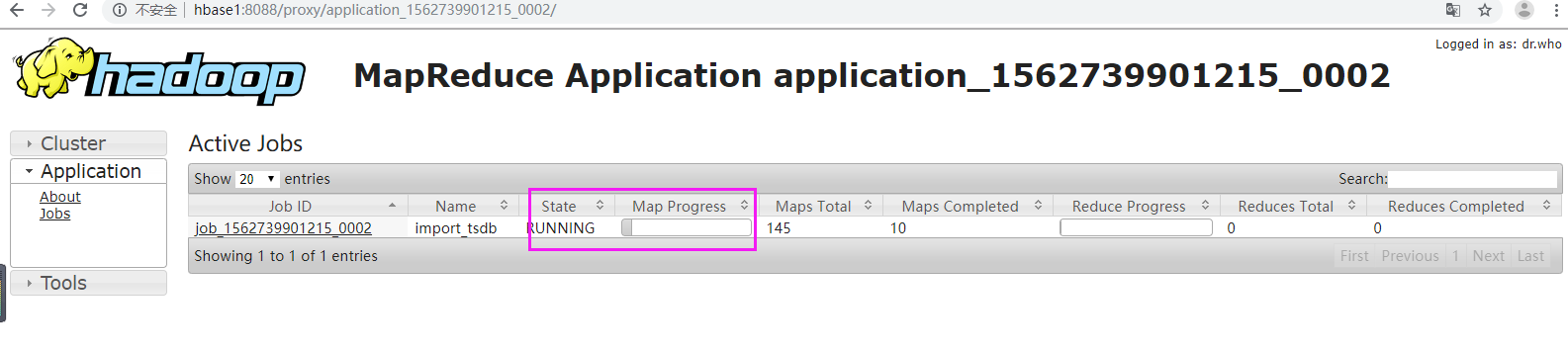
【4】验证
6、增量备份
增量备份跟全量备份操作差不多,只不过要在后面加上时间戳。需要借助时间戳转换工具http://tool.chinaz.com/Tools/unixtime.aspx。
开始时间:2019-07-10 00:00:00 对应时间戳:1562616000
结束时间:2019-07-10 14:00:00 对应时间戳:1562652000
- hbase org.apache.hadoop.hbase.mapreduce.Export -Dhbase.export.scanner.batch=2000 -D mapred.output.compress=true tsdb file:///opt/soft/hbase/hbase_bak/hbase_bak_1562601600-1562652000 1562601600 1562652000
HBase备份还原OpenTSDB数据之Export/Import(增量+全量)的更多相关文章
- HBase备份还原OpenTSDB数据之Snapshot
前言 本文基于伪分布式搭建 hadoop+zookeeper+hbase+opentsdb之后,想了解前因后果的可以看上一篇和上上篇. opentsdb在hbase中生成4个表(tsdb, tsdb- ...
- 基于物理文件的HBase备份还原
前提说明: 1.HBase数据分表,所以备份的粒度是表. 2.备份的内容为Azure的Blob存储. HBase Blob备份 备份时,需要先将表disable,以保持数据一致性. 备份的工具可以用A ...
- RDS备份到OSS增量+全量
一.前言 阿里云的RDS备份是占用使用量的,你购买200G那备份使用量是100G左右,导致备份一般也就存半个月,2个全备份. 那半个月后之前的也就删除了,如果要持续保留更久将花费不少的金钱.所以这里用 ...
- 增量+全量备份SVN服务器
#!/bin/bash # 获取当前是星期几 DAY=$(date +%w) # 获取当前的日期 DATE=$(date '+%Y-%m-%d-%H-%M') # 获取当前版本库中最新的版本 CURR ...
- orcale增量全量实时同步mysql可支持多库使用Kettle实现数据实时增量同步
1. 时间戳增量回滚同步 假定在源数据表中有一个字段会记录数据的新增或修改时间,可以通过它对数据在时间维度上进行排序.通过中间表记录每次更新的时间戳,在下一个同步周期时,通过这个时间戳同步该时间戳以后 ...
- Mysql备份系列(3)--innobackupex备份mysql大数据(全量+增量)操作记录
在日常的linux运维工作中,大数据量备份与还原,始终是个难点.关于mysql的备份和恢复,比较传统的是用mysqldump工具,今天这里推荐另一个备份工具innobackupex.innobacku ...
- MySQL5.7.18 备份、Mysqldump,mysqlpump,xtrabackup,innobackupex 全量,增量备份,数据导入导出
粗略介绍冷备,热备,温暖,及Mysqldump,mysqlpump,xtrabackup,innobackupex 全量,增量备份 --备份的目的 灾难恢复:意外情况下(如服务器宕机.磁盘损坏等)对损 ...
- Mysql备份系列(4)--lvm-snapshot备份mysql数据(全量+增量)操作记录
Mysql最常用的三种备份工具分别是mysqldump.Xtrabackup(innobackupex工具).lvm-snapshot快照.前面分别介绍了:Mysql备份系列(1)--备份方案总结性梳 ...
- Hbase实用技巧:全量+增量数据的迁移方法
摘要:本文介绍了一种Hbase迁移的方法,可以在一些特定场景下运用. 背景 在Hbase使用过程中,使用的Hbase集群经常会因为某些原因需要数据迁移.大多数情况下,可以跟用户协商用离线的方式进行迁移 ...
随机推荐
- 到底如何设置 Java 线程池的大小?
来源:ifeve.com/how-to-calculate-threadpool-size/ 在我们日常业务开发过程中,或多或少都会用到并发的功能.那么在用到并发功能的过程中,就肯定会碰到下面这个问题 ...
- 修复线上bug
1,git branch new_branch 2,git push origin new_branch 以上是线上地址操作,以下是本地仓库操作 3,git fetch 4,git checkout ...
- ASP.NET Core 2.2 : 二十六. 应用JWT进行用户认证及Token的刷新
来源:https://www.cnblogs.com/FlyLolo/p/ASPNETCore2_26.html 本文将通过实际的例子来演示如何在ASP.NET Core中应用JWT进行用户认证以及T ...
- 【JAVA】增强for循环for(int a : arr)
介绍 这种有冒号的for循环叫做foreach循环,foreach语句是java5的新特征之一,在遍历数组.集合方面,foreach为开发人员提供了极大的方便. foreach语句是for语句的特殊简 ...
- jQuery学习总结02-属性
1.attr(name|properties|key,value|fn) 说明:设置和返回被选元素的属性值 示例: 参数: name(属性名称) string properties(作为属性的'名/值 ...
- Robot Framework 源码阅读 day1 run.py
robot里面run起来的接口主要有两类 run_cli def run_cli(arguments): """Command line execution entry ...
- 2018-8-27-C#-powshell-调用
title author date CreateTime categories C# powshell 调用 lindexi 2018-8-27 16:20:4 +0800 2018-06-18 20 ...
- 将Java对象序列化成JSON和XML格式
1.先定义一个Java对象Person: public class Person { String name; int age; int number; public String getName() ...
- CF429E Points and Segments
链接 CF429E Points and Segments 给定\(n\)条线段,然后给这些线段红蓝染色,求最后直线上上任意一个点被蓝色及红色线段覆盖次数之差的绝对值不大于\(1\),构造方案,\(n ...
- 详解JVM内存模型与JVM参数详细配置
对于大多数应用来说,Java 堆(Java Heap)是Java 虚拟机所管理的内存中最大的一块.Java 堆是被所有线程共享的一块内存区域,在虚拟机启动时创建. JVM内存结构 由上图可以清楚的看到 ...