实例学习——爬取豆瓣网TOP250数据
开发环境:(Windows)eclipse+pydev
网址:https://book.douban.com/top250?start=0
from lxml import etree #解析提取数据
import requests #请求网页获取网页数据
import csv #存储数据 fp = open('D:\Pyproject\douban.csv','wt',newline='',encoding='UTF-8') #创建csv文件
writer = csv.writer(fp)
writer.writerow(('name','url','author','publisher','date','price','rate','comment')) #写入表头信息,即第一行 urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)] #构建urls headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'} for url in urls: #循环url,先抓大,后抓小(!!!重要,下面详解)
html = requests.get(url,headers = headers)
selector = etree.HTML(html.text)
infos = selector.xpath('//tr[@class="item"]')
for info in infos:
name = info.xpath('td/div/a/@title')
url = info.xpath('td/div/a/@href')
book_infos = info.xpath('td/p/text()')[0]
author = book_infos.split('/')[0]
publisher =book_infos.split('/')[-3]
date = book_infos.split('/')[-2]
price = book_infos.split('/')[-1]
rate = info.xpath('td/div/span[2]/text()')
comments = info.xpath('td/p/span/text()')
comment = comments[0] if len(comments) != 0 else ''
writer.writerow((name,url,author,publisher,date,price,rate,comment)) #写入数据
fp.close() #关闭csv文件,勿忘
成果展示:
#乱码错误,用记事本打开,另存为UTF-8文件可解决

本例主要学习csv库的使用与数据批量抓取方式(即先抓大,后抓小,寻找循环点)
csv库创建csv文件及写入数据方式:
import csv
fp = ('C://Users/LP/Desktop/text.csv','w+')
writer = csv.writer(fp)
writer.writerow('id','name')
writer.writerow('','OCT')
writer.writerow('','NOV') #写入行
fp.close()
数据批量抓取:
通过类似于BeautifulSoup中的selector()删除谓语部分不可行,思路应为“先抓大,后抓小,寻找循环点”(手写,非copy xpath)
打开chrome浏览器进行“检查”,通过“三角形符号”折叠元素,找到完整的信息标签,如下图
(selector()获取数据集中最大区域,遵循路径表达式,第一个字符串前置)
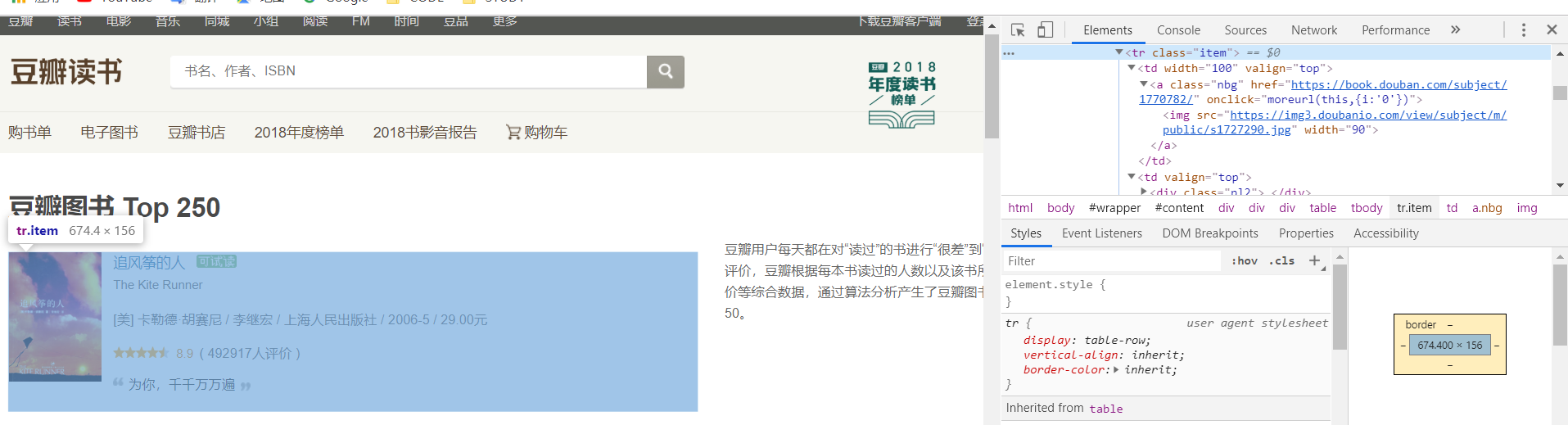
后每个单独的数据(名字,价格等)另取:
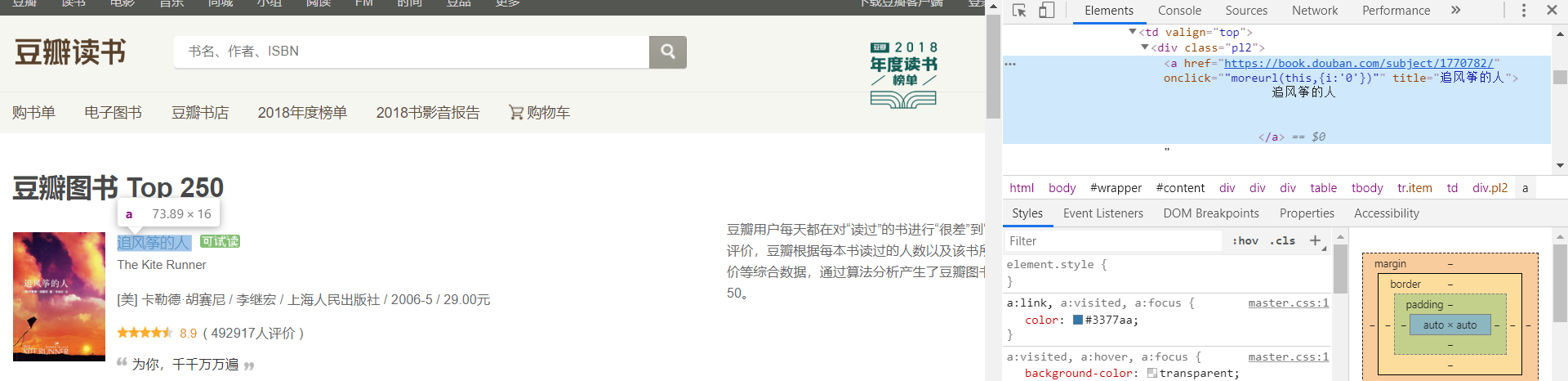
如 name,归属:<a>—><div>—><td>
所以:(当归属指向不变时,取小范围的)
name = info.xpath('td/div/a/@title')
实例学习——爬取豆瓣网TOP250数据的更多相关文章
- 实例学习——爬取豆瓣音乐TOP250数据
开发环境:(Windows)eclipse+pydev+MongoDB 豆瓣TOP网址:传送门 一.连接数据库 打开MongoDBx下载路径,新建名为data的文件夹,在此新建名为db的文件夹,d ...
- 爬取豆瓣网图书TOP250的信息
爬取豆瓣网图书TOP250的信息,需要爬取的信息包括:书名.书本的链接.作者.出版社和出版时间.书本的价格.评分和评价,并把爬取到的数据存储到本地文件中. 参考网址:https://book.doub ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
随机推荐
- AngularJS的目录结构
templates/ _login.html _feed.html app/ app.js controllers/ LoginController.js FeedController.js dire ...
- sh_01_重复执行
sh_01_重复执行 # 打印 500 遍 Hello Python(复制粘贴的方法,手动复制500次) print("Hello Python") print("Hel ...
- es6新的数据类型——generator
todo 一.Generator 函数是 ES6 提供的一种异步编程解决方案,语法行为与传统函数完全不同. 语法上,首先可以把它理解成,Generator 函数是一个状态机,封装了多个内部状态. 执行 ...
- sqli-labs(35)
0X01 构造闭合 发现不需要闭合 ?id=- union ,database(), 0X02组合拳打法
- 利用IKVM在C#中调Java程序(总结+案例)
IKVM.NET是一个针对Mono和微软.net框架的java实现,其设计目的是在.NET平台上运行java程序.本文将比较详细的介绍这个工具的原理.使用入门(如何java应用转换为.NET应用.), ...
- libusb获取usb设备的idVendor(vid),idProduct(pid),以及Serial Number
发表于2015/6/23 21:55:11 4594人阅读 最近在做关于usb设备的项目,用到了libusb,发现关于这个的函数库的介绍,讲解很少,下面仅仅是简单展示一些基本的使用方法,以备后用. ...
- OperationCenter Docker运行环境及其依赖启动脚本
1.Portainer docker rm -f portainer docker run -d -p : --name portainer --restart always portainer/po ...
- 转 HTTP请求报文格式 GET和POST
https://blog.csdn.net/h517604180/article/details/79802914 最近在做安卓客户端图片上传插件功能,供后台调用.其中涉及到了拼接HTTP请求报文,所 ...
- Git-Runoob:Git 工作流程
ylbtech-Git-Runoob:Git 工作流程 1.返回顶部 1. Git 工作流程 本章节我们将为大家介绍 Git 的工作流程. 一般工作流程如下: 克隆 Git 资源作为工作目录. 在克隆 ...
- numpy库简单使用
numpy简介 NumPy(Numerical Python)是python语言的一个扩展程序库,支持大量维度数组与矩阵运算,此外,也针对数据运算提供大量的数学函数库. NumPy是高性能科学计算和数 ...