TensorFlow学习笔记13-循环、递归神经网络
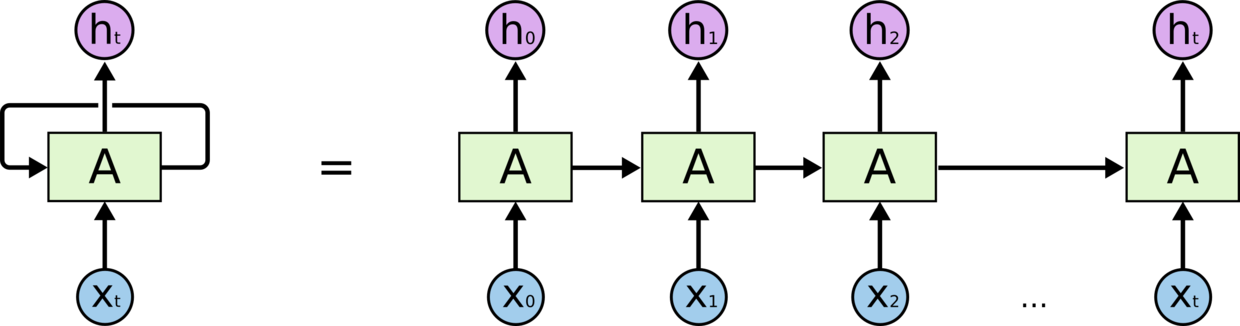
循环神经网络(RNN)
卷积网络专门处理网格化的数据,而循环网络专门处理序列化的数据。
一般的神经网络结构为:
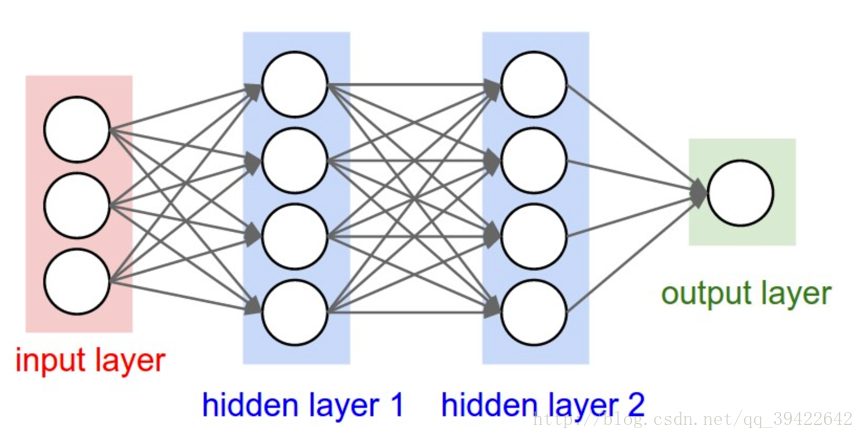
一般的神经网络结构的前提假设是:元素之间是相互独立的,输入、输出都是独立的。
现实世界中的输入并不完全独立,如股票随时间的变化,这就需要循环网络。
循环神经网络的本质
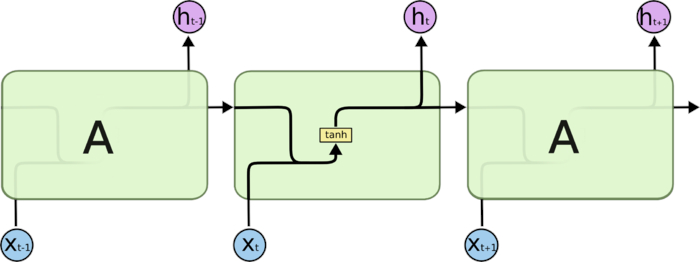
循环神经网络的本质是有记忆能力,能将前一时刻的输出量('记忆')作为下一时刻的输入量。
RNN的结构与原理
结构如下:

设某个神经元的
\]
则\(S_t = f(U*X_t + W*S_{t-1})\) 表示\(t\)时刻的记忆, 其中函数\(f\)就是神经网络的激活函数,常用\(\tanh()\)。
可见,\(t\)时刻的记忆是\(t-1\)时刻记忆与\(t\)时刻输入的加权叠加。
神经元\(t\)时刻的输出基于之前所有的记忆\(S_t\)做出,表示为
\]
将输出\(o_t\)与标签label比较得到误差,用梯度下降(Gradient Descent)和Back-Propagation
Through Time(BPTT)方法对网络进行训练。
例如,在视频中的目标识别案例中,
Xi就是一帧图像.
LSTM基本原理
早期时,RNN被设计成可以处理整个时间序列信息,但记忆最深的还是最后输入的信号,而之前的信号
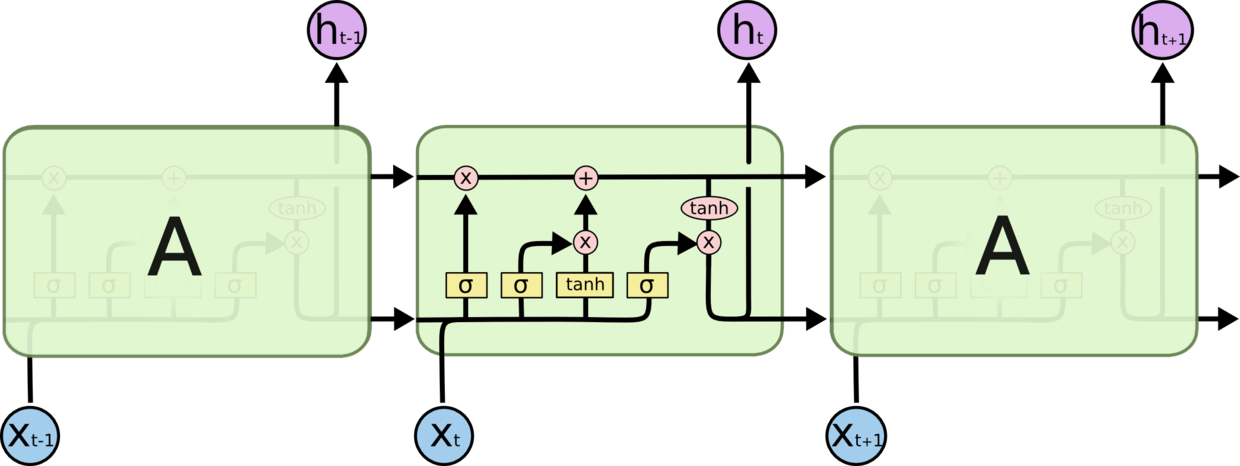
强度则越来越低,这个缺陷导致RNN在当时的作用并不明显。后来发现了Long-Short Term memory(LSTM)
,循环神经网络可以记住长期的信息。如图。它包括4层神经网络。信息流从t-1时刻流向t时刻时,LSTM
单元可对其增加或删减信息,这些修改的操作由LSTM单元中的Gates控制。在图中,由于Sigmoid函数
的输出在(0,1)之间,通过将sigmoid的输出与信息流点乘,可以控制信息流是允许信息流通过(sigmoid=1)
或不允许通过(sigmoid=0)。这里的state就是LSTM单元中上面的那条直线,它贯穿了串联在一起的
LSTM单元。
和卷积神经网络的共享参数方法一样,这里的每个神经元都共享了一组参数(U,V,W), 这样能降低计算量。
其具体原理如下图。
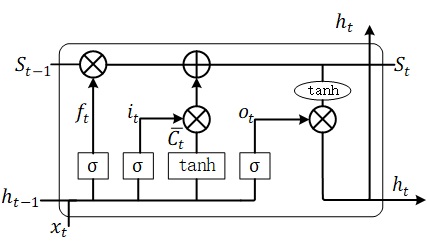
同样地,设某个神经元的
\]
- 忘记门(决定忘记多少旧记忆),当有新的输入到来,我们希望据此对旧记忆进行忘记,保存的比例为:
\]
- 输入门(决定更新什么信息,并用\(\bar{C_t}\)对其筛选)
\]
\]
然后把要更新的信息加入到
\]
- 输出门(根据更新后的记忆进行输出)
\]
\]
LSTM变体
peephole连接

coupled忘记门与输入门
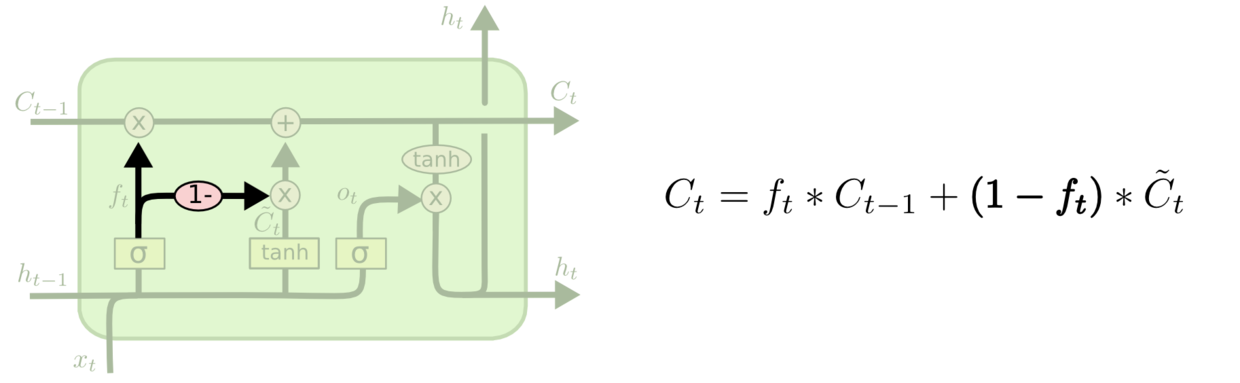
GRU(Gated Recurrent Unit)

下面是用LSTM实现的语言模型。
import reader
import numpy as np
import tensorflow as tf
# 数据参数
DATA_PATH = 'simple-examples/data/' # 数据存放路径
VOCAB_SIZE = 10000 # 单词数量
# 神经网络参数
HIDDEN_SIZE = 200 # LSTM隐藏层规模
NUM_LAYERS = 2 # LSTM结构层数
LEARNING_RATE = 1.0 # 学习速率
KEEP_PROB = 0.5 # 节点不被dropout的概率
MAX_GRAD_NORM = 5 # 用于控制梯度膨胀的参数
# 训练参数
TRAIN_BATCH_SIZE = 20 # 训练数据batch大小
TRAIN_NUM_STEP = 35 # 训练数据截断长度
# 测试参数
EVAL_BATCH_SIZE = 1 # 测试数据batch大小
EVAL_NUM_STEP = 1 # 测试数据截断
NUM_EPOCH = 2 # 使用训练数据的轮数
# 通过PTBModel描述模型,方便维护循环神经网络中的状态
class PTBModel():
def __init__(self, is_training, batch_size, num_steps):
# 记录batch和截断长度
self.batch_size = batch_size
self.num_steps = num_steps
# 定义输入层
self.input_data = tf.placeholder(tf.int32, [batch_size, num_steps])
# 定义预期输出
self.targets = tf.placeholder(tf.int32, [batch_size, num_steps])
# 定义LSTM为使用dropout的两层网络
lstm_cell = tf.contrib.rnn.BasicLSTMCell(HIDDEN_SIZE)
if is_training:
lstm_cell = tf.contrib.rnn.DropoutWrapper(
lstm_cell, output_keep_prob=KEEP_PROB)
cell = tf.contrib.rnn.MultiRNNCell([lstm_cell] * NUM_LAYERS)
# 初始化state
self.initial_state = cell.zero_state(batch_size, tf.float32)
# 将单词ID转为单词向量。每个单词都是HIDDEN_SIZE维
embedding = tf.get_variable('embedding', [VOCAB_SIZE, HIDDEN_SIZE])
# 将原本batch_size*num_steps的输入层转化为batch_size*num_steps*HIDDEN_SIZE
inputs = tf.nn.embedding_lookup(embedding, self.input_data)
# 只在训练时使用dropout
if is_training:
inputs = tf.nn.dropout(inputs, KEEP_PROB)
# 定义输出列表
outputs = []
state = self.initial_state
with tf.variable_scope('RNN'):
for time_step in range(num_steps):
if time_step > 0:
tf.get_variable_scope().reuse_variables()
cell_output, state = cell(inputs[:, time_step, :],
state) # 将当前时刻的数据和状态传入LSTM
outputs.append(cell_output) # 将当前输出加入输出列表
# 将输出列表展开成[batch,hidden_size*num_steps]
# 再reshape成[batch*num_steps,hidden_size]
output = tf.reshape(tf.concat(outputs, 1), [-1, HIDDEN_SIZE])
# 将输出传入全连接层,每个时刻的输出都是长度为VOCAB_SIZE的数组
weight = tf.get_variable('weight', [HIDDEN_SIZE, VOCAB_SIZE])
bias = tf.get_variable('bias', [VOCAB_SIZE])
logits = tf.matmul(output, weight) + bias
# 定义交叉熵损失函数,sequence_loss_by_example计算一个序列的交叉熵的和
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[logits], # 预测结果
[tf.reshape(self.targets, [-1])
], # 预期结果。将[batch_size,num_steps]压缩成一维
[tf.ones([batch_size * num_steps], dtype=tf.float32)
] # 损失的权重。这里所有的权重都为1,表示不同batch和不同时刻的重要程度都一样
)
# 计算得到每个batch的平均损失
self.cost = tf.reduce_sum(loss) / batch_size
self.final_state = state
# 只在训练时反向传播
if not is_training:
return
trainable_variables = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(
tf.gradients(self.cost, trainable_variables),
MAX_GRAD_NORM) # 控制梯度大小。避免梯度膨胀
# 定义优化方法
optimizer = tf.train.GradientDescentOptimizer(LEARNING_RATE)
# 定义训练步骤
self.train_op = optimizer.apply_gradients(
zip(grads, trainable_variables))
# 使用给定的model在data上运行train_op并返回在全部数据上的perplexity
def run_epoch(session, model, data_queue, train_op, output_log, epoch_size):
# 计算perplexity的辅助变量
total_costs = 0.0
iters = 0
state = session.run(model.initial_state)
# 使用当前数据训练或测试模型
for step in range(epoch_size):
# 生成输入和答案
feed_dict = {}
x, y = session.run(data_queue)
feed_dict[model.input_data] = x
feed_dict[model.targets] = y
# 将状态转为字典
for i, (c, h) in enumerate(model.initial_state):
feed_dict[c] = state[i].c
feed_dict[h] = state[i].h
# 获取损失值和下一个状态
cost, state, _ = session.run(
[model.cost, model.final_state, train_op], feed_dict=feed_dict
) # 在当前batch上运行train_op并计算损失值。交叉熵损失函数计算的是下一个单词为给定单词的概率
total_costs += cost
iters += model.num_steps
# 训练时输出日志
if output_log and step % 100 == 0:
print('After %d steps,perplexity is %.3f' %
(step, np.exp(total_costs / iters)))
return np.exp(total_costs / iters)
def main(_):
# 原始数据
train_data, valid_data, test_data, _ = reader.ptb_raw_data(DATA_PATH)
# 计算一个epoch需要训练的次数
train_data_len = len(train_data) # 数据集的大小
train_batch_len = train_data_len // TRAIN_BATCH_SIZE # batch的个数
train_epoch_size = (train_batch_len - 1) // TRAIN_NUM_STEP # 该epoch的训练次数
valid_data_len = len(valid_data)
valid_batch_len = valid_data_len // EVAL_BATCH_SIZE
valid_epoch_size = (valid_batch_len - 1) // EVAL_NUM_STEP
test_data_len = len(test_data)
test_batch_len = test_data_len // EVAL_BATCH_SIZE
test_epoch_size = (test_batch_len - 1) // EVAL_NUM_STEP
# 生成数据队列,必须放在开启多线程之前
train_queue = reader.ptb_producer(train_data, train_model.batch_size,
train_model.num_steps)
valid_queue = reader.ptb_producer(valid_data, eval_model.batch_size,
eval_model.num_steps)
test_queue = reader.ptb_producer(test_data, eval_model.batch_size,
eval_model.num_steps)
# 定义初始化函数
initializer = tf.random_uniform_initializer(-0.05, 0.05)
# 定义训练用的模型
with tf.variable_scope(
'language_model', reuse=None, initializer=initializer):
train_model = PTBModel(True, TRAIN_BATCH_SIZE, TRAIN_NUM_STEP)
# 定义评估用的模型
with tf.variable_scope(
'language_model', reuse=True, initializer=initializer):
eval_model = PTBModel(False, EVAL_BATCH_SIZE, EVAL_NUM_STEP)
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 开启多线程从而支持ptb_producer()使用tf.train.range_input_producer()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 使用训练数据训练模型
for i in range(NUM_EPOCH):
print('In iteration: %d' % (i + 1))
run_epoch(sess, train_model, train_queue, train_model.train_op,
True, train_epoch_size) # 训练模型
valid_perplexity = run_epoch(sess, eval_model, valid_queue,
tf.no_op(), False,
valid_epoch_size) # 使用验证数据评估模型
print('Epoch: %d Validation Perplexity: %.3f' % (i + 1,
valid_perplexity))
# 使用测试数据测试模型
test_perplexity = run_epoch(sess, eval_model, test_queue,
tf.no_op(), False, test_epoch_size)
print('Test Perplexity: %.3f' % test_perplexity)
# 停止所有线程
coord.request_stop()
coord.join(threads)
if __name__ == '__main__':
tf.app.run()
在Github上有更新的代码。
双向循环网络Bi-RNN的结构与原理
#coding:utf-8
#代码主要是使用Bidirectional LSTM Classifier对MNIST数据集上进行测试
#导入常用的数据库,并下载对应的数据集
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot = True)
#设置对应的训练参数
learning_rate = 0.01
max_samples = 400000
batch_size = 128
display_step = 10
n_input = 28
n_steps = 28
n_hidden = 256
n_classes = 10
#创建输入x和学习目标y的placeholder,这里我们的样本被理解为一个时间序列,第一个维度是时间点n_step,第二个维度是每个时间点的数据n_inpt。同时,在最后创建Softmax层的权重和偏差
x = tf.placeholder("float", [None, n_steps, n_input])
y = tf.placeholder("float", [None, n_classes])
weights = tf.Variable(tf.random_normal([2 * n_hidden, n_classes]))
biases = tf.Variable(tf.random_normal([n_classes]))
#定义Bidirectional LSTM网络的生成函数
def BiRNN(x, weights, biases):
x = tf.transpose(x, [1, 0, 2])
x = tf.reshape(x, [-1, n_input])
x = tf.split(x, n_steps)
lstm_fw_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden, forget_bias = 1.0)
lstm_bw_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden, forget_bias = 1.0)
outputs, _, _ = tf.contrib.rnn.static_bidirectional_rnn(lstm_fw_cell,
lstm_bw_cell, x,
dtype = tf.float32)
return tf.matmul(outputs[-1], weights) + biases
#使用tf.nn.softmax_cross_entropy_with_logits进行softmax处理并计算损失
pred = BiRNN(x, weights, biases)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = pred, labels = y))
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
init = tf.global_variables_initializer()
#开始执行训练和测试操作
with tf.Session() as sess:
sess.run(init)
step = 1
while step * batch_size < max_samples:
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, n_steps, n_input))
sess.run(optimizer, feed_dict = {x: batch_x, y: batch_y})
if step % display_step == 0:
acc = sess.run(accuracy, feed_dict = {x: batch_x, y: batch_y})
loss = sess.run(cost, feed_dict = {x: batch_x, y: batch_y})
print("Iter" + str(step * batch_size) + ", Minibatch Loss = " + \
"{:.6f}".format(loss) + ", Training Accuracy = " + \
"{:.5f}".format(acc))
step += 1
print("Optimization Finished!")
test_len = 10000
test_data = mnist.test.assets[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:", sess.run(accuracy, feed_dict = {x: test_data, y: test_label}))
案例
RNN与CNN的结合
在图像处理中,目前做的最好的是CNN,而自然语言处理中,表现比较好的是RNN,因此,我们能否把他们结合起来,一起用呢?那就是看图说话了,这个原理也比较简单,举个小栗子:假设我们有CNN的模型训练了一个网络结构,比如是这个
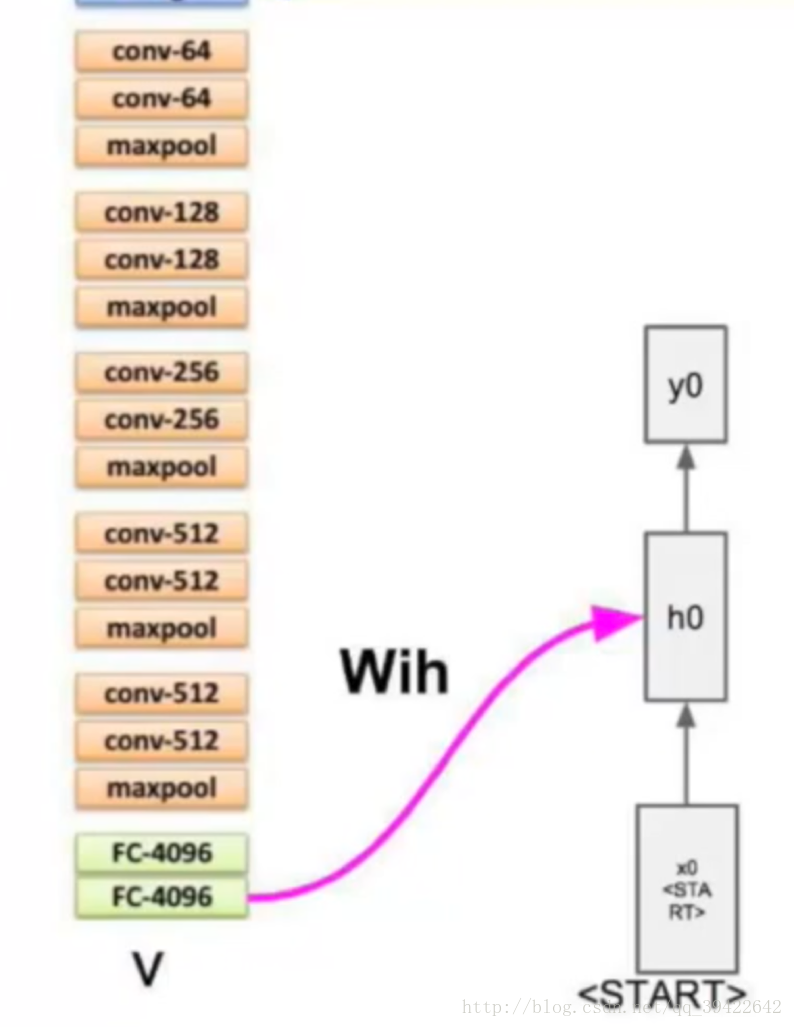
最后我们不是要分类嘛,那在分类前,是不是已经拿到了图像的特征呀,那我们能不能把图像的特征拿出来,放到RNN的输入里,让他学习呢?
之前的RNN是这样的:
\]
我们把图像的特征加在里面,可以得到:
\]
其中的X就是图像的特征。如果用的是上面的CNN网络,X应该是一个4096X1的向量。
注:这个公式只在第一步做,后面每次更新就没有V了,因为给RNN数据只在第一次迭代的时候给。
参考(如不允许转载请及时联系我邮箱charleechan@163.com)

TensorFlow学习笔记13-循环、递归神经网络的更多相关文章
- tensorflow学习笔记——图像识别与卷积神经网络
无论是之前学习的MNIST数据集还是Cifar数据集,相比真实环境下的图像识别问题,有两个最大的问题,一是现实生活中的图片分辨率要远高于32*32,而且图像的分辨率也不会是固定的.二是现实生活中的物体 ...
- Tensorflow学习笔记3:卷积神经网络实现手写字符识别
# -*- coding:utf-8 -*- import tensorflow as tf from tensorflow.examples.tutorials.mnist import input ...
- TensorFlow学习笔记——LeNet-5(训练自己的数据集)
在之前的TensorFlow学习笔记——图像识别与卷积神经网络(链接:请点击我)中了解了一下经典的卷积神经网络模型LeNet模型.那其实之前学习了别人的代码实现了LeNet网络对MNIST数据集的训练 ...
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(2)
tensorflow学习笔记——使用TensorFlow操作MNIST数据(1) 一:神经网络知识点整理 1.1,多层:使用多层权重,例如多层全连接方式 以下定义了三个隐藏层的全连接方式的神经网络样例 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(1)
续集请点击我:tensorflow学习笔记——使用TensorFlow操作MNIST数据(2) 本节开始学习使用tensorflow教程,当然从最简单的MNIST开始.这怎么说呢,就好比编程入门有He ...
- Tensorflow学习笔记No.5
tf.data卷积神经网络综合应用实例 使用tf.data建立自己的数据集,并使用CNN卷积神经网络实现对卫星图像的二分类问题. 数据下载链接:https://pan.baidu.com/s/141z ...
- Tensorflow学习笔记No.4.2
使用CNN卷积神经网络(2) 使用Tensorflow搭建简单的CNN卷积神经网络对fashion_mnist数据集进行分类 不了解是那么是CNN卷积神经网络的小伙伴可以参考上一篇博客(Tensorf ...
- Tensorflow学习笔记No.7
tf.data与自定义训练综合实例 使用tf.data自定义猫狗数据集,并使用自定义训练实现猫狗数据集的分类. 1.使用tf.data创建自定义数据集 我们使用kaggle上的猫狗数据以及tf.dat ...
- Tensorflow学习笔记No.8
使用VGG16网络进行迁移学习 使用在ImageNet数据上预训练的VGG16网络模型对猫狗数据集进行分类识别. 1.预训练网络 预训练网络是一个保存好的,已经在大型数据集上训练好的卷积神经网络. 如 ...
随机推荐
- 自动化运维工具-Ansible基础及Ansible Ad-Hoc
第58章 Ansible 目录 第58章 Ansible 一.Ansible基础概述 1.1)什么是Ansible 1.2)Ansible可以完成哪些功能呢?1.3)Ansible特点 1.4)Ans ...
- visual studio中配置opencv
第1步附加包含目录:H:\software\programming\opencv\opencv\build\include 第2步附加库目录:H:\software\programming\openc ...
- pipeline语法学习日记
1.pipeline 整合job的通用代码,比较基本 2.pipeline参数化构建
- C#基础知识之Partial
C# 2.0 可以将类.结构或接口的定义拆分到两个或多个源文件中,在类声明前添加partial关键字即可. 例如:下面的PartialTest类 class PartialTest { string ...
- 四、ARM 异常处理
4.1 模式与异常 当正常程序流程被暂时停止发生异常,例如响应一个来自外设的中断.在处理异常前,必须保护当前的处理器状态,以便在完成处理程序后能恢复到原来的程序 . 异常的类型: Reset unde ...
- 【串线篇】spring boot自定义starter
starter: 一.这个场景需要使用到的依赖是什么? 二.如何编写自动配置 启动器只用来做依赖导入:(启动器模块是一个空 JAR 文件,仅提供辅助性依赖管理,这些依赖可能用于自动装配或者其他类库) ...
- Pool数据池
sql相关请点我!!! 1.普通的sql语句查询完成之后,就要断开,下次查的时候又要重新开启,这样的话,效率会很低,所以利用pool 数据池来解决这种问题,pool数据池查询完之后,就不用去重新链接数 ...
- 【python】对于程序员来说,2018刑侦科推理试卷是问题么?
最近网上很火的2018刑侦科推理试卷,题目确实很考验人逻辑思维能力. 可是对于程序员来说,这根本不是问题.写个程序用穷举法计算一遍即可,太简单. import itertools class Solu ...
- Python常用框架
序言 所谓专家,就是在一个很小的领域里把所有错误都犯过了的人--尼尔斯·玻尔 Django Flask Tornado 适合后端微服务 资料 flask
- Dijkstra算法求最短路模板
Dijkstra算法适合求不包含负权路的最短路径,通过点增广.在稠密图中使用优化过的版本速度非常可观.本篇不介绍算法原理.只给出模板,这里给出三种模板,其中最实用的是加上了堆优化的版本 算法原理 or ...