neo4j简单学习
背景
最近在一些论坛或者新闻里看到了neo4j,一种擅长处理图形的数据库。 据说非常适合做一些join关系型的查询,所以抽空也看了下相关文档,给自己做个技术储备。
过程
深入学习之前,先在网上找了一下别人的一个学习文档总结,踩在别人的肩膀上总是最快,最有效的学习。
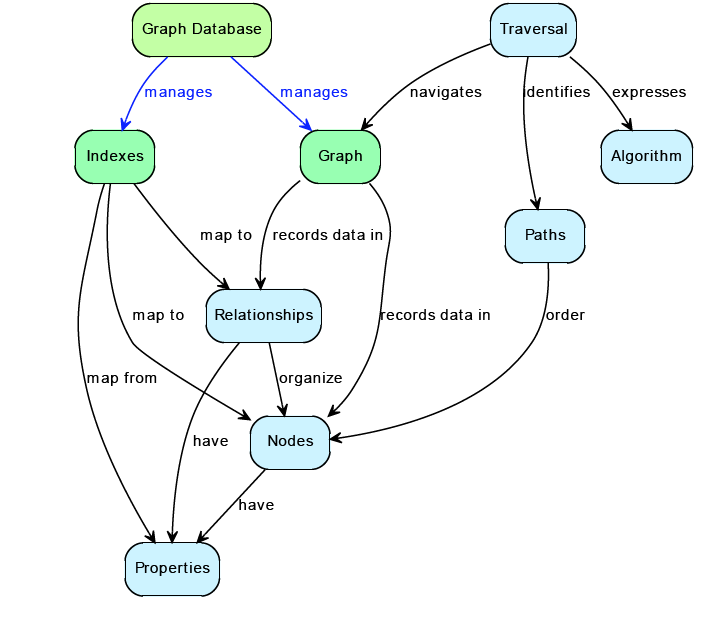
针对图中的一些基本概念:
- node : 节点
- relationships : 关系,也就是图中的边,注意是有向边
- properties : 属性,针对node/relationship都可以设置property
- Traversal : 图遍历工具
- Indexes : 索引
node(节点)
- 每个节点可以和多个节点之间建立多个关系(relationship)
- 单个节点可以设置多个(Key,Value)的properties属性的键值对
relationships(关系)
- 每个关系都会包含一个startNode和endNode
- 每个关系可以设置多个(Key,Value)的properties属性的键值对
- 可以为关系定义对应的关系类型(RelationshipType)
* DynamicRelationshipType 动态关系类型
* XXXRelationshipType 静态关系类型(实现了RelationshipType接口)
Traversal(遍历)
traverser : http://wiki.neo4j.org/content/Traversal
一个例子:
- Traverser trav = swedenNode.traverse(Order.DEPTH_FIRST, StopEvaluator.END_OF_GRAPH,
- new ReturnableEvaluator()
- {
- public boolean isReturnableNode( TraversalPosition pos )
- {
- return !pos.isStartNode() && pos.lastRelationshipTraversed().isType( CUSTOMER_TO_ORDER );
- }
- },
- LIVES_IN, Direction.INCOMING,
- CUSTOMER_TO_ORDER, Direction.OUTGOING );
- // iterate over traverser...<span style="white-space: normal;">
- </span>
Traverser trav = swedenNode.traverse(Order.DEPTH_FIRST, StopEvaluator.END_OF_GRAPH,
new ReturnableEvaluator()
{
public boolean isReturnableNode( TraversalPosition pos )
{
return !pos.isStartNode() && pos.lastRelationshipTraversed().isType( CUSTOMER_TO_ORDER );
}
},
LIVES_IN, Direction.INCOMING,
CUSTOMER_TO_ORDER, Direction.OUTGOING );
// iterate over traverser...
Order : 对应的图的遍历算法
- DEPTH_FIRST : 深度优先搜索,就是找到第一个节点,递归的一直往下找,直到找不到合适的节点后,才进行回溯
- BREADTH_FIRST : 广度优先搜索
- OUTGOING : 出边
- INCOMING : 入边
- BOTH : 顾明思议
- DEPTH_ONE : 深度超过1后停止
- END_OF_GRAPH : 无合适结果和停止
- ALL_BUT_START_NODE : 排除初始节点
- ALL : 返回所有节点
- 上一个节点信息
- 上一个进入的Relationship信息
- 搜索深度
- 目前为止满足条件的节点数
Indexs(索引)
neo4j中针对每个node/relationship/property都是进行独立存储,都是按照自然的顺序。为了支持一些场景,比如针对关系型数据库的根据主键name查询对应的person node,普通的Traversal很难满足这样的需求,而且人家也不是用来解决这个事的。所以neo4j就引出了一个index的概念。
早期的版本的index是采用了IndexService(http://wiki.neo4j.org/content/Indexing_with_IndexService)
一个例子:
- GraphDatabaseService graphDb = new EmbeddedGraphDatabase( "path/to/neo4j-db" );
- IndexService index = new LuceneIndexService( graphDb );
- Node andy = graphDb.createNode();
- Node larry = graphDb.createNode();
- andy.setProperty( "name", "Andy Wachowski" );
- andy.setProperty( "title", "Director" );
- larry.setProperty( "name", "Larry Wachowski" );
- larry.setProperty( "title", "Director" );
- index.index( andy, "name", andy.getProperty( "name" ) );
- index.index( andy, "title", andy.getProperty( "title" ) );
- index.index( larry, "name", larry.getProperty( "name" ) );
- index.index( larry, "title", larry.getProperty( "title" ) );
GraphDatabaseService graphDb = new EmbeddedGraphDatabase( "path/to/neo4j-db" );
IndexService index = new LuceneIndexService( graphDb ); Node andy = graphDb.createNode();
Node larry = graphDb.createNode(); andy.setProperty( "name", "Andy Wachowski" );
andy.setProperty( "title", "Director" );
larry.setProperty( "name", "Larry Wachowski" );
larry.setProperty( "title", "Director" );
index.index( andy, "name", andy.getProperty( "name" ) );
index.index( andy, "title", andy.getProperty( "title" ) );
index.index( larry, "name", larry.getProperty( "name" ) );
index.index( larry, "title", larry.getProperty( "title" ) );
IndexService是做为外部的component进行扩展定义。
现在官方文档中是建议使用Integrated Index Framework
- 官方文档: http://docs.neo4j.org/chunked/stable/indexing.html
- 迁移方案: http://wiki.neo4j.org/content/Transitioning_To_Index_Framework
- IndexManager index = graphDb.index();
- Index<Node> actors = index.forNodes( "actors" );
- Index<Node> movies = index.forNodes( "movies" );
- RelationshipIndex roles = index.forRelationships( "roles" );
IndexManager index = graphDb.index();
Index<Node> actors = index.forNodes( "actors" );
Index<Node> movies = index.forNodes( "movies" );
RelationshipIndex roles = index.forRelationships( "roles" );
查询语法(Cyphe Query Language)
neo4j自己基于图论的搜索算法,实现了一套查询语言解析,提供了一些常见的聚合函数(max,sum,min,count等)。
语法例子:
- Join查询:
- start n=(1) match (n)-[:BLOCKS]->(x) return x
- Where条件:
- start n=(2, 1) where (n.age < 30 and n.name = "Tobias") or not(n.name = "Tobias") return n
- 聚合函数:
- start n=(2,3,4) return avg(n.property)
- Order:
- start n=(1,2,3) return n order by n.name DESC
- 分页:
- start n=(1,2,3,4,5) return n order by n.name skip 1 limit 2
Join查询:
start n=(1) match (n)-[:BLOCKS]->(x) return x Where条件:
start n=(2, 1) where (n.age < 30 and n.name = "Tobias") or not(n.name = "Tobias") return n 聚合函数:
start n=(2,3,4) return avg(n.property) Order:
start n=(1,2,3) return n order by n.name DESC 分页:
start n=(1,2,3,4,5) return n order by n.name skip 1 limit 2
调用例子:
- db = new ImpermanentGraphDatabase();
- engine = new ExecutionEngine( db );
- CypherParser parser = new CypherParser();
- ExecutionEngine engine = new ExecutionEngine(db);
- Query query = parser.parse( "start n=(0) where 1=1 return n" );
- ExecutionResult result = engine.execute( query );
- assertThat( result.columns(), hasItem( "n" ) );
- Iterator<Node> n_column = result.columnAs( "n" );
- assertThat( asIterable( n_column ), hasItem(db.getNodeById(0)) );
- assertThat( result.toString(), containsString("Node[0]") );
db = new ImpermanentGraphDatabase();
engine = new ExecutionEngine( db );
CypherParser parser = new CypherParser();
ExecutionEngine engine = new ExecutionEngine(db);
Query query = parser.parse( "start n=(0) where 1=1 return n" );
ExecutionResult result = engine.execute( query );
assertThat( result.columns(), hasItem( "n" ) );
Iterator<Node> n_column = result.columnAs( "n" );
assertThat( asIterable( n_column ), hasItem(db.getNodeById(0)) );
assertThat( result.toString(), containsString("Node[0]") );
其他
扩展性
暂时未看到有相应的扩展性方案
可用性(HA机制)
目前neo4j支持简单的ha机制,是通过zookeeper进行管理。
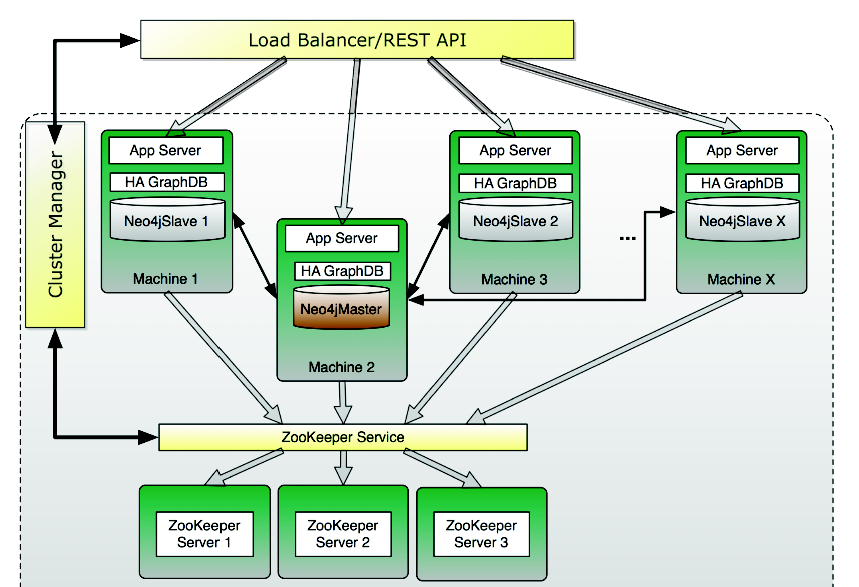
它的工作机制还是挺简单的,就是由zookeeper负责neo4j server的心跳检测。
1. 发现master挂了后,会发起一个选举(没看过源码,估摸着选举的实现也会很简单,根据对应的serverid,取最小的id做为新的master)。
2. 将新的master广播给所有的slave,此时在选举过程中,不接受对应的write请求(全都是返回异常)
3. 新机器加入集群后,会做为slave于master进行通讯,同步两者的数据内容(如果当前slave的tid比master新,会产生一个数据冲突此时需要进行手工干预)
存在的问题:
1. zookeeper心跳检测的及时性,默认为3分钟延迟(因为会有包重试)
2. master选举期间,write请求不可处理,直接返回异常(虽然master的选举时间会相对比较端,但对客户端不够友好)
可以改进的点:
1. 提供客户端的api,提供一种failover重试的机制控制。
Console页面
neo4j支持嵌入式和独立部署的两种模式,部署了一下neo4j独立部署server,效果图如下:
图形管理后台,可以方面查看节点之间的relationships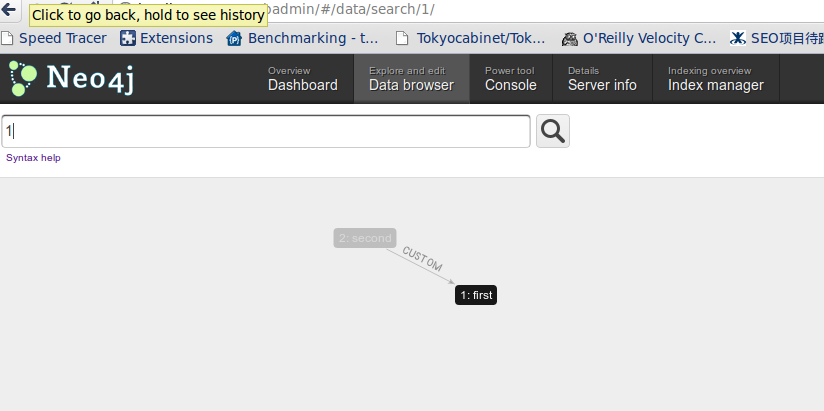
rest接口的api,提供了图形和纯数据的几种方式: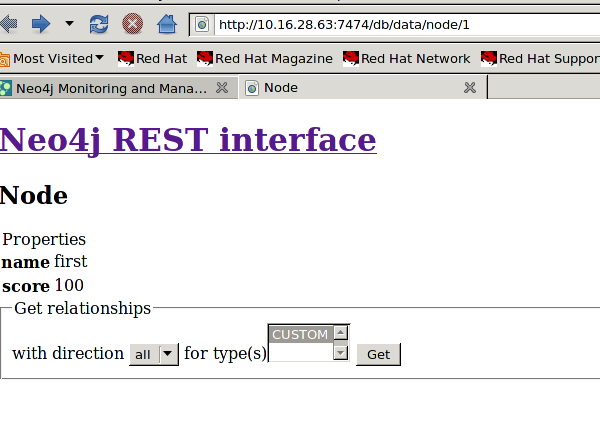
其他文档
- http://wiki.neo4j.org/content/FAQ
- http://wiki.neo4j.org/content/Getting_Started_With_Neo4j_Server
- neo4j-manual-stable.pdf
<ul style="display:none;">
<li><a href="http://dl2.iteye.com/upload/attachment/0052/0645/f2f27cba-8bad-32a5-9c9e-81902070b56f.png" target="_blank"><img src="https://img2018.cnblogs.com/blog/1112483/201909/1112483-20190909111247366-1684275372.png" class="magplus" title="点击查看原始大小图片"></a></li>
<li>大小: 42.7 KB</li>
</ul>
<ul style="display:none;">
<li><a href="http://dl2.iteye.com/upload/attachment/0052/1077/f72f857c-5214-3cd7-a5e7-3815a549727e.png" target="_blank"><img src="https://img2018.cnblogs.com/blog/1112483/201909/1112483-20190909111303154-1917188065.png" class="magplus" title="点击查看原始大小图片"></a></li>
<li>大小: 138.5 KB</li>
</ul>
<ul style="display:none;">
<li><a href="http://dl2.iteye.com/upload/attachment/0052/2869/9b18232b-acbb-353e-9b35-d58ce28e4ceb.png" target="_blank"><img src="http://dl2.iteye.com/upload/attachment/0052/2869/9b18232b-acbb-353e-9b35-d58ce28e4ceb-thumb.png" class="magplus" title="点击查看原始大小图片"></a></li>
<li>大小: 43.8 KB</li>
</ul>
<ul style="display:none;">
<li><a href="http://dl2.iteye.com/upload/attachment/0052/2871/6d548edd-7471-34f3-95ea-ffb0fed32591.png" target="_blank"><img src="http://dl2.iteye.com/upload/attachment/0052/2871/6d548edd-7471-34f3-95ea-ffb0fed32591-thumb.png" class="magplus" title="点击查看原始大小图片"></a></li>
<li>大小: 35.9 KB</li>
</ul>
<ul>
<li><a href="#" onclick="$$('div.attachments ul').invoke('show');$(this).up(1).hide();return false;">查看图片附件</a></li>
</ul>
neo4j简单学习的更多相关文章
- Log4j简单学习笔记
log4j结构图: 结构图展现出了log4j的主结构.logger:表示记录器,即数据来源:appender:输出源,即输出方式(如:控制台.文件...)layout:输出布局 Logger机滤器:常 ...
- shiro简单学习的简单总结
权限和我有很大渊源. 培训时候的最后一个项目是OA,权限那块却不知如何入手,最后以不是我写的那个模块应付面试. 最开始的是使用session装载用户登录信息,使用简单权限拦截器做到权限控制,利用资源文 ...
- CentOS 简单学习 firewalld的使用
1. centos7 开始 使用firewalld 代替了 iptables 命令工具为 firewall-cmd 帮助信息非常长,简单放到文末 2. 简单使用 首先开启 httpd 一般都自带安装了 ...
- Windows 下 Docker 的简单学习使用过程之一 dockertoolbox
1. Windows 下面运行 Docker 的两个主要工具1): Docker for Windows2): DockerToolbox区别:Docker For Windows 可以理解为是新一代 ...
- 在MVC中实现和网站不同服务器的批量文件下载以及NPOI下载数据到Excel的简单学习
嘿嘿,我来啦,最近忙啦几天,使用MVC把应该实现的一些功能实现了,说起来做项目,实属感觉蛮好的,即可以学习新的东西,又可以增加自己之前知道的知识的巩固,不得不说是双丰收啊,其实这周来就开始面对下载在挣 ...
- Linux——帮助命令简单学习笔记
Linux帮助命令简单学习笔记: 一: 命令名称:man 命令英文原意:manual 命令所在路径:/usr/bin/man 执行权限:所有用户 语法:man [命令或配置文件] 功能描述:获得帮助信 ...
- OI数学 简单学习笔记
基本上只是整理了一下框架,具体的学习给出了个人认为比较好的博客的链接. PART1 数论部分 最大公约数 对于正整数x,y,最大的能同时整除它们的数称为最大公约数 常用的:\(lcm(x,y)=xy\ ...
- mongodb,redis简单学习
2.mongodb安装配置简单学习 配置好数据库路径就可以mongo命令执行交互操作了:先将服务器开起来:在开个cmd执行交互操作 ...
- html css的简单学习(三)
html css的简单学习(三) 前端开发工具:Dreamweaver.Hbuilder.WebStorm.Sublime.PhpStorm...=========================== ...
随机推荐
- leetcode.排序.347前k个高频元素-Java
1. 具体题目 给定一个非空的整数数组,返回其中出现频率前 k 高的元素. 示例 1: 输入: nums = [1,1,1,2,2,3], k = 2 输出: [1,2] 示例 2: 输入: nums ...
- spark streaming 笔记
spark streaming项目 学习笔记 为什么要flume+kafka? 生成数据有高峰与低峰,如果直接高峰数据过来flume+spark/storm,实时处理容易处理不过来,扛不住压力.而选用 ...
- 调试Xamarin.Android时出现缺少"Mono.Posix 2.0.0"的错误
1.在http://originaldll.com/file/mono.posix.dll/31191.html中下载mono.posix 2.0.0 dll 2.以管理员权限运行Visual Stu ...
- HTML学习笔记(基础部分)
一.基本概念 1.HTML:超文本标记语言(HyperText Markup Language)是一种用于创建网页的标准标记语言. 2.HTML文档的后缀名:.html 或 .htm 3.标签:由尖括 ...
- 使用jquery.validate组件进行前端数据验证并实现异步提交前验证检查
学习如鹏网掌上组的项目开发,使用到了前端验证,视频里使用的ValidateForm验证框架,但是我使用的Hui的框架中使用的是jquery.validate验证框架 所以自行学习jquery.vali ...
- 【转载】linux查看端口状态相关命令
具体命令移步:https://www.cnblogs.com/cxbhakim/p/9353383.html
- 2018-10-8-如何安装-btsync
title author date CreateTime categories 如何安装 btsync lindexi 2018-10-8 9:15:6 +0800 2018-2-13 17:23:3 ...
- dotNET面试(一)
1.列举ASP.NET 页面之间传递值的几种方式. 1).使用QueryString, 如....?id=1; response. Redirect().... 2).使用Session变量 3).使 ...
- react-native学习(一)————使用react-native-tab-navigator创建底部导航
使用react-native-tab-navigator创建底部Tab导航 1.使用npm安装react-native-tab-navigator npm install react-native-t ...
- Zip函数(Python)
>>> z = zip((2,3,4),(33,44,55)) >>> z <zip object at 0x1022cdb88> >>&g ...