1、引言(Introduction)
1.1 欢迎
在生活中用到的机器学习算法:
(1)打开谷歌、必应搜索到你需要的内容,正是因为他们有良好的学习算法
(2)每次您阅读您的电子邮件垃圾邮件筛选器,可以帮你过滤大量的垃圾邮件
机器学习为什么如此受欢迎:
(1)机器学习用于人工智能领域
找到A与B之间的最短路径、web搜索、照片标记、反垃圾邮件
(2)涉及到各个行业和基础科学
数据库挖掘
电子医疗记录:把医疗记录变成医学知识
计算机生物学:生物学家们收集的大量基因数据序列、DNA序列和等等,机器运行算法让我们更好地了解人类基因组
工程方面,在工程的所有领域,我们有越来越大、越来越大的数据集,我们试图使用学习算法,来理解这些数据
1.2 机器学习是什么?
1.2.1 机器学习没有一个被广泛认可的定义
第一个机器学习的定义来自于Arthur Samuel。他定义机器学习为,在进行特定编程的情况下,给予计算机学习能力的领域。
另一个年代近一点的定义,由Tom Mitchell提出,来自卡内基梅隆大学,Tom定义的机器学习是,一个好的学习问题定义如下,他说,一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升。
1.2.2 主要的两种类型被我们称之为监督学习和无监督学习
监督学习这个想法是指,我们将教计算机如何去完成任务,而在无监督学习中,我们打算让它自己进行学习。
1.3 监督学习(Supervised Learning)
例子1:预测房价
前阵子,一个学生从波特兰俄勒冈州的研究所收集了一些房价的数据。你把这些数据画出来,看起来是这个样子:横轴表示房子的面积,单位是平方英尺,纵轴表示房价,单位是千美元。那基于这组数据,假如你有一个朋友,他有一套750平方英尺房子,现在他希望把房子卖掉,他想知道这房子能卖多少钱。

可以在这组数据中画一条直线,或者换句话说,拟合一条直线,根据这条线我们可以推测出,这套房子可能卖$$150,000$,当然这不是唯一的算法。可能还有更好的,比如我们不用直线拟合这些数据,用二次方程去拟合可能效果会更好。根据二次方程的曲线,我们可以从这个点推测出,这套房子能卖接近$$200,000$。稍后我们将讨论如何选择学习算法,如何决定用直线还是二次方程来拟合。两个方案中有一个能让你朋友的房子出售得更合理。这些都是学习算法里面很好的例子。以上就是监督学习的例子。
例2:乳腺肿瘤预测:假设说你想通过查看病历来推测乳腺癌良性与否,假如有人检测出乳腺肿瘤,恶性肿瘤有害并且十分危险,而良性的肿瘤危害就没那么大
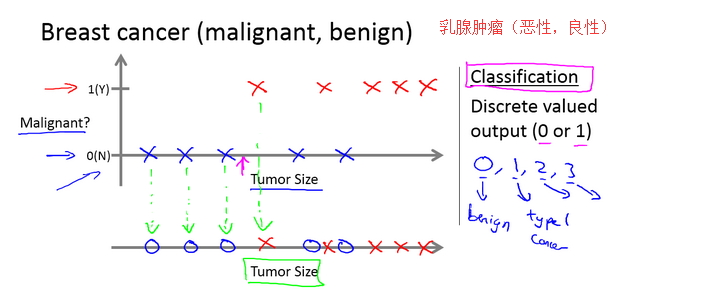
横轴表示肿瘤的大小,纵轴上,我标出1和0表示是或者不是恶性肿瘤。我们之前见过的肿瘤,如果是恶性则记为1,不是恶性,或者说良性记为0。
现在我们有一个朋友很不幸检查出乳腺肿瘤。假设说她的肿瘤大概这么大,那么机器学习的问题就在于,你能否估算出肿瘤是恶性的或是良性的概率。用术语来讲,这是一个分类问题。
分类指的是,我们试着推测出离散的输出值:0或1良性或恶性,而事实上在分类问题中,输出可能不止两个值。比如说可能有三种乳腺癌,所以你希望预测离散输出0、1、2、3。0 代表良性,1 表示第1类乳腺癌,2表示第2类癌症,3表示第3类,但这也是分类问题。
现在我用不同的符号来表示这些数据。既然我们把肿瘤的尺寸看做区分恶性或良性的特征,那么我可以这么画,我用不同的符号来表示良性和恶性肿瘤。或者说是负样本和正样本现在我们不全部画X,良性的肿瘤改成用 O 表示,恶性的继续用 X 表示。来预测肿瘤的恶性与否。
例3:多个特征的肿瘤预测
在其它一些机器学习问题中,可能会遇到不止一种特征。举个例子,我们不仅知道肿瘤的尺寸,还知道对应患者的年龄。在其他机器学习问题中,我们通常有更多的特征,我朋友研究这个问题时,通常采用这些特征,比如肿块密度,肿瘤细胞尺寸的一致性和形状的一致性等等,还有一些其他的特征。这就是我们即将学到最有趣的学习算法之一。
那种算法不仅能处理2种3种或5种特征,即使有无限多种特征都可以处理。

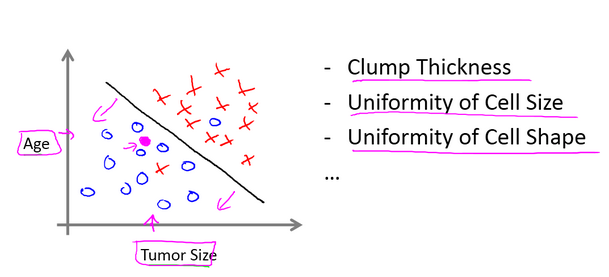
我们列举了总共5种不同的特征,坐标轴上的两种和右边的3种,但是在一些学习问题中,你希望不只用3种或5种特征。相反,你想用无限多种特征,好让你的算法可以利用大量的特征,或者说线索来做推测。那你怎么处理无限多个特征,甚至怎么存储这些特征都存在问题,你电脑的内存肯定不够用。我们以后会讲一个算法,叫支持向量机,里面有一个巧妙的数学技巧,能让计算机处理无限多个特征。
监督学习基本思想:我们数据集中每个样本都有相应的“正确答案”,我们再根据样本做出预测,就像房子和肿瘤的例子中做的那样。
回归问题,即通过回归来推出一个连续的输出。
分类问题,其目标是推出一组离散的结果。
小测验:
你有一大批同样的货物,想象一下,你有上千件一模一样的货物等待出售,这时你想预测接下来的三个月能卖多少件?
你有许多客户,这时你想写一个软件来检验每一个用户的账户。对于每一个账户,你要判断它们是否曾经被盗过?
那这两个问题,它们属于分类问题、还是回归问题?
问题一是一个回归问题,因为你知道,如果我有数千件货物,我会把它看成一个实数,一个连续的值。因此卖出的物品数,也是一个连续的值。
问题二是一个分类问题,因为我会把预测的值,用 0 来表示账户未被盗,用 1 表示账户曾经被盗过。所以我们根据账号是否被盗过,把它们定为0 或 1,然后用算法推测一个账号是 0 还是 1,因为只有少数的离散值,所以我把它归为分类问题。
以上就是监督学习的内容。
1.4 无监督学习(Unsupervised Learning)

对于监督学习,回想当时的数据集,这个数据集中每台哦数据都已经标名为阴性或阳性,即良性肿瘤或恶性肿瘤。所以对于监督学习的每条数据,我们已经清楚知道,训练集对应的正确答案,是良性或恶性。
无监督学习中没有任何的标签或者是有相同的标签或者就是没标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。别的都不知道,就是一个数据集。你能从数据中找到某种结构吗?针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。是的,无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。
聚类应用的一个例子就是在谷歌新闻中。如果你以前从来没见过它,你可以到这个URL网址news.google.com去看看。谷歌新闻每天都在,收集非常多,非常多的网络的新闻内容。它再将这些新闻分组,组成有关联的新闻。所以谷歌新闻做的就是搜索非常多的新闻事件,自动地把它们聚类到一起。所以,这些新闻事件全是同一主题的,所以显示到一起。
1.4.1无监督学习
因为我们没有提前告知算法一些信息,比如,这是第一类的人,那些是第二类的人,还有第三类,等等。我们只是说,是的,这是有一堆数据。我不知道数据里面有什么。我不知道谁是什么类型。我甚至不知道人们有哪些不同的类型,这些类型又是什么。但你能自动地找到数据中的结构吗?就是说你要自动地聚类那些个体到各个类,我没法提前知道哪些是哪些。因为我们没有给算法正确答案来回应数据集中的数据,所以这就是无监督学习。
1.4.2 无监督学习或聚类应用
它用于组织大型计算机集群。我有些朋友在大数据中心工作,那里有大型的计算机集群,他们想解决什么样的机器易于协同地工作,如果你能够让那些机器协同工作,你就能让你的数据中心工作得更高效。第二种应用就是社交网络的分析。所以已知你朋友的信息,比如你经常发email的,或是你Facebook的朋友、谷歌+圈子的朋友,我们能否自动地给出朋友的分组呢?即每组里的人们彼此都熟识,认识组里的所有人?还有市场分割。许多公司有大型的数据库,存储消费者信息。所以,你能检索这些顾客数据集,自动地发现市场分类,并自动地把顾客划分到不同的细分市场中,你才能自动并更有效地销售或不同的细分市场一起进行销售。这也是无监督学习,因为我们拥有所有的顾客数据,但我们没有提前知道是什么的细分市场,以及分别有哪些我们数据集中的顾客。我们不知道谁是在一号细分市场,谁在二号市场,等等。那我们就必须让算法从数据中发现这一切。最后,无监督学习也可用于天文数据分析,这些聚类算法给出了令人惊讶、有趣、有用的理论,解释了星系是如何诞生的。这些都是聚类的例子,聚类只是无监督学习中的一种。
q
1、引言(Introduction)的更多相关文章
- Ng第一课:引言(Introduction)
Machine Learning(机器学习)是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能. 它是人工智能的核心,是使计算机具有智能的根本 ...
- [C0] 引言(Introduction)
引言(Introduction) 欢迎(Welcome) 机器学习是目前信息技术中最激动人心的方向之一.在这门课中,你将学习到这门技术的前沿,并可以自己实现学习机器学习的算法. 你或许每天都在不知不觉 ...
- 机器学习第1课:引言(Introduction)
1.前言 Machine Learning(机器学习)是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能. 它是人工智能的核心,是使计算机具有 ...
- (2)_引言Introduction【论文写作】
- fmri分析工具:spm里的统计学 Introduction to SPM statistics
引言 Introduction 需要特别说明,spm是每一个体素为单位,计算统计量,进行t检验. 1.分别在每个体素上做方差分析; 2.对每个体素的方差分析结果,计算t检验统计量; 3.计算等同于t ...
- ModelDataExchange - Import
ModelDataExchange - Import eryar@163.com Abstract. The ModelDataExchange import utility enables the ...
- Mesh Data Structure in OpenCascade
Mesh Data Structure in OpenCascade eryar@163.com 摘要Abstract:本文对网格数据结构作简要介绍,并结合使用OpenCascade中的数据结构,将网 ...
- Evaluate Math Expression
Evaluate Math Expression eryar@163.com 摘要Abstract:本文简要介绍了数学表达式解析求值的几款开源软件,并结合程序代码说明了OpenCascade中表达式包 ...
- Qt with OpenCascade
Qt with OpenCascade 摘要Abstract:详细介绍了如何在Qt中使用OpenCascade. 关键字Key Words:Qt.OpenCascade 一.引言 Introducti ...
随机推荐
- linux配置 sudo 授权管理
为什么使用 sudo,如果普通用户使用 su - root 切换到管理员.进行非法操作,比如 passwd root 修改 root 密码.那么系统其他用户将无法访问系统.这个普通管理员说白了,已经” ...
- bzoj 3569 DZY Loves Chinese II 随机算法 树上倍增
题意:给你一个n个点m条边的图,有若干组询问,每次询问会选择图中的一些边删除,删除之后问此图是否联通?询问之间相互独立.此题强制在线. 思路:首先对于这张图随便求一颗生成树,对于每一条非树边,随机一个 ...
- HTML5 音频播放
代码实例: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF ...
- 前端经典布局:Sticky footer 布局
什么是Sticky footer布局?前端开发中大部分网站,都会把一个页面分为头部区块.内容区块.页脚区块,这也是比较.往往底部都要求能固定在屏幕的底部,而非随着文档流排布.要实现的样式可以概括如下: ...
- TreeMap和Comparable接口
备注:HashMap线程不安全,效率高,允许key.value为空 HasTable线程安全.效率低.不允许key或value为空 TreeMap在存储时会自动调用comparable方法进行排序,当 ...
- 命令——tr
文本处理工具命令——tr 一帮助说明 TR() User Commands TR() NAME tr - translate or delete characters SYNOPSIS tr [OPT ...
- input的文件上传类型判断
参考网址: http://www.helloweba.com/view-blog-224.html <p> <label>请选择一个图像文件:</label> &l ...
- 数据导入导出mysql版本不同导致的问题
5.6.16-log导出.5.5.47-log导入 `addtime` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '记录生产时间', 需要修改为: `add ...
- MySQL server has gone away 问题解决方法
问题描述: SQLyog在执行大的sql文件时候,报错,报错日志显示2006 - MySQL server has gone away 解决办法: 在php.ini配置文件的[mysqld]节点下添加 ...
- 【Pytest】python单元测试框架pytest简介
1.Pytest介绍 pytest是python的一种单元测试框架,与python自带的unittest测试框架类似,但是比unittest框架使用起来更简洁,效率更高.根据pytest的官方网站介绍 ...