Python之常用模二(时间、序列号等等)
一、time模块
表示时间的三种方式:
时间戳:数字(计算机能认识的)
时间字符串:t='2012-12-12'
结构化时间:time.struct_time(tm_year=2017, tm_mon=8, tm_mday=8, tm_hour=8, tm_min=4, tm_sec=32, tm_wday=1, tm_yday=220, tm_isdst=0)像这样的就是结构化时间
1 import time
2 # 对象:对象.方法
3 # ----------------------------------
4 # 1.时间戳(数字):给计算机的看的
5 print(time.time())#当前时间的时间戳
6 print(time.localtime())#结构化时间对象
7 s=time.localtime() #当前的结构化时间对象(utc时间)
8 print(s.tm_year)
9 s2=time.gmtime() #这个和localtime只是小时不一样
10 print(s2)
11
12
13 #-----------------------------------
14 # 2.时间的转换
15 print(time.localtime(15648461))#把时间戳转换成结构化时间
16 t='2012-12-12' #这是一个字符串时间
17 print(time.mktime(time.localtime()))#将结构化时间转换成时间戳
18 print(time.strftime("%Y-%m-%d",time.localtime()))#将结构化时间转换成字符串时间
19 print(time.strftime('%y/%m/%d %H:%M:%S'))#小写的y是取得年的后两位
20 print(time.strptime('2008-03-12',"%Y-%m-%d"))#将字符串时间转换成结构化时间
time模块的常用方法及三种时间之间的转换
1 %y 两位数的年份表示(00-99)
2 %Y 四位数的年份表示(000-9999)
3 %m 月份(01-12)
4 %d 月内中的一天(0-31)
5 %H 24小时制小时数(0-23)
6 %I 12小时制小时数(01-12)
7 %M 分钟数(00=59)
8 %S 秒(00-59)
9 %a 本地简化星期名称
10 %A 本地完整星期名称
11 %b 本地简化的月份名称
12 %B 本地完整的月份名称
13 %c 本地相应的日期表示和时间表示
14 %j 年内的一天(001-366)
15 %p 本地A.M.或P.M.的等价符
16 %U 一年中的星期数(00-53)星期天为星期的开始
17 %w 星期(0-6),星期天为星期的开始
18 %W 一年中的星期数(00-53)星期一为星期的开始
19 %x 本地相应的日期表示
20 %X 本地相应的时间表示
21 %Z 当前时区的名称
22 %% %号本身
23
24 python中时间日期格式化符号:
python中时间日期格式符号:
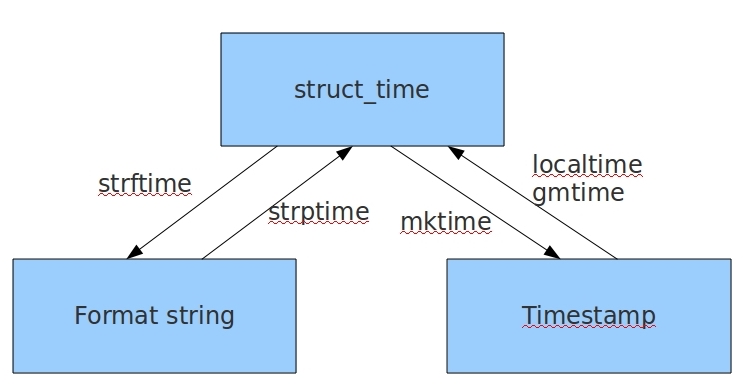
time.strftime('格式定义',‘结构化时间’) 结构化时间参数若不传,则显示当前时间
|
1
2
3
|
print(time.strptime('2008-03-12',"%Y-%m-%d"))print(time.strftime('%Y-%m-%d'))print(time.strftime("%Y-%m-%d",time.localtime(15444))) |
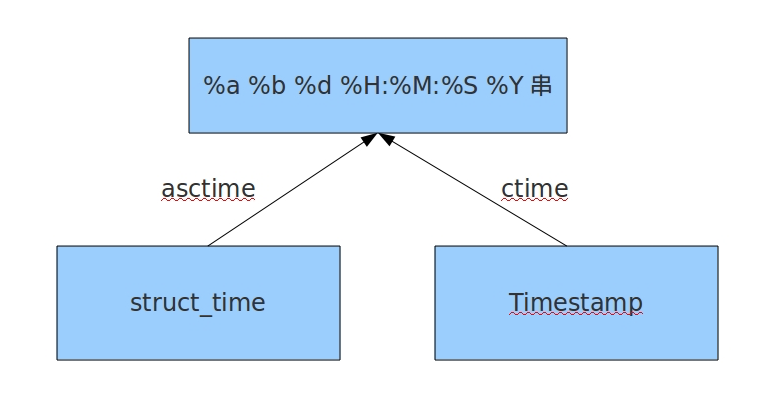
1 print(time.asctime(time.localtime(150000)))
2 print(time.asctime(time.localtime()))
3 # time.ctime(时间戳)如果不传参数,直接返回当前时间的格式化字符串
4 print(time.ctime())
5 print(time.ctime(150000))
asctime和ctime方法
二、random模块
1 import random
2 # ----------------------------
3 # 1.随机小数
4 print(random.random()) #大于0且小于1之间的随机小数
5 print(random.uniform(1,3)) #大于1且小于3的随机小数
6
7 # ----------------------------
8 # 2.随机整数
9 print(random.randint(1,5)) #大于1且小于等于5之间的整数
10 print(random.randrange(1,10,2)) #大于等于1且小于3之间的整数(且是所有的奇数)
11
12 # ----------------------------
13 # 3.随机选择一个返回
14 print(random.choice([1,'',[4,5]]))
15 # ----------------------------
16 # 4.随机选择返回多个
17 print(random.sample([1,'',[4,5]],2)) #列表元素任意两个组合
18 # ----------------------------
19
20
21 # ----------------------------
22 # 5.打乱列表顺序
23 item=[1,5,2,3,4]
24 random.shuffle(item) #打乱次序
25 print(item)
random的方法
1 # 验证码小例子(这个只是产生随机的四位数字)
2 # 方法一、
3 # l=[]
4 # for i in range(4):
5 # l.append(str(random.randint(0,9)))
6 # print(''.join(l))
7 # print(l)
8
9
10 # 方法二
11 # print(random.randint(1000,9999))
12
13
14 # 验证码升级版
15 # 要求:首次要有数字,其次要有字母,一共四位,可以重复
16 # chr(65-90)#a-z
17 # chr(97-122)#A-Z
18
19 方法一
20 # num_list = list(range(10))
21 # new_num_l=list(map(str,num_list))#['0','1'...'9']
22 # l=[] #用来存字母
23 # for i in range(65,91):
24 # zifu=chr(i)
25 # l.append(zifu) #['A'-'Z']
26 # new_num_l.extend(l) #要把上面的数字和下面的字母拼在一块
27 # print(new_num_l)
28 # ret_l=[] #存生成的随机数字或字母
29 # for i in range(4): #从new_num_l里面选数字选择四次就放到了ret_l里面)
30 # ret_l.append(random.choice(new_num_l))
31 # # print(ret_l)
32 # print(''.join(ret_l)) #拼成字符串
33
34 方法二
35 # import random
36 # def myrandom():
37 # new_num_l=list(map(str,range(10)))
38 # l=[chr(i) for i in range(65,91)]
39 # new_num_l.extend(l)
40 # ret_l=[random.choice(new_num_l) for i in range(4)]
41 # return ''.join(ret_l)
42 # print(myrandom())
43
44 方法三
45 import random
46 l=list(str(range(10)))+[chr(i) for i in range(65,91)]+[chr(j) for j in range(97,122)]
47 print(''.join(random.sample(l,4)))
验证码小例子
三、os模块
1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
3 os.curdir 返回当前目录: ('.')
4 os.pardir 获取当前目录的父目录字符串名:('..')
5 os.makedirs('dirname1/dirname2') 可生成多层递归目录
6 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
7 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
8 os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
9 os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
10 os.remove() 删除一个文件
11 os.rename("oldname","newname") 重命名文件/目录
12 os.stat('path/filename') 获取文件/目录信息
13 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
14 os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
15 os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
16 os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
17 os.system("bash command") 运行shell命令,直接显示
18 os.popen("bash command) 运行shell命令,获取执行结果
19 os.environ 获取系统环境变量
20
21
22 os.path
23 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。
24 即os.path.split(path)的第二个元素
25 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
26 os.path.isabs(path) 如果path是绝对路径,返回True
27 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
28 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
29 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
30 os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
31 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
32 os.path.getsize(path) 返回path的大小
os模块常用方法
注意:os.stat('path\filename') 获取文件\目录信息的结构说明
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
stat 结构:st_mode: inode 保护模式st_ino: inode 节点号。st_dev: inode 驻留的设备。st_nlink: inode 的链接数。st_uid: 所有者的用户ID。st_gid: 所有者的组ID。st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。st_atime: 上次访问的时间。st_mtime: 最后一次修改的时间。st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,<br>在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。ststat 结构 |
四、sys模块
sys模块是与python解释器交互的一个接口
1 import sys
2 print(sys.argv) #实现从程序外部向程序传递参数。(在命令行里面输打开路径执行)
3 name=sys.argv[1] #命令行参数List,第一个元素是程序的本身路径
4 password = sys.argv[2]
5 if name=='egon' and password == '':
6 print('继续执行程序')
7 else:
8 exit()
9
10 sys.exit()#退出程序,正常退出时exit(0)
11 print(sys.version)#获取python解释的版本信息
12 print(sys.maxsize)#最大能表示的数,与系统多少位有关
13 print(sys.path)#返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
14 print(sys.platform)#返回操作系统平台名称
sys模块
五、序列化模块
1.什么是序列化-------将原本的字典,列表等内容转换成一个字符串的过程就叫做序列化
2.序列化的目的
1.以某种存储形式使自定义对象持久化
2.将对象从一个地方传递到另一个地方
3.使程序更具维护性
json
Json模块提供了四个功能:dumps、loads、dump、load
1 import json
2 dic={'k1':'v1','k2':'v2','k3':'v3'}
3 print(type(dic))
4 str_dic = json.dumps(dic) #将字典转换成字符串,转换后的字典中的元素是由双引号表示的
5 print(str_dic,type(str_dic))#{"k1": "v1", "k2": "v2", "k3": "v3"} <class 'str'>
6
7
8 dic2 = json.loads(str_dic)#将一个字符串转换成字典类型
9 print(dic2,type(dic2))#{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} <class 'dict'>
10
11 list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}]
12 str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
13 print(type(str_dic),str_dic) #<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
14 list_dic2 = json.loads(str_dic)
15 print(type(list_dic2),list_dic2) #<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]
dumps和loads
1 import json
2 f=open('json_file','w')
3 dic = {'k1':'v1','k2':'v2','k3':'v3'}
4 json.dump(dic,f)# #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
5 f.close()
6
7 f = open('json_file')
8 dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
9 f.close()
10 print(type(dic2),dic2)
dump和load
pickle
json 和 pickle 模块
json:用于字符串和python数据类型之间进行转换
pickle:用于python特有的类型和python的数据类型进行转换
1 # --------------------------
2 import pickle
3 # dic= {'k1':'v1','k2':'v2','k3':'v3'}
4 # str_dic=pickle.dumps(dic)
5 # print(str_dic) #打印的是bytes类型的二进制内容
6 #
7 # dic2 = pickle.loads(str_dic)
8 # print(dic2) #有吧字典给转换回来了
9
10 import time
11 struct_time = time.localtime(1000000000)
12 print(struct_time)
13 f = open('pickle_file','wb')
14 pickle.dump(struct_time,f)
15 f.close()
16
17 f = open('pickle_file','rb')
18 struct_time2 = pickle.load(f)
19 print(struct_time.tm_year)
pickle的dumps,sump和loads,load方法
shelve
shelve也是python提供给我们的序列化工具,比pickle用起来更简单一些。
shelve只提供给我们一个open方法,是用key来访问的,使用起来和字典类似。
1 import shelve
2 f = shelve.open('shelve_file')
3 f['key'] = {'int':10, 'float':9.5, 'string':'Sample data'} #直接对文件句柄操作,就可以存入数据
4 f.close()
5
6 import shelve
7 f1 = shelve.open('shelve_file')
8 existing = f1['key'] #取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错
9 f1.close()
10 print(existing)
11
12 shelve
shelve
这个模块有个限制,它不支持多个应用同一时间往同一个DB进行写操作。所以当我们知道我们的应用如果只进行读操作,我们可以让shelve通过只读方式打开DB
1 import shelve
2 f = shelve.open('shelve_file', flag='r')
3 existing = f['key']
4 f.close()
5 print(existing)
由于shelve在默认情况下是不会记录待持久化对象的任何修改的,所以我们在shelve.open()时候需要修改默认参数,否则对象的修改不会保存。

import shelve
f1 = shelve.open('shelve_file')
print(f1['key'])
f1['key']['new_value'] = 'this was not here before'
f1.close() f2 = shelve.open('shelve_file', writeback=True)
print(f2['key'])
f2['key']['new_value'] = 'this was not here before'
f2.close() 设置writeback
writeback方式有优点也有缺点。优点是减少了我们出错的概率,并且让对象的持久化对用户更加的透明了;但这种方式并不是所有的情况下都需要,首先,使用writeback以后,shelf在open()的时候会增加额外的内存消耗,并且当DB在close()的时候会将缓存中的每一个对象都写入到DB,这也会带来额外的等待时间。因为shelve没有办法知道缓存中哪些对象修改了,哪些对象没有修改,因此所有的对象都会被写入。
Python之常用模二(时间、序列号等等)的更多相关文章
- python之常用模块二(hashlib logging configparser)
摘要:hashlib ***** logging ***** configparser * 一.hashlib模块 Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等. 摘要算法 ...
- Python中常用模块二
一.hashlib (加密) hashlib:提供摘要算法的模块 1.正常的md5算法 import hashlib # 提供摘要算法的模块 md5 = hashlib.md5() md5.upd ...
- layui常用插件(二) 时间插件
日期和时间 html <div class="layui-inline"> <!-- 注意:这一层元素并不是必须的 --> <input type=& ...
- python 列表常用操作(二)
1.tuple 的 unpack a,b = t 2.格式化输出 print('您的输入:{},值为{}',format(a,b)) 3.日期计算 import datetime as dt impo ...
- python中常用的模块二
一.序列化 指:在我们存储数据的时候,需要对我们的对象进行处理,把对象处理成方便存储和传输的数据格式,这个就是序列化, 不同的序列化结果不同,但目的是一样的,都是为了存储和传输. 一,pickle.可 ...
- python常用模块之时间模块
python常用模块之时间模块 python全栈开发时间模块 上次的博客link:http://futuretechx.com/python-collections/ 接着上次的继续学习: 时间模块 ...
- python中常用的时间操作
python中常用的时间模块有time和datetime,以下是这两个模块中常用的方法: #先引入模块 import timefrom datetime import datetiem, timezo ...
- Python 数据类型常用的内置方法(二)
目录 Python 数据类型常用的内置方法(二) 1.字符串类型常用内置方法 1.upper.lower.isupper.islower 2.startswith.endswith 3.format ...
- Python 常用的日期时间命令
今天用到自动添加当前时间,居然把之前的知识忘了,特整理常用的日期时间命令 代码: # 获取当前时间# import time# localtime = time.localtime(time.time ...
随机推荐
- office 安装破解
1. 打开Office Tool Plus.exe部署 2. 添加产品 `excel` `prowerpoint` `word` 3. 选择安装文件管理 选择下载安装 4.安装完成后点击开始部署 5. ...
- TestNG学习笔记 一
一. 介绍 TestNG是一个设计用来简化广泛的测试需求的测试框架,从单元测试(隔离测试一个类)到集成测试(测试由有多个类多个包甚至多个外部框架组成的整个系统,例如运用服务器). 编写一个测试的过程有 ...
- 对MPU6050坐标矩阵修改的学习
MPU6050是根据三轴陀螺仪和三轴加速度计数据通过DMP运算的出欧拉角.系统默认为水平放置, 但是实际使用过程中并不都是水平放置,有些特殊的场合,要求芯片竖直放置,这时候就不得 不修改MPU6050 ...
- 【CUDA开发】CUDA从入门到精通
CUDA从入门到精通(零):写在前面 在老板的要求下,本博主从2012年上高性能计算课程开始接触CUDA编程,随后将该技术应用到了实际项目中,使处理程序加速超过1K,可见基于图形显示器的并行计算对于追 ...
- 数组转字符串,字符串转数组 join(), split();
join() join() 方法用于把数组中的所有元素放入一个字符串. 元素是通过指定的分隔符进行分隔的. arrayObject.join(separator), 默认为使用逗号分隔 var ar ...
- Go语言中byte类型和rune类型(五)
本篇内容本来准备在上一篇写的,想了想还是拆开写. go语言中字符串需要使用用双引号,而单引号用来表示单个的字符,字符也是组成字符串的元素.go语言的字符有两种: uint8类型,或者叫 byte 型, ...
- msql 事务
START TRANSACTION delete from t_emp delete from t_deptcommit START TRANSACTION delete from t ...
- [Next] 二.next.js之组件
next.js 中的组件 next.js 里面的组件(页面)就是 react 里面的组件. 功能组件 在项目之中一个功能组件的创建 , 他可以和父组件放到一个文件里,也可以单独创建一个文件存放组件. ...
- npm命令的使用
本人实际项目开发前端用的是单页vue组件开发.不管是启动项目还是下载依赖,都要使用npm命令. 东凑凑,西拼拼,整理些常用的. 前提:需要下载node.js.这里就不详细说明了.具体参照官方文档. 1 ...
- 087、日志管理之 Docker logs (2019-05-09)
参考https://www.cnblogs.com/CloudMan6/p/7749304.html 高效的监控和日志管理对保持生产系统只需稳定的运行以及排查问题至关重要. 在微服务架构中,由 ...