Selenium_python自动化第一个测试案例(代码基本规范)
发生背景:
最近开始整理Selenium+python自动化测试项目中相关问题,偶然间翻起自己当时学习自动化时候写的脚本,发现我已经快认不出来写的什么鬼流水账了,所以今天特别整理下自动化开发Selenium+python脚本的基本示例;
示例脚本:
1、在这里拿最简单的示例代码分别讲解写脚本时候需要注意的地方,和各模块的作用;
# -*- coding:utf-8 -*-
__author__='dong.c'
from selenium import webdriver
import unittest
import HTMLTestRunner
import sys
from time import sleep
reload(sys)
sys.setdefaultencoding('utf-8')
class BaiduTest(unittest.TestCase):
"""百度首页搜索测试用例"""
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = u"http://www.baidu.com"
def test_baidu_search(self):
driver = self.driver
print u"开始[case_001]百度搜索"
driver.get(self.base_url)
#验证标题
self.assertEqual(driver.title,u"百度一下,你就知道")
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys(u"博客园")
driver.find_element_by_id("su").click()
sleep(3)
#验证搜索结果标题
self.assertEqual(driver.title,u"博客园_百度搜索")
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
testunit = unittest.TestSuite()
testunit.addTest(BaiduTest('test_baidu_search'))
#定义报告输出路径
htmlpath = u"testReport.html"
fp = file(htmlpath,"wb")
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,title=u"百度测试",description = u"测试用例结果")
runner.run(testunit)
fp.close()
代码解释:
1、总体上代码分为五大块:
a、文件保存编码及作者定义
# -*- coding:utf-8 -*-
__author__='dong.c'
b、导入相关基础模块
#从selenium中导入webdriver模块
from selenium import webdriver
#导入unittest模块,作为用例基类
import unittest
#导入html报告生成模块,用于html格式报告生成
import HTMLTestRunner
#导入sys模块
import sys
#导入sleep模块,用于强制等待
from time import sleep
c、设置当前pythony运行环境为utf-8
#设置当前python运行在utf-8编码下,这样你的中文就不会乱码了
reload(sys)
sys.setdefaultencoding("utf-8")
d、定义和实现测试用例
#从unittest.TestCase继承
class BaiduTest(unittest.TestCase):
"""百度首页搜索测试用例"""
#用例初始化函数,自动执行
def setUp(self):
#初始化基于firefox浏览器的实例
self.driver = webdriver.Firefox()
#给当前webdriver设置全局隐性等待时间,最大30s
self.driver.implicitly_wait(30)
#设置url首页
self.base_url = u"http://www.baidu.com"
def test_baidu_search(self):
#简单赋值,这样在本次测试后继续不用每次都写self.driver;
driver = self.driver
#在控制台打印输出
print u"开始[case_001]百度搜索"
#启动浏览器,并访问首页
driver.get(self.base_url)
#验证标题
self.assertEqual(driver.title,u"百度一下,你就知道")
#清理输入框中的数据
driver.find_element_by_id("kw").clear()
#在输入框中输入博客园
driver.find_element_by_id("kw").send_keys(u"博客园")
#单击百度搜索
driver.find_element_by_id("su").click()
#强制等待3s
sleep(3)
#验证搜索结果标题
self.assertEqual(driver.title,u"博客园_百度搜索")
#用例级清理函数、自动执行
def tearDown(self):
#退出webdriver,同时关闭当前webdriver session下所有浏览器窗口
self.driver.quit()
e、测试脚本主运行入口
#python main函数
if __name__ == '__main__':
#初始化一个用例套件集
testunit = unittest.TestSuite()
#往用例套件集中添加一个测试
testunit.addTest(BaiduTest('test_baidu_search'))
#定义报告输出路径,这里是当前目录
htmlpath = u"testReport.html"
#打开测试报告文件
fp = file(htmlpath,"wb")
#构建一个HTMLTestReport执行器
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,title=u"百度测试",description = u"测试用例结果")
#运行测试集
runner.run(testunit)
#关闭打开的测试报告文件
fp.close()
运行代码:
使用上述命令运行后发现打开了百度首页,输入博客园后单击一下百度一下按钮,显示出搜索结果后关闭了浏览器;在当前目录下生成了html格式的测试报告文件;
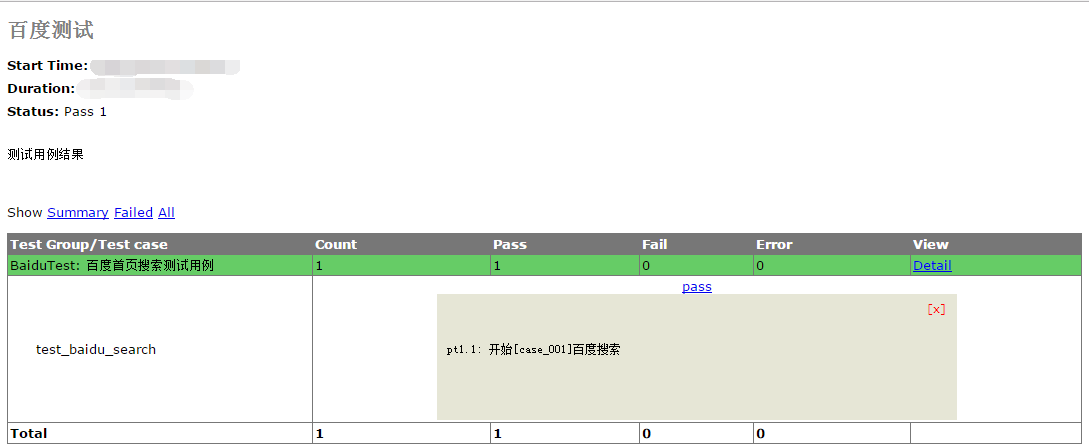
总结:
要注意的关键点,确保selenium环境已经配置好,对应浏览器驱动已经下载;
确保下载了HTMLTestRunner文件;
对应环境问题下篇博客介绍;
Selenium_python自动化第一个测试案例(代码基本规范)的更多相关文章
- Selenium_python自动化跨浏览器执行测试
Selenium_python自动化跨浏览器执行测试(简单多线程案例) 转:https://www.cnblogs.com/dong-c/p/8976746.html 跨浏览器测试是功能测试的一个分 ...
- Selenium(十四):自动化测试模型介绍、模块化驱动测试案例、数据驱动测试案例
1. 自动化测试模型介绍 随着自动化测试技术的发展,演化为了集中模型:线性测试.模块化驱动测试.数据驱动测试和关键字驱动测试. 下面分别介绍这几种自动化测试模型的特点. 1.1 线性测试 通过录制或编 ...
- ENode 2.0 - 第一个真实案例剖析-一个简易论坛(Forum)
前言 经过不断的坚持和努力,ENode 2.0的第一个真实案例终于出来了.这个案例是一个简易的论坛,开发这个论坛的初衷是为了验证用ENode框架来开发一个真实项目的可行性.目前这个论坛在UI上是使用了 ...
- Storm自带测试案例的运行
之前Storm安装之后,也知道了Storm的一些相关概念,那么怎么样才可以运行一个例子对Storm流式计算有一个感性的认识呢,那么下面来运行一个Storm安装目录自带的测试案例,我们的Storm安装在 ...
- 编写优美的GTest测试案例
http://www.cnblogs.com/coderzh/archive/2010/01/09/beautiful-testcase.html 使用gtest也有很长一段时间了,这期间也积累了一些 ...
- robotframework+selenium搭配chrome浏览器,web测试案例(搭建篇)
这两天发布版本 做的事情有点多,都没有时间努力学习了,先给自己个差评,今天折腾了一天, 把robotframework 和 selenium 还有appnium 都研究了一下 ,大概有个谱,先说说we ...
- gtest命令行测试案例
使用gtest编写的测试案例通常本身就是一个可执行文件,因此运行起来非常方便.同时,gtest也为我们提供了一系列的运行参数(环境变量.命令行参数或代码里指定),使得我们可以对案例的执行进行一些有效的 ...
- 如何利用Azure DevOps快速实现自动化构建、测试、打包及部署
前两天有朋友问我,微软的Azure好用吗,适不适合国人的使用习惯,我就跟他讲了下,Azue很好用,这也是为什么微软云营收一直涨涨涨的原因,基本可以再1个小时内实现自动化构建.打包以及部署到Azure服 ...
- 自动化接口差异测试-diffy 回归测试 charles rewrite 请求
https://mp.weixin.qq.com/s/vIxbtQtRRqgYCrDy7XTcrA 自动化接口差异测试-diffy Boris 搜狗测试 2018-08-30 自动化接口差异测试- ...
随机推荐
- 定义类/实例(Class)
# -*- coding: UTF-8 -*- class pp(): '''Description''' def __init__(self,name): #初始化函数 self.nam ...
- windows 下 gdb 的安装
在 windows 下 gcc/g++ 的安装 这篇文章中已经提到,用MinGW Installation Manager可以方便地管理 MinGW 组件,因此使用该软件安装 gdb . 打开 Min ...
- 新特性之MAPI over HTTP \ 配置 MAPI over HTTP
Exchange 2016 中的 MAPI over HTTP https://docs.microsoft.com/zh-cn/Exchange/clients/mapi-over-http/map ...
- c#listbox使用详解和常见问题解决
关于ListBox ListBox是WinForm中的 列表 控件,它提供了一个项目列表(一组数据项),用户可以选择一个或者多个条目,当列表项目过多时,ListBox会自动添加滚动条,使用户可以滚动查 ...
- Windows和Linux环境,网络异常模拟测试方法【转载自光荣之路微信公众号】
1.网络异常的分类 在系统的运行过程中,可能会遇到各种各样的网络问题,其中主要可能出现的问题有 网络延迟:当网络信息流过大时,可能导致设备反应缓慢,造成数据传输延迟: 网路掉包:网路掉包是在数据传输的 ...
- HashMap源代码解析
HashMap原理剖析 之前有看过别人的HashMap源代码的分析,今天尝试自己来分析一波,纯属个人愚见.听一些老的程序员说过,当别人跟你说用某样技术到项目中去,而你按照别人的想法实现了的时候,你只能 ...
- 「CF1025D Recovering BST」
题目 郑州讲过的题了 发现这是一个二叉搜索树,给出的还是中序遍历,我们很自然的想到我们需要可以用一个\(f[i][j][k](k\in[i,j])\)来表示区间\([i,j]\)能不能形成以\(k\) ...
- 【[POI2010]ANT-Antisymmetry】
开始复习字符串了 第一步肯定得是\(hash\) 首先理性分析一波不可能出现长度为奇数的反回文串,对称轴位置取反之后肯定和原来不相等了 我们可以枚举所有回文串的对称中心,之后我们发现这个样子是具有单调 ...
- xss实现钓鱼操作
自己写一个和原网站后台登录地址一模一样的钓鱼页面 JS加载一个iframe 100%覆盖原网页 提示登录超时重新登录 因为是iframe加载 url地址不变 钓鱼成功后 再跳转回/admin/inde ...
- linq项目中例子实例
在mvc项目中 var ls = (from i in gt.vendor_login join j in gt.vendor on i.vendor_id equa ...