HBase系统入门--整体介绍
转自:http://www.aboutyun.com/thread-8957-1-2.html
问题导读:
1.HBase查询与写入哪个更好一些?
2.HBase面对复杂操作能否实现?
3.Region服务器由哪2部分构成?
扩展:
4.HBase能否实现join操作?
5.二级索引的作用是什么?

前言
如今在软件开发领域,谈及大数据已经是家常便饭。笔者相信在未来几年内,大数据的运算和存储一定会成为企业关注的核心。在此普及一个概念,什么级别的数据才能称之为大数据?如果你存储在DB中的数据达到了PB或者单表过亿甚至几十亿行的时候,这就是大数据。传统的RDBMS架构的数据库,在特殊的应用场景下,处理一些半结构化的大数据时,渐渐变得力不从心,虽然构表建索引等一系列的检索优化机制,但仍然无法高效解决大数据背景下的数据存取瓶颈。
目录
一、关系模型与Nosql;
二、HBase环境部署;
三、HBase Shell的使用;
四、HBase内核结构;
五、HBase Client API的使用;
六、HBase内置过滤器;
七、HBase表结构设计要点;
八、构建HBase的反向索引表实现二级索引查询;
一、关系模型与Nosql
相信几乎所有的开发人员都有使用过RDBMS的数据库,这类数据库是构建在关系模型之上的,所强调的概念无非就是表与表之间的依赖关系和固定的表结构。关系模型的数据库拥有确切的数据存储维度,这种维度所呈现出来的形式是一个基于行和列的二维表格,由于维度是固定的,所以一个表的每一行的列也是固定的。并且关系模型的数据库还具备关系规范化、概念简单、数据结构单一等特点。
如果说RDBMS适用于存储结构化数据,那么Nosql(Not-Only-SQL)就是为半结构化数据存储而生的。Nosql数据库都有一个显著的特点,即采用Key-Value的形式对数据进行存储,且结构不固定,也就是说一个表的任意一行的列的数量可以不相同。并且就算定义字段,在不使用的情况下,也并不会占用存储空间,这样在某种程度上来说也降低了一定的存储开销。当然Nosql的数据库不仅仅只是为了解决存储问题,它还能够带给企业非常多的实惠,比如可以部署在廉价的PC服务器上集群用于处理大规模的海量数据,并且由于没有SQL->DBMS的编译过程耗时,Nosql将会在某些情况下更为高效。Nosql的数据库在扩展性和可用性方面同样也非常优秀。
二、HBase环境部署
Nosql只是非关系型数据库的一种概念,目前市面上比较成熟和优秀的Nosql产品有:HBase、Mongodb、Membase等等。当然笔者本篇博文还是主要以HBase为主,关于其它的Nosql数据库,大家可以参考阅读其它的技术文章或者书籍进行了解和掌握。
HBase是Hadoop平台下数据存储引擎,它能够为大数据提供实时的读/写操作,但是根据实际情况来看,HBase在实时的数据写入性能上优于查询性能。HBase具备开源、分布式、可扩展性以及面向列的存储特点,使得HBase可以部署在廉价的PC服务器集群上处理大规模的海量数据。HBase最早是由Google的Bigtable演变而来,所以熟悉Bigtable的开发人员应该不会陌生HBase的使用。HBase的存储方式有2种,一种是使用操作系统的本地文件系统,另外一种则是在集群环境下使用Hadoop的HDFS,相对而言,使用HDFS将会使数据更加稳定。HBase的存储的是松散型数据,也就是半结构化数据,那么注定HBase的存储维度是动态可变的。也就是说HBase表中的每一行可以包含不同数量的列,并且某一行的某一列还可以有多个版本的数据,这主要通过时间戳范围进行区分。HBase不仅可以向下提供运算,它还能够结合Hadoop的MapReduce向上提供运算,这些都是HBase所具备的特点,如图2-1所示。
<ignore_js_op>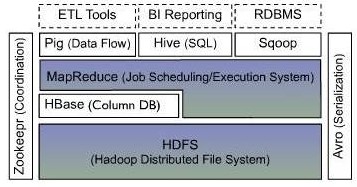
图2-1 分布式环境下的HBase结构图
本文所使用的HBase版本为hbase-0.96.0-hadoop2,笔者建议大家尽量保持和本文一致的版本,这样便可以避免因版本问题导致的不一致情况出现。当大家成功下载好HBase的安装包后,我们通过命令“tar -xzvf hbase-0.96.0-hadoop2-bin.tar.gz”将其解压,解压后的文件目录如图2-2所示:
<ignore_js_op>
图2-2 HBase安装包解压示例
在开始启动HBase之前,我们首先需要修改${HBase-Dir}/conf/hbase-site.xml文件,该文件是HBase的配置文件,通过修改这个文件,开发人员可以更新HBase的基本配置(包括集群配置)。除了hbase-default.xml外,还有一个叫做hbase-default.xml的配置文件,该文件是Hbase的缺省配置文件,并且它和hbase-site.xml文件完全相同。当HBase启动时,首先会加载hbase-site.xml,如果hbase-site.xml中有更新,则会覆盖掉hbase-default.xml中的内容,所以笔者建议大家只修改hbase-site.xml即可,这样一旦当hbase-site.xml配置错误,我们可以迅速从hbase-default.xml中进行配置还原。
HBase的单机配置如下:
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!-- HBase单机版本配置 -->
- <configuration>
- <!-- 定义HBase存储路径 -->
- <property>
- <name>hbase.rootdir</name>
- <value>file:///usr/hadoop/hbase-data</value>
- </property>
- </configuration>
复制代码
当成功配置好hbase-site.xml后,输入命令“./start-hbase.sh”便可以成功启动HBase的服务,如图2-3所示。
<ignore_js_op>
图2-3 HBase启动示例
上述我们成功启动了Hbase服务,大家可以通过命令“jps”查看HBase的Master的进程,并且如果需要停止HBase服务,则可以使用命令“/.stop-hbase.sh”,
如图2-4。
<ignore_js_op>
图2-4 HBase停止示例
三、HBase Shell的使用
当成功启动HBase服务后,输入“./hbase shell”命令即可进入HBase的shell程序,如图3-1所示。HBase shell类似于Oracle的SQL PLUS操作,并且提供有大多数的HBase命令,开发人员可以很方便的进行表的CRUD操作,只不过如果要使用复杂的查询(比如:多条件检索),HBase Shell则显得有些无能为力。当然如果只是简单的CRUD操作,HBase Shell还是能够很好胜任。
<ignore_js_op>
图3-1 使用HBase Shell检索数据
在开始进行CRUD操作之前,我们首先需要创建一个表。在HBase中,创建一个表则可以使用命令“create 'TableName','Columnfamily'“,如图3-2所示。
<ignore_js_op>
图3-2 创建表
如果需要在HBase Shell中删除一个表可以使用命令”drop 'TableName'“,但是在删除之前首先需要执行命令”Diasable 'TableName'“将运行时的表暂停掉,如图3-3所示。
<ignore_js_op>
图3-3 暂停表与删除表
当成功创建好表后,我们可以使用命令“list”检索HBase中的所有表,如图3-4所示。
<ignore_js_op>
图3-4 使用list命令检索Hbase中所有表
使用命令“put 'TableName','RowKey','ColumnFamily:ColumnName','value'”既可向表中插入一列数据,如图4-5所示。在此笔者需要提醒大家,在HBase中并不存在update和delete操作,这些操作其实都是以追加形式呈现,并通过版本时间戳进行区分和取值(取最新的值,当然也可以设定时间戳取历史值)。我们可以简单的把HBase理解为一个很大的HashTable,Key-Value形式就是其存储结构,当使用put操作的时候,如果RowKey不存在就是添加,反之就是更新。
<ignore_js_op>
图3-5 使用put命令插入数据
HBase中数据检索有2种形式,一种是直接建立在索引的基础之上使用get检索,这种方式相当高效。另外一种则是通过定位Region范围后,通过Scan扫表的方式检索数据。在HBase中RowKey就是索引,程序中我们可以通过命令“get 'TableName','Row'”执行数据检索,如图3-6所示。
<ignore_js_op>
图3-6 使用get命令检索数据
上述程序示例中,笔者演示了如何使用get命令检索数据,那么接下来再来看看如何使用Scan检索数据。一般来说使用Scan扫表更多的是体现到检索规则上,可能由于业务需要,我们需要根据时间范围、行关键字、分页等一系列的条件来检索数据,这个时候get操作将不再适用,如图3-7所示。
<ignore_js_op>
图3-7 使用Scan命令检索数据
或许在实际的开发过程中,我们往往需要根据业务需要使用count关键字统计业务表的行数。在RDBMS中,使用count进行行数统计效率非常高,而在HBase中同样也提供命令”count 'tableName'“,只不过这种方式并不高效,因为HBase在执行count命令的时候采用逐行累加计数,这种方式极为低效,如图3-8所示。
<ignore_js_op>
图3-8 使用count命令统计
四、HBase内核结构
HBase遵循的是简单的Master/Slave架构,它由Master服务器和Region服务器构成,在集群环境中HBase的所有服务器都是通过ZooKeeper来进行调度,并处理HBase运行时可能遇见的错误,如图4-1所示。Master服务器负责管理集群环境中所有的Region服务器,但它本身并不负责数据存储,而是存储数据到Region服务器之间的映射(数据由集群环境中的Region服务器存储),并且Master服务器还负责管理用户对表的CRUD操作、管理Region服务器的负载均衡,调整Region分布、负责Region分块后的任务分配、负责Region服务器Down掉后的失效转移操作等。
<ignore_js_op>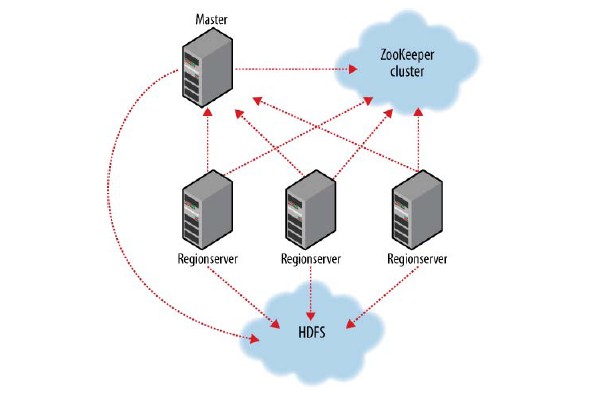
图4-1 HBase内核结构
上述笔者提到过,在HBase中负责数据存储的是Region服务器,那么Region服务器我们却可以把它看做是一张很大的表。Region服务器中由多个Region块构成,每一个Region块中其实是包含行的一个子集,对于用户来说每一个Region块中存储的就是一堆连续的数据集合,靠主键来进行区分。
Region服务器由2部分构成:HLog和Region块。其中HLog用来存储数据日志,而Region块存储的是实际的数据值。在Region块中又由多个的Store组成,每一个Store中存储的实际是一个ColumnFamily下的数据,此外每一个Store中还包含有一块memStore(写入缓存)和多个StoreFile(最小数据存储单元)。当数据来领时,HBase会首先写入到memStore中,达到阈值后再通过StoreFile写入到文件系统或者HDFS中,这样做的目的可以有效的降低磁盘I/O的读写率,提高大数据的存储性,如图4-2所示。
<ignore_js_op>
图4-2 Region服务器内核结构
在Region服务器中,如果一个Region块由于数据存储超出了预设的阈值后,Region服务器会将原来的一个Region块拆分成2个Region块,并通知Master服务器并由它决定Region分块后到底由哪一个Region服务器来负责存储新的Region块。从物理结构上来说一个完整的表,应由多个Region块构成,但多个Region块是分散的,有可能存储在多个Region服务器中。Region块的拆分速度相当快,因为新的Region块最初只是保留原Region块的引用,只有当完全拆分完成并删除引用后,旧的Region块中的数据才会执行删除。
五、HBase Client API的使用
在实际的程序开发过程中,我们往往需要在程序中使用HBase Client API访问HBase服务,那么必不可少的构件就是HBase相关的所需构件等。我们首先需要将构件添加或引用至项目工程中,并在ClassPath下添加”conf/hbase-site.xml“文件。
程序中hbase-site.xml配置如下:
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>hbase.rootdir</name>
- <value>file:///home/johngao/hadoop/hadoop-data</value>
- </property>
- <property>
- <name>hbase.cluster.distributed</name>
- <value>false</value>
- </property>
- <property>
- <name>hbase.zookeeper.property.clientPort</name>
- <value>2181</value>
- </property>
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>192.168.1.102</value>
- </property>
- </configuration>
复制代码
上述配置文件中,”hbase.rootdir“定义了HBase的存储路径,如果是集群环境则需要指定HDFS的存储路径。”hbase.cluster.distributed“指定了HBase是否是配置集群,缺省为false,反之为true。”hbase.zookeeper.property.clientPort“定义了HBase服务中ZooKeeper的访问端口,一般来说单机版安装HBase不需要单独搭建Zookeeper服务,但如果是集群,笔者还是建议你单独搭建Zookeeper集群服务更有优势。”hbase.zookeeper.quorum“指定了ZooKeeper的地址,因为HBase都是依赖ZooKeeper的做任务调度,所以必须要在程序中指定ZooKeeper的访问地址,如果是集群环境,则可以通过符号”,“添加多个ZooKeeper地址。
HBase Client API示例:
- /**
- * HBase客户端调用示例
- *
- * @author JohnGao
- */
- public class HBaseTest {
- private static Configuration cfg;
- private static HTablePool tablePool;
- private Logger log = Logger.getLogger(this.getClass().getName());
- static {
- cfg = HBaseConfiguration.create();
- /* 创建tablePool,并定义Pool大小 */
- tablePool = new HTablePool(cfg, 1000);
- }
- @Test
- public void testInsert() {
- try {
- final String TABLE_NAME = "test_table";
- /* 创建HTable对象获取表信息 */
- HTableInterface table = tablePool.getTable(TABLE_NAME);
- /* 创建Row Key */
- final String ROW_KEY = "JohnGao"
- + ":"
- + String.valueOf(Long.MAX_VALUE
- - System.currentTimeMillis());
- /* 创建Put对象,插入行级数据 */
- Put put = new Put(ROW_KEY.getBytes());
- put.add("message".getBytes(), "content1".getBytes(),
- "Hello HBase1".getBytes());
- put.add("message".getBytes(), "content2".getBytes(),
- "Hello HBase2".getBytes());
- /* 开始执行数据添加 */
- table.put(put);
- /* 资源释放 */
- release(table);
- log.info("数据插入成功");
- } catch (IOException e) {
- log.error("数据插入失败", e);
- }
- }
- @Test
- public void testGet() {
- try {
- final String TABLE_NAME = "test_table";
- /* 创建HTable对象获取表信息 */
- HTableInterface table = tablePool.getTable(TABLE_NAME);
- /* 创建Row Key */
- final String ROW_KEY = "JohnGao"
- + ":"
- + String.valueOf(Long.MAX_VALUE
- - System.currentTimeMillis());
- Get get = new Get(ROW_KEY.getBytes());
- /* 定义需要检索的列 */
- get.addColumn("message".getBytes(), "content1".getBytes());
- Result result = table.get(get);
- /* 输出数据 */
- System.out.println(Bytes.toString(result.getValue(
- "message".getBytes(), "content1".getBytes())));
- /* 资源释放 */
- release(table);
- } catch (IOException e) {
- log.error("数据检索失败", e);
- }
- }
- /**
- * HBase资源释放
- *
- * @author JohnGao
- */
- public void release(HTableInterface table) throws IOException {
- /* 清空缓冲区并提交 */
- table.flushCommits();
- /* 将Table对象归还Pool */
- tablePool.putTable(table);
- }
- }
复制代码
注释:HTablePool是HBase连接池的老用法,该类在0.94,0.95和0.96中已经不建议使用,在0.98.1版本以后已经移除。但是并不影响初学者对hbase的理解。想进一步了解可参考:HBase连接池 -- HTablePool被Deprecated以及可能原因是什么
注意:
如果是使用HBase Client的方式访问HBase服务,则务必在C:\Windows\System32\drivers\etc\hosts文件中添加HBase服务器的IP+机器名映射,否则无法访问HBase服务。这是因为HBase是通过hostname解析IP地址的(DNS),Zookeeper只会返回Hbase的域名,所以需要客户端通过DNS或本地hosts文件进行解析。
六、HBase内置过滤器
HBase提供了许多内置过滤器来帮助开发人员提高表中的数据检索效率,在实际的开发过程中,大家不仅可以使用缺省的内置过滤器,还可以实现自定义过滤器。至于为什么需要在程序中使用过滤器?这就好比我们在RDBMS的SQL中使用许多的and或or条件一样,过滤器就是HBase中的检索条件。过滤器其实是在客户端创建,然后通过RPC协议传送到服务端,最后由服务端执行过滤操作,如图6-1所示。在此笔者需要提醒大家,程序中如果过滤器使用的越多,程序的检索效率就会越低效。
<ignore_js_op>
图6-1 HBase过滤器结构
在HBase中,过滤器的层次结构最底层是Filter接口和FilterBase抽象类,它们实现了过滤器的基础架构,这使得实际的过滤器类可以避免许多的冗余结构代码。本文笔者不打算演示所有的HBase缺省过滤器,仅演示常用的分页过滤器和行键过滤器。
在HBase中分页过滤器由PageFilter实现:
- @Test
- public void queryDatabyFilter(String tablePrefix, int startNum,
- int totalNum, String rowKey) {
- try {
- final String TABLE_NAME = "test_table";
- /* 创建HTable对象获取表信息 */
- HTableInterface table = tablePool.getTable(TABLE_NAME);
- /* 定义分页过滤器 */
- Filter pageFilter = new PageFilter(totalNum);
- int totalRows = 0;
- byte[] lastRow = null;
- Scan can = new Scan();
- can.setFilter(pageFilter);
- for (int i = 0; i < 1; i--) {
- if (null != lastRow) {
- byte[] startRow = Bytes.add(lastRow,
- String.valueOf(startNum).getBytes());
- can.setStartRow(startRow);
- }
- ResultScanner rts = table.getScanner(can);
- int localRows = 0;
- Result rt = null;
- while ((rt = rts.next()) != null) {
- System.out.println(Bytes.toString(rt.getValue(
- "message".getBytes(), "message".getBytes())));
- totalRows++;
- lastRow = rt.getRow();
- }
- /* 资源释放 */
- release(table);
- if (0 == localRows)
- break;
- }
- } catch (IOException e) {
- log.error("分页获取数据失败", e);
- }
- }
复制代码
上述程序示例中,我们首先需要在PageFilter的构造中指定分页的固定totalNum,然后在Scan中添加过滤器支持,这样一来我们便可以在程序中实现HBase的分页请求。但是上述程序示例并没有指定过滤行健,也就是说按照上述分页情况将会检索整表,如果想根据行健进行检索,我们则可以在程序中再次添加一个行过滤器与分页过滤器组合使用,然后通过一个过滤器链表把2个过滤器组织在一起进行联合过滤。
分页过滤器+行健过滤器的组合使用:
- @Test
- public void queryDatabyFilter(String tablePrefix, int startNum,
- int totalNum, String rowKey) {
- List<Filter> filters = new ArrayList<Filter>();
- try {
- final String TABLE_NAME = "test_table";
- /* 创建HTable对象获取表信息 */
- HTableInterface table = tablePool.getTable(TABLE_NAME);
- /* 定义行过滤器 */
- Filter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL,
- new SubstringComparator(rowKey));
- filters.add(rowFilter);
- /* 定义分页过滤器 */
- Filter pageFilter = new PageFilter(totalNum);
- filters.add(pageFilter);
- /* 添加过滤器列表 */
- FilterList filterList = new FilterList(filters);
- int totalRows = 0;
- byte[] lastRow = null;
- Scan can = new Scan();
- /* 锁定Region块范围 */
- can.setStartRow(rowKey.getBytes());
- can.setStopRow(new String(rowKey + ":"
- + String.valueOf(Long.MAX_VALUE)).getBytes());
- can.setFilter(filterList);
- for (int i = 0; i < 1; i--) {
- if (null != lastRow) {
- byte[] startRow = Bytes.add(lastRow,
- String.valueOf(startNum).getBytes());
- can.setStartRow(startRow);
- }
- ResultScanner rts = table.getScanner(can);
- int localRows = 0;
- Result rt = null;
- while ((rt = rts.next()) != null) {
- System.out.println(Bytes.toString(rt.getValue(
- "message".getBytes(), "message".getBytes())));
- totalRows++;
- lastRow = rt.getRow();
- }
- /* 资源释放 */
- release(table);
- if (0 == localRows)
- break;
- }
- } catch (IOException e) {
- log.error("获取数据失败", e);
- }
- }
复制代码
上述程序示例中,笔者通过设定起止行健定位Region块位置,能够是明显提升检索效率。因为笔者前面提到过一个完整的表,在物理环境下会由多个Region块构成,且分布在不同的Region服务器中。如果一个检索条件不定位到目标Region块中进行检索,那么HBase将会对整表所有的Region进行逐一检索,自然而然,这种检索效率无疑是相当低效的。
七、HBase表结构设计要点
1、谈到HBase的表结构设计,最重要的无疑就是RowKey的设计,因为在HBase中Put条件直接决定了Query条件。在HBase中表可以设计为高表(tall-narrow table)和宽表2(flat-wide table)种形式。高表指的是列少行多,也就是说表中的每一行尽可能保持唯一。宽表正好相反,通过时间戳版本来进行区分取值。由于HBase的索引就是RowKey,所以我们应该尽可能的把检索条件存储于行健中,这样的检索效率才会是最高效的。并且HBase只能按行进行分片,因此将表设计为高表会更有优势。
2、HBase在设计的时候,切勿定义过多的ColumnFamily,一般来说一张表一个ColumnFamily足矣。就目前的HBase的版本而言,对于2个以上的ColumnFamily支持并不好,因为Flushing和压缩是基于Region块的。当一个ColumnFamily所存储的数据达到Flushing的阈值时,该表中的所有ColumnFamily将同时进行Flushing操作,这将会带来许多不必要的I/O读写消耗,ColumnFamily越多,对性能的影响也就越大。除此之外,每一个表中不同ColumnFamily存储的数值量差别也不应该太大,否则检索效率也会受到不同程度的影响。
3、HBase在进行数据存储的时候,新的数据并不会直接覆盖旧的数据,而是通过追加的形式呈现,并通过时间戳进行区分取值。缺省情况下,每行数据存储三个版本,虽然可以修改版本数据,但不建议设置过大。
八、构建HBase的反向索引表实现二级索引查询
就目前版本而言HBase并没有提供缺省的二级索引支持,但在开发过程中我们可以通过建立反向索引表的方式实现自定义的二级索引检索。假设我们设定主表A,RowKey为’Account‘,字段为’PhoneNumber‘,反向索引表B的RowKey为’PhoneNumber‘,字段为A表的RowKey,这样的结构既可以满足二级索引检索,如图8-1。
<ignore_js_op>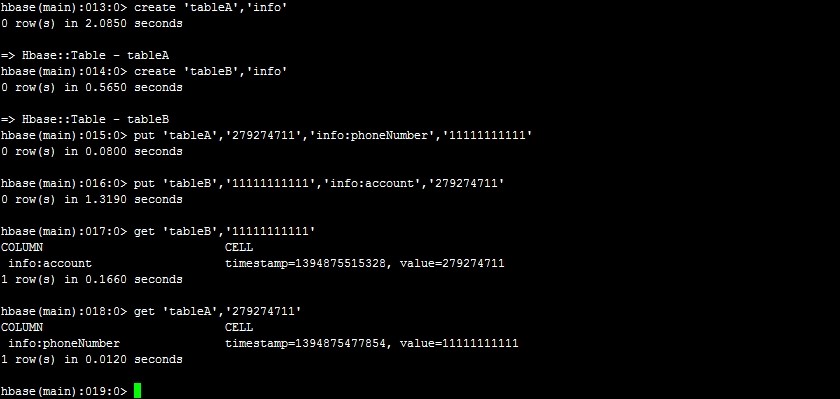
图8-1 二级索引检索数据
HBase系统入门--整体介绍的更多相关文章
- HBase 基本入门
目录 一.简介 有什么特性 与RDBMS的区别 二.数据模型 三.安装HBase 四.基本使用 表操作 五.FAQ 参考文档 无论是 NoSQL,还是大数据领域,HBase 都是非常"炙热& ...
- IT技术学习指导之Linux系统入门的4个阶段(纯干货带图)
IT技术学习指导之Linux系统入门的4个阶段(纯干货带图) 全世界60%的人都在使用Linux.几乎没有人没有受到Linux系统的"恩惠",我们享受的大量服务(包括网页服务.聊天 ...
- Hbase 0.95.2介绍及下载地址
HBase是一个分布式的.面向列的开源数据库,该技术来源于Google论文“Bigtable:一个结构化数据的分布式存储系统”.就像Bigtable利用了Google文件系统(File System) ...
- HBase的Snapshots功能介绍
HBase的Snapshots功能介绍 hbase的snapshot功能还是挺有用的,本文翻译自cloudera的一篇博客,希望对想了解snapshot 的朋友有点作用,如果翻译得不好的地方,请查看原 ...
- (一)ROS系统入门 Getting Started with ROS 以Kinetic为主更新 附课件PPT
ROS机器人程序设计(原书第2版)补充资料 教案1 ROS Kinetic系统入门 ROS Kinetic在Ubuntu 16.04.01 安装可参考:http://blog.csdn.net/zha ...
- HBase轻松入门之HBase架构图解析
2018-12-13 2018-12-20 本篇文章旨在针对初学者以我本人现阶段所掌握的知识就HBase的架构图中各模块作一个概念科普.不对文章内容的“绝对.完全正确性”负责. 1.开胃小菜 关于HB ...
- SNF快速开发平台--规则引擎整体介绍及使用说明书
一.设计目标 a)规则引擎语法能够满足分单,计费,WMS策略的配置要求.语法是一致和统一的 b)能够在不修改规则引擎模块的情况下,加入任意一个新的规则:实现上述需求之外的规则配置需求 c)运算速度快 ...
- 列式存储hbase系统架构学习
一.Hbase简介 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行 ...
- PyQt5整体介绍
1 PyQt5整体介绍 PyQt5是基于图形程序框架Qt5的Python语言实现,由一组Python模块构成. PyQt5的官方网站是:www.riverbankcomputing.co.uk. Py ...
随机推荐
- Python ceil() 函数
描述 ceil(x) 函数返回一个大于或等于 x 的的最小整数(向上取整). 语法 以下是 ceil() 方法的语法: import math math.ceil( x ) 注意:ceil()是不能直 ...
- YOLO 详解
YOLO核心思想:从R-CNN到Fast R-CNN一直采用的思路是proposal+分类 (proposal 提供位置信息, 分类提供类别信息)精度已经很高,但是速度还不行. YOLO提供了另一种更 ...
- java web中jsp常用标签
在jsp页面开发过程中,经常需要使用JSTL(Java Server Pages Standard Tag Library)标签开开发页面,是看起来更加的规整舒服. JSTL主要提供了5大类标签库: ...
- ISE在win8.1的安装问题
问题1:.lic无法打开 打开:C:\Xilinx\14.6\ISE_DS\ISE\lib\nt64 思路是这样: 将libPortability.dll重命名(加尾缀.orig,意思是origina ...
- particleDesigner2 positionType按钮
在particleDesigner2中positionType对应的设置是:
- [Jobdu] 题目1500:出操队形
题目描述: 在读高中的时候,每天早上学校都要组织全校的师生进行跑步来锻炼身体,每当出操令吹响时,大家就开始往楼下跑了,然后身高矮的排在队伍的前面,身高较高的就要排在队尾.突然,有一天出操负责人想了一个 ...
- jquery data方法获取某个元素上事件
获取某个元素上的事件,jquery的给元素绑定的事件可以用data方法取出来. 通过$(element).data("events")来获取 // 比如给一个button绑定两个c ...
- Linux下nagios网络监控与/proc/net/tcp文件详解
问题描述:nagios自带的check_antp太过简约,除了状态统计输出外,什么参数都不提供.在面对不同应用服务器时,报警就成了很大问题. 问题描述:nagios自带的check_antp太过简约, ...
- 如何在 block 中修改外部变量
转自:http://www.cnblogs.com/easonoutlook/archive/2012/08/22/2650070.html block 的目的是为了支持并行编程,对于普通的 loca ...
- ny225 小明求素数积
小明求素数积时间限制:1000 ms | 内存限制:65535 KB 难度:1描述 小明最近遇到了一个素数题,是给你一个正整数N(2=<N<=1000)让你求出2~N的所有素数乘积的后 ...