scala集合与数据结构
1、数据结构特点
Scala同时支持可变集合和不可变集合,不可变集合从不可变,可以安全的并发访问。
两个主要的包:
不可变集合:scala.collection.immutable
可变集合: scala.collection.mutable
Scala优先采用不可变集合,对于几乎所有的集合类,Scala都同时提供了可变和不可变的版本。
不可变集合继承层次:
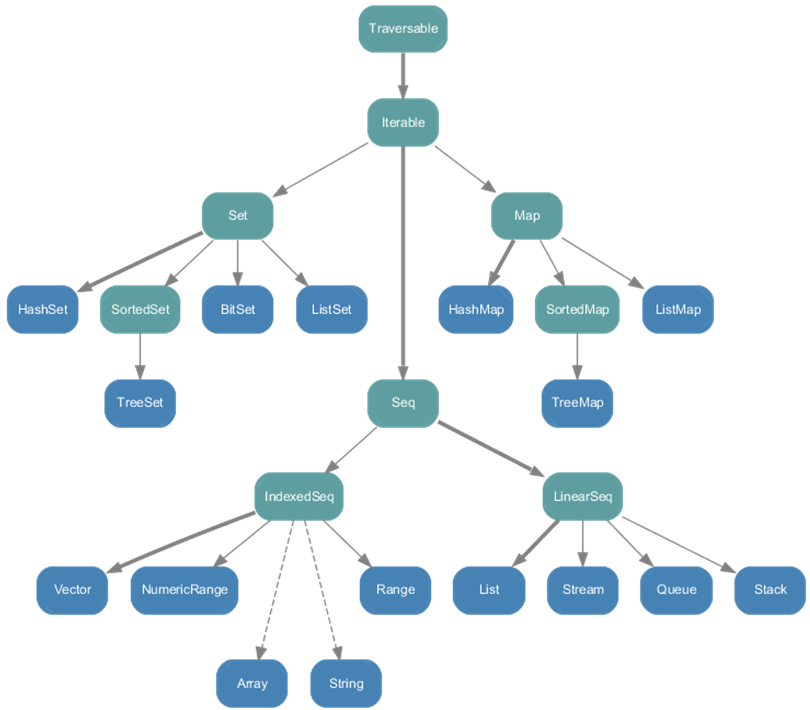
可变集合继承层次:

2、数组
2.1、定义定长数组
我们可以定义一个固定长度大小和类型的定长数组
|
,类型为Int的固定大小数组 val array = new Array[Int](10) array(1) = 10 array(2) = 20 //访问数组当中的某一个下标元素值 println(array(1)) //直接使用apply方法进行生成一个数组 val array2 = Array(1,2,3) //访问数组的元素 println(array2(2)) |
2.2、变长数组
我们也可以通过ArrayBuffer来定义一个变长数组
|
val array3 = new ArrayBuffer[Int]() array3.append(20) val array4 = ArrayBuffer[String]() array4.append("helloworld") |
2.3、定长数组与变长数组的相互转换
|
//定长数组转换成变长数组 val toBuffer = array.toBuffer toBuffer.append(50) //变长数组准换成定长数组 val toArray = array3.toArray |
2.4、多维数组
我们可以通过Array的ofDim方法来定义一个多维的数组,多少行,多少列,都是我们自己定义说了算
|
val dim = Array.ofDim[Double](3,4) dim(1)(1) = 11.11 println(dim.mkString(",")) |
2.5、scala当中数组的遍历
|
val array5 = ArrayBuffer(1,2,3,4,5,6) for(x <- array5){ println(x ) } |
2.6、数组的常见算法
|
val array6 = Array(1,2,3,4,5,6) //求和 array6.sum //求最大值 array6.max //排序 array6.sorted |
3、元组tuple
在scala当中提供元组tuple的数据类型,可以理解tuple为一个容器,可以存放各种不同的数据类型的数据,例如一个Tuple当中既可以存放String类型数据,同时也可以存放Int类型的数据
注意:注意元组一旦创建之后,就是不可变的,也就是说元组当中没有添加和删除元素这一说
3.1、创建元组
创建元组,直接使用小括号,小括号当中存放我们元组当中各种类型的元素即可
|
val tuple1 = ("hello",1,5.0f) println(tuple1) |
3.2、元组数据的访问
访问元组当中的数据直接使用_加角标即可,但是要注意,元组当中的数据角标是从1开始的
|
val tuple1 = ("hello",1,5.0f) println(tuple1) val tuple1Result = tuple1._1 println(tuple1Result) |
3.3、元组的遍历
|
val tuple1 = ("hello",1,5.0f) println(tuple1) val tuple1Result = tuple1._1 println(tuple1Result) |
//第一种方式遍历元组
|
for(x <- tuple1.productIterator){ println(x) } //第二种方式遍历元组 tuple1.productIterator.foreach( x => println(x)) |
4、映射Map
scala当中的Map集合与java当中的Map类似,也是key,value对形式的
4.1、不可变映射
|
val map1 = Map("hello" ->"world","name" -> "zhangsan","age" -> 18) |
4.2、可变映射及其操作
|
val map2 = scala.collection.mutable.Map("hello" ->"world","name" -> "zhangsan","age" -> 18) //可变map添加元素 map2.+=("address" ->"地球") println(map2) //可变map删除元素.注意,删除元素是返回一个删除元素之后的map,原来的map并没有改变 val map3 = map2.-("address") println(map2) println(map3) //可变map更新元素 map2("address") ="火星" println(map2) //或者使用覆盖key的方式来更细元素 map2 += ("address" -> "北京") println(map2) //或者使用 + 来进行更新元素 //注意,map当中没有phonNo这个key,则不能更细 map2 +("address" ->"上海","phonNo" -> "13688886666") println(map2) |
4.3、获取map当中指定的key值
|
//通过key来进行取值 map2.get("address") //通过key来进行取值,如果没有这个key,就用后面给定的默认值 map2.getOrElse("address","非洲") //通过key来进行取值,真的没有这个key,那么就用后面给定的默认值 map2.getOrElse("phoNo","13133335555") |
4.4、遍历Map当中的元素
|
//遍历key与value for((k,v) <- map2){ println(k) println(v) } //遍历获取所有的key for(k <- map2.keys) { println(k) } //遍历获取所有的value for(v <- map2.values) { println(v) } //打印key,value对 for(kv <- map2){ println(kv) } |
4.5、将对偶的数组转变为map
|
//将对偶的元组转变为map val arrayMap = Array(("name","zhangsan"),("age",28)) val toMap = arrayMap.toMap println(toMap) |
5、列表(List)
scala当中也提供有与java类似的List集合操作
5.1、创建列表
注意:列表当中的元素类型可以是不同的,这一点与我们元组类似,但是列表当中的元素是可以删减的
|
val list1 = List("hello",20,5.0f) println(list1) |
5.2、访问列表当中的元素
|
//访问列表当中的元素 val list1Result = list1(0) println(list1Result) |
5.3、列表当中添加元素
我们可以从列表头部或者尾部添加元素
|
val list2 = list1:+50 val list3 = 100+:list1 println(list2) println(list3) |
5.4、List的创建与追加元素
Nil是一个空的List,定义为List[Nothing]
|
//尾部添加了Nil,那么就会出现List集合里面装List集合的现象 val list4 = 1::2 ::3 :: list1 ::Nil println(list4) //尾部没有添加Nil的值,那么所有的元素都压平到一个集合里面去了 val list5 = 1::2::3::list1 println(list5) |
5.5、变长List的创建与使用
|
val list6 = new ListBuffer[String] list6.append("hello") list6.append("world") println(list6.mkString(",")) val list7 = list6.toList println(list7) |
5.6、List操作延伸阅读
Scala是函数式风格与面向对象共存的编程语言,方法不应该有副作用是函数风格编程的一个重要的理念。方法唯一的效果应该是计算并返回值,用这种方式工作的好处就是方法之间很少纠缠在一起,因此就更加可靠和可重用。另一个好处(静态类型语言)是传入传出方法的所有东西都被类型检查器检查,因此逻辑错误会更有可能把自己表现为类型错误。把这个函数式编程的哲学应用到对象世界里以为着使对象不可变。
前面一章介绍的Array数组是一个所有对象都共享相同类型的可变序列。比方说Array[String]仅包含String。尽管实例化之后你无法改变Array的长度。因此,Array是可变的对象。
说到共享相同类型的不可变对象类型,Scala的List类才是。和数组一样,List[String]包含的仅仅是String。Scala的List不同于Java的java.util.List,总是不可变的(Java的List是可变)。更准确的说法,Scala的List是设计给函数式风格的编程用的。
(1)List类型定义以及List的特点:
|
//字符串类型List scala> val fruit=List("Apple","Banana","Orange") fruit: List[String] = List(Apple, Banana, Orange) //前一个语句与下面语句等同 scala> val fruit=List.apply("Apple","Banana","Orange") fruit: List[String] = List(Apple, Banana, Orange) //数值类型List scala> val nums=List(1,2,3,4,5) nums: List[Int] = List(1, 2, 3, 4, 5) //多重List,List的子元素为List scala> val list = List(List(1, 2, 3), List("adfa", "asdfa", "asdf")) list: List[List[Any]] = List(List(1, 2, 3), List(adfa, asdfa, asdf)) //遍历List scala> for(i <- list; from=i; j<-from)println(j) adfa asdfa asdf |
(2)List与Array的区别:
1、List一旦创建,已有元素的值不能改变,可以使用添加元素或删除元素生成一个新的集合返回。
如前面的nums,改变其值的话,编译器就会报错。而Array就可以成功
|
scala>nums(3)=4 <console>:10: error: value update is not a member of List[Int] nums(3)=4 ^ |
2、List具有递归结构(Recursive Structure),例如链表结构
List类型和气他类型集合一样,它具有协变性(Covariant),即对于类型S和T,如果S是T的子类型,则List[S]也是List[T]的子类型。
例如:
|
scala>var listStr:List[Object] = List("This", "Is", "Covariant", "Example") listStr:List[Object] = List(This, Is, Covariant, Example) //空的List,其类行为Nothing,Nothing在Scala的继承层次中的最底层 //,即Nothing是任何Scala其它类型如String,Object等的子类 scala> var listStr = List() listStr:List[Nothing] = List() scala>var listStr:List[String] = List() listStr:List[String] = List() |
(3)List常用构造方法
|
//1、常用::及Nil进行列表构建 scala> val nums = 1 :: (2:: (3:: (4 :: Nil))) nums: List[Int] = List(1, 2, 3, 4) //由于::操作符的优先级是从右向左的,因此上一条语句等同于下面这条语句 scala> val nums = 1::2::3::4::Nil nums:List[Int] = List(1, 2, 3, 4) |
至于::操作符的使用将在下面介绍
(4)List常用操作
|
//判断是否为空 scala> nums.isEmpty res5: Boolean = false //取第一个元素 scala> nums.head res6: Int = 1 //取列表第二个元素 scala>nums.tail.head res7: Int = 2 //取第三个元素 scala>nums.tail.tail.head res8: Int = 3 //插入操作 //在第二个位置插入一个元素 scala>nums.head::(3::nums.tail) res11: List[Int] = List(1, 3, 2, 3, 4) scala> nums.head::(nums.tail.head::(4::nums.tail.tail)) res12: List[Int] = List(1, 2, 4, 3, 4) //插入排序算法实现 def isort(xs: List[Int]):List[Int] = { if(xs.isEmpty) Nil else insert(xs.head, issort(xs.tail)) } def insert(x:Int, xs:List[Int]):List[Int] = { if(xs.isEmpty || x <= xs.head) x::xs else xs.head :: insert(x, xs.tail) } //连接操作 scala>List(1, 2, 3):::List(4, 5, 6) res13: List[Int] = List(1, 2, 3, 4, 5, 6) //去除最后一个元素外的元素,返回的是列表 scala> nums.init res13: List[Int] = List(1, 2, 3) //取出列表最后一个元素 scala>nums.last res14: Int = 4 //列表元素倒置 scala> nums.reverse res15: List[Int] = List(4, 3, 2, 1) //一些好玩的方法调用 scala> nums.reverse.reverse == nums //丢弃前面n个元素 scala>nums drop 3 res16: List[Int] = List(4) //获取前面n个元素 scala>nums take 1 res17: List[Int] = List[1] //将列表进行分割 scala> nums.splitAt(2) res18: (List[Int], List[Int]) = (List(1, 2),List(3, 4)) //前一个操作与下列语句等同 scala> (nums.take(2),nums.drop(2)) res19: (List[Int], List[Int]) = (List(1, 2),List(3, 4)) //Zip操作 scala> val nums=List(1,2,3,4) nums: List[Int] = List(1, 2, 3, 4) scala> val chars=List('1','2','3','4') chars: List[Char] = List(1, 2, 3, 4) //返回的是List类型的元组(Tuple),返回的元素个数与最小的List集合的元素个数一样 scala> nums zip chars res20: List[(Int, Char)] = List((1,1), (2,2), (3,3), (4,4)) //List toString方法 scala> nums.toString res21: String = List(1, 2, 3, 4) //List mkString方法 scala> nums.mkString res22: String = 1234 //转换成数组 scala> nums.toArray res23: Array[Int] = Array(1, 2, 3, 4) |
(5)List伴生对象方法
|
//apply方法 scala> List.apply(1, 2, 3) res24: List[Int] = List(1, 2, 3) //range方法,构建某一值范围内的List scala> List.range(2, 6) res25: List[Int] = List(2, 3, 4, 5) scala> List.range(2, 6,2) res26: List[Int] = List(2, 4) //步长为-1 scala> List.range(2, 6,-1) res27: List[Int] = List() scala> List.range(6,2 ,-1) res28: List[Int] = List(6, 5, 4, 3) //构建相同元素的List scala> List.make(5, "hey") res29: List[String] = List(hey, hey, hey, hey, hey) //unzip方法 scala> List.unzip(res20) res30: (List[Int], List[Char]) = (List(1, 2, 3, 4),List(1, 2, 3, 4)) //list.flatten,将列表平滑成第一个无素 scala> val xss =List(List('a', 'b'), List('c'), List('d', 'e')) xss: List[List[Char]] = List(List(a, b), List(c), List(d, e)) scala> xss.flatten res31: List[Char] = List(a, b, c, d, e) //列表连接 scala> List.concat(List('a', 'b'), List('c')) res32: List[Char] = List(a, b, c) |
(6)::和:::操作符介绍
List中常用'::',发音为"cons"。Cons把一个新元素组合到已有元素的最前端,然后返回结果List。
|
scala> val twoThree = List(2, 3) scala> val oneTwoThree = 1 :: twoThree scala> oneTwoThree oneTwoThree: List[Int] = List(1, 2, 3) |
上面表达式"1::twoThree"中,::是右操作数,列表twoThree的方法。可能会有疑惑。表达式怎么是右边参数的方法,这是Scala语言的一个例外的情况:如果一个方法操作符标注,如a * b,那么方法被左操作数调用,就像a.* (b)--除非方法名以冒号结尾。这种情况下,方法被右操作数调用。
List有个方法叫":::",用于实现叠加两个列表。
|
scala> val one = List('A', 'B') val one = List('A', 'B') scala> val two = List('C', 'D') scala> one:::two res1: List[Char] = List(A, B, C, D) |
6、Set集合
集是不重复元素的结合。集不保留顺序,默认是以哈希集实现。
如果想要按照已排序的顺序来访问集中的元素,可以使用SortedSet(已排序数据集),已排序的数据集是用红黑树实现的。
默认情况下,Scala 使用的是不可变集合,如果你想使用可变集合,需要引用 scala.collection.mutable.Set 包。
6.1、不可变集合的创建
|
val set1 =Set("1","1","2","3") println(set1.mkString(",")) |
6.2、可变集合的创建以及添加元素
如果我们引入的集合的包是可变的,那么我们创建的集合就是可变的
|
import scala.collection.mutable.Set val set2 = Set(1, 2, 3) set2.add(4) set2 += 5 //使用.这个方法添加元素,会返回一个新的集合 val set3 = set2.+(6) println(set2.mkString(",")) println(set3.mkString("\001")) |
6.3、可变集合删除元素
|
set3 -= 1 println(set3.mkString(".")) set3.remove(2) println(set3.mkString(".")) |
6.4、遍历Set集合元素
|
for(x <- set3){ println(x ) } |
注意:如果要创建有序的set,那么需要使用SortedSet。用法与Set类似
更多Set集合操作参见如下:
http://www.runoob.com/scala/scala-sets.html
6.5、Set更多常用操作介绍
|
序号 |
方法 |
描述 |
|
1 |
def +(elem: A): Set[A] |
为集合添加新元素,并创建一个新的集合,除非元素已存在 |
|
2 |
def -(elem: A): Set[A] |
移除集合中的元素,并创建一个新的集合 |
|
3 |
def contains(elem: A): Boolean |
如果元素在集合中存在,返回 true,否则返回 false。 |
|
4 |
def &(that: Set[A]): Set[A] |
返回两个集合的交集 |
|
5 |
def &~(that: Set[A]): Set[A] |
返回两个集合的差集 |
|
6 |
def ++(elems: A): Set[A] |
合并两个集合 |
|
7 |
def drop(n: Int): Set[A]] |
返回丢弃前n个元素新集合 |
|
8 |
def dropRight(n: Int): Set[A] |
返回丢弃最后n个元素新集合 |
|
9 |
def dropWhile(p: (A) => Boolean): Set[A] |
从左向右丢弃元素,直到条件p不成立 |
|
10 |
def max: A |
查找最大元素 |
|
11 |
def min: A |
查找最小元素 |
|
12 |
def take(n: Int): Set[A] |
返回前 n 个元素 |
7、集合元素与函数的映射
我们可以使用map方法,传入一个函数,然后将这个函数作用在集合当中的每一个元素上面
map:将集合中的每一个元素映射到某一个函数
|
val listFunc = List("name","age","zhangsan","lisi") println(listFunc.map(x => x +"hello")) println(listFunc.map(_.toUpperCase())) |
flatmap:flat即压扁,压平,扁平化,效果就是将集合中的每个元素的子元素映射到某个函数并返回新的集合
|
val listFunc2 = List("address","phonNo") println(listFunc2.flatMap( x => x +"WORLD")) |
8、队列Queue
队列Queue是一个先进先出的结构
8.1、创建队列
|
//创建可变的队列 val queue1 = new mutable.Queue[Int]() println(queue1) |
8.2、队列当中添加元素
|
//队列当中添加元素 queue1 += 1 //队列当中添加List queue1 ++=List(2,3,4) println(queue1) |
8.3、按照进入队列顺序,删除队列当中的元素(弹出队列)
|
val dequeue = queue1.dequeue() println(dequeue) println(queue1) |
8.4、向队列当中加入元素(入队列操作)
|
//塞入元素到队列 queue1.enqueue(5,6,7) println(queue1) |
8.5、获取第一个与最后一个元素
|
//获取第一个元素 println(queue1.head) //获取最后一个元素 println(queue1.last) |
9、集合当中的化简、折叠与扫描操作
9.1、折叠、化简 reduce操作
将二元函数引用集合当中的函数
|
val reduceList = List(1,2,3,4,5) //1-2-3-4-5 = -13 val reduceLeftList = reduceList.reduceLeft(_ - _) val reduceLeftList2 = reduceList.reduceLeft((x,y) => x-y) println(reduceLeftList) println(reduceLeftList2) //reduceRight操作 // 4-5 = -1 // 3- (-1) = 4 //2-4 = -2 //1 -(-2) = 3 val reduceRightList = reduceList.reduceRight(_ - _) println(reduceRightList) |
9.2、折叠、化简folder操作
fold函数将上一步返回的值作为函数的第一个参数继续传递参与运算,直到list中的所有元素被遍历。可以把reduceLeft看做简化版的foldLeft。相关函数:fold,foldLeft,foldRight,可以参考reduce的相关方法理解。
reduce的本质其实就是fold操作,只不过我们使用fold操作的时候,需要指定初始值fold操作
|
val foldList = List(1,9,2,8) val foldResult = foldList.fold(10)((x,y) => x+y) println(foldResult) foldLeft操作 //50-1-9-2-8 = 30 val foldLeftResult = foldList.foldLeft(50)((x,y) => x-y) println(foldLeftResult) |
10、拉链操作
对于多个List集合,我们可以使用Zip操作,将多个集合当中的值绑定到一起去
|
val zipList1 = List("name","age","sex") val zipList2 = List("zhangsan",28) val zip = zipList1.zip(zipList2) val toMap1 = zip.toMap println(zip) println(toMap1) |
11、迭代器
对于集合当中的元素,我们也可以使用迭代器来进行遍历
|
val listIterator = List(1,2,"zhangsan") val iterator = listIterator.iterator while(iterator.hasNext){ println(iterator.next()) } |
12、线程安全的集合
scala当中为了解决多线程并发的问题,提供对应的线程安全的集合
https://www.scala-lang.org/api/2.11.8/#package
SynchronizedBuffer
SynchronizedMap
SynchronizedPriorityQueue
SynchronizedQueue
SynchronizedSet
13、操作符
大致了解即可
- 如果想在变量名、类名等定义中使用语法关键字(保留字),可以配合反引号反引号:
var `var` num:Int = 2
2) 这种形式叫中置操作符,A操作符B等同于A.操作符(B)
3) 后置操作符,A操作符等同于A.操作符,如果操作符定义的时候不带()则调用时不能加括号
4) 前置操作符,+、-、!、~等操作符A等同于A.unary_操作符。
5) 赋值操作符,A操作符=B等同于A=A操作符B
scala集合与数据结构的更多相关文章
- Scala集合操作
大数据技术是数据的集合以及对数据集合的操作技术的统称,具体来说: 1.数据集合:会涉及数据的搜集.存储等,搜集会有很多技术,存储技术现在比较经典方案是使用Hadoop,不过也很多方案采用Kafka. ...
- Scala函数式编程(三) scala集合和函数
前情提要: scala函数式编程(二) scala基础语法介绍 scala函数式编程(二) scala基础语法介绍 前面已经稍微介绍了scala的常用语法以及面向对象的一些简要知识,这次是补充上一章的 ...
- Spark:scala集合转化为DS/DF
scala集合转化为DS/DF case class TestPerson(name: String, age: Long, salary: Double) val tom = TestPerson( ...
- Scala集合常用方法解析
Java 集合 : 数据的容器,可以在内部容纳数据 List : 有序,可重复的 Set : 无序,不可重复 Map : 无序,存储K-V键值对,key不可重复 scala 集合 : 可变集合( ...
- Java的数组,集合,数据结构,算法(一)
本人的愚见,博客是自己积累对外的输出,在学习初期或自己没有多少底料的情况下,与其总结写博客不如默默去搞自己的代码,但是学到集合这一块时,数组,集合,数据结构,算法这个概念搞的我比较混淆,所以不得已写这 ...
- Scala集合笔记
Scala的集合框架类比Java提供了更多的一些方便的api,使得使用scala编程时代码变得非常精简,尤其是在Spark中,很多功能都是由scala的这些api构成的,所以,了解这些方法的使用,将更 ...
- Scala集合(一)
Scala集合的主要特质 Iterator,用来访问集合中所有元素 val coll = ... // 某种Iterable val iter = col.iterator while(iter.ha ...
- Scala集合类型详解
Scala集合 Scala提供了一套很好的集合实现,提供了一些集合类型的抽象. Scala 集合分为可变的和不可变的集合. 可变集合可以在适当的地方被更新或扩展.这意味着你可以修改,添加,移除一个集合 ...
- 再谈Scala集合
集合!集合!一个现代语言平台上的程序员每天代码里用的最多的大概就是该语言上的集合类了,Scala的集合丰富而强大,至今无出其右者,所以这次再回过头再梳理一下. 本文原文出处: 还是先上张图吧,这是我 ...
随机推荐
- JDK1.7新特性(3):java语言动态性之脚本语言API
简要描述:其实在jdk1.6中就引入了支持脚本语言的API.这使得java能够很轻松的调用其他脚本语言.具体API的使用参考下面的代码: package com.rampage.jdk7.chapte ...
- 玩转树莓派《二》——用python实现动画与多媒体
环境:树莓派,系统raspbian,系统自带两个版本的python以及pygame. 1.画板 程序如下: !/home/pi/game_1.py import pygame width = 640 ...
- 理解Flexbox:你需要知道的一切
这篇文章介绍了Flexbox模块所有基本概念,而且是介绍Flexbox模块的很好的一篇文章,所以这篇文章非常的长,你要有所准备. 学习Flexbox的曲线 @Philip Roberts在Twitte ...
- 工作中遇到的一道SQL应用题
登录日志表 CREATE TABLE [dbo].[LoginLog]([Seq] [int] NOT NULL IDENTITY(1, 1), --Seq[UserId] [varchar] (2 ...
- 读取excel的方法(可用于批量导入)
FileStream stream = File.Open(filePath, FileMode.Open, FileAccess.Read); //1. Reading from a binary ...
- <深入理解JavaScript>学习笔记(4)_立即调用的函数表达式
前言 大家学JavaScript的时候,经常遇到自执行匿名函数的代码,今天我们主要就来想想说一下自执行.(小菜理解:的确看到好多,之前都不知道这是自执行匿名函数) 在详细了解这个之前,我们来谈了解一下 ...
- javascript之url转义escape()、encodeURI()和decodeURI(),ifram父子传参参数有中文时出现乱码
ifram父子传参参数有中文时出现乱码,可先在父级页面用encodeURI转义,在到子页面用进行decodeURI()解码 我们可以知道:escape()除了 ASCII 字母.数字和特定的符号外,对 ...
- BZOJ1970 [Ahoi2005] 矿藏编码
Description 依次对每份进行编码,得S1,S2,S3,S4.该矿藏区的编码S为2S1S2S3S4. 例如上图中,矿藏区的编码为:2021010210001. 小联希望你能根据给定的编码统计出 ...
- svg矢量图标在html中的使用, (知识点:1.通过h5中的css实现点击变色,2.一个svg文件包含多个图标)
svg矢量文件体积小,不变形,比传统的png先进,比现在流行的icon-font灵活.然而在使用过程中还是遇到了很多坑.今天花了一天时间把经验整理出来,以供后来者借鉴.如果您从本文收益,请留言mark ...
- vue指令示例合集
vue所有指令练习合集.这是个html文件,用chrome打开可查看结果. <!DOCTYPE html> <html lang="en" xmlns:v-on= ...