彻底解密 Spark 的 HashShuffle
本课主题
- Shuffle 是分布式系统的天敌
- Spark HashShuffle介绍
- Spark Consolidated HashShuffle介绍
- Shuffle 是如何成为 Spark 性能杀手
- Shuffle 性能调优思考
- Spark HashShuffle 源码鉴赏
引言
Spark HashShuffle 是它以前的版本,现在1.6x 版本默应是 Sort-Based Shuffle,那为什么要讲 HashShuffle 呢,因为有分布式就一定会有 Shuffle,而且 HashShuffle 是 Spark以前的版本,亦即是 Sort-Based Shuffle 的前身,因为有 HashShuffle 的不足,才会有后续的 Sorted-Based Shuffle,以及现在的 Tungsten-Sort Shuffle,所以我们有必要去了解它。
人们对Spark的印象往往是基于内存进行计算,但实际上来讲,Spark可以基于内存、也可以基于磁盘或者是第三方的储存空间进行计算,背后有两层含意,第一、Spark框架的架构设计和设计模式上是倾向于在内存中计算数据的,第二、这也表达了人们对数据处理的一种美好的愿望,就是希望计算数据的时候,数据就在内存中。
为什么再一次强调 Shuffle 是 Spark 的性能杀手啦,那不就是说,Spark中的 “Shuffle“ 和 “Spark完全是基于内存计算“ 的愿景是相违背的!!!希望这篇文章能为读者带出以下的启发:
- 了解为什么 Shuffle 是分布式系统的天敌
- 了解 Spark HashShuffle的原理和机制
- 了解优化后 Spark Consolidated HashShuffle的原理和机制
- 了解Shuffle 是如何成为 Spark 性能杀手
- 了解可以从那几方面思考 Spark Shuffle 的性能调优
- 了解 Spark HashShuffle 在读、写磁盘这个过程的源码鉴赏
Shuffle 是分布式系统的天敌
Spark 运行分成两部份,第一部份是 Driver Program,里面的核心是 SparkContext,它驱动着一个程序的开始,负责指挥,另外一部份是 Worker 节点上的 Task,它是实际运行任务的,当程序运行时,不间断地由 Driver 与所在的进程进行交互,交互什么,有几点,第一、是让你去干什么,第二、是具体告诉 Task 数据在那里,例如说有三个 Stage,第二个 Task 要拿数据,它就会向 Driver 要数据,所以在整个工作的过程中,Executor 中的 Task 会不断地与 Driver 进行沟通,这是一个网络传输的过程。
[下图是 Spark 官方网站上的经典Spark架框图]

在这个过程中一方面是 Driver 跟 Executor 进行网络传输,另一方面是Task要从 Driver 抓取其他上游的 Task 的数据结果,所以有这个过程中就不断的产生网络结果。其中,下一个 Stage 向上一个 Stage 要数据这个过程,我们就称之为 Shuffle。
思考点:上一个 Stage 为什么要向下一个 Stage 发数据?假设现在有一个程序,里面有五个 Stage,我把它看成为一个很大的 Stage,在分布式系统中,数据分布在不同的节点上,每一个节点计算一部份数据,如果不对各个节点上独立的部份进行汇聚的话,我们是计算不到最终的结果。这就是因为我们需要利用分布式来发挥它本身并行计算的能力,而后续又需要计算各节点上最终的结果,所以需要把数据汇聚集中,这就会导致 Shuffle,这也是说为什么 Shuffle 是分布式不可避免的命运。
Spark 中的 HashShuffle介绍
原始的 HashShuffle 机制
基于 Mapper 和 Reducer 理解的基础上,当 Reducer 去抓取数据时,它的 Key 到底是怎么分配的,核心思考点是:作为上游数据是怎么去分配给下游数据的。在这张图中你可以看到有4个 Task 在2个 Executors 上面,它们是并行运行的,Hash 本身有一套 Hash算法,可以把数据的 Key 进行重新分类,每个 Task 对数据进行分类然后把它们不同类别的数据先写到本地磁盘,然后再经过网络传输 Shuffle,把数据传到下一个 Stage 进行汇聚。
下图有3个 Reducer,从 Task 开始那边各自把自己进行 Hash 计算,分类出3个不同的类别,每个 Task 都分成3种类别的数据,刚刚提过因为分布式的关系,我们想把不同的数据汇聚然后计算出最终的结果,所以下游的 Reducer 会在每个 Task 中把属于自己类别的数据收集过来,汇聚成一个同类别的大集合,抓过来的时候会首先放在内存中,但内存可能放不下,也有可能放在本地 (这也是一个调优点。可以参考上一章讲过的一些调优参数),每1个 Task 输出3份本地文件,这里有4个 Mapper Tasks,所以总共输出了4个 Tasks x 3个分类文件 = 12个本地小文件。
[下图是 Spark 最原始的 Hash-Based Shuffle 概念图]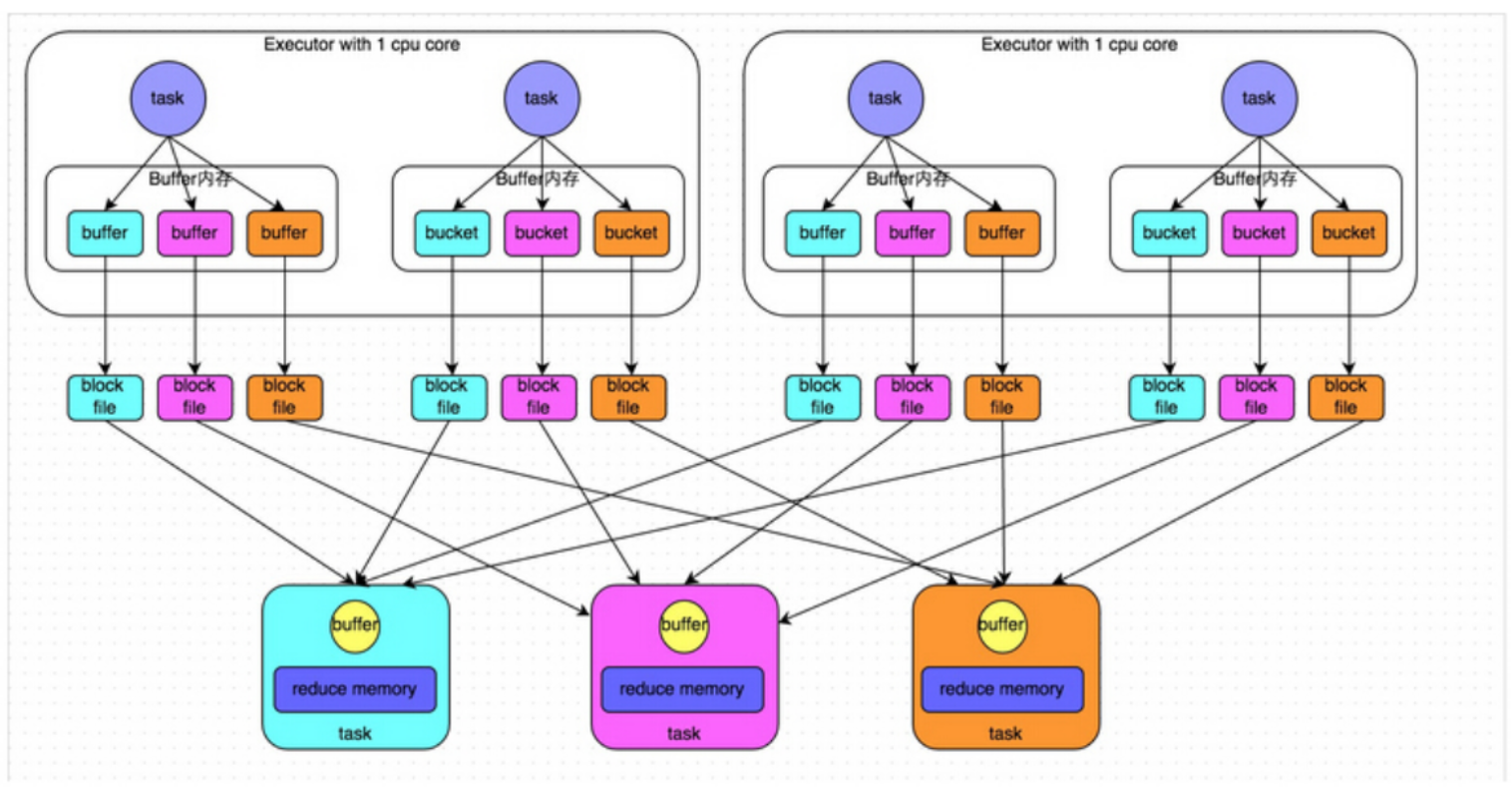
HashShuffle 也有它的弱点:
- Shuffle前在磁盘上会产生海量的小文件,此时会产生大量耗时低效的 IO 操作 (因為产生过多的小文件)
- 内存不够用,由于内存中需要保存海量文件操作句柄和临时信息,如果数据处理的规模比较庞大的话,内存不可承受,会出现 OOM 等问题。
优化后的 HashShuffle 机制
在刚才 HashShuffle 的基础上思考该如何进行优化,这是优化后的实现:
[下图是 Spark Consolidated Hash-Based Shuffle 概念图]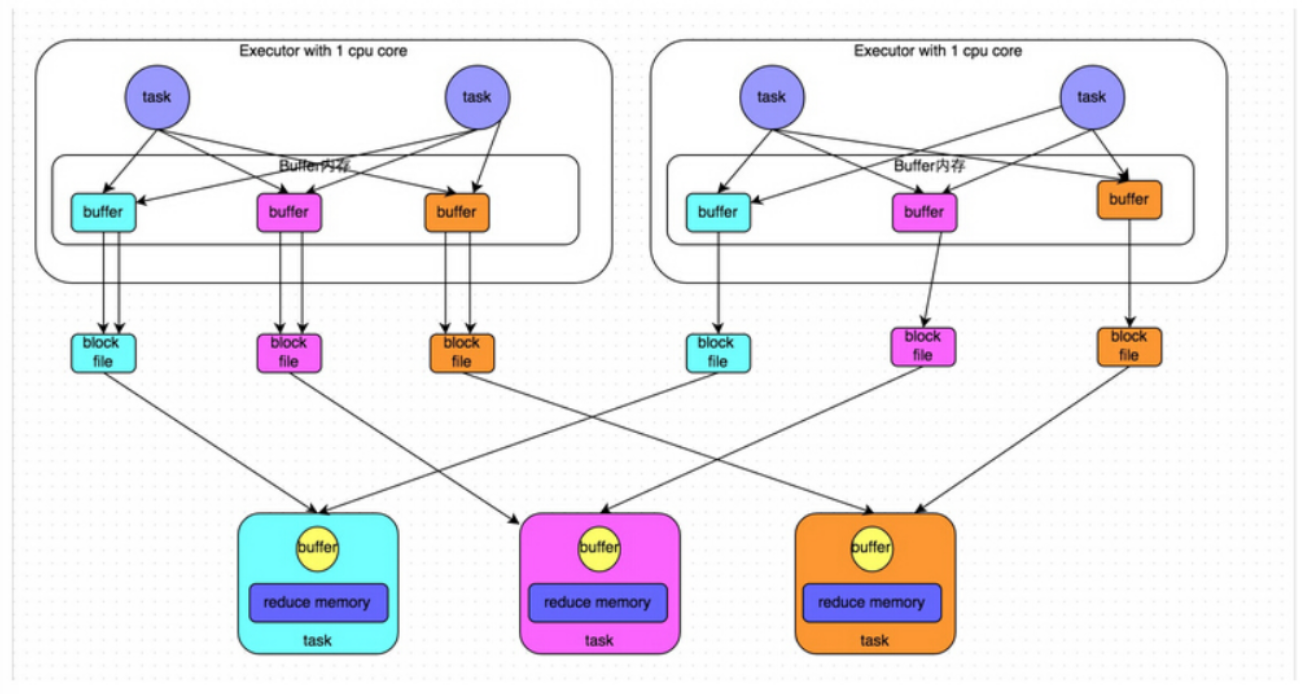
这里还是有4个Tasks,数据类别还是分成3种类型,因为Hash算法会根据你的 Key 进行分类,在同一个进程中,无论是有多少过Task,都会把同样的Key放在同一个Buffer里,然后把Buffer中的数据写入以Core数量为单位的本地文件中,(一个Core只有一种类型的Key的数据),每1个Task所在的进程中,分别写入共同进程中的3份本地文件,这里有4个Mapper Tasks,所以总共输出是 2个Cores x 3个分类文件 = 6个本地小文件。Consoldiated Hash-Shuffle的优化有一个很大的好处就是假设现在有200个Mapper Tasks在同一个进程中,也只会产生3个本地小文件; 如果用原始的 Hash-Based Shuffle 的话,200个Mapper Tasks 会各自产生3个本地小文件,在一个进程已经产生了600个本地小文件。3个对比600已经是一个很大的差异了。
这个优化后的 HashShuffle 叫 ConsolidatedShuffle,在实际生产环境下可以调以下参数:
|
1
|
spark.shuffle.consolidateFiles=true |
Consolidated HashShuffle 也有它的弱点:
- 如果 Reducer 端的并行任务或者是数据分片过多的话则 Core * Reducer Task 依旧过大,也会产生很多小文件。
Shuffle是如何成为Spark性能杀手及调优点思考
Shuffle 不可以避免是因为在分布式系统中的基本点就是把一个很大的的任务/作业分成一百份或者是一千份,这一百份和一千份文件在不同的机器上独自完成各自不同的部份,我们是针对整个作业要结果,所以在后面会进行汇聚,这个汇聚的过程的前一阶段到后一阶段以至网络传输的过程就叫 Shuffle。在 Spark 中为了完成 Shuffle 的过程会把真正的一个作业划分为不同的 Stage,这个Stage 的划分是跟据依赖关系去决定的,Shuffle 是整个 Spark 中最消耗性能的一个地方。试试想想如果没有 Shuffle 的话,Spark可以完成一个纯内存式的操作。
|
1
|
reduceByKey,它会把每个 Key 对应的 Value 聚合成一个 value 然后生成新的 RDD |
Shuffle 是如何破坏了纯内存操作呢,因为在不同节点上我们要进行数据传输,数据在通过网络发送之前,要先存储在内存中,内存达到一定的程度,它会写到本地磁盘,(在以前 Spark 的版本它没有Buffer 的限制,会不断地写入 Buffer 然后等内存满了就写入本地,现在的版本对 Buffer 多少设定了限制,以防止出现 OOM,减少了 IO)
Mapper 端会写入内存 Buffer,这个便关乎到 GC 的问题,然后 Mapper端的 Block 要写入本地,大量的磁盘与IO的操作和磁盘与网络IO的操作,这就构成了分布式的性能杀手。
如果要对最终计算结果进行排序的话,一般会都会进行 sortByKey,如果以最终结果来思考的话,你可以认为是产生了一个很大很大的 partition,你可以用 reduceByKey 的时候指定它的并行度,例如你把 reduceByKey 的并行度变成为1,新 RDD 的数据切片就变成1,排序一般都会在很多节点上,如果你把很多节点变成一个节点然后进行排序,有时候会取得更好的效果,因为数据就在一个节点上,技术层面来讲就只需要在一个进程里进行排序。
|
1
2
|
可以在调用 reduceByKey()接著调用 mapPartition( );也可以用 repartitionAndSortWithPartitions( ); |
还有一个很危险的地方就是数据倾斜,在我们谈的 Shuffle 机制中,不断强调不同机器从Mapper端抓取数据并计算结果,但有没有意会到数据可能会分布不均衡,什么时候会导致数据倾斜,答案就是 Shuffle 时会导政数据分布不均衡,也就是数据倾斜的问题。数据倾斜的问题会引申很多其他问题,比如,网络带宽、各重硬件故障、内存过度消耗、文件掉失。因为 Shuffle 的过程中会产生大量的磁盘 IO、网络 IO、以及压缩、解压缩、序列化和反序列化等等。
Shuffle 性能调优思考
Shuffle可能面临的问题,运行 Task 的时候才会产生 Shuffle (Shuffle 已经融化在 Spark 的算子中)
- 几千台或者是上万台的机器进行汇聚计算,数据量会非常大,网络传输会很大
- 数据如何分类其实就是 partition,即如何 Partition、Hash 、Sort 、计算
- 负载均衡 (数据倾斜)
- 网络传输效率,需要压缩或解压缩之间做出权衡,序列化 和 反序列化也是要考虑的问题
具体的 Task 进行计算的时候尽一切最大可能使得数据具备 Process Locality 的特性,退而求其次是增加数据分片,减少每个 Task 处理的数据量,基于Shuffle 和数据倾斜所导致的一系列问题,可以延伸出很多不同的调优点,比如说:
- Mapper端的 Buffer 应该设置为多大呢?
- Reducer端的 Buffer 应该设置为多大呢?如果 Reducer 太少的话,这会限制了抓取多少数据
- 在数据传输的过程中是否有压缩以及该用什么方式去压缩,默应是用 snappy 的压缩方式。
- 网络传输失败重试的次数,每次重试之间间隔多少时间。
Spark HashShuffle 源码鉴赏
我们说 Shuffle 的过程是Mapper和Reducer以及网络传输构成的,Mapper 这一端会把自己的数据写入本地磁盘,Reducer 这一端会通过网络把数据抓取过来。Mapper 会先把数据缓存在内存中,在默应情况下缓存空间是 32K,数据从内存到本地磁盘的一个过程就是写数据的一个过程。
这里有两个 Stage,上一个 Stage 叫 ShuffleMapTask,下面的一个 Stage 可能是 ShuffleMapTask,也有可能是 ResultsTask,取决于它这个任务是不是最后一个Stage所产生的。ShuffleMapTask会把我们处理的RDD的数据分成苦干个 Bucket,即一个又一个的 Buffer。一个Task怎么去切分具体要看你的 partitioner,ShuffleMapTask肯定是属于具体的 Stage。
HashShuffle 写数据的过程
- 在一个 Task 中,核心的代码是 runTask,你可以看到里面创建了一个 ShuffleWriter,它是负责把缓存中的数据写入本地磁盘的,但 ShuffleWriter 写入入本地磁盘时,还有一个非常重要的工作,就是要先跟Spark 的Driver 通信,说我把数据写到了什么地方,这样下一个Stage找上一个Stage的数据的时候,它是找 Driver(blockManagerMaster)去获取数据信息的,Driver(blockManagerMaster) 会告诉下一个Stage中的Task写入的数据在那里。
[下图是 ShuffleMapTask.scala 中的 runTask 方法]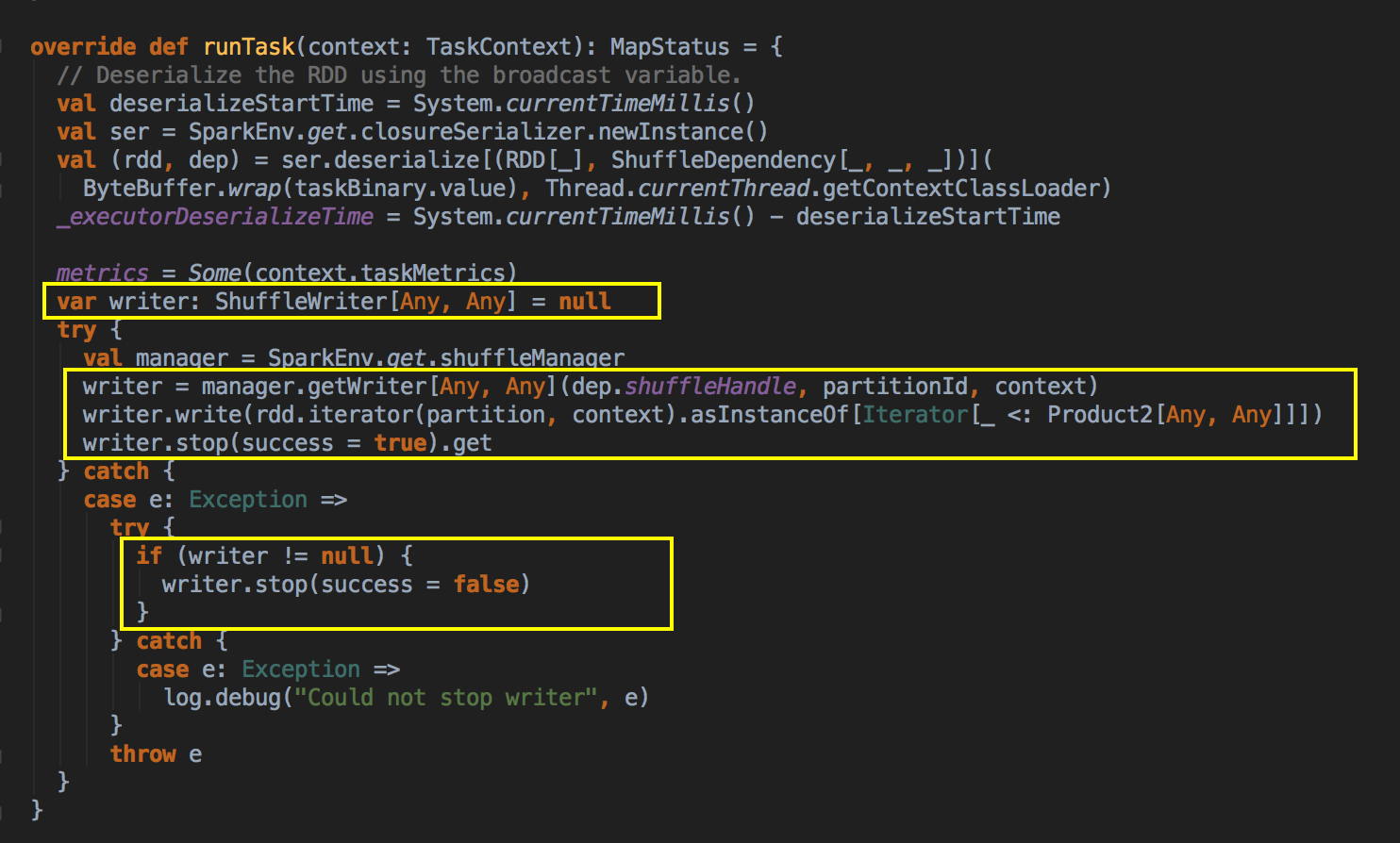
- 然后创建了一个 ShuffleManager,这是从 SparkEnv 中获得到的 ShuffleManager,SparkEnv是运行时的环境,所以在写代码的时候可以配置它。
[下图是 SparkContext.scala 中的 shuffleManager 变量]
- 再往下看ShuffleManager调用了getWriter 方法,在这里我们主要的是看 HashShuffle 的方式,所以看看它具体子类该怎么实现。
[下图是 ShuffleManager.scala 中的 ShuffleManager 类]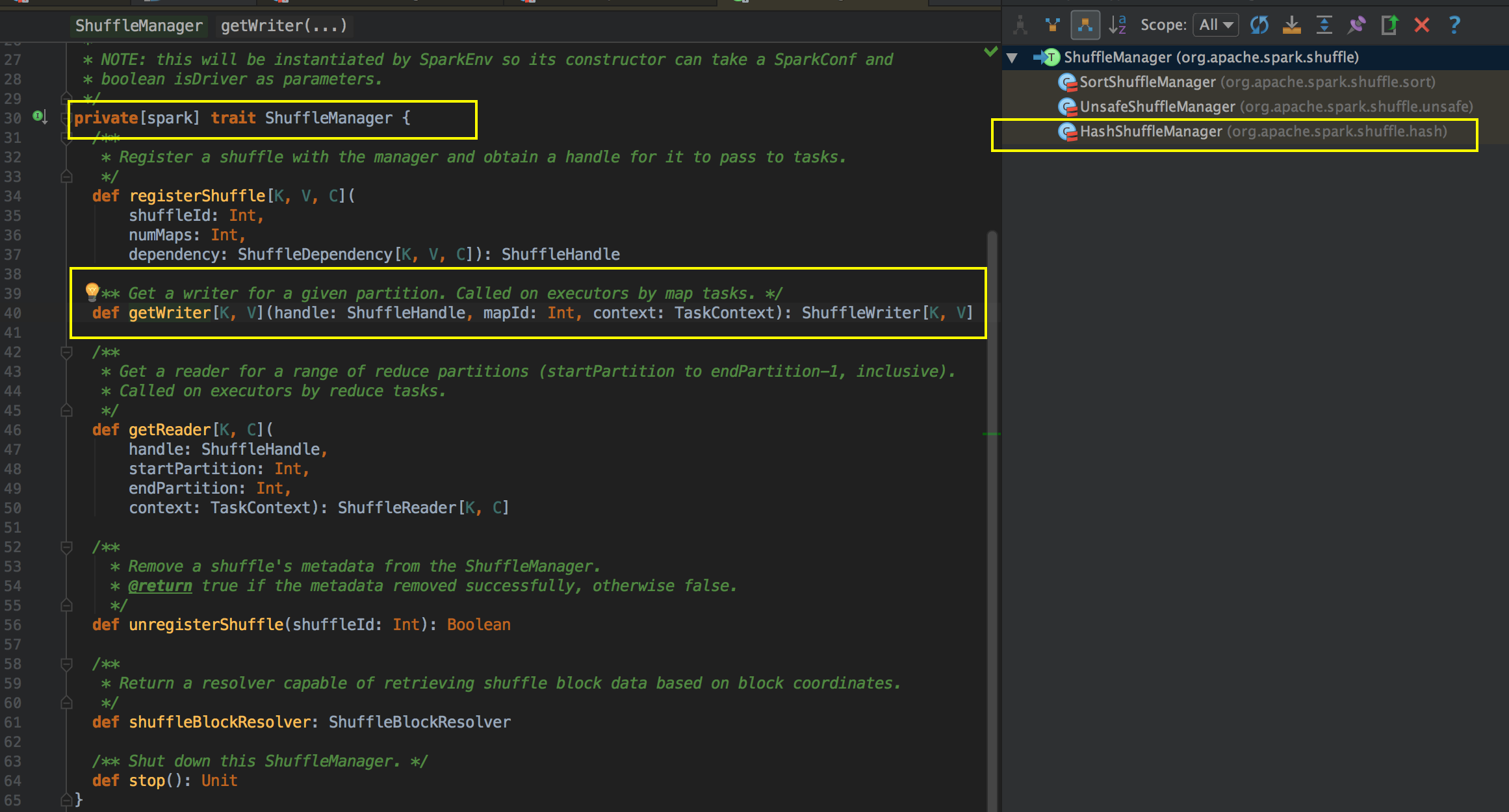
[下图是 HashShuffleManager.scala 中的 getWriter 方法]
- 从getWriter方式创建了 HashShuffleWriter 的实例对象,所以如果需要看它具体的怎么写数据的话,必需要看 HashShuffleWriter 类,然后它也必需有一个 write 的方法,首先它会判断一下是否有在 Mapper 端进行 aggregrate 的操作,也就是说是否进行的 Mapper 和 Reducer 这种计算模型的 LocalReduce,如果有的话,就基于records 进行聚合,它就会循环遍历Buffer里面的数据。在本地的聚合显现带来的好处是减少的磁盘IO的数据、以及操作磁盘IO的次数、以及网络传输的数据量、以及这个 Reduce Task 抓取 Mapper Task 数据的次数,这个意义肯定是非常重大的。
[下图是 HashShuffleWriter.scala 中的 write 方法]
- ShuffleWriterGroup,它会把相应的 Key 合并在同一个文件中,然后它会判断一下是否需要进行一个合并的过程,它构建了一个ShuffleWriterGroup的实体对象,同时呢,它会判断是否启动压缩机制,如果启动了压缩机制,会有一个fileGroup(bucketId),否则的话就getFile(bucketId)。
[下图是 ShuffleWriterGroup.scala 中的 forMapTask 方法]
[下图是 ShuffleWriterGroup.scala 中的 forMapTask 方法内部具体的实现]
- 最后无论它采用那种情况,最终也会调用 blockManager.getDiskWriter( )来完成写入数据到本地磁盘这个动作
[下图是 BlockManager.scala 中的 getDiskWriter 方法]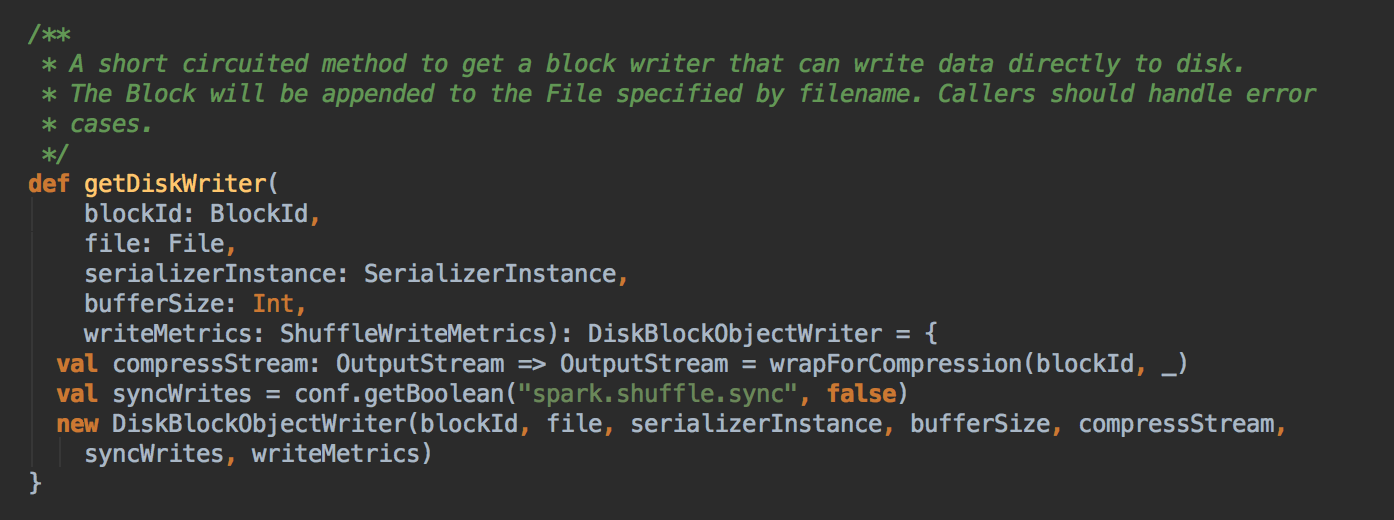
- 经过第4步后再回来看看shuffle,第一个参数是 shuffleId,第二个是 mapId,第三个是输出的 Split 个数,第4个是序列化器,第五个是metric 来统计它的一些基本信息
[下图是 HashShuffleWriter.scala 中的 shuffle 参数]
- 这里的writer是表明具体要写到什么地方,bucketId 是通过传入key到partition中的方式,下面调用 write 时有两个参数,elem._1 和 elem._2,所以elem._1是key和elem._2是具体内容本身。当分好bucketId就开始写数据。
[下图是 HashShuffleWriter.scala 中的 runTask 方法内部具体的实现]
Spark 的并行度是继承的,如果上游有4个并行任务的话,下游也会有4个
[下图是 Partitioner.scala 中的 HashPartitioner 类以及它的方法实现]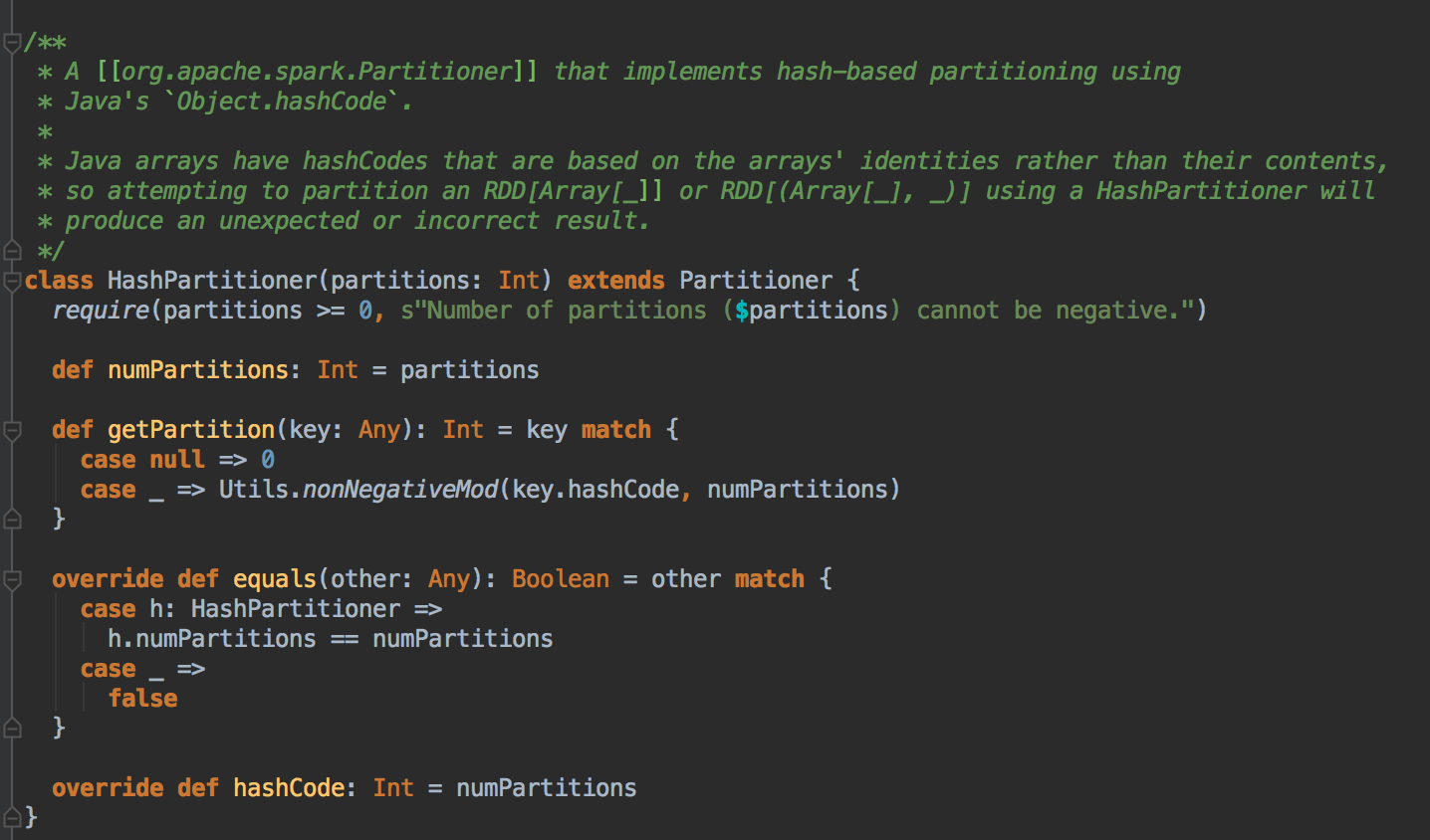
[下图是 Utils.scala 中的 nonNegativeMod 方法]
HashShuffle 读数据的过程
- 在 Reader 中重点是看它的 Read 方法,首先会创建一个 ShuffleBlockFetcherIterator,这里有一个很重要的调优的参数,也就是说一次能最大的抓取多少数据过来,在 Spark1.5.2 默应情况下是 48M,如果你内存足够大以及把内存空间分配足够的情况下,因为Shuffle会占用百分比,可以试试调大这个参数,调大这个参数的好处是减少抓取次数,因为网络IO的开销来建立新的连接其实很耗时的;往下看它再次进行一下判断看看Mapper端的Aggregrator 是否已经定义了。
[下图是 HashShuffleReader.scala 中的 read 方法]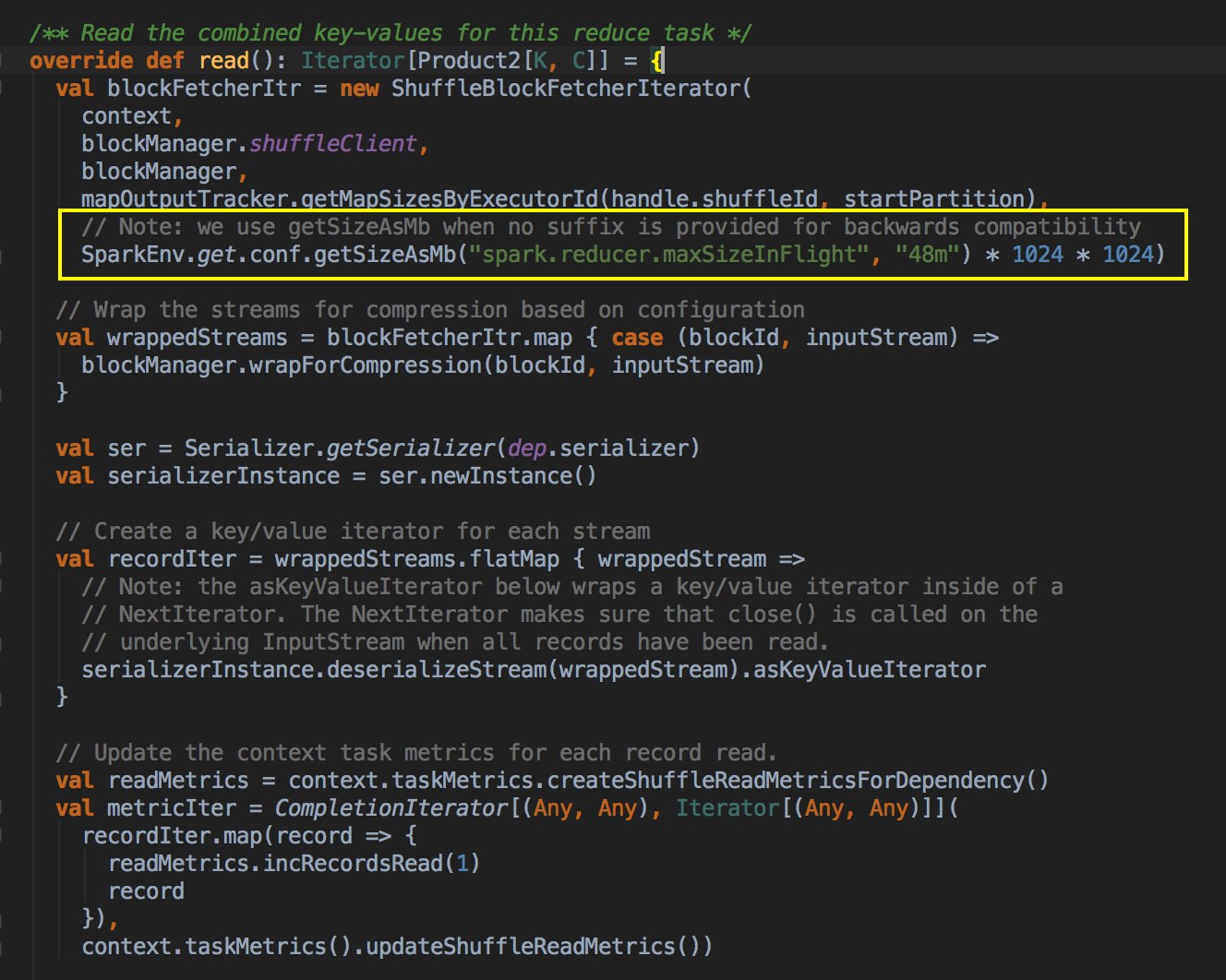
[下图是 HashShuffleReader.scala 中的 read 方法的内部实现]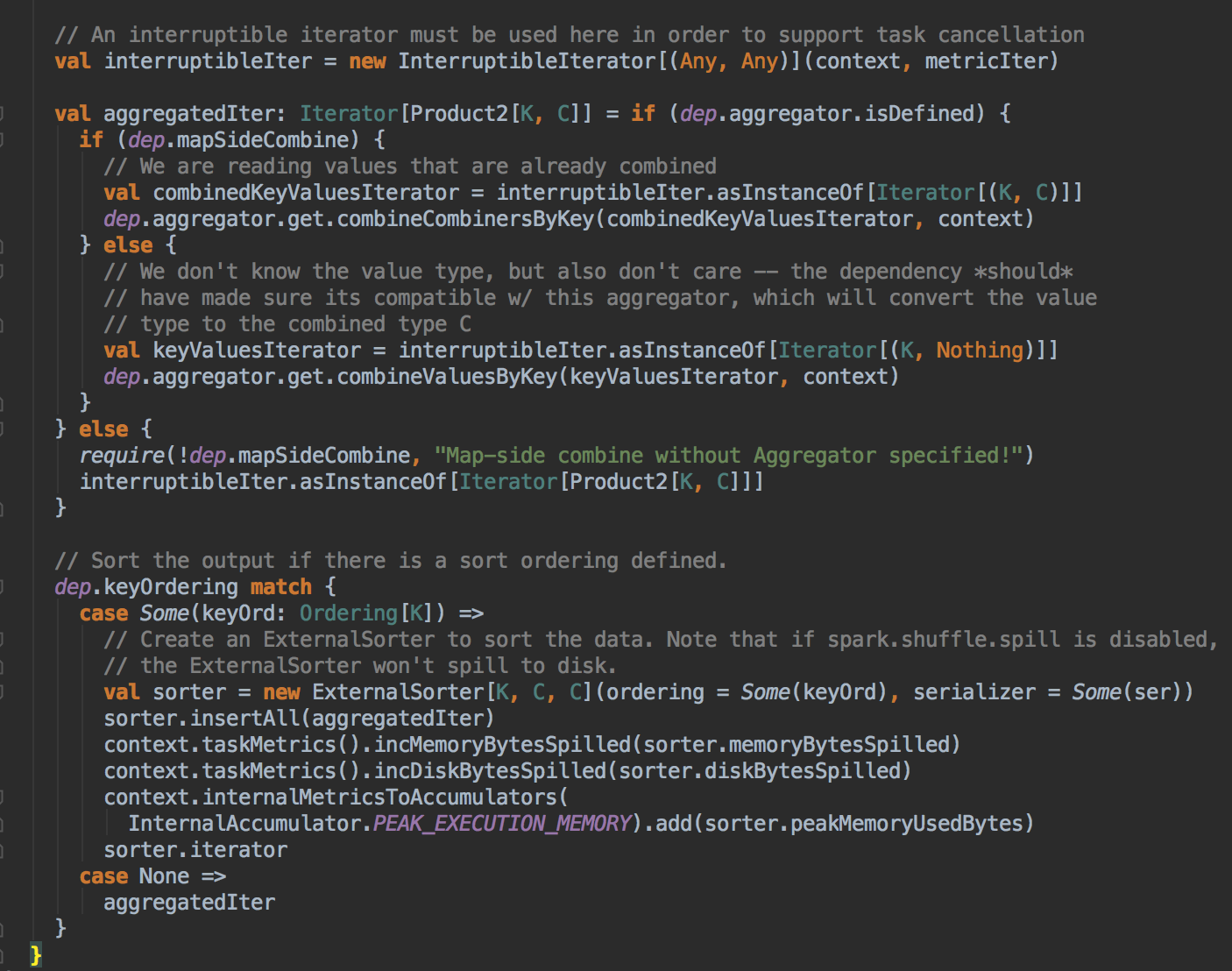
- 在Shuffle写数据的过程中,一开始会创建 ShuffleBlockFetecherIterator 对象实例,然后调用它的 initialize( )方法
[下图是 ShuffleBlockFetecherIterator.scala 中的 ShuffleBlockFetecherIterator 类]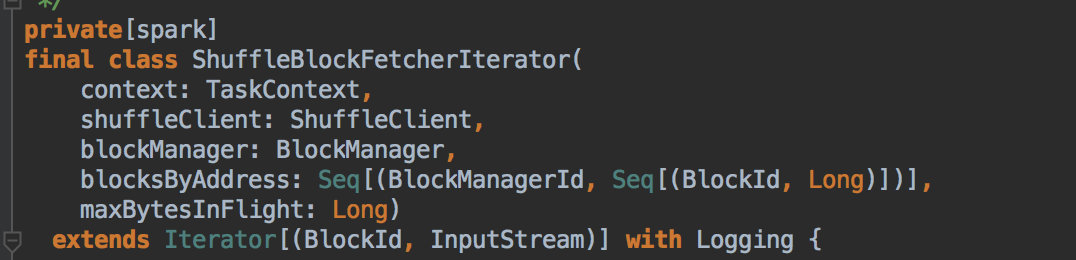
[下图是 ShuffleBlockFetecherIterator.scala 中的 localBlocks 和 remoteBlocks 变量]
[下图是 ShuffleBlockFetecherIterator.scala 中的 initialize 方法]
在 initialize( )方法转过来会调用 sendRequest( )方法,抓到数据后这里有一个 BlockFetchingListener,它会对数据进行处理,
[下图是 ShuffleBlockFetecherIterator.scala 中的 sendRequest 方法]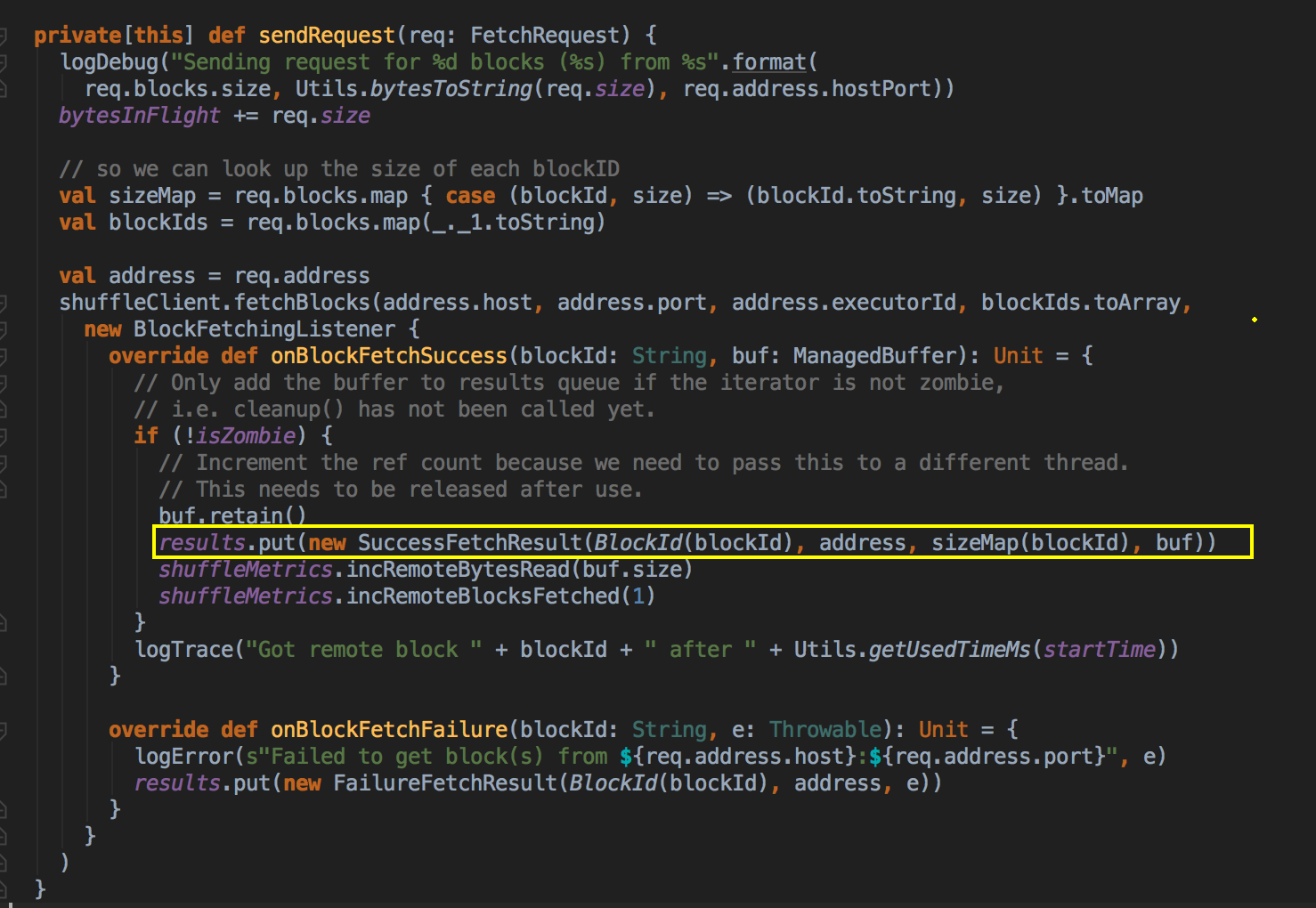
- 说明一点就是它底层有一套通信框架,我们基于这套通信框架进行数据的请求和传输
[下图是 NettyBlockTransferService.scala 中的 fetchBlocks 方法]
我们从 Reducer端借助了 HashShuffleReader 从远程抓取数据,抓取数据过来之后进行 Aggregrate 操作汇聚,汇聚具体是进行分组或者是什么样的算法是开发者自己决定的。reduceByKey和Hadoop中的mapper与reducer相比,有一个缺点,在 Hadoop 的世界,无论你的数据的什么样的类型你都可以自定义,Mapper和Reducer的业务逻辑可以完成不一样。
Reducer端如果内存不够写磁盘的代价是双倍的,在 Mapper端无论内存够不够它都需要先写磁盘,因为Reducer端在计算的时候需要又一次的把数据从磁盘上抓回来,所以实际生产环境下需要适当地把 Shuffle 内存调大一点。
总结
因为想利用分布式的计算能力,所以要把数据分散到不同节点上运行,上游阶段数据是并行运行的,下游阶段要进行汇聚,所以出现Shuffle,如果下游分成三类,上游也需要每个Task把数据分成三类,虽然有可能有一类是没有数据,这无所谓,只要在实际运行时按照这套规则就可以了,这就是最原始的 Shuffle 过程。
Hash-based Shuffle 默认Mapper 阶段会为Reducer 阶段的每一个Task单独创建一个文件来保存该Task中要使用的数据,但是在一些情况下(例如说数据量非常庞大的情况) 会造成大量文件的随机磁盘IO操作且会性成大量的Memory消耗(极易造成OOM)。
- 原始的 Hash-Shuffle 所产生的小文件: Mapper 端 Task 的个数 x Reduce 端 Task 的数量
- Consolidated Hash-Shuffle 所产生的小文件: CPU Cores 的个数 x Reduce 端 Task 的数量
Spark Shuffle 说到底都是离不开读文件、写文件、为了高效我们需要缓存,由于有很多不同的进程,就需要一个管理者。HashShuffle 适合的埸景是小数据的埸景,对小规模数据的处理效率会比排序后的 Shuffle 高。
参考资料
资料来源来至
彻底解密 Spark 的 HashShuffle的更多相关文章
- [Spark性能调优] 第二章:彻底解密Spark的HashShuffle
本課主題 Shuffle 是分布式系统的天敌 Spark HashShuffle介绍 Spark Consolidated HashShuffle介绍 Shuffle 是如何成为 Spark 性能杀手 ...
- spark性能调优(二) 彻底解密spark的Hash Shuffle
装载:http://www.cnblogs.com/jcchoiling/p/6431969.html 引言 Spark HashShuffle 是它以前的版本,现在1.6x 版本默应是 Sort-B ...
- Spark中hashshuffle与sortshuffle
在spark1.2以上的版本中,默认shuffle的方式已经变成了sortshuffle(在spark.shuffle.manager修改org.apache.spark.shuffle.sort.H ...
- Spark 学习笔记大纲
Spark 内核 第28课:Spark天堂之门解密 (点击进入博客)从 SparkContext 创建3大核心对象开始到注册给 Master 这个过程中的源码鉴赏 第29课:Master HA彻底解密 ...
- Spark性能调优
Spark性能优化指南——基础篇 https://tech.meituan.com/spark-tuning-basic.html Spark性能优化指南——高级篇 https://tech.meit ...
- Hadoop和Spark的Shuffer过程对比解析
Hadoop Shuffer Hadoop 的shuffer主要分为两个阶段:Map.Reduce. Map-Shuffer: 这个阶段发生在map阶段之后,数据写入内存之前,在数据写入内存的过程就已 ...
- [Spark内核] 第29课:Master HA彻底解密
本课主题 Master HA 解析 Master HA 解析源码分享 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... Master HA 解析 生产环境下一般 ...
- [Spark内核] 第30课:Master的注册机制和状态管理解密
本課主題 Master 接收 Worker, Driver, Application Master 处理 Driver 狀态变换 Master 处理 Executor 狀态变换 [引言部份:你希望读者 ...
- [Spark内核] 第34课:Stage划分和Task最佳位置算法源码彻底解密
本課主題 Job Stage 划分算法解密 Task 最佳位置算法實現解密 引言 作业调度的划分算法以及 Task 的最佳位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心,这 ...
随机推荐
- WPF UpdateSourceTrigger属性
TextBox中的变化并不是立即传递到源,而是在TextBox失去焦点后,源才更新.这种表现由绑定中的UpdateSourceTrigger属性来控制.它的默认值是Default,源会根据你绑定的属性 ...
- Win10正式版关机时自动更新怎么关闭
http://jingyan.baidu.com/article/64d05a02462d6fde55f73b97.html
- PTA (Advanced Level) 1016 Phone Bills
Phone Bills A long-distance telephone company charges its customers by the following rules: Making a ...
- NodeJS入门篇
在我印象里,“全栈工程师”这个词是NodeJS诞生后才逐渐火起来的,因为NodeJS赋予了JS服务器开发的能力.下面开始从一个小白的角度进军NodeJS... 前言:在学习NodeJS之前是需要安装的 ...
- 帧布局--FrameLayout
<?xml version="1.0" encoding="utf-8"?> <FrameLayout xmlns:android=" ...
- 【angular5项目积累总结】一些正则积累
/^[1-9][0-9]{0,4}$/ /^[1-9][0-9]{0,4}(,[1-9][0-9]{0,4})*$/ /^([a-zA-Z0-9_\-])+\@(([a-zA-Z0-9\-])+\.) ...
- 20个专业H5(HTML5)动画工具推荐
AnimateMate 可能是最好的 Sketch 动画插件.Sketch 目前被广泛应用于 HTML5 的原型界面设计,或者被应用于数据可视化的,动画部分则一般经由软件 Principle 等实现. ...
- Python 逐行分割大txt文件
# -*- coding: <encoding name> -*- import io LIMIT = 150000 file_count = 0 url_list = [] with i ...
- 基于asp.net mvc的近乎产品开发培训课程(第一讲)
演示产品源码下载地址:http://www.jinhusns.com/Products/Download
- NET Core 应用程序 IIS 运行报错 502.3-Gateway
转自:http://www.zmland.com/forum.php?mod=viewthread&tid=941 将 NET Core 应用程序部署在 IIS 环境,默认配置下,如果任务执行 ...