熵 互信息 Gini指数 和 不纯度
在学习决策树类的算法时,总是绕不开 信息熵、Gini指数和它们相关联的概念,概念不清楚,就很难理解决策树的构造过程,现在把这些概念捋一捋。
信息熵
信息熵,简称熵,用来衡量随机变量的不确定性大小,熵越大,说明随机变量的不确定性越大。计算公式如下:
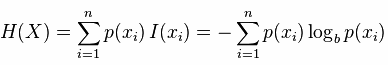
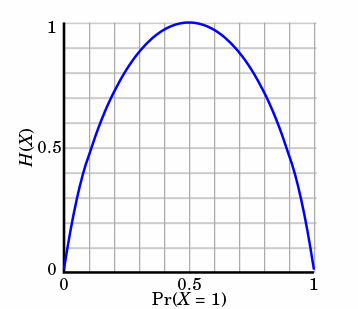
考虑二元分布的情况,当取2为对数底时,可以得到如下的函数曲线。可以看到,当p=0.5时,不确定性最大,熵的值是1,也最大,当p=0或1时,没有不确定性,熵的值最小,是0。
条件熵
我们在分析某个特征对随机变量的影响时,需要计算条件熵,即随机变量Y的信息熵相对特征X的条件期望,公式如下:

互信息
互信息,也叫信息增益,是熵和条件熵的差值,g(Y,X) = H(Y) - H(Y|X)。
信息增益的含义是,某一个特征会使得随机变量的不确定性下降多少。下降的越多,说明这个特征与标签的相关性越强,分类效果自然越好。在构造决策树时,常用的做法是选择信息增益更大的特征构造分支。
另外,在构造决策树时,信息增益有两种算法,一是差值(ID3),二是比值(C4.5),比值是差值与特征的信息熵的比例,公式如下所示:

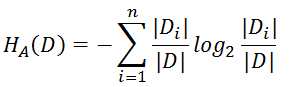
比值比差值能更准确的反应不确定性变化的程度,原因是,如果按差值选取节点,那些取值数量更多的特征总是会排在前面,在比值的计算公式中,分母可以度量特征的取值数量,相当于对各个特征做了归一化,所以不会出现,特征取值数量多,信息增益一定更大的情况。
Gini指数
Gini指数和熵类似,都是衡量随机变量不确定程度的,计算公式是:
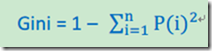
Gini指数有一个比较直观的解释:从样本中任意挑选两个,两个样本属于不同类别的概率就是Gini指数。从Gini指数的定义和解释就可以发现,它和熵和类似,不确定性越大,Gini指数和熵也越大。不同点在于Gini指数的最大值是0.5,不是1。把Gini指数公式和信息熵公式都变换成求和的形式,可以发现二者只相差一个乘积项,Gini指数是 1-p,信息熵是-log(p),就是这么一点点差别。
Gini指数的另一种说法是不纯度(impurity),Gini指数越大,不确定性越大,数据越混乱,不纯度越高。
笔者没研究过信息熵和Gini指数的发迹史,但可以猜测,Gini指数和信息熵很可能是不同领域的研究者分别建立的评价不确定性的指标,从含义上看,二者殊途同归。在实际使用时,往往用Gini指数来构造CART。
熵 互信息 Gini指数 和 不纯度的更多相关文章
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
- 用Excel建模进行决策树分析
决策树(Decision Tree)在机器学习中也是比较常见的一种算法,最早的决策树算法是ID3,改善后得到了C4.5算法,进一步改进后形成了我们现在使用的C5.0算法,综合性能大幅提高. 算法核心: ...
- 决策树--信息增益,信息增益比,Geni指数的理解
决策树 是表示基于特征对实例进行分类的树形结构 从给定的训练数据集中,依据特征选择的准则,递归的选择最优划分特征,并根据此特征将训练数据进行分割,使得各子数据集有一个最好的分类的过程. ...
- 笔记︱风控分类模型种类(决策、排序)比较与模型评估体系(ROC/gini/KS/lift)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本笔记源于CDA-DSC课程,由常国珍老师主讲 ...
- 风控分类模型种类(决策、排序)比较与模型评估体系(ROC/gini/KS/lift)
python信用评分卡建模(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_ca ...
- 决策树 ID3 C4.5 CART(未完)
1.决策树 :监督学习 决策树是一种依托决策而建立起来的一种树. 在机器学习中,决策树是一种预测模型,代表的是一种对象属性与对象值之间的一种映射关系,每一个节点代表某个对象,树中的每一个分叉路径代表某 ...
- AI工程师基础知识100题
100道AI基础面试题 1.协方差和相关性有什么区别? 解析: 相关性是协方差的标准化格式.协方差本身很难做比较.例如:如果我们计算工资($)和年龄(岁)的协方差,因为这两个变量有不同的度量,所以我们 ...
- 【十大经典数据挖掘算法】CART
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 前言 分类与回归树(Class ...
- CART分类与回归树与GBDT(Gradient Boost Decision Tree)
一.CART分类与回归树 资料转载: http://dataunion.org/5771.html Classification And Regression Tree(CART)是决策 ...
随机推荐
- CSS控制显示图片的一部分
使用情形:防止反复请求图片资源,我们经常采用一张图片多种效果或内容显示. 假设我有纸张竖直方向的一张图片,竖直y轴方向分别是字母:A,B,C.... 现在分别要显示A.B.C 等字母,我们的CSS可以 ...
- ajax回调函数中使用$(this)取不到对象的解决方法
如果在ajax的回调函数内使用$(this)的话,实践证明,是取不到任何对象的,需要的朋友可以参考下 $(".derek").each(function(){ $(this).cl ...
- DSSM(DEEP STRUCTURED SEMANTIC MODELS)
Huang, Po-Sen, et al. "Learning deep structured semantic models for web search using clickthrou ...
- 【转】 如何利用C#代码来进行操作AD
要用代码访问 Active Directory域服务,需引用System.DirectoryServices命名空间,该命名空间包含两个组件类,DirectoryEntry和 DirectorySea ...
- 建议 for 语句的循环控制变量的取值采用“半开半闭区间”写法
建议 for 语句的循环控制变量的取值采用“半开半闭区间”写法. #include <iostream> /* run this program using the console pau ...
- Session超时问题(AOP 过滤器)
public class TimeoutAttribute : ActionFilterAttribute { public override void OnActionExecuting(Actio ...
- vs2013配置opencv3.2.0
工具/原料 l VS2013 l OpenCV3.20http://jaist.dl.sourceforge.net/project/opencvlibrary/opencv-win/3.2.0/op ...
- Java 应用程序设计规范
1.能在程序中取的产生就从程序中取.不用客户输入(减少客户输入). 比如客户号 信息 等. 2.如果有参数输入尽可能减少参数输入的个数(4个->0个): 3.验证入参(尽可能的实现输入参数的正确 ...
- [Scikit-learn] Dynamic Bayesian Network - Kalman Filter
看上去不错的网站:http://iacs-courses.seas.harvard.edu/courses/am207/blog/lecture-18.html SciPy Cookbook:http ...
- try catch finally的执行顺序
1.将预见可能引发异常的代码包含在try语句块中. 2.如果发生了异常,则转入catch的执行.catch有几种写法: catch 这将捕获任何发生的异常. catch(Exception e) 这将 ...