A/B_test改变新旧网页 观察用户的引流效果
代码处:https://github.com/xubin97/Data-analysis_exp2
分析A/B测试结果
目录
简介
I - 概率
II - A/B 测试
简介
首先这个项目数据来自某公司的虚拟数据,主要是了解电子商务网站运行的 A/B 测试的结果。目标是通过这个 notebook 来帮助公司弄清楚他们是否应该使用新的页面,保留旧的页面,或者应该将测试时间延长,之后再做出决定。
步骤:
计算了对照组和实验组的指标观察差异;
为比例差异建立了抽样分布 模型;
用这个抽样分布模型来为 零假设分布 建立模型,也即创建了一个随机正态分布模型,模型以 0 为中心,大小和宽度与抽样分布的一样。
通过找出零假设分布中大于观察差异的那部分比值,从而计算出了 p 值;
用 p 值来确定观察差异是否有 统计显著性。
I - 概率
先导入库,然后开始任务。
In [1]:
import pandas as pd
import numpy as np
import random
import matplotlib.pyplot as plt
%matplotlib inline
random.seed(42)
- 现在,导入 ab_data.csv 数据,并将其存储在 df 中。
a. 导入数据集,并在这里查看前几行:
In [2]:
df=pd.read_csv('ab-data.csv')
df.head()
Out[2]:
user_id
timestamp
group
landing_page
converted
0
851104
2017-01-21 22:11:48.556739
control
old_page
0
1
804228
2017-01-12 08:01:45.159739
control
old_page
0
2
661590
2017-01-11 16:55:06.154213
treatment
new_page
0
3
853541
2017-01-08 18:28:03.143765
treatment
new_page
0
4
864975
2017-01-21 01:52:26.210827
control
old_page
1
b. 使用下面的单元格来查找数据集中的行数。
In [3]:
df.shape[0]
Out[3]:
294478
c. 数据集中独立用户的数量。
In [4]:
len(df['user_id'].unique())
Out[4]:
290584
d. 用户转化的比例。
In [5]:
df['converted'].mean()
Out[5]:
0.11965919355605512
e. new_page 与 treatment 不一致的次数。
In [6]:
df[((df['group'] == 'treatment') == (df['landing_page'] == 'old_page')) == True].shape[0]
Out[6]:
3893
f. 是否有任何行存在缺失值?
In [7]:
df.info()
Out[]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 294478 entries, 0 to 294477
Data columns (total 5 columns):
user_id 294478 non-null int64
timestamp 294478 non-null object
group 294478 non-null object
landing_page 294478 non-null object
converted 294478 non-null int64
dtypes: int64(2), object(3)
memory usage: 11.2+ MB
- 对于
treatment不与new_page一致的行或control不与old_page一致的行,我们不能确定该行是否真正接收到了新的或旧的页面。所以我们应该删除这些混乱的行。
a. 现在,创建了一个符合要求的新数据集。将新 dataframe 存储在 df2 中。
In [5]:
df_1=df[((df['group'] == 'treatment') == (df['landing_page'] == 'old_page'))==True].index
df2=df.drop(df_1)
In [6]:
df2[((df2['group'] == 'treatment') == (df2['landing_page'] == 'new_page')) == False].shape[0]
Out[6]:
0
In [6]:
df_2=df2[((df2['group'] == 'control') == (df2['landing_page'] == 'new_page')) == True].index
df2=df2.drop(df_2)
In [8]:
df2[((df2['group'] == 'control') == (df2['landing_page'] == 'new_page')) == True].shape[0] #df2经过检查,没有混乱的行
Out[8]:
0
- 查看 df2 是否还有其他方面的隐藏问题。
a. df2 中有多少唯一的 user_id?
In [11]:
len(df2['user_id'].unique())
Out[11]:
290584
b. df2 中有一个重复的 user_id 。它是什么?
In [7]:
a=df2.drop_duplicates(subset=['user_id'],keep='first') #构造去重且保留重复第一行的数据集a
b=df2.drop_duplicates(subset=['user_id'],keep=False) #构造去重把所有重复行都去掉的数据集b
no_unique=a.append(b).drop_duplicates(subset=['user_id'],keep=False) #a连接上b数据集,再去重其不保留,只剩下单独的之前的‘重复行’
no_unique['user_id']
Out[7]:
1899 773192
Name: user_id, dtype: int64
c. 这个重复的 user_id 的行信息是什么?
In [13]:
no_unique
Out[13]:
user_id
timestamp
group
landing_page
converted
1899
773192
2017-01-09 05:37:58.781806
treatment
new_page
0
d. 删除 一个 含有重复的 user_id 的行, 确保 dataframe 为 df2。
In [8]:
df2=df2.drop_duplicates(subset=['user_id'],keep='first')
- 在 df2 中查看各种转换率
a. 不管它们收到什么页面,单个用户的转化率是多少?
In [6]:
df2['converted'].mean()
Out[6]:
0.11959667567149027
b. 假定一个用户处于 control 组中,他的转化率是多少?
In [7]:
df2.query('group=="control"')['converted'].mean()
Out[7]:
0.1203863045004612
c. 假定一个用户处于 treatment 组中,他的转化率是多少?
In [8]:
df2.query('group=="treatment"')['converted'].mean()
Out[8]:
0.11880724790277405
d. 一个用户收到新页面的概率是多少?
In [9]:
df2.query('landing_page=="new_page"').count()[0]/df2.count()[0]
Out[9]:
0.5000636646764286
通过这些概率的分析发现:在数据集中新页面与旧页面占的比例相同,并且两组的转化率都接近0.12,并不能证明新页面能带来更多转化。
II - A/B 测试
A / B测试中最难的问题:一个页面被认为比另一页页面的效果好得多的时候你就要停止检验吗?还是需要在一定时间内持续发生?你需要将检验运行多长时间来决定哪个页面比另一个页面更好?
1. 现在,要考虑的是,需要根据提供的所有数据做出决定。如果想假定旧的页面效果更好,除非新的页面在类型I错误率为5%的情况下才能证明效果更好,那么,零假设和备择假设是什么? 注:旧页面与新页面的转化率 p_{old} 与 p_{new} 来陈述
H0:P_old - P_new >=0
H1: P_old - P_new < 0
2. 进行A/B测试注意要求:
1)假定在零假设中,不管是新页面还是旧页面, p_{new} and p_{old} 都具有等于 转化 成功率的“真”成功率,也就是说, p_{new} 与p_{old} 是相等的。此外,假设它们都等于ab_data.csv 中的 转化 率,新旧页面都是如此。
2)每个页面的样本大小要与 ab_data.csv 中的页面大小相同。
3)执行两次页面之间 转化 差异的抽样分布,计算零假设中10000次迭代计算的估计值。
a. 在零假设中,p_{new}的 convert rate(转化率) 是多少?
b. 在零假设中,pold的 convert rate(转化率) 是多少?
In [10]:
p_old=df2.query('group=="control"')['converted'].mean()
p_old
Out[10]:
0.1203863045004612
c. n_{new} 是多少?
In [11]:
n_new=df2.query('landing_page=="new_page"').count()[0]
n_new
Out[11]:
145310
d. n_{old}?是多少?
In [12]:
n_old=df2.query('landing_page=="old_page"').count()[0]
n_old
Out[12]:
145274
e. 在零假设中,使用 pnew转化率模拟 nnew交易,并将这些 nnew
1's 与 0's 存储在 new_page_converted 中。(提示:可以使用 numpy.random.choice。)
random.seed(42)
new_page_converted=np.random.choice([0,1],n_new,[1-p_new,p_new])
new_page_converted
Out[14]:
array([1, 0, 0, ..., 1, 1, 1])
f. 在零假设中,使用 pold转化率模拟 nold交易,并将这些 nold1's 与 0's 存储在 old_page_converted 中。
In [15]:
old_page_converted=np.random.choice([0,1],n_old,[1-p_old,p_old])
old_page_converted
Out[15]:
array([1, 1, 0, ..., 1, 1, 0])
g. 在 (e) 与 (f)中找到Pnew Pold 模拟值
In [16]:
new_page_converted.mean()-old_page_converted.mean()
Out[16]:
-0.0002203979065243944
h. 使用a. 到 g. 中的计算方法来模拟 10,000个 pnew-pold值,并将这 10,000 个值存储在 p_diffs 中
In [17]:
p_diffs=[]
for i in range(10000):
Pnew=np.random.choice([0,1],n_new,[1-p_new,p_new]).mean()
Pold=np.random.choice([0,1],n_old,[1-p_old,p_old]).mean()
p_diffs.append(Pnew-Pold)
i. 绘制一个 p_diffs 直方图。
In [18]:
plt.hist(p_diffs)
Out[18]:
(array([3.000e+00, 2.100e+01, 2.160e+02, 9.030e+02, 2.162e+03, 3.042e+03,
2.317e+03, 1.048e+03, 2.540e+02, 3.400e+01]),
array([-0.00799081, -0.006553 , -0.0051152 , -0.00367739, -0.00223958,
-0.00080178, 0.00063603, 0.00207384, 0.00351164, 0.00494945,
0.00638726]),
<a list of 10 Patch objects>)

j. 在p_diffs列表的数值中,有多大比例大于 ab_data.csv 中观察到的实际差值?
In [24]:
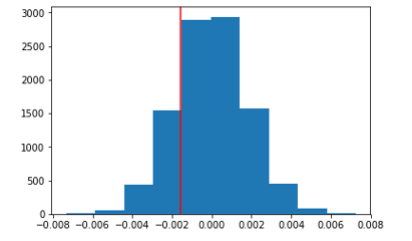
null_vals=np.random.normal(0,np.std(p_diffs),10000)
obs_diff1=df2.query('landing_page=="new_page"')['converted'].mean()-df2.query('landing_page=="old_page"')['converted'].mean()
plt.hist(null_vals)
plt.axvline(obs_diff1,color='red')
Out[24]:
<matplotlib.lines.Line2D at 0x296f09882b0>
In [25]:
p=(null_vals>obs_diff1).mean()
p
Out[25]:
0.8062
k.这个P值表示统计显著性,接近1,说明拒接零假设的风险很大,即接受零假设,新旧页面转化率没有区别。
l. 我们也可以使用一个内置程序 (built-in)来实现类似的结果。尽管使用内置程序可能更易于编写代码,但上面的内容是对正确思考统计显著性至关重要的思想的一个预排。填写下面的内容来计算每个页面的转化次数,以及每个页面的访问人数。使用 n_old 与 n_new 分别引证与旧页面和新页面关联的行数。
In [29]:
import statsmodels.api as sm
convert_old = df2.query('landing_page=="old_page"')['converted'].sum()
convert_new = df2.query('landing_page=="new_page"')['converted'].sum()
n_old = df2.query('landing_page=="old_page"').count()[0]
n_new = df2.query('landing_page=="new_page"').count()[0]
m. 现在使用 stats.proportions_ztest 来计算检验统计量与 p-值。
In [30]:
z_score, p_value = sm.stats.proportions_ztest([convert_old,convert_new],[n_old,n_new],alternative='smaller')
z_score, p_value
Out[30]:
(1.3109241984234394, 0.90505831275902449)
根据上题算出的 z-score 0.05,认为差异不显著,新旧页面的转化率没有区别。它们与 k. 中的结果一致.
结论:经过两遍的显著性差异检验
A/B_test改变新旧网页 观察用户的引流效果的更多相关文章
- 一种历史详细记录表,完整实现:CommonOperateLog 详细记录某用户、某时间、对某表、某主键、某字段的修改(新旧值
一种历史详细记录表,完整实现:CommonOperateLog 详细记录某用户.某时间.对某表.某主键.某字段的修改(新旧值). 特别适用于订单历史记录.重要财务记录.审批流记录 表设计: names ...
- 使用Flexbox:新旧语法混用实现最佳浏览器兼容
Flexbox非常的棒,肯定是未来布局的一种主流.在过去的几年这之中,语法改变了不少,这里有一篇“旧”和“新”新的语法区别教程(如果你对英文不太感兴趣,可以移步阅读中文版本).但是,如果我们把Flex ...
- 微信快速开发框架(八)-- V2.3--增加语音识别及网页获取用户信息,代码已更新至Github
不知不觉,版本以每周更新一次的脚步进行着,接下来应该是重构我的代码及框架的结构,有朋友反应代码有点乱,确实如此,当时写的时候只是按照订阅号来写的,后来才慢慢增加到支持API接口.目前还在开发第三方微信 ...
- Flex布局新旧混合写法详解(兼容微信)
原文链接:https://www.usblog.cc/blog/post/justzhl/Flex布局新旧混合写法详解(兼容微信) flex是个非常好用的属性,如果说有什么可以完全代替 float 和 ...
- Flex布局新旧混合写法详解
flex是个非常好用的属性,如果说有什么可以完全代替 float 和 position ,那么肯定是非它莫属了(虽然现在还有很多不支持 flex 的浏览器).然而国内很多浏览器对 Flex 的支持都不 ...
- Hadoop日记Day15---MapReduce新旧api的比较
我使用hadoop的是hadoop1.1.2,而很多公司也在使用hadoop0.2x版本,因此市面上的hadoop资料版本不一,为了扩充自己的知识面,MapReduce的新旧api进行了比较研究. h ...
- Android技巧小结之新旧版本Notification
最近开发用到了通知功能,但有几个地方老是提示deprecated,然后就找了篇文章学习了下新旧版本的不同. Notification即通知,用于在通知栏显示提示信息. 在较新的版本中(API leve ...
- [Q&A]VS 2012 MVC4专案与网站的差异?「ASP.NET组态」的Login账号出现在「新旧两组」会员数据库里面?
原文出處 http://www.dotblogs.com.tw/mis2000lab/archive/2013/08/30/mvc4_vs2012_login_member_db.aspx [Q&a ...
- MapReduce简述、工作流程及新旧API对照
什么是MapReduce? 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查而且数出有多少张是黑桃. MapReduce方法则是: 1. 给在座的全部玩家中分配这摞牌. 2. 让每一个玩家数自己手 ...
随机推荐
- Redis配置参数汇总
==配置文件全解=== ==基本配置daemonize no 是否以后台进程启动databases 16 创建database的数量(默认选中的是database 0) save 900 1 #刷新快 ...
- win server 2012 R2 你需要先安装 对应于 KB2919355 的更新
产生阻滞的问题: 你需要先安装 对应于 KB2919355 的更新 ,然后才可在 Windows 8.1 或 Windows Server 2012 R2 上安装此产品. 官方说法(这些 KB 必须按 ...
- C# Winform WPF DeskBand 窗体嵌入任务栏,在任务栏显示文字
最近写了个小程序,用于将固态硬盘的写入量等信息显示在任务栏,最开始使用Windows API也可以实现,但是当任务栏托盘增加的时候,会被遮盖,最终采用了DeskBand来实现,填了很多坑. 参考的Gi ...
- Sql语法高级应用之五:使用存储过程实现对明细多层次统计
前言 前面章节我们讲到了存储过程的基础用法,本章则将一个在项目中实际应用的场景. 在项目中经常会存在这样的需求,例如需要对明细列表进行按组.按级别.按人等进行统计,如果在附带列表的查询条件,又如何实现 ...
- infopath 2007 升级到2013 栏目字段重复生成问题
1. 把Expense Statement.xsn的xsn扩展名改成zip.然后解压后会看到有一个mnifest.xsf. 2. 在vs 2013 中打开它. 3. Search for the fi ...
- iOS 添加字体
1. 将字体(ttf 文件)导入项目. 2. 在项目plist 文件里的 Fonts provided by application 添加新导入的字体. 3. 代码中的调用 [aLabel setFo ...
- iOS开发网络篇—GET请求和POST请求的说明与比较
1.GET请求和POST请求简单说明 1.1 创建GET请求 // 1.设置请求路径 NSString *urlStr = [NSString stringWithFormat:@"http ...
- css如何去掉select原始样式
css代码: select { /*将默认的select选择框样式清除*/ appearance: none; -moz-appearance: none; -webkit-appearance: n ...
- HTTP请求报文支持的各种方法
常见的HTTP方法如下: 1.GET GET是最常用的方法.通常用于请求服务器发送某个资源. 2.HEAD HEAD与GET的行为类似,但服务器在响应中只返回首部,不会返回实体的部分.这就允许客户端在 ...
- Elastic Search 5.x Nest Multiple Queries C#
I'm using C# with those nuget packeges; <package id="Elasticsearch.Net" version="5 ...