OpenCL入门:(三:GPU内存结构和性能优化)
如果我们需要优化kernel程序,我们必须知道一些GPU的底层知识,本文简单介绍一下GPU内存相关和线程调度知识,并且用一个小示例演示如何简单根据内存结构优化。
一、GPU总线寻址和合并内存访问
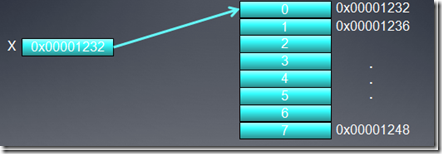
假设X指向一个32位整数数组的指针,数组首地址是0x00001232,那么一个线程需要访问第0个成员时是也许是如下访问的:
int tmp = X[0]假设内存总线宽度是256位,内存访问时必须和总线宽度对齐,所以内存只能访问0x00000020,0x00000040这种地址(0x20=256位),如果要访问0x00001232,那么内存必须同时获取0x00001220-0x0000123f的数据,一次获取了32字节的数据,但是我们有用的只有4字节,这就造成了28个字节的浪费。
事实上,GPU为了利用总线带宽,它会合并内存访问,尽量将多个线程读取内存合并到一起进行访问,例如我们有16个线程,每个线程访问4字节,总共需要访问0x00001232-0x00001272,如果不合并内存访问,那么他需要访问内存16次,每次浪费28字节空间;如果合并内存访问,它第一次访问0x00001220-0x0000123f,第二次访问0x00001240-0x0000125f,第三次访问0x00001260-0x0000133f,总共只需要访问三次,这样可以大大减少内存访问次数。优化kernel的性能。
二、性能优化
考虑一个矩阵相乘的问题,一个MXP的矩阵A,和一个P*N的矩阵B相乘得到MXN的C矩阵,在CPU中计算的代码入下:
#define M 1024
#define P 512
#define N 2048 void RunAsCpu(
const float *A,
const float *B,
float* C)
{
for (int i = 0; i < M; i++)
{
for (int j = 0; j < N; j++)
{
C[i*N + j] = 0.0;
for (int k = 0; k < P; k++)
{
C[i*N + j] += A[i*P + k] * B[k*N + j];
}
}
}
}如果使用GPU运行,那么通过降维操作,创建M*N个线程,第一个维度大小的M,第二个维度大小为N,kernel中代码可能如下:
__kernel void RunAsGpu_1(
__global float *A,
__global float *B,
int M,
int N,
int P,
__global float* C)
{
int x = get_global_id(0);
int y = get_global_id(1);
float sum = 0;
for(int i = 0;i<P;i++)
{
sum += A[x*P + i]*B[i*N + y];
}
C[x*N + y] = sum;
}此时,如果思考一下,可能会发现,还有第二种方案,即第一个维度大小的N,第二个维度大小为M
__kernel void RunAsGpu_2(
__global float *A,
__global float *B,
int M,
int N,
int P,
__global float* C)
{
int x = get_global_id(0);
int y = get_global_id(1);
float sum = 0;
for(int i = 0;i<P;i++)
{
sum += A[y*P + i]*B[i*N + x];
}
C[y*N + x] = sum;
}这两个kernel运行结果是一样的,那运行效率有什么不同呢?host文件用如下代码,然后运行一下看看效果:
#include <iostream>
#include <CL/cl.h>
#include <cassert>
#include <windows.h>
#include <ctime>
using namespace std; #define M 1024
#define P 512
#define N 2048 void RunAsCpu(
const float *A,
const float *B,
float* C)
{
for (int i = 0; i < M; i++)
{
for (int j = 0; j < N; j++)
{
C[i*N + j] = 0.0;
for (int k = 0; k < P; k++)
{
C[i*N + j] += A[i*P + k] * B[k*N + j];
}
}
}
} //计时函数
double time_stamp()
{
LARGE_INTEGER curclock;
LARGE_INTEGER freq;
if (
!QueryPerformanceCounter(&curclock) ||
!QueryPerformanceFrequency(&freq)
)
{
return -1;
} return double(curclock.QuadPart) / freq.QuadPart;
}
#define OPENCL_CHECK_ERRORS(ERR) \
if(ERR != CL_SUCCESS) \
{ \
cerr \
<< "OpenCL error with code " << ERR \
<< " happened in file " << __FILE__ \
<< " at line " << __LINE__ \
<< ". Exiting...\n"; \
exit(1); \
}
int main(int argc, const char** argv)
{
cl_int error = 0; // Used to handle error codes
cl_context context;
cl_command_queue queue;
cl_device_id device; // 遍历系统中所有OpenCL平台
cl_uint num_of_platforms = 0;
// 得到平台数目
error = clGetPlatformIDs(0, 0, &num_of_platforms);
OPENCL_CHECK_ERRORS(error);
cout << "可用平台数: " << num_of_platforms << endl; cl_platform_id* platforms = new cl_platform_id[num_of_platforms];
// 得到所有平台的ID
error = clGetPlatformIDs(num_of_platforms, platforms, 0);
OPENCL_CHECK_ERRORS(error);
//遍历平台,选择一个Intel平台的
cl_uint selected_platform_index = num_of_platforms;
for (cl_uint i = 0; i < num_of_platforms; ++i)
{
size_t platform_name_length = 0;
error = clGetPlatformInfo(
platforms[i],
CL_PLATFORM_NAME,
0,
0,
&platform_name_length
);
OPENCL_CHECK_ERRORS(error); // 调用两次,第一次是得到名称的长度
char* platform_name = new char[platform_name_length];
error = clGetPlatformInfo(
platforms[i],
CL_PLATFORM_NAME,
platform_name_length,
platform_name,
0
);
OPENCL_CHECK_ERRORS(error); cout << " [" << i << "] " << platform_name; if (
strstr(platform_name, "Intel") &&
selected_platform_index == num_of_platforms // have not selected yet
)
{
cout << " [Selected]";
selected_platform_index = i;
} cout << endl;
delete[] platform_name;
}
if (selected_platform_index == num_of_platforms)
{
cerr
<< "没有找到Intel平台\n";
return 1;
}
// Device
cl_platform_id platform = platforms[selected_platform_index];
error = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL);
OPENCL_CHECK_ERRORS(error) // Context
context = clCreateContext(0, 1, &device, NULL, NULL, &error);
OPENCL_CHECK_ERRORS(error) // Command-queue CL_QUEUE_PROFILING_ENABLE开启才能计时
queue = clCreateCommandQueue(context, device, CL_QUEUE_PROFILING_ENABLE, &error);
OPENCL_CHECK_ERRORS(error) //下面初始化测试数据(主机数据)
float* A_h = new float[M*P];
float* B_h = new float[P*N];
float* C_h = new float[M*N];
//srand((unsigned)time(NULL));
srand(100);
for (int i = 0; i < M*P; i++)
A_h[i] = rand() % 50; for (int i = 0; i < P*N; i++)
B_h[i] = rand() % 50;
//初始化设备数据
// 标志位表示数据只读,并且从nums1_h和nums2_h复制数据
cl_mem A_d = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float)*M*P, A_h, &error);
OPENCL_CHECK_ERRORS(error)
cl_mem B_d = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float)*P*N, B_h, &error);
OPENCL_CHECK_ERRORS(error)
cl_mem C_d = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(float)*M*N, NULL, &error);
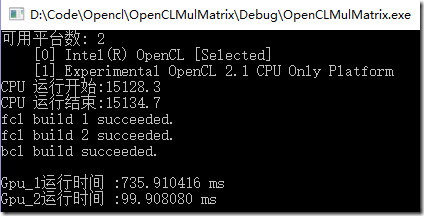
OPENCL_CHECK_ERRORS(error) cout << "CPU 运行开始:" << time_stamp() << endl;
RunAsCpu(A_h, B_h, C_h);
cout << "CPU 运行结束:" << time_stamp() << endl; //读取OpenCLSum.cl文件内容 FILE* fp = fopen("OpenCLMulMatrix.cl", "rb");
fseek(fp, 0, SEEK_END);
size_t src_size = ftell(fp);
fseek(fp, 0, SEEK_SET);
const char* source = new char[src_size];
fread((void*)source, 1, src_size, fp);
fclose(fp); //创建编译运行kernel函数
cl_program program = clCreateProgramWithSource(context, 1, &source, &src_size, &error);
OPENCL_CHECK_ERRORS(error)
delete[] source; // Builds the program
error = clBuildProgram(program, 1, &device, NULL, NULL, NULL);
OPENCL_CHECK_ERRORS(error) // Shows the log
char* build_log;
size_t log_size;
// First call to know the proper size
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0, NULL, &log_size);
build_log = new char[log_size + 1];
// Second call to get the log
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, log_size, build_log, NULL);
build_log[log_size] = '\0';
cout << build_log << endl;
delete[] build_log; // Extracting the kernel
cl_kernel run_as_gpu_1 = clCreateKernel(program, "RunAsGpu_1", &error);
OPENCL_CHECK_ERRORS(error)
//设置kernel参数
cl_int M_d = M;
cl_int P_d = P;
cl_int N_d = N;
error = clSetKernelArg(run_as_gpu_1, 0, sizeof(cl_mem), &A_d);
error |= clSetKernelArg(run_as_gpu_1, 1, sizeof(cl_mem), &B_d);
error |= clSetKernelArg(run_as_gpu_1, 2, sizeof(int), &M_d);
error |= clSetKernelArg(run_as_gpu_1, 3, sizeof(int), &N_d);
error |= clSetKernelArg(run_as_gpu_1, 4, sizeof(int), &P_d);
error |= clSetKernelArg(run_as_gpu_1, 5, sizeof(cl_mem), &C_d);
OPENCL_CHECK_ERRORS(error) // 启动kernel
size_t globalws_1[2] = { M,N };
cl_event ev;
error = clEnqueueNDRangeKernel(queue, run_as_gpu_1, 2, NULL, globalws_1, NULL, 0, NULL, &ev);
clFinish(queue);
OPENCL_CHECK_ERRORS(error)
//计算kerenl执行时间
cl_ulong startTime, endTime;
clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_START,
sizeof(cl_ulong), &startTime, NULL);
clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_END,
sizeof(cl_ulong), &endTime, NULL);
cl_ulong kernelExecTimeNs = endTime - startTime;
printf("Gpu_1运行时间 :%8.6f ms\n", kernelExecTimeNs*1e-6); //取得kernel返回值
float* gpu_C_1 = new float[M*N];
clEnqueueReadBuffer(queue, C_d, CL_TRUE, 0, M*N*sizeof(float), gpu_C_1, 0, NULL, NULL);
assert(memcmp(C_h, gpu_C_1, M*N * sizeof(float)) == 0); // Extracting the kernel
cl_kernel run_as_gpu_2 = clCreateKernel(program, "RunAsGpu_2", &error);
OPENCL_CHECK_ERRORS(error)
//设置kernel参数
error = clSetKernelArg(run_as_gpu_2, 0, sizeof(cl_mem), &A_d);
error |= clSetKernelArg(run_as_gpu_2, 1, sizeof(cl_mem), &B_d);
error |= clSetKernelArg(run_as_gpu_2, 2, sizeof(int), &M_d);
error |= clSetKernelArg(run_as_gpu_2, 3, sizeof(int), &N_d);
error |= clSetKernelArg(run_as_gpu_2, 4, sizeof(int), &P_d);
error |= clSetKernelArg(run_as_gpu_2, 5, sizeof(cl_mem), &C_d);
OPENCL_CHECK_ERRORS(error) // 启动kernel
size_t globalws_2[2] = { N,M };
error = clEnqueueNDRangeKernel(queue, run_as_gpu_2, 2, NULL, globalws_2, NULL, 0, NULL, &ev);
clFinish(queue);
OPENCL_CHECK_ERRORS(error)
//计算kerenl执行时间
clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_START,
sizeof(cl_ulong), &startTime, NULL);
clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_END,
sizeof(cl_ulong), &endTime, NULL);
kernelExecTimeNs = endTime - startTime;
printf("Gpu_2运行时间 :%8.6f ms\n", kernelExecTimeNs*1e-6);
//取得kernel返回值
float* gpu_C_2 = new float[M*N];
clEnqueueReadBuffer(queue, C_d, CL_TRUE, 0, M*N * sizeof(float), gpu_C_2, 0, NULL, NULL); assert(memcmp(C_h, gpu_C_2, M*N * sizeof(float)) == 0); error = clEnqueueNDRangeKernel(queue, run_as_gpu_1, 2, NULL, globalws_1, NULL, 0, NULL, &ev);
clFinish(queue);
OPENCL_CHECK_ERRORS(error)
//计算kerenl执行时间
clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_START,
sizeof(cl_ulong), &startTime, NULL);
clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_END,
sizeof(cl_ulong), &endTime, NULL);
kernelExecTimeNs = endTime - startTime;
printf("Gpu_1运行时间 :%8.6f ms\n", kernelExecTimeNs*1e-6); delete[] A_h;
delete[] B_h;
delete[] C_h;
delete[] gpu_C_1;
delete[] gpu_C_2;
delete[] platforms;
clReleaseKernel(run_as_gpu_1);
clReleaseKernel(run_as_gpu_2);
clReleaseCommandQueue(queue);
clReleaseContext(context);
clReleaseMemObject(A_d);
clReleaseMemObject(B_d);
clReleaseMemObject(C_d);
return 0;
}
三、运行结果
这里可以看出,两个方案虽然结果一样,但是效率是有很大差别的,原因是什么呢?上面说到,GPU会合并内存访问来优化性能,多维情况下,内存空间是按照行主序的方式储存的,如下图,一个5列的二维数组内存排列方式如下:
而在GPU执行过程中,他是先执行第一个纬度,再执行第二个纬度。所以,在第一种情况下,第一维是M,第二维是N,此时,B和C的内存无法合并访问(访问顺序是00 10 20 30 40 01 11 21 …)
在第二种情况下,B和C的内存可以合并访问(访问顺序是00 01 02 03 04 11 12 13 …)
合并访问会减小内存请求,优化性能。

四、其他示例
试试添加一个kernel函数,测试它的运行时间。
__kernel void RunAsGpu_3(
__global float *A,
__global float *B,
int M,
int N,
int P,
__global float* C)
{
int x = get_global_id(0);
int y = get_global_id(1);
C[x*N + y] = 0;
for(int i = 0;i<P;i++)
{
C[x*N + y] += A[x*P + i]*B[i*N + y];
}
}
五、相关下载
OpenCL入门:(三:GPU内存结构和性能优化)的更多相关文章
- JVM的内存结构以及性能调优
JVM的内存结构以及性能调优 发布时间: 2017-11-22 阅读数: 16675 JVM的内存结构以及性能调优1:JVM的结构主要包括三部分,堆,栈,非堆内存(方法区,驻留字符串)堆上面存储的是引 ...
- JVM内存模型和性能优化 转
JVM内存模型和性能优化 JVM内存模型优点 内置基于内存的并发模型: 多线程机制 同步锁Synchronization 大量线程安全型库包支持 基于内存的并发机制,粒度灵活控制,灵活度高于 ...
- 利用内存结构及多线程优化多图片下载(IOS篇)
利用内存结构及多线程优化多图片下载(IOS篇) 前言 下载地址, 后续发布, 请继续关注本blog 在IOS中,我们常常遇到多图片下载的问题.最简单的解决方案是直接利用别人写好的框架.但是这如同练武, ...
- LeakCanary 内存泄漏 监测 性能优化 简介 原理 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- [转]oracle学习入门系列之五内存结构、数据库结构、进程
原文地址:http://www.2cto.com/database/201505/399285.html 1 Oracle数据库结构 关于这个话题,网上一搜绝对一大把,更别提书籍上出现的了,还有很多大 ...
- 《嵌入式Linux内存使用与性能优化》笔记
这本书有两个关切点:系统内存(用户层)和性能优化. 这本书和Brendan Gregg的<Systems Performance>相比,无论是技术层次还是更高的理论都有较大差距.但是这不影 ...
- Mali GPU OpenGL ES 应用性能优化--測试+定位+优化流程
1. 使用DS-5 Streamline定位瓶颈 DS-5 Streamline要求GPU驱动启用性能測试,在Mali GPU驱动中激活性能測试对性能影响微不足道. 1.1 DS-5 Streamli ...
- Java内存模型及性能优化
最近在做一个项目的性能优化,遇到好多以前没有关注过的性能问题,一头雾水,今天做个笔记,简单记录下JVM相关的参数设置. 一.JVM内存模型 首先介绍下Java程序具体执行的过程: Java源代码文件( ...
- JVM内存模型和性能优化
JVM内存模型优点 内置基于内存的并发模型: 多线程机制 同步锁Synchronization 大量线程安全型库包支持 基于内存的并发机制,粒度灵活控制,灵活度高于数据库锁. 多核并行计算模 ...
随机推荐
- 【vue.js】入门
慕课网视频学习笔记:http://www.imooc.com/learn/694 1.将html.js.css写到一个后缀名.vue的文件中,区分这三种类型是通过<template>.&l ...
- 5、Dubbo-监控中心
5.1).dubbo-admin 图形化的服务管理页面:安装时需要指定注册中心地址,即可从注册中心中获取到所有的提供者/消费者进行配置管理 5.2).dubbo-monitor-simple 简单的监 ...
- java把行政区划放到一个节点树形中
作者原创:转载请注明出处.https://www.cnblogs.com/yunqing/p/9486923.html 先放数据,t_city表 //津京冀地区行政区划数据 SET FOREIGN_K ...
- Shell笔记-02
Shell支持自定义变量. 定义变量 定义变量时,变量名不加美元符号($),如: variableName="value" 注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编 ...
- DDL-库的管理
一.创建库create database [if not exists] 库名[ character set 字符集名]; 二.修改库alter database 库名 character set 字 ...
- Java中的类与对象
一.类与对象的概念 1.类:类是一组相同属性.方法的对象的集合:对象是类的具体化. 2.对象具有类所有的特征,类拥有的,对象就拥有. 3.类与对象他们的关系是相对的. 类有什么特点 1) 类是对象的类 ...
- Web—11-手机端页面适配
流式布局: 就是百分比布局,非固定像素,内容向两侧填充,理解成流动的布局,成为流式布局 视觉窗口: viewport是移动端持有.这是一个虚拟的区域,承载网页的. 承载关系:浏览器—->view ...
- kvo本质探寻
一.概述 1.本文章内容,须参照本人的另一篇博客文章“class和object_getClass方法区别”加以理解: 2.基本使用: //给实例对象instance添加观察者,监听该实例对象的某个属性 ...
- Angular7教程-05-搭建项目环境
1. 本节说明 本节以及后面的内容我们将会通过搭建一个简单的博客程序来对angular进行介绍,项目使用前端框架是bootstrap.版本v3.3.7,另外需要安装jquery.关于bootstrap ...
- 19-3-15Python中闭包,迭代器,递归
函数名的使用 函数名可以当作值赋值给变量 函数名可以当作元素放到容器里 闭包 一个嵌套函数 在嵌套函数内的函数使用外部(非全局的变量) 满足以上两条就是闭包 python中闭包,会进行内存驻留,普通函 ...