【Python项目篇】【爬妹子图】
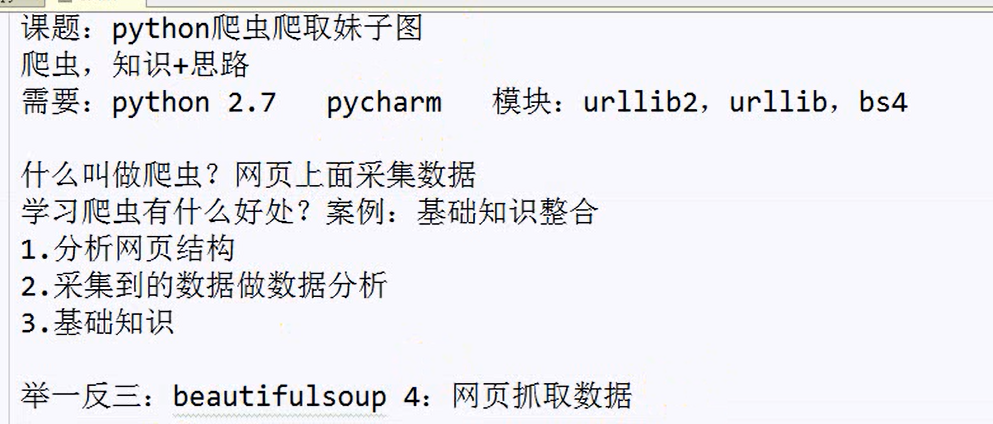


#-*- coding:utf-8 -*-
import urllib
import urllib2
from bs4 import beautifulsoup4 #获取标签下的内容
#打开网页,获取源码
x=0
url='http://www.dbmeinv.com/?pager_offset=1'
def crawl(url): #取名字,最好见名思义
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'}
req=urllib2.Request(url,headers=headers) #浏览器帽子
page=urllib2.urlopen(req,timeout=20) #打开网页
contents=page.read()#获取源码
#print contents
#html.parser是自带的解析方式,lxml功能大
soup=BeautifulSoup(contents,'html.parser')#创建一个soup对象
my_girl=soup.find_all('img')#找到所有的标签
print(my_girl)
for girl in my_girl:#遍历list,选取属性
link=girl.get('src')#获取src图片路径
print(link)
#下载的文件,取名字
global x
urllib.urlretrieve(link,'image\%s.jpg'%x)
x+=1
print crawl(url)
以上代码在3.5环境下运行一下代码可以成功爬到各图片链接
#-*- coding:utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup #获取标签下的内容
#打开网页,获取源码 x = 0
url = 'http://www.dbmeinv.com/?pager_offset=1'
def crawl(url):
print('')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'}
print('')
req = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(req)
#req = urllib3.request(url, headers=headers) #浏览器帽子
print('')
#page = urllib3.urlopen(req, timeout=20) #打开网页
contents = page.read()#获取源码
soup = BeautifulSoup(contents,'html.parser')#创建一个soup对象
my_girl = soup.find_all('img')#找到所有的标签
print(my_girl)
for girl in my_girl:
link = girl.get('src')
print(link)
print('')
print('')
crawl(url)
【Python项目篇】【爬妹子图】的更多相关文章
- python3 爬 妹子图
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式 Beautiful Soup 4 通过PyP ...
- 【Python项目】爬取新浪微博个人用户信息页
微博用户信息爬虫 项目链接:https://github.com/RealIvyWong/WeiboCrawler/tree/master/WeiboUserInfoCrawler 1 实现功能 这个 ...
- 【Python项目】爬取新浪微博签到页
基于微博签到页的微博爬虫 项目链接:https://github.com/RealIvyWong/WeiboCrawler/tree/master/WeiboLocationCrawler 1 实现功 ...
- python爬虫之一---------豆瓣妹子图
#-*- coding:utf-8 -*- __author__ = "carry" import urllib import urllib2 from bs4 import Be ...
- 老王Python培训视频教程(价值500元)【基础进阶项目篇 – 完整版】
老王Python培训视频教程(价值500元)[基础进阶项目篇 – 完整版] 教学大纲python基础篇1-25课时1.虚拟机安装ubuntu开发环境,第一个程序:hello python! (配置开发 ...
- 「玩转Python」突破封锁继续爬取百万妹子图
前言 从零学 Python 案例,自从提交第一个妹子图版本引来了不少小伙伴的兴趣.最近,很多小伙伴发来私信说,妹子图不能爬了!? 趁着周末试了一把,果然爬不动了,爬下来的都是些 0kb 的假图片,然后 ...
- Python使用Scrapy爬虫框架全站爬取图片并保存本地(妹子图)
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://sc ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
随机推荐
- Mysql利用match...against进行全文检索
在电商项目中,最核心的功能之一就是搜索功能,搜索做的好,整个电商平台就是个优秀的平台.一般搜索功能都使用搜索引擎如Lucene.solr.elasticsearch等,虽然这功能比较强大,但是对于一些 ...
- struts2的零配置
最近开始关注struts2的新特性,从这个版本开始,Struts开始使用convention-plugin代替codebehind-plugin来实现struts的零配置.配置文件精简了,的确是简便了 ...
- mysql中如何在创建数据库的时候指定数据库的字符集?
需求描述: 在创建DB的时候指定字符集. 操作过程: 1.使用create database语句创建数据库 mysql> create database if not exists test03 ...
- mybatis由浅入深day01_8.2resultMap
8.2 resultMap mybatis中使用resultMap完成高级输出结果映射. resultType可以指定pojo将查询结果映射为pojo,但需要pojo的属性名和sql查询的列名一致方可 ...
- HTML&CSS精选笔记_HTML与CSS网页设计概述
HTML与CSS网页设计概述 Web基本概念 认识网页 网页主要由文字.图像和超链接等元素构成.当然,除了这些元素,网页中还可以包含音频.视频以及Flash等. 名词解释 Internet网络 就是通 ...
- com.alibaba.fastjson.JSONException: default constructor not found. class ……
1.json工具类 package com.hyzn.fw.util; import java.util.List; import java.util.Map; import com.alibaba. ...
- select 相关 获取当前项以及option js选定
$("#product option[value='170']").prop("selected","true")//要确定是selecte ...
- Android英文文档翻译系列(3)——AsyncTask
AsyncTask——异步任务 个人认为这是翻译比较好的一次.. Class Overview//类概述 AsyncTask enables proper and easy use of th ...
- Android之ListView分页数据加载
1.效果如下: 实例如下: 上图的添加数据按钮可以换成一个进度条 因为没有数据所以我加了一个按钮添加到数据库用于测试:一般在服务器拉去数据需要一定的时间,所以可以弄个进度条来提示用户: 点击加载按 ...
- synchronized同步方法
“非线程安全”其实会在多个线程对同一个对象中的实例变量进行并发访问的时候产生,产生的后果是脏读,也就是取到的数据是被更改过的.而“线程安全”就是以获得的实例变量的值是经过同步处理的,不会出现脏读的现象 ...