Hbase(三) hbase协处理器与二级索引
一、协处理器—Coprocessor
1、 起源
Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执 行求和、计数、排序等操作。比如,在旧版本的(<0.92)Hbase 中,统计数据表的总行数,需 要使用 Counter 方法,执行一次 MapReduce Job 才能得到。虽然 HBase 在数据存储层中集成
了 MapReduce,能够有效用于数据表的分布式计算。然而在很多情况下,做一些简单的相 加或者聚合计算的时候, 如果直接将计算过程放置在 server 端,能够减少通讯开销,从而获 得很好的性能提升。于是, HBase 在 0.92 之后引入了协处理器(coprocessors),实现一些激动
人心的新特性:能够轻易建立二次索引、复杂过滤器(谓词下推)以及访问控制等。
2、协处理器有两种: observer 和 endpoint
(1) Observer 类似于传统数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。Observer Coprocessor 就是一些散布在 HBase Server 端代码中的 hook 钩子, 在固定的事件发生时被调用。比如: put 操作之前有钩子函数 prePut,该函数在 put 操作
执行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数
以 HBase0.92 版本为例,它提供了三种观察者接口:
● RegionObserver:提供客户端的数据操纵事件钩子: Get、 Put、 Delete、 Scan 等。
● WALObserver:提供 WAL 相关操作钩子。
● MasterObserver:提供 DDL-类型的操作钩子。如创建、删除、修改数据表等。
到 0.96 版本又新增一个 RegionServerObserver
下图是以 RegionObserver 为例子讲解 Observer 这种协处理器的原理:

(2) Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处 理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常 见的用法就是进行聚集操作。如果没有协处理器,当用户需要找出一张表中的最大数据,即
max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的 操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执 行,势必效率低下。利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,
HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内 执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给客户端。在客户端进一步将多个 Region 的最大值进一步处理而找到其中的最大值。
这样整体的执行效率就会提高很多
下图是 EndPoint 的工作原理:
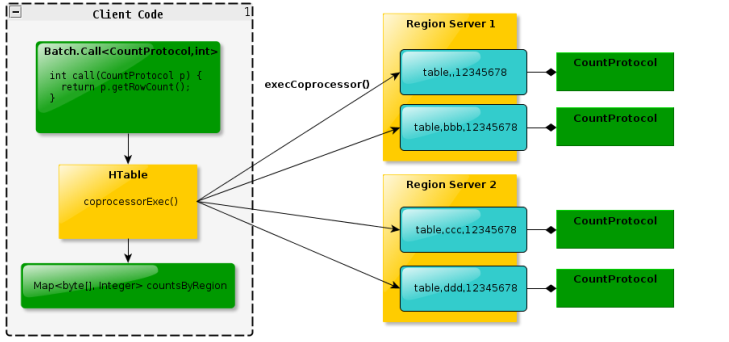
(3)总结
Observer 允许集群在正常的客户端操作过程中可以有不同的行为表现
Endpoint 允许扩展集群的能力,对客户端应用开放新的运算命令
observer 类似于 RDBMS 中的触发器,主要在服务端工作
endpoint 类似于 RDBMS 中的存储过程,主要在 client 端工作
observer 可以实现权限管理、优先级设置、监控、 ddl 控制、 二级索引等功能
endpoint 可以实现 min、 max、 avg、 sum、 distinct、 group by 等功能
二、协处理器加载方式
协处理器的加载方式有两种,我们称之为静态加载方式( Static Load) 和动态加载方式 ( Dynamic Load)。 静态加载的协处理器称之为 System Coprocessor,动态加载的协处理器称 之为 Table Coprocessor
1、静态加载
通过修改 hbase-site.xml 这个文件来实现, 启动全局 aggregation,能过操纵所有的表上 的数据。只需要添加如下代码:
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value>
</property>
为所有 table 加载了一个 cp class,可以用” ,”分割加载多个 class
2、动态加载
启用表 aggregation,只对特定的表生效。通过 HBase Shell 来实现。
disable 指定表。 hbase> disable 'mytable'
添加 aggregation
hbase> alter 'mytable', METHOD => 'table_att','coprocessor'=>
'|org.apache.Hadoop.hbase.coprocessor.AggregateImplementation||'
重启指定表 hbase> enable 'mytable'
3、协处理器卸载

三、二级索引案例
row key 在 HBase 中是以 B+ tree 结构化有序存储的,所以 scan 起来会比较效率。单表以 row key 存储索引, column value 存储 id 值或其他数据 ,这就是 Hbase 索引表的结构。
由于 HBase 本身没有二级索引( Secondary Index)机制,基于索引检索数据只能单纯地依靠 RowKey,为了能支持多条件查询,开发者需要将所有可能作为查询条件的字段一一拼接到 RowKey 中,这是 HBase 开发中极为常见的做法
在社交类应用中,经常需要快速检索各用户的关注列表 guanzhu,同时,又需要反向检索各 种户的粉丝列表 fensi,为了实现这个需求,最佳实践是建立两张互为反向的表:
插入一条关注信息时,为了减轻应用端维护反向索引表的负担,可用 Observer 协处理器实 现: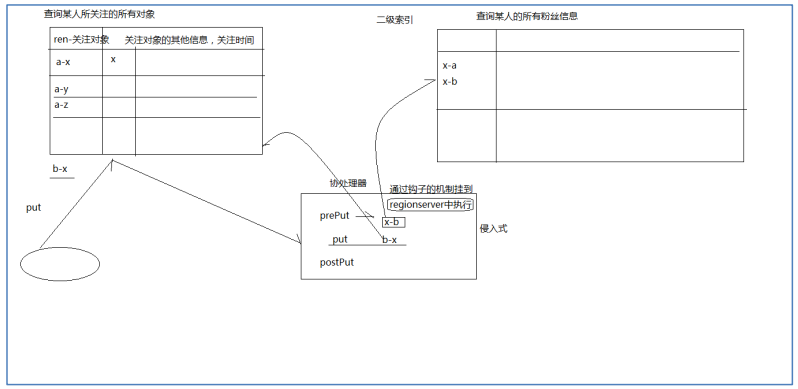
实现步骤:
(1)代码:
package com.ghgj.hbase;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
public class TestCoprocessor extends BaseRegionObserver {
static Configuration config = HBaseConfiguration.create();
static HTable table = null;
static{
config.set("hbase.zookeeper.quorum",
"hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181");
try {
table = new HTable(config, "guanzhu");
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void prePut(ObserverContext<RegionCoprocessorEnvironment> e,
Put put, WALEdit edit, Durability durability) throws IOException {
// super.prePut(e, put, edit, durability);
byte[] row = put.getRow();
Cell cell = put.get("f1".getBytes(), "from".getBytes()).get(0);
Put putIndex = new
Put(cell.getValueArray(),cell.getValueOffset(),cell.getValueLength());
putIndex.addColumn("f1".getBytes(), "from".getBytes(), row);
table.put(putIndex);
table.close();
}
}
(2)打成 jar 包( cppp.jar),上传到 hdfs 中的 hbasecp 目录下
hadoop fs -put cppp.jar /hbasecp
(3)建hbase表,按以下顺序操作

(4)现在插入数据进行验证,命令行和代码都可以
testput("fensi","c","f1","from","b");

Hbase(三) hbase协处理器与二级索引的更多相关文章
- HBase协处理器同步二级索引到Solr(续)
一. 已知的问题和不足二.解决思路三.代码3.1 读取config文件内容3.2 封装SolrServer的获取方式3.3 编写提交数据到Solr的代码3.4 拦截HBase的Put和Delete操作 ...
- HBase协处理器同步二级索引到Solr
一. 背景二. 什么是HBase的协处理器三. HBase协处理器同步数据到Solr四. 添加协处理器五. 测试六. 协处理器动态加载 一. 背景 在实际生产中,HBase往往不能满足多维度分析,我们 ...
- HBase 协处理器实现二级索引
HBase在0.92之后引入了coprocessors,提供了一系列的钩子,让我们能够轻易实现访问控制和二级索引的特性.下面简单介绍下两种coprocessors,第一种是Observers,它实际类 ...
- HBase学习(四) 二级索引 rowkey设计
HBase学习(四) 一.HBase的读写流程 画出架构 1.1 HBase读流程 Hbase读取数据的流程:1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接2)从zookeepe ...
- HBase 二级索引与Coprocessor协处理器
Coprocessor简介 (1)实现目的 HBase无法轻易建立“二级索引”: 执行求和.计数.排序等操作比较困难,必须通过MapReduce/Spark实现,对于简单的统计或聚合计算时,可能会因为 ...
- Phoneix(三)HBase集成Phoenix创建二级索引
一.Hbase集成Phoneix 1.下载 在官网http://www.apache.org/dyn/closer.lua/phoenix/中选择提供的镜像站点中下载与安装的HBase版本对应的版本. ...
- HBase协处理器的使用(添加Solr二级索引)
给HBase添加一二级索引,HBase协处理器结合solr 代码如下 package com.hbase.coprocessor; import java.io.IOException; import ...
- HBase 二级索引与Join
二级索引与索引Join是Online业务系统要求存储引擎提供的基本特性.RDBMS支持得比较好,NOSQL阵营也在摸索着符合自身特点的最佳解决方案. 这篇文章会以HBase做为对象来探讨如何基于Hba ...
- 085 HBase的二级索引,以及phoenix的安装(需再做一次)
一:问题由来 1.举例 有A列与B列,分别是年龄与姓名. 如果想通过年龄查询姓名. 正常的检索是通过rowkey进行检索. 根据年龄查询rowkey,然后根据rowkey进行查找姓名. 这样的效率不高 ...
随机推荐
- MySQL数据库之安装,基本操作
一.基础部分 1.数据库是什么 之前所学,数据要永久保留,比如用户注册的用户信息,都是保存于文件,而文件只能存在于某一台机器上. 如果我们不考虑从文件中读取数据的效率问题,并且假设我们的程序所有的组件 ...
- dubbo常见的一些面试题
什么是Dubbo? Duubbo是一个RPC远程调用框架, 分布式服务治理框架 什么是Dubbo服务治理? 服务与服务之间会有很多个Url.依赖关系.负载均衡.容错.自动注册服务. Dubbo有哪些协 ...
- linux菜鸟笔记
linux目录的子目录复制 cp -r 要复制的目录+新的目录 cp -r a test 意思就是将a的子目录及文件复制到新的目录test下面 zt@ubuntu:~/Desktop$ mkdir - ...
- 移动端车牌识别/车牌OCR识别
周末,小编约了朋友商场shopping. 开车进地下车库时,“滴”的一声,完成车牌录入:开车离开时,扫描二维码,输入车牌,完成停车收费.小编不禁感叹科技改变生活,人工智能给生活带来的便利. 车牌自动识 ...
- 获取Java线程返回值的几种方式
在实际开发过程中,我们有时候会遇到主线程调用子线程,要等待子线程返回的结果来进行下一步动作的业务. 那么怎么获取子线程返回的值呢,我这里总结了三种方式: 主线程等待. Join方法等待. 实现Call ...
- HP VC模块Server Profile配置快速参考(With SUS)
以管理员身份登录VCM 准备进行Server Profiles的配置 在左侧导航栏中找到并点击"Server Profiles",在右侧主窗口的左下角点击"Add&quo ...
- eclipse安装反编译器jad
1.下载net.sf.jadclipse_3.3.0.jar.jadclipse_3.3.0.jar.jad.exe 2.将net.sf.jadclipse_3.3.0.jar放在eclipse的安装 ...
- 带你玩转JavaScript中的隐式强制类型转换
正题开始前我想先抛出一个问题,==和===有什么区别?可能一般人会想,不就是后者除了比较值相等之外还会比较类型是否相等嘛,有什么好问的,谁不知道?!但是这样说还不够准确,两者的真正区别其实是==在比较 ...
- 石家庄铁道大学网站首页UI分析
今天的软件工程王老师讲了UI的设计,以前狭隘的认为只有移动设备上的界面叫UI,百度一下才发现UI其实有这么多含义:UI即User Interface的简称.泛指用户的操作界面,UI设计主要指界面的样式 ...
- 人生苦短,我用Python!
一.程序分析 1.读取文件到缓冲区 def process_file(): # 读文件到缓冲区 try: # 打开文件 f = open("C:\\Users\\panbo\\Desktop ...