[place recognition]NetVLAD: CNN architecture for weakly supervised place recognition 论文翻译及解析(转)
https://blog.csdn.net/qq_32417287/article/details/80102466
abstract
本文关注的是大规模的地点识别问题,任务是从一张图像中快速准确地识别位置。
1. 提出一种卷积神经网络结构,可以实现端到端的识别。主要组件是 NetVLAD,这是一个新生成的VLAD层。NetVLAD 可以很容易地运用到任何的CNN结构中,并且可以使用BP优化。
2. 基于一种新的弱监督排序损失(a new weakly supervised ranking loss),提出了一个训练过程,来学习得到所需要的参数。使用的数据集是Google Street View Time Machine。
3. 结果显示我们提出的结构得到的特征比其他非学习的图像表示(non-learnt image representations)以及现有的CNN描述子得到的特征要好,
introduction
地点识别现在主要应用在自主驾驶,增强学习等
地点识别一个挑战是,我们如何在一个城市或国家中识别相同的街角,即使有光照等其他因素的影响。关键问题是如何找到这样的一个具有代表性并且具有区分性的地方。
传统做法是将地点识别问题看作实例检索任务,使用具有局部不变性的特征(SIFT)来表示每一个图像,然后将特征聚合成一个向量表示,方法有 BOW, VLAD, FV等。近些年,CNNs的出现为多种类级的识别任务提供了更强性能的图像表示。
虽然CNN能够用在较大的数据集上,但是如果直接迁移使用CNN,那么它作为一个黑盒进行特征提取,对于实例识别任务会在性能上有限制。所以本文的任务是探究这种性能上的差距能够使用CNN特征减小。主要的问题是:
- 如何定义一个好的CNN结构,
- 怎样得到足够多的标注数据
- 怎么训练来提升结构性能
第一,基于现有的神经网络架构,本文提出一种一个带有VLAD层的卷积神经网络结构,NetVLAD,可以被加到任何的CNN结构中,并且可以使用BP算法优化,然后使用PCA降维得到compact descriptor of the image。
第二,为了训练网络,使用 the Google Street View Time Machine 收集了大量的不同时间不同角度相同地点的全景图。通过这些数据进行训练是弱监督学习:两幅相似的全景图是通过他们的GPS特征近似得到的,但是并不知道图像中的哪个部分决定了这两幅全景图是同一个地方。
第三,使用了端到端的模式来学习得到参数。得到的特征对于视角和光照情况具有鲁棒性。
method overview
将地点识别问题看作是图像检索问题,有未知地点的图像作为查询图像,检索一个地理标注的数据集合,然后返回排序较高的图像。
图像特征提取:f(Ii)" role="presentation" style="position: relative;">f(Ii)f(Ii) offline
待查询图像特征:f(q)" role="presentation" style="position: relative;">f(q)f(q) online
goal:找到与待查询图像最近的图像,欧氏距离 Euclidean distance d(q,Ii)" role="presentation" style="position: relative;">d(q,Ii)d(q,Ii), 也有其他的距离计算方法,但是本文采用的是欧氏距离。
本文提出以端到端的方式学习图像的特征表示 f(I)" role="presentation" style="position: relative;">f(I)f(I),特征表示通过 θ" role="presentation" style="position: relative;">θθ 参数化。 fθ(I)" role="presentation" style="position: relative;">fθ(I)fθ(I),欧式距离为 dtheta(Ii,Ij)=‖fθ(Ii)−fθ(Ij)‖" role="presentation" style="position: relative;">dtheta(Ii,Ij)=∥fθ(Ii)−fθ(Ij)∥dtheta(Ii,Ij)=‖fθ(Ii)−fθ(Ij)‖
Deep architecture for place recognition
本章主要讨论 fθ" role="presentation" style="position: relative;">fθfθ
提取图像特征最好使得这些特征对一些特性具有鲁棒性,对于光照以及视角转变的鲁棒性是由特征描述子决定,尺度不变性是通过在多个尺度下提取描述子进行保证的。
本文设计的CNN结构模拟的是标准的检索过程。
第一步、去掉CNN的最后一层,把它作为描述子,输出是 H×W×D" role="presentation" style="position: relative;">H×W×DH×W×D 的向量,可以将其看作一个D维度的描述子,一共由 H×W" role="presentation" style="position: relative;">H×WH×W 个。
第二部、设计一个新的池化层 NetVLAD(受VLAD启发)对提取到的描述子进行池化,使其成为一个固定的图像表示,参数是通关过BP学习得到的。
NetVLAD: A Generalized VLAD layer (fVLAD" role="presentation" style="position: relative;">fVLADfVLAD)
BoW 统计的是 visual words 的数量,VLAD 统计的是 每个visual word 的残差和(sum of residuals)(描述子和其相应的聚类中心的差值)
input:N×{xi}∈RD" role="presentation" style="position: relative;">N×{xi}∈RDN×{xi}∈RD
cluster centers(visual words): K×{ck}" role="presentation" style="position: relative;">K×{ck}K×{ck}
output image representation V∈RK×D" role="presentation" style="position: relative;">V∈RK×DV∈RK×D
V(j,k)=∑i=1Nak(xi)(xi(j)−ck(j))" role="presentation" style="position: relative;">V(j,k)=∑Ni=1ak(xi)(xi(j)−ck(j))V(j,k)=∑i=1Nak(xi)(xi(j)−ck(j))
ak" role="presentation" style="position: relative;">akak is 1 if cluster ck" role="presentation" style="position: relative;">ckck is the closest cluster to descriptor xi" role="presentation" style="position: relative;">xixi and 0 otherwise
也就是说,VLAD的向量V存储的是所有的x在其对应的聚类中上的残差和
找到每个聚类中心中的所有的X,然后以该聚类中心为基础,计算所有的残差和:遍历所有的样本点,利用a(x) 决定是否属于该样本点,然后计算相应的残差,最后求和,这样得到了一个聚类中心的残差和,就是得到了V的一行。
遍历k个聚类中心,得到 V的k行。
最后对V进行 a vector 处理,然后进行L2归一化。
要通过BP对参数进行优化,就需要对所有参数以及输入都是可微分的,所有对 ak" role="presentation" style="position: relative;">akak 进行修改

其中 α" role="presentation" style="position: relative;">αα 是一个正数,控制学习速率
将(2)中的平方展开, e−α‖xi‖2" role="presentation" style="position: relative;">e−α∥xi∥2e−α‖xi‖2 会消失,得到

新的到的NetVLAD 依赖于三分参数 {wk},{bk},{ck}" role="presentation" style="position: relative;">{wk},{bk},{ck}{wk},{bk},{ck},使其灵活性更好。
图2 将NetVLAD分解成一个CNN层和一个有向五环图。
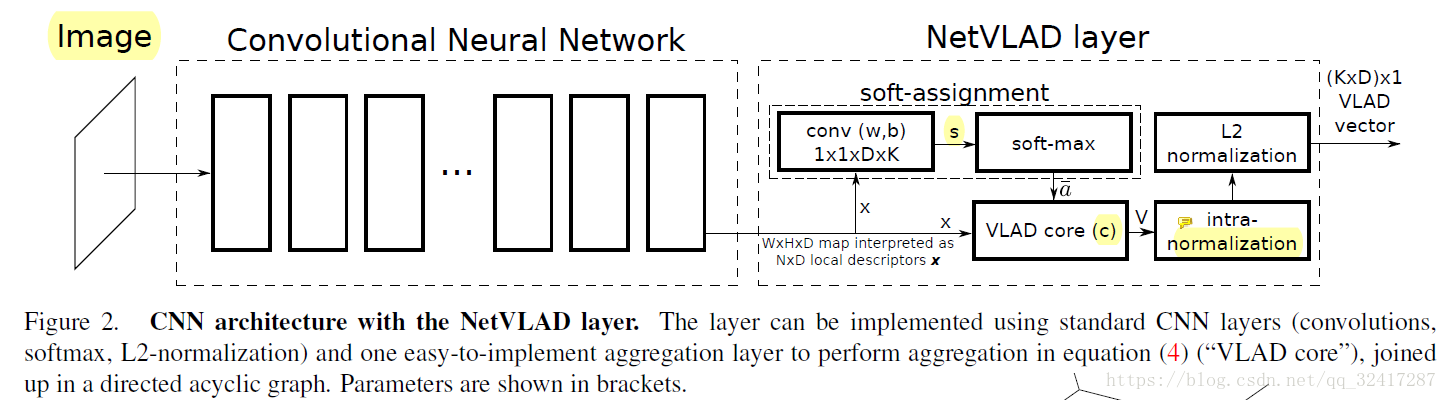
The output after normalization is a (K×D)×1" role="presentation" style="position: relative;">(K×D)×1(K×D)×1 descriptor.
Max pooling (fmax)
在实验中对 H×W" role="presentation" style="position: relative;">H×WH×W 个D维的特征使用了最大池化,产生一个D维度的输出,然后使用 L2−normalized" role="presentation" style="position: relative;">L2−normalizedL2−normalized
Learning from Time Machine data
本章主要是怎样通过端到端的学习得到涉及到的参数。
怎样得到足够多的带有标记的数据
通过 the Google Street View Time Machine 得到大量的弱监督图像。这些图像仅仅有地理位置的标记,表示他们是相近的位置,但是没有图像本身上的近似,所以是弱监督问题。
两个地理位置相近的图像能相互替代(two geographically close perspective images do not necessarily depict the same objects since they could be facing different directions or occlusions could take place)。
对于一个给定的训练图片,GPS信息的作用:潜在的正确项 {piq}" role="presentation" style="position: relative;">{pqi}{piq}(距离较近),绝对的错误项 {njq}" role="presentation" style="position: relative;">{nqj}{njq}(距离很远)怎样的损失 loss 是合适的
设计了一个弱监督三元组损失 ( a new weakly supervised triplet ranking loss) 来解决数据的不完整以及噪声
给定一个图像,目的是找出与其最为近似的图像,也就是说找到欧氏距离最小的图像与其匹配。dθ(q,Ii∗)<dθ(q,Ii)" role="presentation" style="position: relative;">dθ(q,Ii∗)<dθ(q,Ii)dθ(q,Ii∗)<dθ(q,Ii)
将其转化为一个三元组 {q,Ii∗,Ii}" role="presentation" style="position: relative;">{q,Ii∗,Ii}{q,Ii∗,Ii}
从Google Street View Time Machine中得到训练集 (q,{piq},{njq})" role="presentation" style="position: relative;">(q,{pqi},{nqj})(q,{piq},{njq})
{piq}" role="presentation" style="position: relative;">{pqi}{piq} 至少有一个与查询图像匹配的正确项。
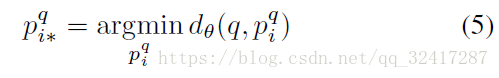
得到损失函数
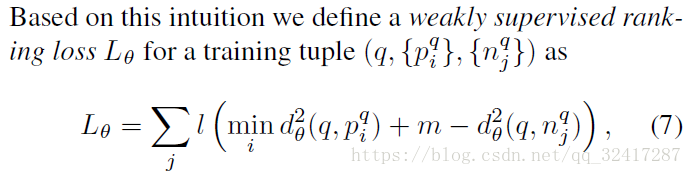
l(x)=max(x,0)" role="presentation" style="position: relative;">l(x)=max(x,0)l(x)=max(x,0)
if the margin between the distance to the negative image and to the best matching positive is violated, the loss is proportional to the amount of violation.
通过随机梯度下降的方法训练得到 fθ" role="presentation" style="position: relative;">fθfθ
Experiments
Datasets and evaluation methodology
datasets:
- Pittsburgh (Pitts250k)
- Tokyo 24/7
- Evaluation metric
Implementation details:
- two base architectures: AlexNet and VGG-16
- both are cropped at the last convolutional layer (conv5), before ReLU
- K = 64 resulting in 16k and 32k-D image representations for the two base architectures, respectively
Results and discussion
- Baselines and state-of-the-art.
- Dimensionality reduction. PCA and whitening followed by L2-normalization
- Benefits of end-to-end training for place recognition: first, our approach can learn rich yet compact image representations for place recognition. second, the popular idea of using pretrained networks “off-the-shelf” is sub-optimal as the networks trained for object or scene classification are not necessary suitable for the end-task of place recognition. 在分类任务上预训练的网络对于图像检索任务不是最好的
- Comparison with state-of-the-art.
- VLAD versus Max.
- Which layers should be trained?
- Importance of Time Machine training
Qualitative evaluation
Image retrieval
Conclusions
提出了一种端到端的学习方式进行地点识别,使用的是卷积神经网络,数据集(Street View Time Machine data)是弱监督的。
两个重要的组件:
- the NetVLAD pooling layer
- weakly supervised ranking loss
NetVLAD可以容易地用于其他的CNN结构中。
The weakly supervised ranking loss 作用很大 opens up the possibility of end-to-end learning for other ranking tasks where large amounts of weakly labelled data are available, for example, images described with natural language
paper: NetVLAD: CNN architecture for weakly supervised place recognition
文章来源:https://blog.csdn.net/zshluckydogs/article/details/82415393
关键词:NetVLAD Pooling layer triplet-loss fmax function weakly-supervised-learning
摘要:
针对大规模的位置识别问题(place recognition),本文设计了一种NetVLAD结构,在保留经典VLAD算法优点的同时又可以利用神经网络可以反馈学习参数的优点,从而生成即优于VLAD图像描述子又优于神经网络的原始feature-map层特征向量的图像描述子。在Oxford 5k Paris 6k Holidays 上的mAP分别是63.5%,73.5%,79.9%,其中对Oxford 5k的提升达到了20%,可以说是一种很优秀的算法了。
补充两点:一、关于vlad可以参考我的博客https://blog.csdn.net/zshluckydogs/article/details/81003966。
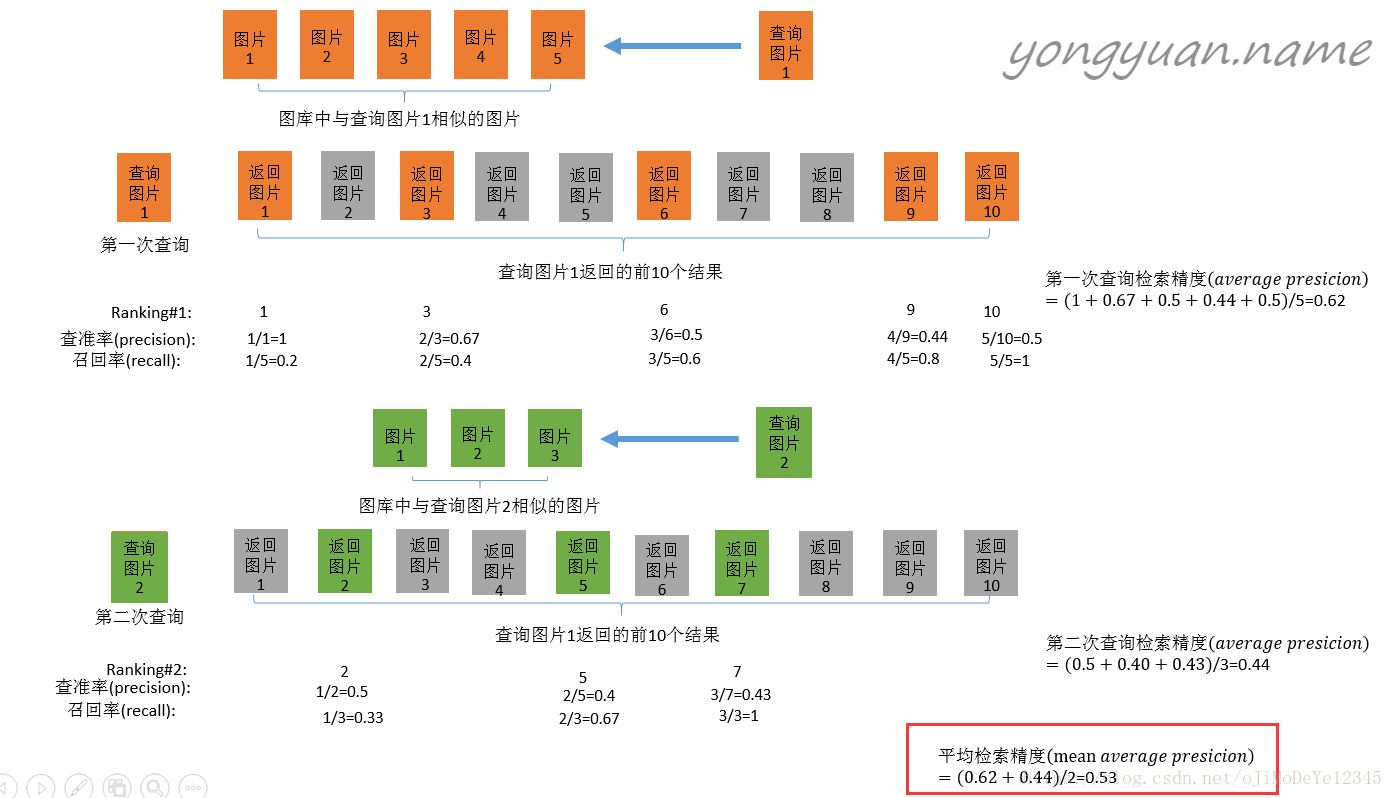
二、MAP(Mean Average Precision)盗一张图
写在前面:
本文的主要工作由两部分组成:
1、NetVLAD的结构
2、triplet-loss函数
论文作者转化问题的思想和构造数学模型的能力值得我们学习借鉴。作者没有直接训练识别位置的网络,而是把位置识别问题转化成了基于内容的图像实体检索。虽然这种方法不是作者原创,只是借此说明我们在解决一个很抽象很不熟悉的问题时尽量把它转化为我们熟悉的问题,这样会大大提高解决问题的效率。如果你遇到了一个无法转化从未见过的问题,如果你解决了,那你可以发论文了。。23333
还有就是作者独立思考的能力,VLAD很成熟很多人知道,CNN也是耳熟能详,但是能够把两者结合起来又用来解决实际问题的人就很少了。
上面两段读者可以自行忽略。。。。。。。。。。
进入正题:
第一个问题:为什么是弱监督学习?
这个跟数据集有关。作者训练用的是Google Street View Time Machine,这个数据集中的图像都有一个GPS标签标记图像的地理位置,但是由于精度等问题,这只是地图上的一个较为接近的位置,可能跟实际位置有误差。用过高德、百度地图等导航软件的小伙伴应该有所体会,GPS总是会有些许误差。但是查询图像是通过camera phone得到的,有较为准确的位置信息,所以它可以用来识别距离较近的全景图,但是无法给出部分场景之间的对应关系。(which can be used to identify close-by panoramas but does not provide correspondences between parts of the depicted scenes.)原文在括号内,博主是这样理解的,有不同理解的可以跟博主讨论。因此,在地理位置上接近的两张图像,由于拍摄角度和遮挡问题,图像的内容可以不同,但只要有相同的GPS位置标记即可。这区别于传统的图像检索算法要求图像内容必须是相同的,所以GPS标记的样本数据只能做弱监督的学习,提供潜在的正样本(和查询图像在地理位置上接近的样本)和确定的负样本(和查询图像在地理位置上相距甚远的样本)。
第二个问题:VLAD有什么参数是可以学习的?
神经网络的学习过程也即是卷积层参数的自我更新过程。损失函数是对问题模型的数学表示,用来评估一个网络模型的好坏并且控制权值的更新方向(梯度)。最好的模型即是问题的最优解是在损失函数取得最优解时得到的(此时网络收敛)。
对于VLAD当我们通过K-means训练出码书时已经完成了相应的最优化问题,此时得到的K-centroids是一个最优解。如果要把VLAD加入到CNN网络中,那么VLAD必须写成可微的函数,并且要设计新的损失函数用来评估模型和参数学习。对于VLAD算法来说,向量 V 如果和第k个聚类中心的距离最近,他就会被分配到k,这是一个0或1的硬分配,不可微。为了解决这个问题作者提出了一种soft-assignment的算法。
公式如下:
(1)
如果你对softMax函数有所了解的话,这个公式是很容易理解的。虽然xi仍然是分配到了它最有可能属于的聚类中心,但是这个用来判断属于关系的数值变成了一个连续可微的值,满足CNN反馈学习的要求。
我们对公式(1)展开令,
,公式(1)可以写成如下公式(2)
(2)
VLAD就可以写成下面公式(3)的形式
(3)
参数,可以通过网络训练学习得到,然后之后的处理步骤与VLAD类似。然后公式(3)可以看作一个卷积层加一个softMax层。
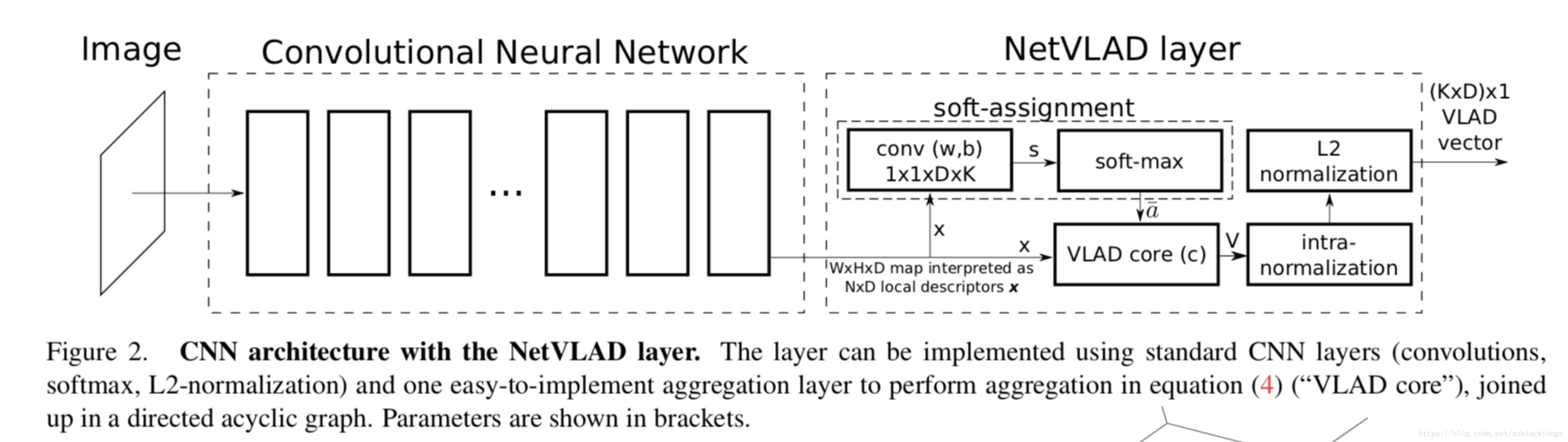
上图是NetVLAD的框架图,左边是一个传统的卷积神经网络,但是没有分类层,在卷积层后接NetVLAD layer,来自CNN的featureMap x 输入到NetVLAD layer中,做一次卷积和soft-max得到x的最可能属于的聚类中心,然后在VLAD core中按照VLAD的方式对x进行处理。最后做两次归一化得到最终的VLAD特征向量。
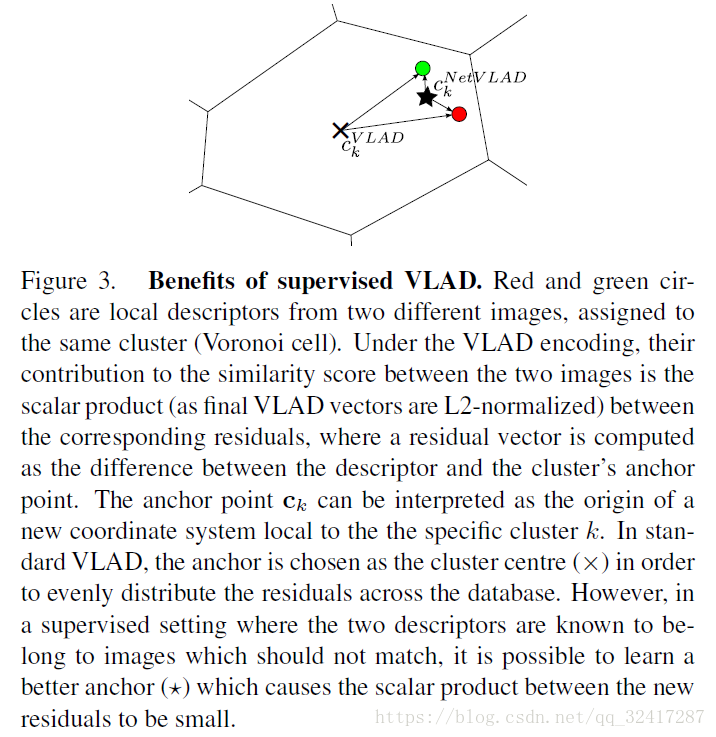
Conclude: NetVLAD层的W和b可以通过网络学习得到。W和b又跟聚类中心有关,所以网络最终是通过调整聚类中心的值完成参数的学习调整。相当于在原来做完K-means的基础上进一步的优化调整。
第三个问题:loss-function
确切的损失函数可以进行参数的调整,以及模型的调优。类似face Net的三元组损失函数,作者提出了triplet-loss-function,查询图像和潜在正样本的距离小于和确定的负样本的距离。用公式(5)描述如下:
(4)
(5)
(6)
因为潜在的正样本有很多,为了避免冲突和麻烦,我们选取和查询图像距离最近的正样本,损失函数可以写成公式(6)的形式,,m 是一个常数,之后通过优化
训练网络学习参数。
至此,整个网络的训练过程就完整了。
博主实现后会写具体的实施部署过程。
[place recognition]NetVLAD: CNN architecture for weakly supervised place recognition 论文翻译及解析(转)的更多相关文章
- [CVPR2017] Deep Self-Taught Learning for Weakly Supervised Object Localization 论文笔记
http://openaccess.thecvf.com/content_cvpr_2017/papers/Jie_Deep_Self-Taught_Learning_CVPR_2017_paper. ...
- [CVPR2017] Weakly Supervised Cascaded Convolutional Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #042eee } p. ...
- 2018年发表论文阅读:Convolutional Simplex Projection Network for Weakly Supervised Semantic Segmentation
记笔记目的:刻意地.有意地整理其思路,综合对比,以求借鉴.他山之石,可以攻玉. <Convolutional Simplex Projection Network for Weakly Supe ...
- [CVPR 2016] Weakly Supervised Deep Detection Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- Robust Tracking via Weakly Supervised Ranking SVM
参考文献:Yancheng Bai and Ming Tang. Robust Tracking via Weakly Supervised Ranking SVM Abstract 通常的算法:ut ...
- [ICCV 2019] Weakly Supervised Object Detection With Segmentation Collaboration
新在ICCV上发的弱监督物体检测文章,偷偷高兴一下,贴出我的poster,最近有点忙,话不多说,欢迎交流- https://arxiv.org/pdf/1904.00551.pdf http://op ...
- 深度学习论文翻译解析(二):An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
论文标题:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- 深度学习论文翻译解析(十一):OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
论文标题:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 标题翻译: ...
随机推荐
- 使用MAT分析Java内存
Overview MAT(Memory Analyzer Tool) 是一个JAVA Heaper分析器,可以用来分析内存泄露和减少内存消耗.分析Process showmap中的/dev/ashme ...
- kerberos认证协议分析
Kerberos认证协议分析 Kerberos认证协议流程 如上图: * 第一步:client和认证服务器(AS)通信完成认证过程,如果认证成功AS返回给client一个TGT(用来向TGS获取tic ...
- 11.事件驱动events
事件驱动events ==> events.EventEmitter, EventEmitter 的核心就是事件发射与事件监听器功能的封装更详细的 API 文档参见 http://nodejs. ...
- java获取年份的第一天和最后一天
Calendar cal = Calendar.getInstance();cal.set(Calendar.MONTH, 0);cal.set(Calendar.DATE, 1);String da ...
- 浙江工业大学校赛 画图游戏 BugZhu抽抽抽!!
BugZhu抽抽抽!! Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Tota ...
- nginx+lua构建简单waf网页防火墙
需求背景 类似于论坛型的网站经常会被黑掉,除了增加硬件防护感觉效果还是不太好,还会偶尔被黑,waf的功能正好实现了这个需求. waf的作用: 防止sql注入,本地包含,部分溢出,fuzzing测试,x ...
- 禁止输入emoji表情
三个文本框textField UITextView都要禁止苹果自带emoji 后来发现是原来写的方法不能覆盖所有的表情,新增的表情过滤不掉,只好再加了一个方法 http://www.jianshu.c ...
- web框架们~Django~Flask~Tornado
1.web框架本质 2.Django 3.Flask 4.Tornado
- stark - 分页、search、actions
一.分页 效果图 知识点 1.分页 {{ showlist.pagination.page_html|safe }} 2.page.py class Pagination(object): def _ ...
- Day06 DOM4J&schema介绍&xPath
day06总结 今日内容 XML解析之JAXP( SAX ) DOM4J Schema 三.XML解析器介绍 操作XML文档概述 1 如何操作XML文档 XML文档也是数据的一种,对数据的 ...