Meanshift均值漂移算法
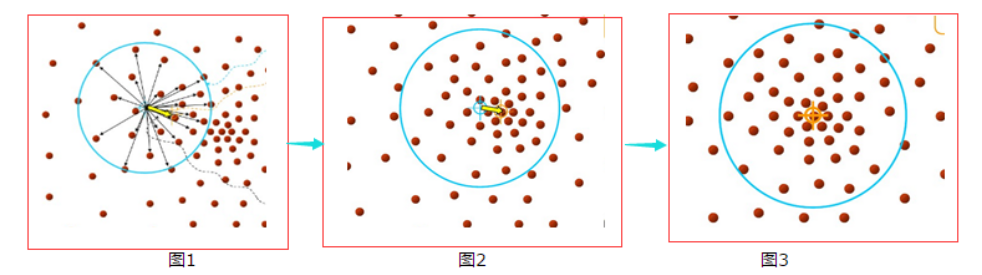
#坐标轴负一问题
plt.rcParams['axes.unicode_minus'] =False
#分割数据集
from sklearn.model_selection import train_test_split
data=pd.read_csv('./贝叶斯.csv',header=None)
print(data.shape) #显示几行几列
#拆分数据
dataset_X,dataset_y =data.iloc[:,:-1],data.iloc[:,-1]
# print(dataset_X.head())
## 将pandas转为np.ndarray 可以用dataset = df.as_matrix()
dataset_X =dataset_X.values
dataset_y =dataset_y.values
#估算带宽
from sklearn.cluster import estimate_bandwidth,MeanShift
# estimate_bandwidth有估计带宽的意思 n_clusters聚类的个数 quantile分位数,分位点
bandwidth = estimate_bandwidth(dataset_X,quantile=0.1,n_samples=len(dataset_X))
#打印出带宽
print(bandwidth).
#初始化聚类模型 bandwidth:带宽 bin_seeding网格化数据点(加速模型)
meanshift = MeanShift(bandwidth=bandwidth,bin_seeding=True)
# 训练模型
meanshift.fit(dataset_X)
print(meanshift.cluster_centers_)
print(meanshift.labels_)
此时打印除掉数据如下,

#最后一步,将图形绘制出,查看一下效果
def visual_meanshift_effect(meanshift,dataset):
assert dataset.shape[1]==2,'only support dataset with 2 features'
X=dataset[:,0]
Y=dataset[:,1]
X_min,X_max=np.min(X)-1,np.max(X)+1
Y_min,Y_max=np.min(Y)-1,np.max(Y)+1
X_values,Y_values=np.meshgrid(np.arange(X_min,X_max,0.01),
np.arange(Y_min,Y_max,0.01))
# 预测网格点的标记
predict_labels=meanshift.predict(np.c_[X_values.ravel(),Y_values.ravel()])
predict_labels=predict_labels.reshape(X_values.shape)
plt.figure()
plt.imshow(predict_labels,interpolation='nearest',
extent=(X_values.min(),X_values.max(),
Y_values.min(),Y_values.max()),
cmap=plt.cm.Paired,
aspect='auto',
origin='lower')
# 将数据集绘制到图表中
plt.scatter(X,Y,marker='v',facecolors='none',edgecolors='k',s=30)
# 将中心点绘制到图中
centroids=meanshift.cluster_centers_
plt.scatter(centroids[:,0],centroids[:,1],marker='o',
s=100,linewidths=2,color='k',zorder=5,facecolors='b')
plt.title('MeanShift effect graph')
plt.xlim(X_min,X_max)
plt.ylim(Y_min,Y_max)
plt.xlabel('feature_0')
plt.ylabel('feature_1')
plt.show()
visual_meanshift_effect(meanshift,dataset_X)
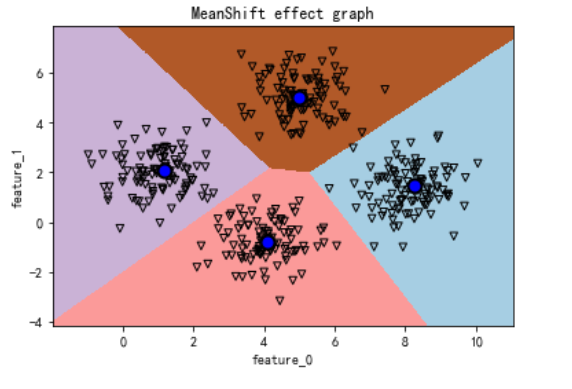
Meanshift均值漂移算法的更多相关文章
- opencv2对读书笔记——使用均值漂移算法查找物体
一些小概念 1.反投影直方图的结果是一个概率映射,体现了已知图像内容出如今图像中特定位置的概率. 2.概率映射能够找到最初的位置,从最初的位置開始而且迭代移动,便能够找到精确的位置,这就是均值漂移算法 ...
- opecv2 MeanShift 使用均值漂移算法查找物体
#if !defined OFINDER #define OFINDER #include <opencv2\core\core.hpp> #include <opencv2\img ...
- 使用Opencv中均值漂移meanShift跟踪移动目标
Mean Shift均值漂移算法是无参密度估计理论的一种,无参密度估计不需要事先知道对象的任何先验知识,完全依靠训练数据进行估计,并且可以用于任意形状的密度估计,在某一连续点处的密度函数值可由该点邻域 ...
- Opencv均值漂移pyrMeanShiftFiltering彩色图像分割流程剖析
meanShfit均值漂移算法是一种通用的聚类算法,它的基本原理是:对于给定的一定数量样本,任选其中一个样本,以该样本为中心点划定一个圆形区域,求取该圆形区域内样本的质心,即密度最大处的点,再以该点为 ...
- kmeans均值聚类算法实现
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
随机推荐
- arcgis point 随着 line类型的轨迹运动的动画
animate : function(frampoint,topoint,speed = 60){ var path = topoint.geometry.paths[0]; var i = 1; v ...
- urllib、urllib2、urllib3区别和使用
python3中把urllib和urllib合并为一个库了,urllib对应urllib.request 1.) python 中最早内置拥有的网络请求模块就是 urllib,我们可以看一下 urll ...
- 自然语言推断(NLI)、文本相似度相关开源项目推荐(Pytorch 实现)
Awesome-Repositories-for-NLI-and-Semantic-Similarity mainly record pytorch implementations for NLI a ...
- jquery中checkbox的选中,反选,全不选 注意1.6版本以上将attr改成prop
<script type="text/javascript"> $(function () { // 全选 $("#btnCheckAll").bi ...
- VS2019正式版注册码秘钥
Visual Studio 2019 EnterpriseBF8Y8-GN2QH-T84XB-QVY3B-RC4DF Visual Studio 2019 ProfessionalNYWVH-HT4X ...
- pytorch之张量的理解
张量==容器 张量是现代机器学习的基础,他的核心是一个容器,多数情况下,它包含数字,因此可以将它看成一个数字的水桶. 张量有很多中形式,首先让我们来看最基本的形式.从0维到5维的形式 0维张量/标量: ...
- step_by_step_用python爬点磁力链接
爬点东西 -Scrapy 今天是小年,团聚的日子,想想这一年中发生过大大小小的事,十分感慨. 言归正传: 吐槽了一些话,没事的时候一个单身老男人就只能上上网打发打发时间,后来我发现一个网站比较好,但是 ...
- freeswitch dialplan 基础
freeswitch dialplan 基础 一.基础概念 dialplan 拨号方案 context 拨号表(块) extension 拨号去向 action (拨号后执行的)动作 condit ...
- html转化为图片下载
业务需求:按照客户要求把排课表转化为图片下载到本地.一个月到排课有很多.所以图片会很大 <!DOCTYPE html> <html lang="en"> & ...
- 100-days: twenty
Title: Apple's 'show time(好戏开幕)' event(发布会) puts the spotlight on subscription services Apple's 'sho ...