数据挖掘---Numpy的学习


什么是Numpy
NumPy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵(任意维度的数据处理),比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。
数据类型ndarray
NumPy provides an N-dimension array type, the ndarray, which describes a collection of ‘items’of the same type.
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。
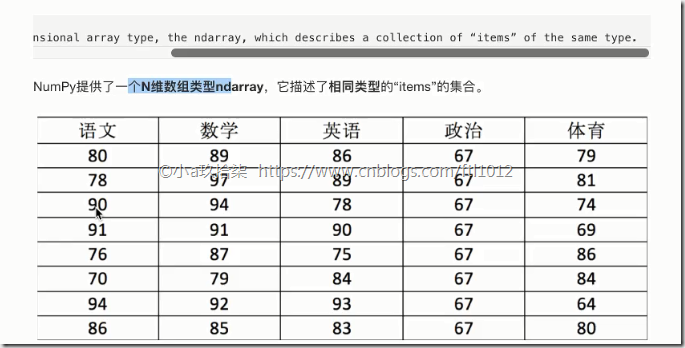
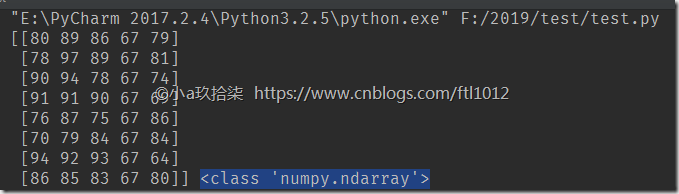
import numpy as np score = np.array([
[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]]) print(score, type(score)) #<class 'numpy.ndarray'>
ndarray与Python原生list运算效率对比
import numpy as np
import random
import time
# 生成一个大数组
python_list = [] for i in range(100000000):
python_list.append(random.random()) ndarray_list = np.array(python_list)
len(ndarray_list) # 原生pythonlist求和
t1 = time.time()
a = sum(python_list)
t2 = time.time()
d1 = t2 - t1
print(d1) # 0.7309620380401611 # ndarray求和
t3 = time.time()
b = np.sum(ndarray_list)
t4 = time.time()
d2 = t4 - t3
print(d2) # 0.12980318069458008
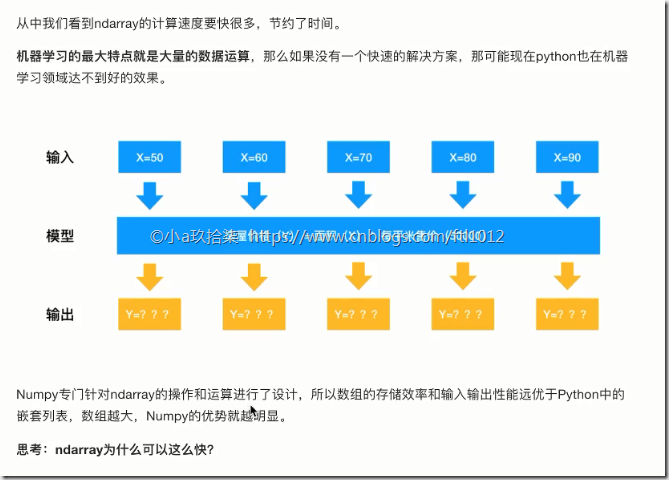
Numpy优势:
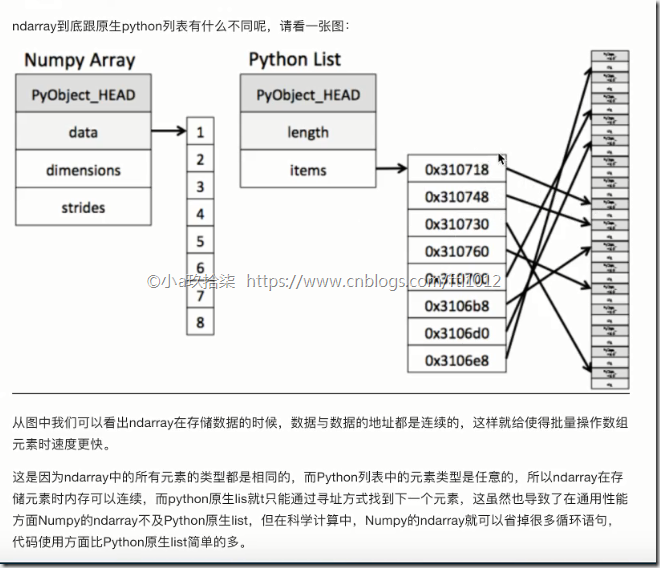
1)存储风格
ndarray - 相同类型 - 通用性不强 - 数据是连续性的存储
list - 不同类型 - 通用性很强 - 引用的方式且不连续的堆空间存储
2)并行化运算
ndarray支持向量化运算
3)底层语言
C语言,解除了GIL
1、内存块风格
2、ndarry支持并行化运算
3、Numpy底层是C编程,内部解除了GIL(全局解释器锁--实际上只有一个线程)的限制

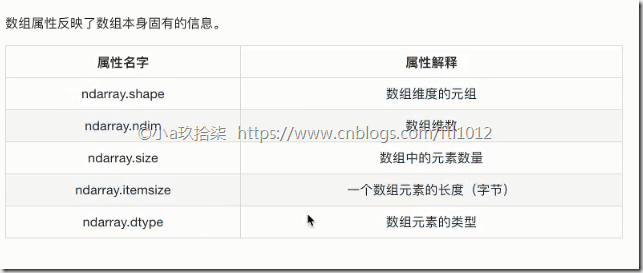
认识N维数组的属性-ndarry的属性(shape+dtype)
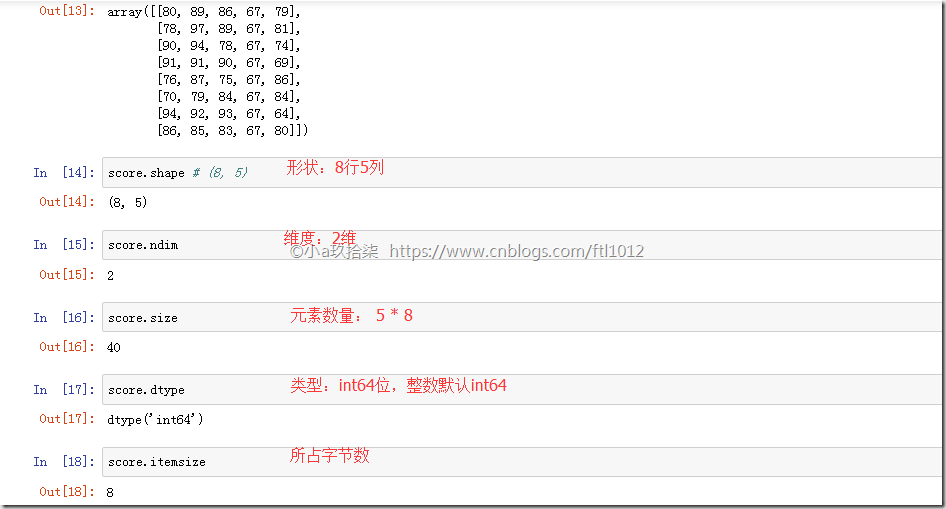
ndarry形状
import numpy as np
# 利用元组表示维度(2,3)2个数字代表2维,具体代表2行3列
a = np.array([[1, 2, 3], [4, 5, 6]])
# (4,)1维用1个数字表示,表示元素个数,为了表示为一个元组,我们会添加一个,
b = np.array([1, 2, 3, 4])
# (2,2,3),最外层2个二维数组,2维数组内又嵌套了2个一维数组,一个一维数组又有3个元素
c = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
如何理解数组的形状?
二维数组实际上是在一维数组内嵌套多个一维数组
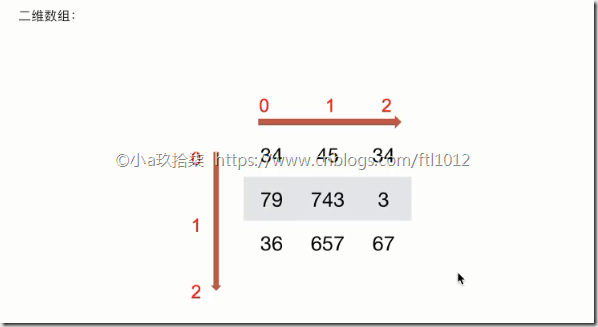
三维数组实际上是在一维数组内嵌套多个二维数组
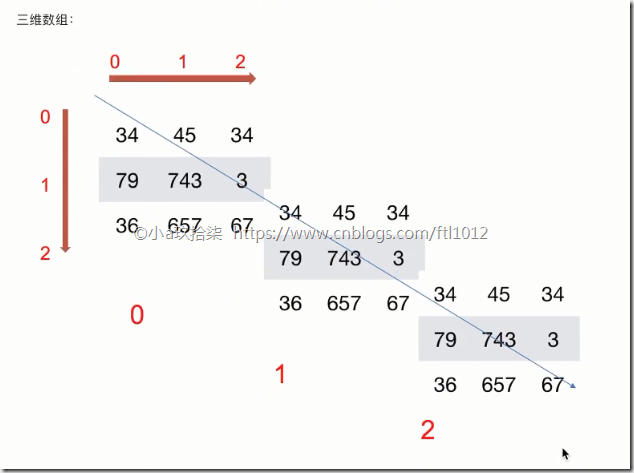
ndarry的类型
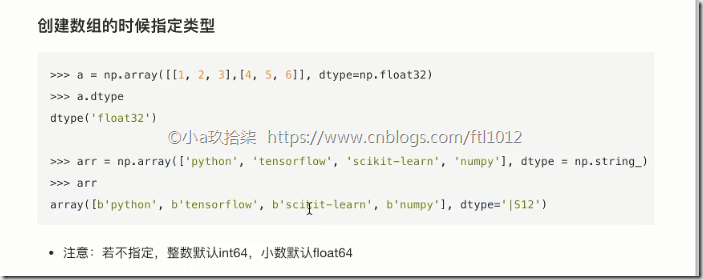
在创建ndarray的时候,如果没有指定类型
默认整数 int64
默认浮点数 float64
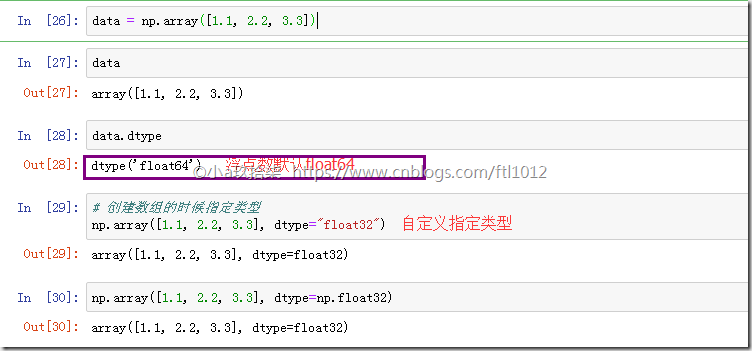
创建数组的时候指定类型
import numpy as np # 创建数组的时候指定类型(1)
t = np.array([1.1, 2.2, 3.3], dtype=np.float32)
# 创建数组的时候指定类型(2)
tt = np.array([1.1, 2.2, 3.3], dtype="float32")
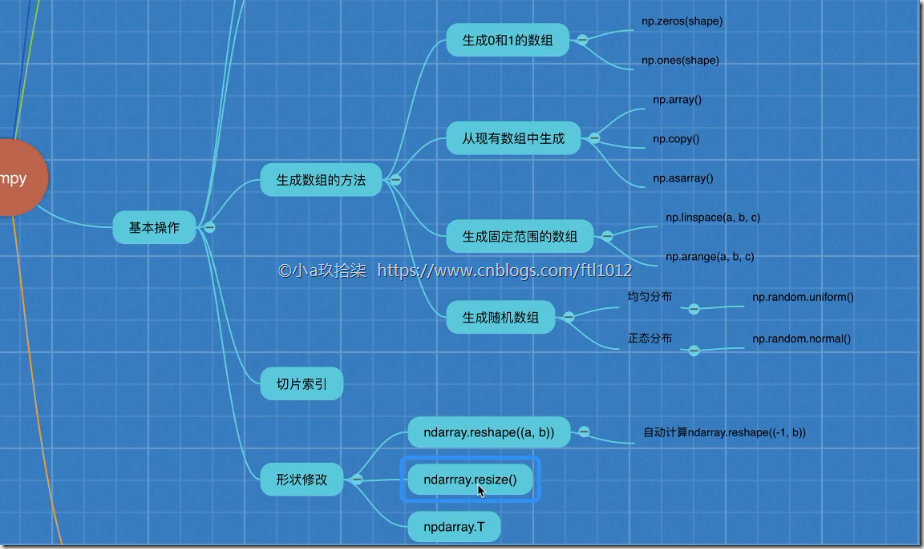
基本操作
生成数组的方法
生成数组的方法(4种类型)
1)生成0和1
np.zeros(shape)
np.ones(shape)
2)从现有数组中生成
np.array() np.copy() 深拷贝
np.asarray() 浅拷贝
3)生成固定范围的数组
np.linspace(0, 10, 100)
[0, 10] 等距离np.arange(a, b, c)
range(a, b, c)
[a, b) c是步长
4)生成随机数组
分布状况 - 直方图
1)均匀分布
每组的可能性相等
2)正态分布
σ 幅度、波动程度、集中程度、稳定性、离散程度
1、生成0和1的数组

import numpy as np # 1 生成0和1的数组
t = np.zeros(shape=(3, 4), dtype="float32")
tt = np.ones(shape=[2, 3], dtype=np.int32)
2 从现有数组生成
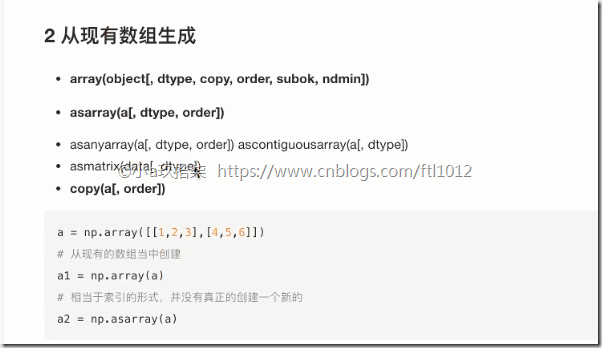
import numpy as np
# 方法一:np.array()
score = np.array([[80, 89, 86, 67, 79],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]]) # 方法二:np.copy()
ttt = np.copy(score) # 方法三:np.asarray()
tttt = np.asarray(ttt)
区别:
np.array() np.copy() 深拷贝
np.asarray() 浅拷贝
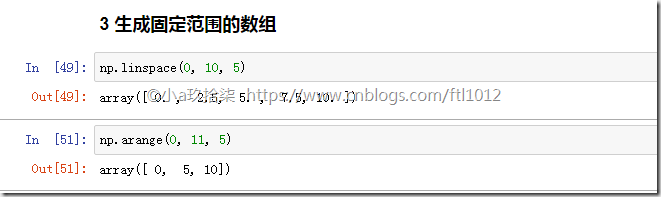
3 生成固定范围的数组
np.linspace(0, 10, 100)
[0, 10] 左闭右闭的等距离输出100个数字np.arange(a, b, c)
[a, b) 左闭右开的步长为c的数组
4 生成随机数组( 分布状况 - 直方图)
1)均匀分布
每组的可能性相等
2)正态分布
σ 幅度、波动程度、集中程度、稳定性、离散程度
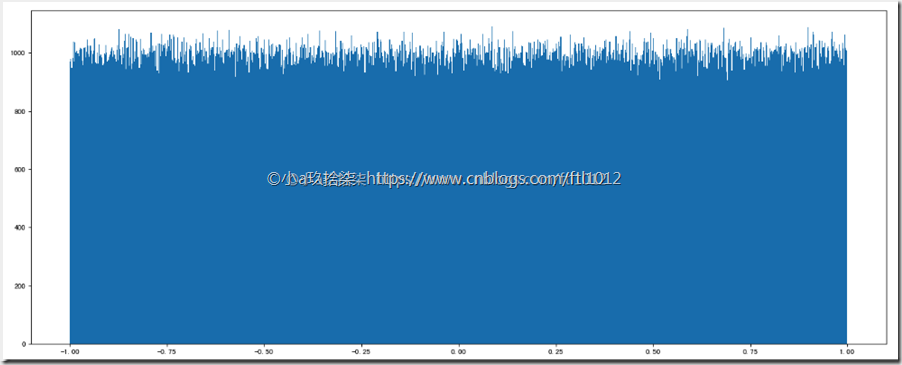
1、均匀分布:出现的概率一样

import numpy as np
import matplotlib.pyplot as plt # 均匀分布:
data1 = np.random.uniform(low=-1, high=1, size=1000000) # 1、创建画布
plt.figure(figsize=(8, 6), dpi=100)
# 2、绘制直方图
plt.hist(data1, 1000)
# 3、显示图像
plt.show()
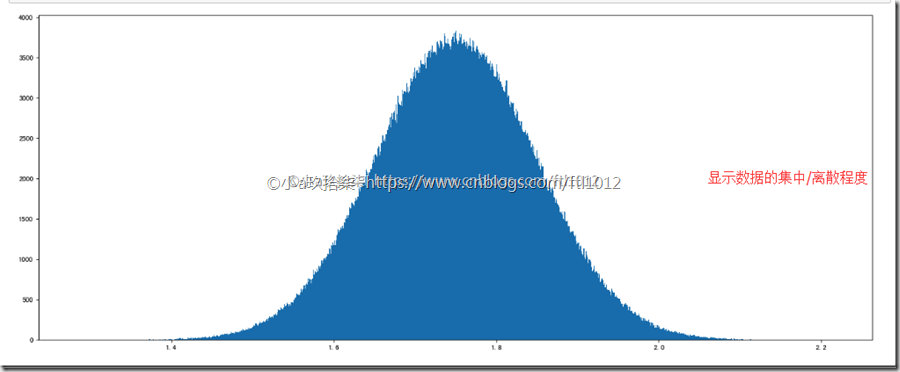
2、正太分布
方差是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。标准差越小,数据越集中。


demo:
import numpy as np
import matplotlib.pyplot as plt # 正太分布
data2 = np.random.normal(loc=1.75, scale=0.1, size=1000000) # 1、创建画布
plt.figure(figsize=(20, 8), dpi=80) # 2、绘制直方图
plt.hist(data2, 1000) # 3、显示图像
plt.show()
数组的索引与切片
demo:
import numpy as np def slice_index():
'''
一维修改:
'''
arr = np.array([12, 32, 31])
arr[0]=2
print(arr) '''
二维修改:
'''
arr2 = np.array([[12, 2], [43, 3]])
arr2[0, 0] = 22 # 修改[12, 2]为[22, 2]
print(arr2) '''
三维修改:
'''
arr3 = np.array(
[[[1, 2, 3],
[4, 5, 6]], [[12, 3, 34],
[5, 6, 7]]]
) # 3个[,表示3维数组,内又2个2维数组,1个二维数组有2个1维数组,1个一维数组又3个数字,古(2,2,3) arr3[1, 0, 2] = 22 # 修改[12, 3, 34]为[12, 3, 22]
print(arr3)
print(arr3[1, 1, :2]) # 5,6 # 取出前2个 if __name__ == '__main__':
# 切片与索引
slice_index()
形状改变
ndarray.reshape(shape) 返回新的ndarray,原始数据没有改变,且仅仅是改变了形状,未改变行列. ndarry.reshape(-1,2) 自动变形
ndarray.resize(shape) 没有返回值,对原始的ndarray进行了修改,未改变行列
ndarray.T 转置 行变成列,列变成行
demo:
import numpy as np def np_change():
arr3 = np.array(
[[1, 2, 3], [4, 5, 6]]
) # (2, 3)
'''
方式一:
reshape: 返回一个新的ndarry, 且不改变原ndarry,且仅仅是改变了形状,未改变行列
[[1 2]
[3 4]
[5 6]]
'''
arr4 = arr3.reshape((3, 2))
print(arr3.shape) # (2, 3)
print(arr4.shape) # (3, 2) '''
方式二:
resize: 没有返回值,对原始的ndarray进行了修改,未改变行列
[[1 2 3 1 2 3]]
'''
arr3.resize((1, 6))
print(arr3) # (1, 6) '''
方式三:
T: 进行行列的转置,把行数据转换为列,列数据转换为行
[[1 3 5]
[2 4 6]]
'''
print(arr4.T) if __name__ == '__main__':
# 改变形状
np_change()
类型的修改
ndarray.astype(type)
ndarray 序列化到本地 --》ndarray.tostring():实现序列化
import numpy as np def type_change():
'''
ndarry的类型修改一: astype('float32')
'''
arr3 = np.array(
[[1, 2, 3], [4, 5, 6]]
) # (2, 3)
arr4 = arr3.astype("float32") # int转换为float
print(arr3.dtype) # int32
print(arr4.dtype) # float32 '''
ndarry的类型修改二: 利用tostrint()序列化
''' arr5 =arr3.tostring() # 序列化 \x01\x00\x00\x00
print(arr5) if __name__ == '__main__':
# 类型形状
type_change()
数组去重
set

import numpy as np def type_change():
'''
ndarry的去重
'''
temp = np.array([[1, 2, 3, 4], [3, 4, 5, 6]])
# 方法一: unique()
np.unique(temp)
print('利用unique去重:', temp) # [3 4 5 6]] temp2 = np.array([[1, 2, 3, 4], [3, 4, 5, 6]])
# 方法二: set的要求是数组必须是一维的,利用flatten()进行降维
set(temp2.flatten())
print('利用set进行降维后:', temp2) # [3 4 5 6]] if __name__ == '__main__':
# ndarry的去重
type_change()
小结:
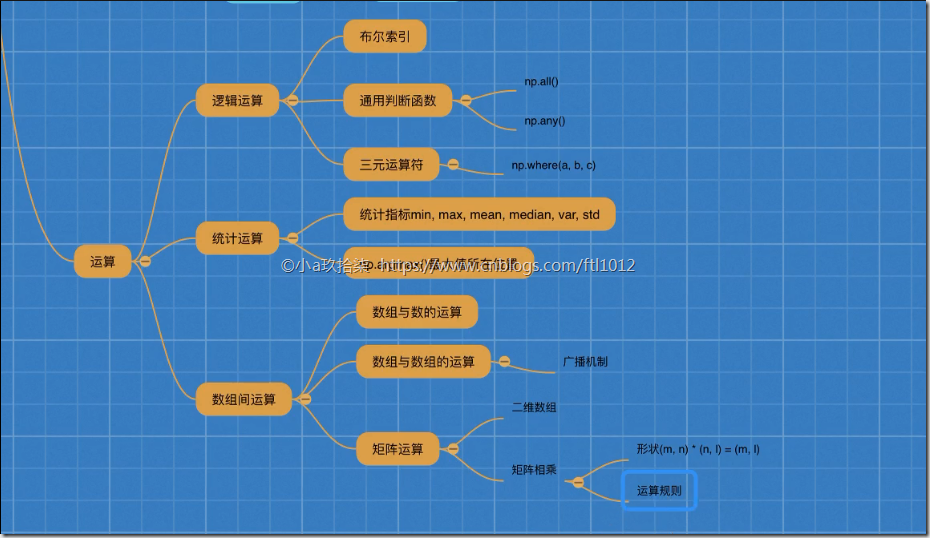
ndarray的运算(逻辑运算+统计运算+数组运算)
1、逻辑运算
布尔索引
通用判断函数
np.all(布尔值)
只要有一个False就返回False,只有全是True才返回True
np.any()
只要有一个True就返回True,只有全是False才返回False
np.where(三元运算符)
np.where(布尔值, True的位置的值, False的位置的值)
- 布尔索引
import numpy as np def demo():
'''
逻辑运算
'''
temp = np.array([[1, 2, 3, 4], [3, 4, 5, 6]])
# 判断temp里面的元素是否大于5(temp > 5)就标记为True 否则为False:
print(temp > 5) # 找到数值大于等于5的数字
print(temp[temp >= 5]) # [5 6] # 找到数值大于等于5的数字,并统一赋值为100
temp[temp >= 5] = 100
print(temp) if __name__ == '__main__':
# 逻辑运算 -- 布尔索引
demo()
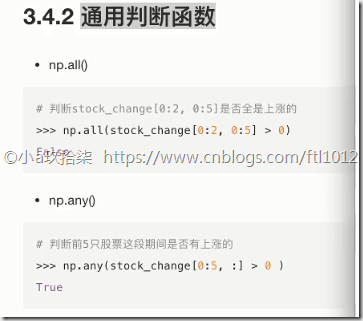
- 通用判断函数
np.all(布尔值)
只要有一个False就返回False,只有全是True才返回True
np.any()
只要有一个True就返回True,只有全是False才返回False
import numpy as np def demo():
'''
通用判断函数
'''
temp = np.array([[1, 2, 3, 4], [3, 4, 5, 6]])
# np.all(): 只要有一个False就返回False,只有全是True才返回True
print(np.all(temp > 5)) # False
print(np.all(temp < 15)) # True # np.any(): 只要有一个True就返回True,只有全是False才返回False
print(np.any(temp > 5)) # True if __name__ == '__main__':
# 逻辑运算 -- 通用判断函数
demo()
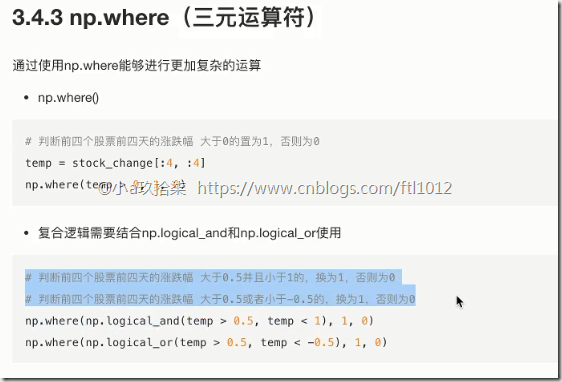
- 三元运算符
np.where(布尔值, True的位置的值, False的位置的值)
import numpy as np def demo():
'''
三元运算符
'''
temp = np.array([[1, 2, 3, 4], [3, 4, 5, 6]])
# np.where(): np.where(布尔值, True的位置的值, False的位置的值)
print(np.where(temp > 4, 100, -100)) # 如果元素大于4,则置为100,否则置为-100 '''
[[-100 -100 -100 -100]
[-100 -100 100 100]]
''' if __name__ == '__main__':
# 逻辑运算 -- 三元运算符
demo()
配合了逻辑与或非的运算:
import numpy as np def demo():
'''
三元运算符: 配合逻辑与或非运算
'''
temp = np.array([[1, 2, 3, 4], [3, 4, 5, 6]])
# np.logical_and(), np.logical_or(), logical_not()进行与或非运算
print(np.logical_and(temp > 2, temp < 4)) # 进行与运算 print(np.logical_or(temp > 2, temp < 3)) # 进行或运算 print(np.where(np.logical_or(temp > 2, temp < 3), 1, 0)) # 配合了or的where三木运算 print(np.where(np.logical_and(temp > 2, temp < 4), 1, 0)) # 配合了and的where三木运算 '''
[[-100 -100 -100 -100]
[-100 -100 100 100]]
''' if __name__ == '__main__':
# 逻辑运算 -- 三元运算符
demo()
2、统计运算
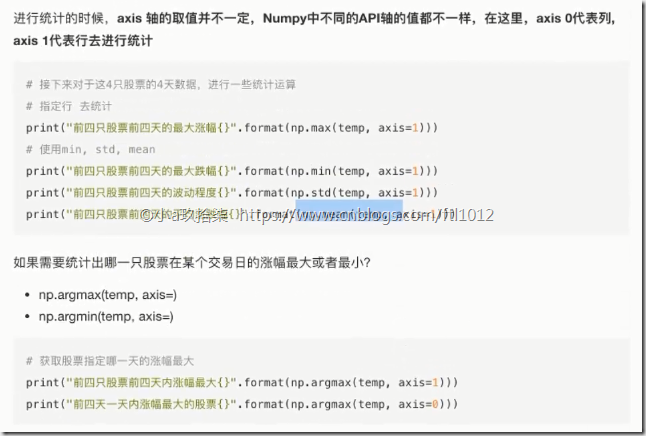
统计指标函数
min, max, mean, median, var, std
np.函数名,例如,arr.max()
ndarray.方法名, 例如,ndarray.max(arr, ) # 需要先指定好元组
返回最大值、最小值所在位置
np.argmax(temp, axis=)
np.argmin(temp, axis=)
- 统计指标函数:需指定好指标

import numpy as np def demo():
'''
统计运算
'''
temp = np.array([[1, 2, 3, 4], [3, 4, 5, 6], [5, 6, 7, 8]])
print(temp.max(axis=0)) # [5 6 7 8], 按照列比较
print(temp.max(axis=1)) # [4 6 8], 按照行比较 print(np.argmax(temp, axis=1)) # [3 3 3], 返回最大值所在的位置
print(np.argmin(temp, axis=1)) # [0 0 0 ], 返回最小值所在的位置 if __name__ == '__main__':
# 统计运算
demo()
3、数组间运算
1. 数组与数的运算
2. 数组与数组的运算
3. 广播机制
4. 矩阵运算
1 什么是矩阵
矩阵matrix 二维数组
矩阵 & 二维数组
两种方法存储矩阵
1)ndarray 二维数组
矩阵乘法:
np.matmul
np.dot
2)matrix数据结构
2 矩阵乘法运算
形状
(m, n) * (n, l) = (m, l)
运算规则
A (2, 3) B(3, 2)
A * B = (2, 2)
1、数组与数的运算
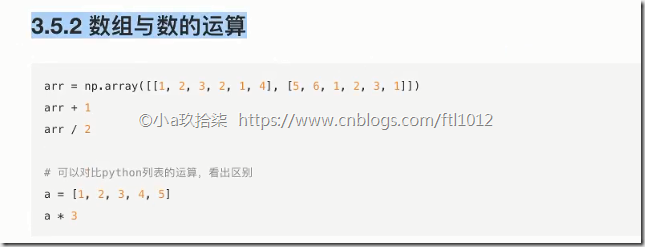
import numpy as np def demo():
'''
数组与数的运算
'''
temp = np.array([[1, 2, 3, 4], [3, 4, 5, 6], [5, 6, 7, 8]])
print(temp + 10)
print(temp * 10) if __name__ == '__main__':
# 数组与数的运算
demo()
2、数组与数组的运算(需满足广播机制)

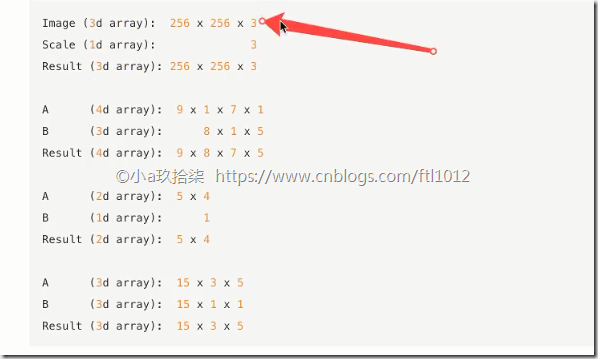
import numpy as np def demo():
'''
数组与数组的运算
'''
arr1 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]]) # 2行6列
arr2 = np.array([[1, 2, 3, 4], [3, 4, 5, 6]]) # 2行4列
arr3 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]]) # 2行6列
arr4 = [2]
# print(arr1 + arr2) could not be broadcast together with shapes (2,6) (2,4)
print(arr1 + arr3)
print(arr1 + arr4) if __name__ == '__main__':
# 数组与数组的运算
demo()
矩阵运算
1 什么是矩阵
矩阵matrix 二维数组
矩阵 & 二维数组 --》矩阵肯定是二维数组形式存储计算机,但是不是所有的二维数组都是矩阵。
两种方法存储矩阵
1)ndarray 二维数组
矩阵乘法:
np.matmul
np.dot
2)matrix数据结构
2 矩阵乘法运算
形状
(m, n) * (n, l) = (m, l)
运算规则
A (2, 3) B(3, 2)
A * B = (2, 2)
1、什么是矩阵
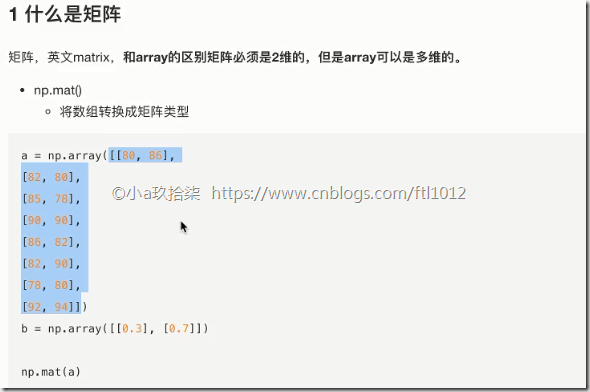
import numpy as np def demo():
'''
矩阵存储方法
'''
# 方案一:ndarray存储矩阵
data = np.array([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
print(type(data)) # <class 'numpy.ndarray'> # 方案二: matrix存储矩阵
data_mat = np.mat([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
print(type(data_mat)) # <class 'numpy.matrix'> if __name__ == '__main__':
# ndarray存储矩阵
demo()
2、矩阵乘法
形状
(m, n) * (n, l) = (m, l)
运算规则
A (2, 3) B(3, 2)
A * B = (2, 2)


import numpy as np def demo():
'''
矩阵乘法API
'''
# 方案一:np.matmul()
data = np.array([[80, 86],
[82, 80],
[78, 80],
[92, 94]]) # (4,2)
weight = np.array([[0.5],
[0.5]]) # (2,1) print(np.matmul(data, weight)) # (4,1) # 方案二: np.dot()
data_mat = np.mat([[80, 86],
[82, 80],
[78, 80],
[92, 94]])
print(np.dot(data_mat, weight)) # (4,1) # 扩展方案: print(data @ weight) # ndarry的直接矩阵计算 if __name__ == '__main__':
# 矩阵乘法API
demo()
合并与分割
合并
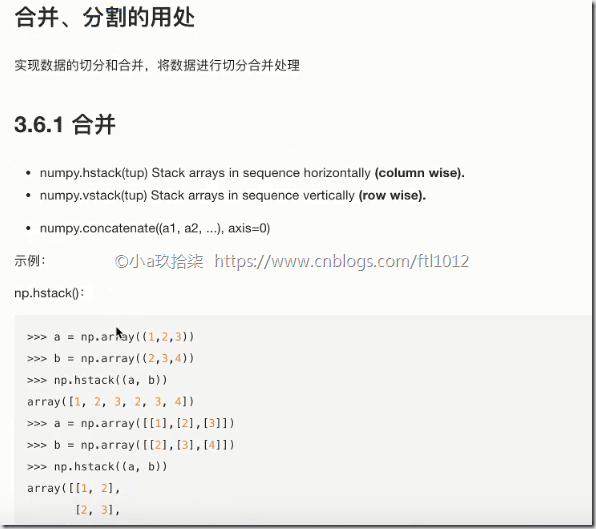
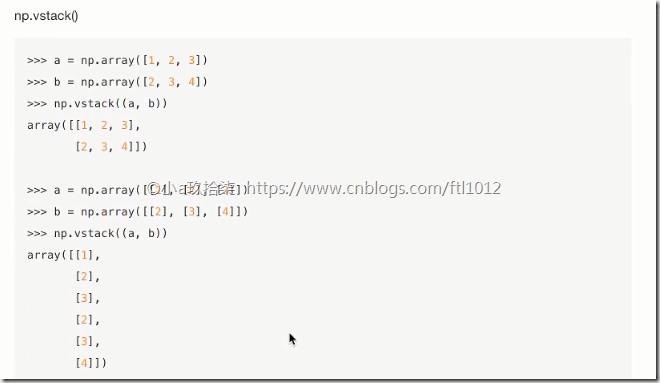
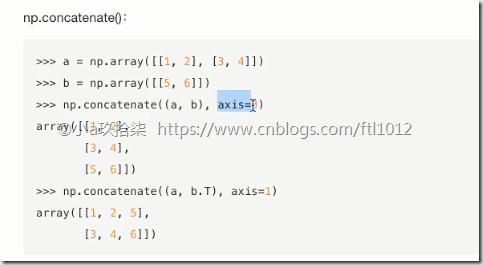
分割

IO操作和数据处理
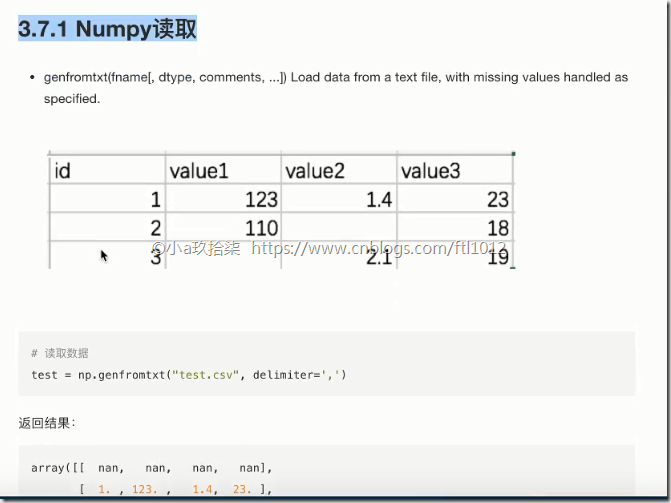
数据准备:test.csv
id,value1,value2,value3
1,123,1.4,23
2,110,,18
3,,2.1,19
demo:
import numpy as np def demo():
'''
# 合并
'''
data = np.genfromtxt("F:\linear\\test.csv", delimiter=",")
print(data) # 把字符串和缺失值用nan记录(not a number)
'''
[[ nan nan nan nan]
[ 1. 123. 1.4 23. ]
[ 2. 110. nan 18. ]
[ 3. nan 2.1 19. ]]
''' if __name__ == '__main__':
# 合并
demo()
缺失值的处理
1. 直接删除含有缺失值的样本
2. 替换/插补
按列求平均,用平均值进行填补

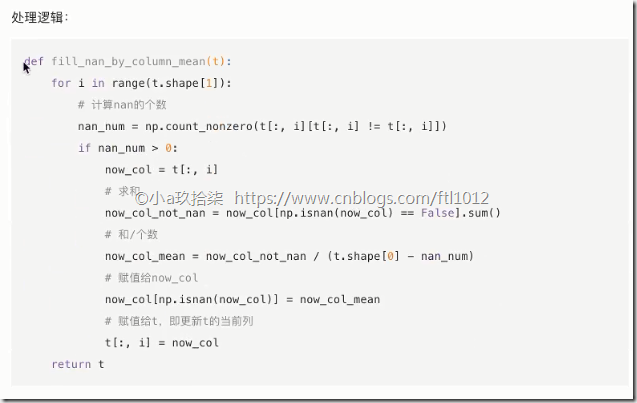
import numpy as np def fill_nan_by_column_mean():
'''
处理缺失值 -- 均值填补
'''
t = np.genfromtxt("F:\linear\\test.csv", delimiter=",")
for i in range(t.shape[1]): # 按照列求平均,先计算数据的shape,看列的数量
# 计算nan的个数
nan_num = np.count_nonzero(t[:, i][t[:, i] != t[:, i]])
if nan_num > 0:
now_col = t[:, i]
# 求和
now_col_not_nan = now_col[np.isnan(now_col) == False].sum()
# 和/个数
now_col_mean = now_col_not_nan / (t.shape[0] - nan_num)
# 赋值给now_col
now_col[np.isnan(now_col)] = now_col_mean
# 赋值给t,即更新t的当前列
t[:, i] = now_col
print(t)
return t if __name__ == '__main__':
# 处理缺失值 -- 均值填补
fill_nan_by_column_mean()

数据挖掘---Numpy的学习的更多相关文章
- Numpy基础学习与总结
Numpy类型学习 1.数组的表示 import numpy as np In [2]: #numpy核心是高维数组,库中的ndarray支持多维数组,同时提供了数值运算,可对向量矩阵进行运算 In ...
- NumPy 数组学习手册·翻译完成
原文:Learning NumPy Array 协议:CC BY-NC-SA 4.0 欢迎任何人参与和完善:一个人可以走的很快,但是一群人却可以走的更远. 在线阅读 ApacheCN 面试求职交流群 ...
- numpy pandas 学习
一. 数组要比列表效率高很多 numpy高效的处理数据,提供数组的支持,python默认没有数组.pandas.scipy.matplotlib都依赖numpy. pandas主要用于数据挖掘,探索, ...
- Hadoop里的数据挖掘应用-Mahout——学习笔记<三>
之前有幸在MOOC学院抽中小象学院hadoop体验课. 这是小象学院hadoop2.X的笔记 由于平时对数据挖掘做的比较多,所以优先看Mahout方向视频. Mahout有很好的扩展性与容错性(基于H ...
- 机器学习如何选择模型 & 机器学习与数据挖掘区别 & 深度学习科普
今天看到这篇文章里面提到如何选择模型,觉得非常好,单独写在这里. 更多的机器学习实战可以看这篇文章:http://www.cnblogs.com/charlesblc/p/6159187.html 另 ...
- Numpy函数学习--genfromtxt函数
genfromtxt函数 今天学习时遇到了genfromtxt函数 world_alcohol = numpy.genfromtxt("world_alcohol.txt",del ...
- Numpy的学习
Numpy numpy(Numerical Python extensions)是一个第三方的Python包,用于科学计算.这个库的前身是1995年就开始开发的一个用于数组运算的库.经过了长时间的发展 ...
- 数据挖掘---Matplotib的学习
什么是matplotlib mat - matrix 矩阵 二维数据 - 二维图表 plot - 画图 lib - libra ...
- numpy.sort()学习记录
python的功能真的是只有我想不到,没有它做不到 在学系np.sort中学到了一些 print(array2) [14 13 12 11] [10 9 8 7] [ 6 5 4 3] print(n ...
随机推荐
- NiftyNet开源平台的使用 -- 配置文件
NiftyNet开源平台的使用 NiftyNet基础架构是使研究人员能够快速开发和分发用于分割.回归.图像生成和表示学习应用程序,或将平台扩展到新的应用程序的深度学习解决方案. 详细介绍请见: ...
- 绝对路径的表示方式为什么是"/usr"而不是"//usr"
今天闲逛贴吧,竟然看到有个人问绝对路径的表示方式为什么不是//usr/local而是/usr/local.原文: 我想99%的人都没想过这个问题,都理所当然的认为:它不就是根"/" ...
- HttpClient+Jsoup模拟登陆贺州学院教务系统,获取学生个人信息
前言 注:可能学校的教务系统已经做了升级,当前的程序不知道还能不能成功获取信息,加上已经毕业,我的账户已经被注销,试不了,在这里做下思路跟过程的记录. 在我的毕业设计中”基于SSM框架贺州学院校园二手 ...
- lambda,linq
一:什么是Lambda表达式 lambda表达式是实例化委托的一个参数,就是一个方法,具体实现如下: { //.NetFramework 1.0-1.1的时候这样应用 NoReturnNoPara m ...
- javascript 小实例,求和的方法sumFn
新年第一记,从这里开始,先来个简单的!去年的知识梳理留下了很多尾巴,原因有很多(知识储量不足,懒了,项目多...) lg:都是借口~ 好吧,我承认,这都是借口,今年一定把尾巴清干净! 下面要写的是 ...
- 本地yum仓库搭建,使用163yum源
如果内部网络没有连接Internet就在本地配置yum仓库 将操作系统镜像上传到服务器中,进行挂载 mount –o loop rhel-server-6.7-x86_64-dvd.iso /mnt ...
- devDependencies与dependencies (转载)
简单整理: 一.关键词解释 devDependencies用于本地环境开发 dependencies用户发布环境 devDependencies是只会在开发环境下依赖的模块,生产环境不会被打入包内.通 ...
- 【LInux】查看Linux系统版本信息
一.查看Linux内核版本命令(两种方法): 1.cat /proc/version [root@S-CentOS home]# cat /proc/versionLinux version 2.6. ...
- java过滤器(简化认证)
最近在看过滤器,刚刚实现了过滤器的简化认证功能: 使用过滤器简化认证: 在Web应用程序中,过滤器的一个关键用例是保护应用程序不被未授权的用户访问.为跨国部件公司开发的客户支持应用程序使用了一种非常原 ...
- Java五种基本的Annotation,提高程序的可读性
从JDK5开始,Java增加了对元数据的支持,也就是Annotation(即注解也被翻译为注释). 这里的Annotation和普通的注释有一定的区别,它是代码中的特殊标记,这些标记可以在编译.类加载 ...