solr 中文分词器IKAnalyzer和拼音分词器pinyin
solr分词过程:
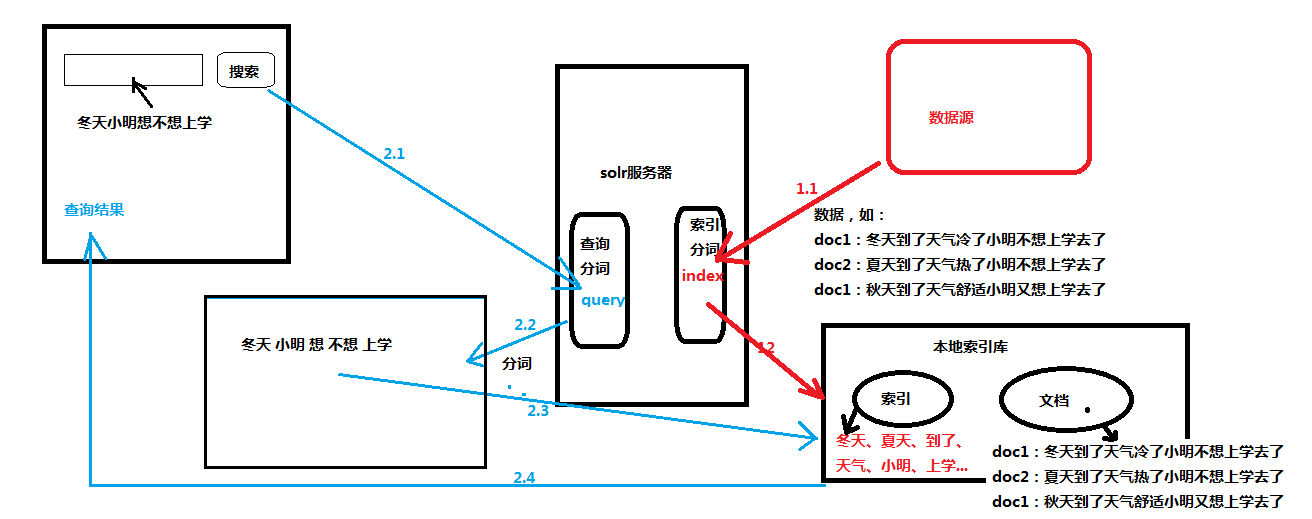
Solr Admin中,选择Analysis,在FieldType中,选择text_en
左边框输入 “冬天到了天气冷了小明不想上学去了”,点击右边的按钮,发现对每个字都进行分词。这不符合中国人的习惯。
solr6.3.0自带中文分词包,在 \solr-6.3.0\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-6.3.0.jar,但是不能自定义词库
好在我们有IKAnalyzer(已无人更新,目前版本是2012)和pinyin分词插件。
IKAnalyzer安装
IKAnalyzer下载地址:https://github.com/EugenePig/ik-analyzer-solr5
因为原始的IKAnalyzer已经不支持solr5以后的版本,这里是修改过后的
用git clone到本地或者直接下载zip到本地,然后执行mvn clean instal(Java8),或者mvn clean -Djavac.src.version=1.7 -Djavac.target.version=1.7 install(jdk1.7)
执行完,在项目 /target 目录下,看到jar文件
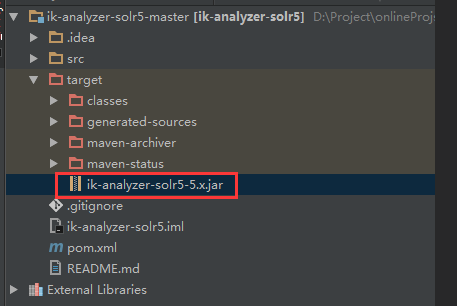
将改jar文件copy到 solr目录:\solr-6.3.0\server\solr-webapp\webapp\WEB-INF\lib
然后修改core的配置文件:\solr-6.3.0\server\solr\test\conf\managed-schema
添加如下配置:
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" />
</analyzer>
</fieldType>
或者
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
保存重启solr,到选择test核心-Analysis,进入分词页面,输入“冬天到了天气冷了小明不想上学去了”,FieldType选择“text_cn”,点击Analyse Value按钮:
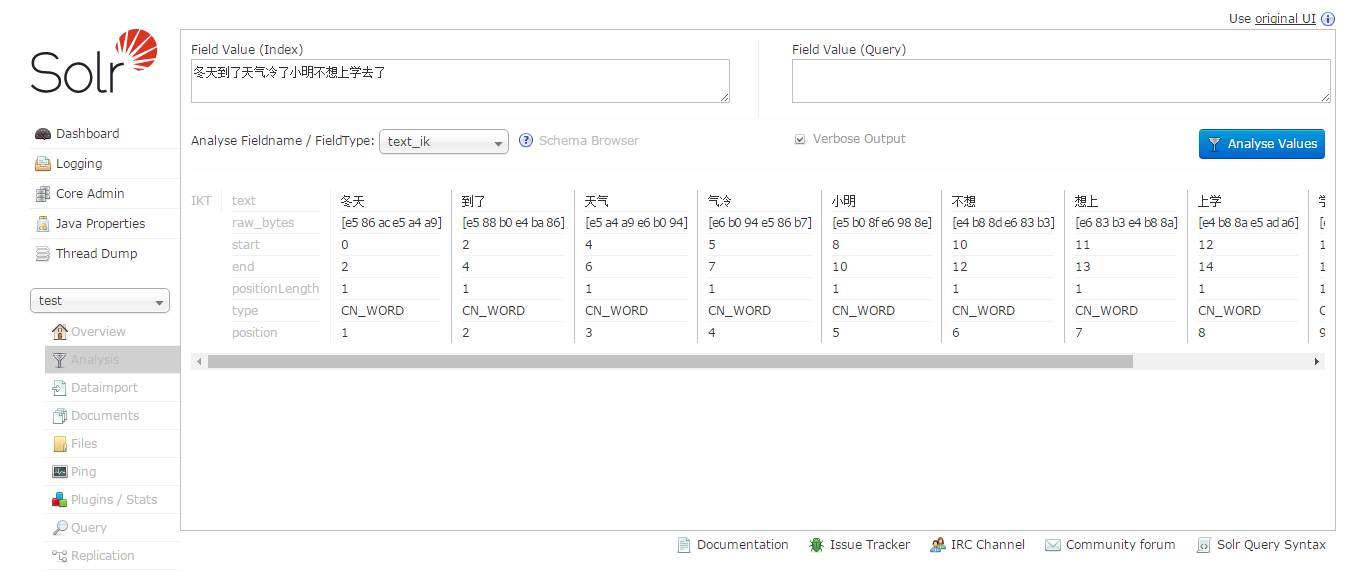
看到已经分词中文成功了。
pinyin安装
pinyin下载地址:http://files.cnblogs.com/files/wander1129/pinyin.zip
下载后将2个jar文件copy到\solr-6.3.0\server\solr-webapp\webapp\WEB-INF\lib目录下,
然后修改core的配置文件:\solr-6.3.0\server\solr\test\conf\managed-schema,添加:
<!-- 配置拼音分词 pinyin-->
<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
</fieldType>
重启solr
到选择test核心-Analysis,进入分词页面,输入“冬天到了天气冷了小明不想上学去了”,FieldType选择“text_pinyin”,点击Analyse Value按钮:
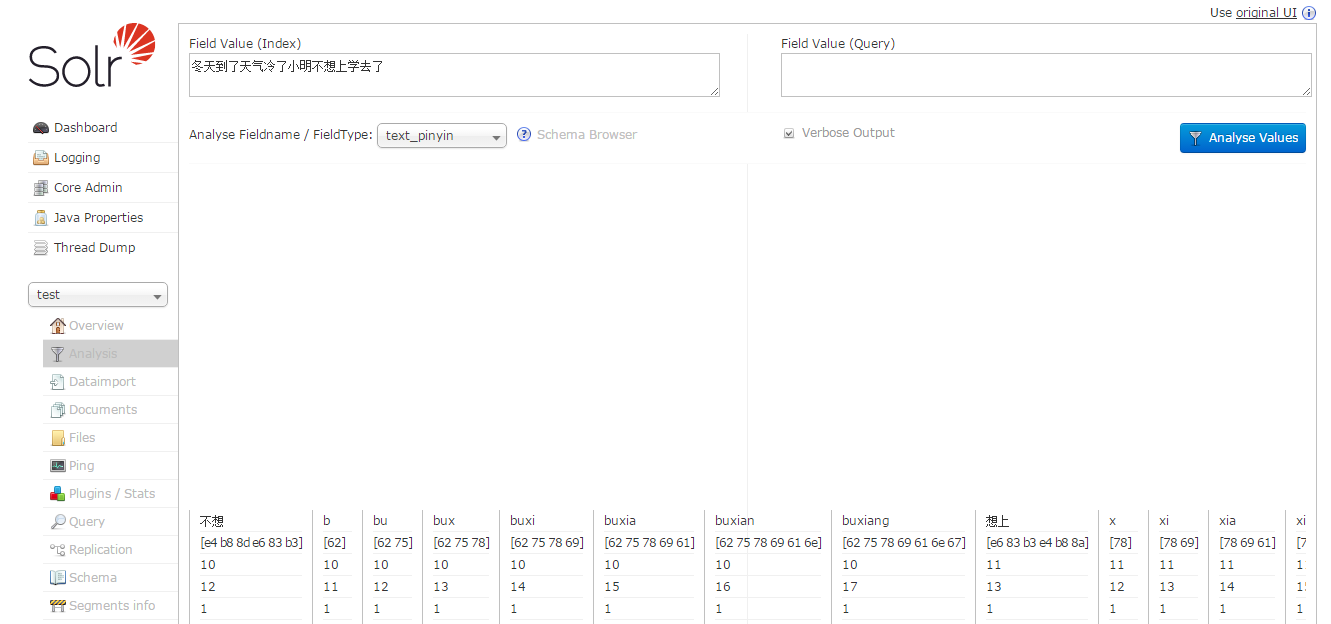
看到汉字转成拼音了。
solr 中文分词器IKAnalyzer和拼音分词器pinyin的更多相关文章
- 如何在Elasticsearch中安装中文分词器(IK)和拼音分词器?
声明:我使用的Elasticsearch的版本是5.4.0,安装分词器前请先安装maven 一:安装maven https://github.com/apache/maven 说明: 安装maven需 ...
- 开源项目在线化 中文繁简体转换/敏感词/拼音/分词/汉字相似度/markdown 目录
前言 以前在 github 上自己开源了一些项目.碍于技术与精力,大部分项目都是 java 实现的. 这对于非 java 开发者而言很不友好,对于不会编程的用户更加不友好. 为了让更多的人可以使用到这 ...
- Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二)
之前在 Solr6.5在Centos6上的安装与配置 (一) 一文中介绍了solr6.5的安装.这篇文章主要介绍创建Solr的Core并配置中文IKAnalyzer分词和拼音检索. 一.创建Core: ...
- es 修改拼音分词器源码实现汉字/拼音/简拼混合搜索时同音字不匹配
[版权声明]:本文章由danvid发布于http://danvid.cnblogs.com/,如需转载或部分使用请注明出处 在业务中经常会用到拼音匹配查询,大家都会用到拼音分词器,但是拼音分词器匹配的 ...
- elasticsearch 拼音+ik分词,spring data elasticsearch 拼音分词
elasticsearch 自定义分词器 安装拼音分词器.ik分词器 拼音分词器: https://github.com/medcl/elasticsearch-analysis-pinyin/rel ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
- solr 中文分词 IKAnalyzer
solr中文分词器ik, 推荐资料:http://iamyida.iteye.com/blog/2220474?utm_source=tuicool&utm_medium=referral 使 ...
- 全文检索引擎Solr系列——整合中文分词组件IKAnalyzer
IK Analyzer是一款结合了词典和文法分析算法的中文分词组件,基于字符串匹配,支持用户词典扩展定义,支持细粒度和智能切分,比如: 张三说的确实在理 智能分词的结果是: 张三 | 说的 | 确实 ...
- Solr7.3.0入门教程,部署Solr到Tomcat,配置Solr中文分词器
solr 基本介绍 Apache Solr (读音: SOLer) 是一个开源的搜索服务器.Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现.Apache ...
随机推荐
- 【php】php数组相关操作函数片段
下面这些都是我在工作中用到的函数,现在整理下. 判断是否是一个数组 function _is_array($value){ if (is_array($value)) { return true; } ...
- 洛谷4451 整数的lqp拆分(生成函数)
比较水的一题.居然是一道没看题解就会做的黑题…… 题目链接:洛谷 题目大意:定义一个长度为 $m$ 的正整数序列 $a$ 的价值为 $\prod f_{a_i}$.($f$ 是斐波那契数)对于每一个 ...
- htmlunit 校验验证码
htmlUnit 校验验证码 直接上代码 String url = "http://www.zycg.gov.cn/"; WebclientUtil webClientUtils ...
- OI生涯回忆录 2018.11.12~2019.4.15
上一篇:OI生涯回忆录 2017.9.10~2018.11.11 一次逆风而行的成功,是什么都无法代替的 ………… 历经艰难 我还在走着 一 NOIP之后,全机房开始了省选知识的自学. 动态DP,LC ...
- LINQ的基础使用方法
//新建一个项目 //项目下新建一个App_Code文件夹 //在文件夹内添加一个LINQ TO SQL,这个操作就相当于创建了一个实体类 //连接数据库后把表拖入到服务器资源管理器中 //创建数据访 ...
- JDBC动态查询MySQL中的表(按条件筛选)
动态查询实现按条件筛选.PreparedStatement 准备语句指定要查询的表头列,.setString()通过赋值指定行,.executeQuery()执行语句 在数据库test里先创建表sch ...
- (string stoi 栈)leetcode682. Baseball Game
You're now a baseball game point recorder. Given a list of strings, each string can be one of the 4 ...
- (选择不相交区间)今年暑假不AC hdu2037
今年暑假不AC Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Sub ...
- 【优秀的艺术文字和图标设计软件】Art Text 3.2.3 for Mac
[简介] Art Text 3.2.3 版本,这是一款Mac上简单易用的艺术文字和图标设计软件,今这款软件内置了大量的背景纹理和特效,能够让我们非常快速的制作出漂亮的图标,相比专业的PS,Art ...
- label与input之间的对应
实现点击文字对应的框可以被选中,再点击一下文字框又取消选中 label的for属性与input的id属性值对应,即可实现.