Event Recommendation Engine Challenge分步解析第六步
一、请知晓
本文是基于:
Event Recommendation Engine Challenge分步解析第一步
Event Recommendation Engine Challenge分步解析第二步
Event Recommendation Engine Challenge分步解析第三步
Event Recommendation Engine Challenge分步解析第四步
Event Recommendation Engine Challenge分步解析第五步
需要读者先阅读前五篇文章解析
二、特征构建
前五步我们已经将需要的数据进行了结构的存储,这一部分我们将利用前五步的数据
1)生成训练数据
dr = DataRewriter()
print('生成训练数据...\n')
dr.rewriteData(train=True, start=2, header=True)
我们先来解析这个DataRewriter类的rewriteData方法:该方法把前面user-based协同过滤和item-based协同过滤及各种热度和影响度作为特征组合在一起生成新的训练数据,用于分类器使用
def rewriteData(self, start=1, train=True, header=True):
"""
把前面user-based协同过滤和item-based协同过滤以及各种热度和影响度作为特征组合在一起
生成新的train,用于分类器分类使用
"""
fn = 'train.csv' if train else 'test.csv'
fin = open(fn)
fout = open('data_' + fn, 'w')
#write output header
if header:
ocolnames = ['invited', 'user_reco', 'evt_p_reco', 'evt_c_eco', 'user_pop', 'frnd_infl', 'evt_pop']
if train:
ocolnames.append('interested')
ocolnames.append('not_interested')
fout.write( ','.join(ocolnames) + '\n' )
fn:即为train.csv或者test.csv
fout:即为我们要写入保存的文件,data_train.csv或者data_test.csv
ocolnames:即为我们的特征,如果是train.csv的话应该还有标签-interested或not_interested
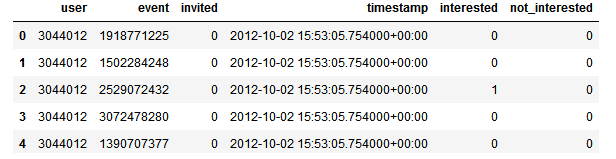
这里以train.csv为例讲解代码,其中train.csv文件如下所示:
def rewriteData(self, start=1, train=True, header=True):
"""
把前面user-based协同过滤和item-based协同过滤以及各种热度和影响度作为特征组合在一起
生成新的train,用于分类器分类使用
"""
fn = 'train.csv' if train else 'test.csv'
fin = open(fn)
fout = open('data_' + fn, 'w')
#write output header
if header:
ocolnames = ['invited', 'user_reco', 'evt_p_reco', 'evt_c_eco', 'user_pop', 'frnd_infl', 'evt_pop']
if train:
ocolnames.append('interested')
ocolnames.append('not_interested')
fout.write( ','.join(ocolnames) + '\n' ) ln = 0
for line in fin:
ln += 1
if ln < start:
continue
cols = line.strip().split(',')
#user,event,invited,timestamp,interested,not_interested
userId = cols[0]
eventId = cols[1]
invited = cols[2]
if ln % 500 == 0:
print("%s : %d (userId, eventId) = (%s, %s)" % (fn, ln, userId, eventId))
a)逐行读取train.csv或者test.csv,逗号分隔后获取userId,eventId,和invited,即前三列信息,然后调用self.userReco( userId, eventId)方法计算user_reco:
#这是特征构建部分 #import cPickle
#From python3, cPickle has beed replaced by _pickle
import _pickle as cPickle
import scipy.io as sip class DataRewriter:
def __init__(self):
#读入数据做初始化
self.userIndex = cPickle.load( open('PE_userIndex.pkl','rb') )
self.eventIndex = cPickle.load( open('PE_eventIndex.pkl', 'rb') )
self.userEventScores = sio.mmread('PE_userEventScores').todense()
self.userSimMatrix = sio.mmread('US_userSimMatrix').todense()
self.eventPropSim = sio.mmread('EV_eventPropSim').todense()
self.eventContSim = sio.mmread('EV_eventContSim').todense()
self.numFriends = sio.mmread('UF_numFriends')
self.userFriends = sio.mmread('UF_userFriends').todense()
self.eventPopularity = sio.mmread('EA_eventPopularity').todense() def userReco(self, userId, eventId):
"""
根据User-based协同过滤,得到event的推荐度
基本的伪代码思路如下:
for item in i
for every other user v that has a preference for i
compute similarity s between u and v
incorporate v's preference for i weighted by s into running average
return top items ranked by weighted average """
i = self.userIndex[userId]
j = self.eventIndex[eventId]
vs = self.userEventScores[:, j]
sims = self.userSimMatrix[i, :]
prod = sims * vs
try:
return prod[0, 0] - self.userEventScores[i, j]
except IndexError:
return 0
如在处理train.csv的第一行时,userId = 3044012, eventId = 1918771225
#import cPickle
#From python3, cPickle has beed replaced by _pickle
import _pickle as cPickle
userIndex = cPickle.load( open('PE_userIndex.pkl','rb') )
eventIndex = cPickle.load( open('PE_eventIndex.pkl', 'rb') )
userEventScores = sio.mmread('PE_userEventScores').todense()
userSimMatrix = sio.mmread('US_userSimMatrix').todense() userId = '3044012'
eventId = '1918771225'
i = userIndex[userId]
j = eventIndex[eventId] print('The first line in train.csv: userIndex of (userId = %s) is (i = %d) ' %(userId, i) )
print('The first line in train.csv: eventIndex of (eventId = %s) is (j = %d) ' %(eventId, j) ) vs = userEventScores[:, j]#获得所有user对event j兴趣分,即userEventScores的第j+1列
sims = userSimMatrix[i, :]#获得userSimMatrix的第i+1行,即每个user对该user的相似度
prod = sims * vs
try:
print(prod[0, 0] - userEventScores[i, j])
except IndexError:
print(0)
代码示例结果:
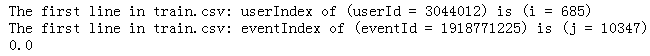
这样我们得到该user的user_reco值
b)evt_p_reco和evt_c_reco的计算
过程和上面的userReco()类似,读者可以参考eventPropSim和eventContSim的结构信息
def eventReco(self, userId, eventId):
"""
根据基于物品的协同过滤,得到Event的推荐度
基本的伪代码思路:
for item i:
for every item j that u has a preference for
compute similarity s between i and j
add u's preference for j weighted by s to a running average
return top items, ranked by weighted average
"""
i = self.userIndex[userId]
j = self.eventIndex[eventId]
js = self.userEventScores[i, :]#user i对每个event的兴趣分
psim = self.eventPropSim[:, j]
csim = self.eventContSim[:, j]
pprod = js * psim
cprod = js * csim
pscore = 0
cscore = 0
try:
pscore = pprod[0, 0] - self.userEventScores[i, j]
except IndexError:
pass try:
cscore = cprod[0, 0] - self.userEventScores[i, j]
except IndexError:
pass return pscore, cscore
c)user_pop计算:调用self.userPop()方法
这里需要用户的朋友数(已经用占比表示):
def userPop(self, userId):
"""
基于用户的朋友个数来推断用户的社交程度
主要的考量是如果用户的朋友非常多,可能会更倾向于参加各种社交活动
""" if userId in self.userIndex:
i = self.userIndex[userId]
try:
return self.numFriends[0, i]
except IndexError:
return 0
else:
return 0
d)frnd_infl计算:调用self.friendInfluence()方法,朋友对该用户的影响,即用户的所有朋友中,有多少是非常喜欢参加各种社交活动(event)的
这里需要变量self.userFriends
def friendInfluence(self, userId):
"""
朋友对用户的影响
主要考虑用户的所有朋友中,有多少是非常喜欢参加各种社交活动(event)的
用户的朋友圈如果都是积极参加各种event,可能会对当前用户有一定的影响
"""
nusers = np.shape(self.userFriends)[1]
i = self.userIndex[userId]
#下面的一行代码是不是有问题呢?
#是不是应该为某个用户的所有朋友的兴趣分之和,然后除以nusers,也就是axis应该=1
return (self.userFriends[i, :].sum(axis=0) / nusers)[0, 0]
e)evt_pop的计算:调用self.eventPop()方法,某个event的热度,主要通过参与的人数来界定的
需要用到变量self.eventPopularity
def eventPop(self, eventId):
"""
活动本身的热度
主要通过参与的参数来界定的
"""
i = self.eventIndex[eventId]
return self.eventPopularity[i, 0]
f)然后就是将该行的信息写入文件保存
文件信息包含:[invited, user_reco, evt_p_reco, evt_c_reco, user_pop, frnd_infl, evt_pop],如果读取的是train.csv,则还需要append 标签interested和not_interested
#读取一行,处理后,将该行写入,保存
fout.write(','.join( map(lambda x: str(x), ocols)) + '\n')
g)构建特征完整代码
#这是特征构建部分 #import cPickle
#From python3, cPickle has beed replaced by _pickle
import _pickle as cPickle
import scipy.io as sio
import numpy as np class DataRewriter:
def __init__(self):
#读入数据做初始化
self.userIndex = cPickle.load( open('PE_userIndex.pkl','rb') )
self.eventIndex = cPickle.load( open('PE_eventIndex.pkl', 'rb') )
self.userEventScores = sio.mmread('PE_userEventScores').todense()
self.userSimMatrix = sio.mmread('US_userSimMatrix').todense()
self.eventPropSim = sio.mmread('EV_eventPropSim').todense()
self.eventContSim = sio.mmread('EV_eventContSim').todense()
self.numFriends = sio.mmread('UF_numFriends')
self.userFriends = sio.mmread('UF_userFriends').todense()
self.eventPopularity = sio.mmread('EA_eventPopularity').todense() def userReco(self, userId, eventId):
"""
根据User-based协同过滤,得到event的推荐度
基本的伪代码思路如下:
for item in i
for every other user v that has a preference for i
compute similarity s between u and v
incorporate v's preference for i weighted by s into running average
return top items ranked by weighted average """
i = self.userIndex[userId]
j = self.eventIndex[eventId]
vs = self.userEventScores[:, j]
sims = self.userSimMatrix[i, :]
prod = sims * vs
try:
return prod[0, 0] - self.userEventScores[i, j]
except IndexError:
return 0 def eventReco(self, userId, eventId):
"""
根据基于物品的协同过滤,得到Event的推荐度
基本的伪代码思路:
for item i:
for every item j that u has a preference for
compute similarity s between i and j
add u's preference for j weighted by s to a running average
return top items, ranked by weighted average
"""
i = self.userIndex[userId]
j = self.eventIndex[eventId]
js = self.userEventScores[i, :]
psim = self.eventPropSim[:, j]
csim = self.eventContSim[:, j]
pprod = js * psim
cprod = js * csim
pscore = 0
cscore = 0
try:
pscore = pprod[0, 0] - self.userEventScores[i, j]
except IndexError:
pass try:
cscore = cprod[0, 0] - self.userEventScores[i, j]
except IndexError:
pass return pscore, cscore def userPop(self, userId):
"""
基于用户的朋友个数来推断用户的社交程度
主要的考量是如果用户的朋友非常多,可能会更倾向于参加各种社交活动
""" if userId in self.userIndex:
i = self.userIndex[userId]
try:
return self.numFriends[0, i]
except IndexError:
return 0
else:
return 0 def friendInfluence(self, userId):
"""
朋友对用户的影响
主要考虑用户的所有朋友中,有多少是非常喜欢参加各种社交活动(event)的
用户的朋友圈如果都是积极参加各种event,可能会对当前用户有一定的影响
"""
nusers = np.shape(self.userFriends)[1]
i = self.userIndex[userId]
#下面的一行代码是不是有问题呢?
#是不是应该为某个用户的所有朋友的兴趣分之和,然后除以nusers,也就是axis应该=1
return (self.userFriends[i, :].sum(axis=0) / nusers)[0, 0] def eventPop(self, eventId):
"""
活动本身的热度
主要通过参与的参数来界定的
"""
i = self.eventIndex[eventId]
return self.eventPopularity[i, 0] def rewriteData(self, start=1, train=True, header=True):
"""
把前面user-based协同过滤和item-based协同过滤以及各种热度和影响度作为特征组合在一起
生成新的train,用于分类器分类使用
"""
fn = 'train.csv' if train else 'test.csv'
fin = open(fn)
fout = open('data_' + fn, 'w')
#write output header
if header:
ocolnames = ['invited', 'user_reco', 'evt_p_reco', 'evt_c_reco', 'user_pop', 'frnd_infl', 'evt_pop']
if train:
ocolnames.append('interested')
ocolnames.append('not_interested')
fout.write( ','.join(ocolnames) + '\n' ) ln = 0
for line in fin:
ln += 1
if ln < start:
continue
cols = line.strip().split(',')
#user,event,invited,timestamp,interested,not_interested
userId = cols[0]
eventId = cols[1]
invited = cols[2]
if ln % 500 == 0:
print("%s : %d (userId, eventId) = (%s, %s)" % (fn, ln, userId, eventId)) user_reco = self.userReco( userId, eventId )
evt_p_reco, evt_c_reco = self.eventReco( userId, eventId )
user_pop = self.userPop( userId )
frnd_infl = self.friendInfluence( userId )
evt_pop = self.eventPop( eventId )
ocols = [invited, user_reco, evt_p_reco, evt_c_reco, user_pop, frnd_infl, evt_pop] if train:
ocols.append( cols[4] )#interested
ocols.append( cols[5] )#not_interested fout.write(','.join( map(lambda x: str(x), ocols)) + '\n') fin.close()
fout.close() def rewriteTrainingSet(self):
self.rewriteData(True) def rewriteTestSet(self):
self.rewriteData(False) dr = DataRewriter()
print('生成训练数据...\n')
dr.rewriteData(train=True, start=2, header=True) print('生成预测数据...\n')
dr.rewriteData(train=False, start=2, header=True)
print('done')
2)生成测试数据:过程和生成训练数据类似
至此,第六步完成,哪里有不明白的请留言
在特征构建好了之后,我们有很多办法去训练得到模型和完成预测
我们来看看Event Recommendation Engine Challenge分步解析第七步
Event Recommendation Engine Challenge分步解析第六步的更多相关文章
- Event Recommendation Engine Challenge分步解析第七步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第五步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第四步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第三步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第二步
一.请知晓 本文是基于Event Recommendation Engine Challenge分步解析第一步,需要读者先阅读上篇文章解析 二.用户相似度计算 第二步:计算用户相似度信息 由于用到:u ...
- Event Recommendation Engine Challenge分步解析第一步
一.简介 此项目来自kaggle:https://www.kaggle.com/c/event-recommendation-engine-challenge/ 数据集的下载需要账号,并且需要手机验证 ...
- SpringBoot 源码解析 (六)----- Spring Boot的核心能力 - 内置Servlet容器源码分析(Tomcat)
Spring Boot默认使用Tomcat作为嵌入式的Servlet容器,只要引入了spring-boot-start-web依赖,则默认是用Tomcat作为Servlet容器: <depend ...
- (转) Quick Guide to Build a Recommendation Engine in Python
本文转自:http://www.analyticsvidhya.com/blog/2016/06/quick-guide-build-recommendation-engine-python/ Int ...
- 卷积神经网络 cnnff.m程序 中的前向传播算法 数据 分步解析
最近在学习卷积神经网络,哎,真的是一头雾水!最后决定从阅读CNN程序下手! 程序来源于GitHub的DeepLearnToolbox 由于确实缺乏理论基础,所以,先从程序的数据流入手,虽然对高手来讲, ...
随机推荐
- 学习Linux系统的态度及技巧
Linux作为一种简单快捷的操作系统,现在被广泛的应用.也适合越来越多的计算机爱好者学习和使用.但是对于Linux很多人可能认为很难,觉得它很神秘,从而对其避而远之,但事实真的是这样么?linux真的 ...
- 【数学建模】day02-整数规划
基本类似于中学讲的整数规划--线性规划中变量约束为整数的情形. 目前通用的解法适合整数线性规划.不管是完全整数规划(变量全部约束为整数),还是混合整数规划(变量既有整数又有实数),MATLAB都提供了 ...
- Civil 3D 2017本地化中VBA程序移植到2018版中
中国本地化包简直就是一块鸡肋, 但对于某些朋友来说还真离不了: 可惜中国本地化包的推出一直滞后, 在最新版软件出来后1年多, 本地化还不一定能够出来, 即使出来了, 也只能是购买了速博服务的用户才能得 ...
- IntelliJ IDEA default settings 全局默认设置
可以通过以下两个位置设置IDEA的全局默认设置: 以后诸如默认的maven配置就不需要每次都重复配置了?
- #195 game(动态规划+二分)
考虑第一问的部分分.显然设f[i]为i子树从根开始扩展的所需步数,考虑根节点的扩展顺序,显然应该按儿子子树所需步数从大到小进行扩展,将其排序即可. 要做到n=3e5,考虑换根dp.计算某点答案时先将其 ...
- [NOIP2017] 逛公园 【最短路】【强连通分量】
题目分析: 首先考虑无数条的情况.出现这种情况一定是一条合法路径经过了$ 0 $环中的点.那么预先判出$ 0 $环中的点和其与$ 1 $和$ n $的距离.加起来若离最短路径不超过$ k $则输出$ ...
- [luogu2571][bzoj1857][SCOI2010]传送门【三分套三分】
题目描述 在一个2维平面上有两条传送带,每一条传送带可以看成是一条线段.两条传送带分别为线段AB和线段CD.lxhgww在AB上的移动速度为P,在CD上的移动速度为Q,在平面上的移动速度R.现在lxh ...
- vxlan和vlan数据报文
802.1Q标准的以太网帧格式增加了802.1Q字段,该字段包含了Type.PRI.CFI和VID 4个部分,各个部分的含义如下: ·Type:长度为2 bytes,表示帧类型,802.1Q tag帧 ...
- 【原创】线段树query模板对比! 新手线段树的一个容易出错的问题!!因为我就糊涂了一整天.......
我们解决问题的最好方法就是拿实例来举例子 我们来看tyvj1038或计蒜客 “管家的忠诚” 老管家是一个聪明能干的人.他为财主工作了整整10年,财主为了让自已账目更加清楚.要求管家每天记k次账,由于管 ...
- J2EE--常见面试题总结 -- ( 一)
StringBuilder和StringBuffer的区别: String 字符串常量 不可变 使用字符串拼接时是不同的2个空间 StringBuffer 字符串变量 可变 ...