scrapy框架原理学习
Scrapy框架原理:
参考出处:https://cuiqingcai.com/3472.html
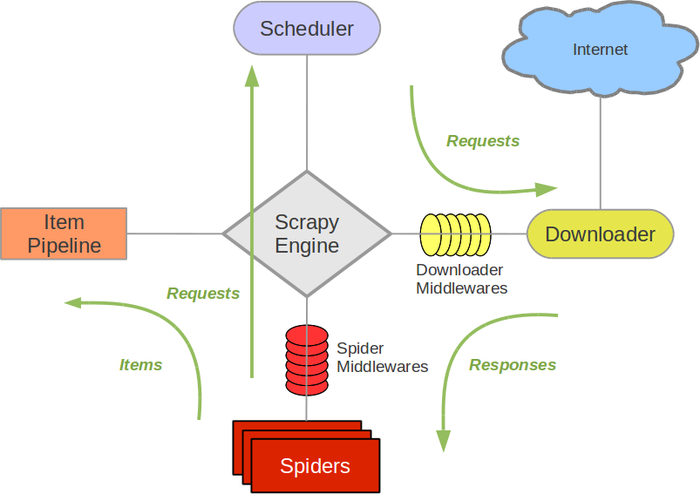
整个Scrapy的架构图:
Scrapy Engine: 这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!(像不像人的身体?)
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理,
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)
数据在整个Scrapy的流向:
程序运行的时候,
引擎:Hi!Spider, 你要处理哪一个网站?
Spiders:我要处理23wx.com
引擎:你把第一个需要的处理的URL给我吧。
Spiders:给你第一个URL是XXXXXXX.com
引擎:Hi!调度器,我这有request你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request给我,
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照下载中间件的设置帮我下载一下这个request
下载器:好的!给你,这是下载好的东西。(如果失败:不好意思,这个request下载失败,然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载。)
引擎:Hi!Spiders,这是下载好的东西,并且已经按照Spider中间件处理过了,你处理一下(注意!这儿responses默认是交给def parse这个函数处理的)
Spiders:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,这是我需要跟进的URL,将它的responses交给函数 def xxxx(self, responses)处理。还有这是我获取到的Item。
引擎:Hi !Item Pipeline 我这儿有个item你帮我处理一下!调度器!这是我需要的URL你帮我处理下。然后从第四步开始循环,直到获取到你需要的信息,
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy会重新下载。)
scrapy框架原理学习的更多相关文章
- scrapy爬虫学习系列五:图片的抓取和下载
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列四:portia的学习入门
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列一:scrapy爬虫环境的准备
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy再学习与第二个实例
这周对于Scrapy进一步学习,知识比较零散,需要爬取的网站因为封禁策略账号还被封了/(ㄒoㄒ)/~~ 一.信息存储 1.log存储命令:scrapy crawl Test --logfile=tes ...
- 《精通Python爬虫框架Scrapy》学习资料
<精通Python爬虫框架Scrapy>学习资料 百度网盘:https://pan.baidu.com/s/1ACOYulLLpp9J7Q7src2rVA
- 自己的Scrapy框架学习之路
开始自己的Scrapy 框架学习之路. 一.Scrapy安装介绍 参考网上资料,先进行安装 使用pip来安装Scrapy 在开始菜单打开cmd命令行窗口执行如下命令即可 pip install Scr ...
- #0 scrapy爬虫学习中遇到的坑记录
python 基础学习中对于scrapy的使用遇到了一些问题. 首先进行的是对Amazon.cn的检索结果页进行爬取,很顺利,无碍. 下一个目标是对baidu的搜索结果进行爬取 1,反爬虫 1.1 我 ...
随机推荐
- SMB协议利用之ms17-010-永恒之蓝漏洞抓包分析SMB协议
SMB协议利用之ms17-010-永恒之蓝漏洞抓包分析SMB协议 实验环境: Kali msf以及wireshark Win7开启网络共享(SMB协议) 实验步骤: 1.查看本机数据库是否开启,发现数 ...
- 在Linux系统上利用Tomcat搭建测试环境
第一歩:查看Linux系统的IP地址. 输入命令:ifconfig 第二歩:WinSCP工具 1.下载WinSCP工具,便于文件直接从windows系统直接拖动到Linux系统中,图形化创建文件夹等. ...
- Glyphicons 字体图标
- IT部门不应该是一个后勤部门
管理上最大的问题在于不重视预算与核算的管理.从管理层到员工,很少有经营的念头,只是一味地埋头做事.西方企业总结了当今几百年的经营理念,最终把企业一切活动的评价都归结到唯一的.可度量的标准上:钱来度量. ...
- ansys19.0安装破解教程(图文详解)
ansys19.0是一款非常著名的大型通用有限元分析(FEA)软件.该软件能够与多数计算机辅助设计软件接口,比如Creo, NASTRAN.Algor.I-DEAS.AutoCAD等,并能实现数据的共 ...
- Nginx使用教程(四):提高Nginx网络吞吐量之buffers优化
请求缓冲区在NGINX请求处理中起着重要作用. 在接收到请求时,NGINX将其写入这些缓冲区. 这些缓冲区中的数据可作为NGINX变量使用,例如$request_body. 如果缓冲区与请求大小相比较 ...
- C. Queen Codeforces Round #549 (Div. 2) dfs
C. Queen time limit per test 1 second memory limit per test 256 megabytes input standard input outpu ...
- BZOJ 4820 [SDOI2017] 硬币游戏
Description 周末同学们非常无聊,有人提议,咱们扔硬币玩吧,谁扔的硬币正面次数多谁胜利.大家纷纷觉得这个游戏非常符合同学们的特色,但只是扔硬币实在是太单调了.同学们觉得要加强趣味性,所以要找 ...
- 用python设置定时任务
python中的轻量级定时任务调度库:schedule 提到定时任务调度的时候,相信很多人会想到芹菜celery,要么就写个脚本塞到crontab中.不过,一个小的定时脚本,要用celery的话太 ...
- 数据库事务的四大特性以及事务的隔离级别-与-Spring事务传播机制&隔离级别
数据库事务的四大特性以及事务的隔离级别 本篇讲诉数据库中事务的四大特性(ACID),并且将会详细地说明事务的隔离级别. 如果一个数据库声称支持事务的操作,那么该数据库必须要具备以下四个特性: ⑴ ...