Randomized Online PCA Algorithms with Regret Bounds that are Logarithmic in the Dimension
前俩次,都用到了\(rounding()\),遗憾的是,都没有讲清楚,这次稍微具体地讲下这篇论文。但是说实话,我感觉,我还是没有领会到这篇文章的精髓。
Setup of Batch PCA and Online PCA
Batch PCA的目标,就是寻找一个子空间,能够最小化平方误差。
这篇论文,给出了一个比较新颖的表达方式:
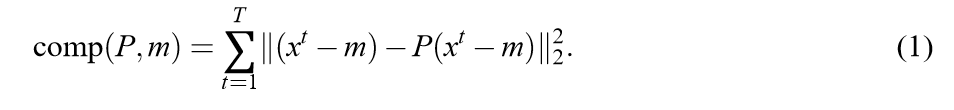
where,
\(m\in \mathbb{R}^{n}\)
\(rank(P) =k\)
一般来讲,最优解就是,\(m = \overline{x}\), 而\(P\)所对应的子空间就是协方差矩阵的前\(k\)个特征向量组成的子空间。
论文对(1)进行了一个改写:
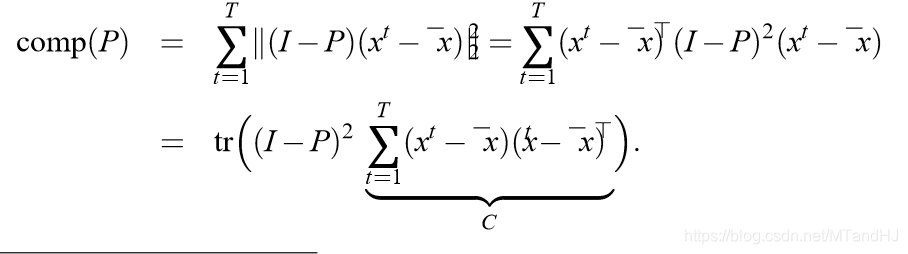
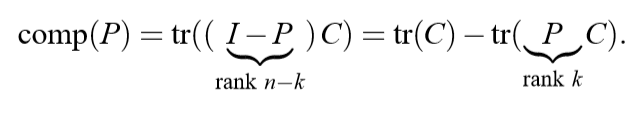
上面式子的一种直观解释就是,\(comp(P)\)就是一种损失,这个损失是由投影矩阵\(P\)带来的。
而在streaming PCA(论文里为Online PCA):
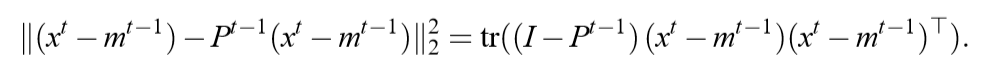
很自然的,
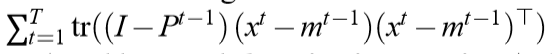
成了\(T\)次迭代所积累的损失。
我们希望,这些损失,能够接近由Batch PCA所产生的损失。
Hedge Algorithm
假设,有\(n\)个专家:expert \(i\), \(i=1,2,\ldots,n\).
有一个概率向量\(\mathsf{w}\),每个元素\(\mathsf{w}_i\)为舍弃expert \(i\)的概率。
自然而然,会有一个损失,称之为:\(\mathcal{l}\),每个元素是舍弃相应expert的损失,但是要求\(\mathcal{l}\in[0,1]\),所以我估计得有个单位化的过程。
下面就是如何选取专家,和迭代更新\(\mathsf{w}\)的算法。

这个\(\mathbf{w}\)的更新,有点类似adaboost,感觉其它地方也有看到过,至于其中的原理,估计还是得看论文吧。
同时,有下面的性质:
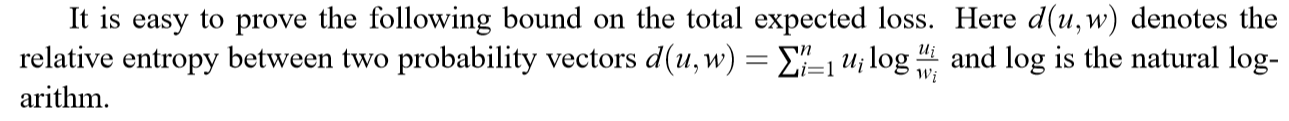
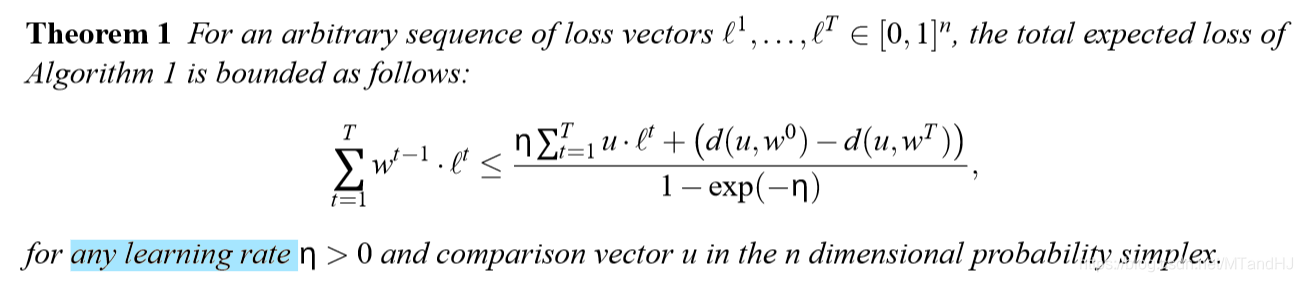
改进算法
这个算法的目标是,将\(\mathbf{w}\)分解为\(\mathop{\sum}\limits_{i}p_ir_i\),其中\(p_i\)为概率,\(r_i\)为\((n-k)\)-corner.\(d\)-corner,是指有且仅有\(d\)个非零项,且非零项的值为:\(\frac{1}{d}\).分解完毕只有,不同于上面的算法,这个算法将通过分布\(p_i\)选择\(r_i\),而\(r_i\)中的非零项所对应的指标就是相应的要舍弃的专家,expert。
分解算法如下:

\(\mathbf{w} \in B_d^n\)是指\(|\mathbf{w}|=\mathop{\sum}\limits_{i}\mathbf{w}_i=1\),且\(0 \leq \mathbf{w}_i \leq \frac{1}{d}\)
为了使\(\mathbf{w} \in B_d^{n}\),有下面的算法:

接下来就是结合上面的分解所得到的改进的Hedge算法:

有一个性质:
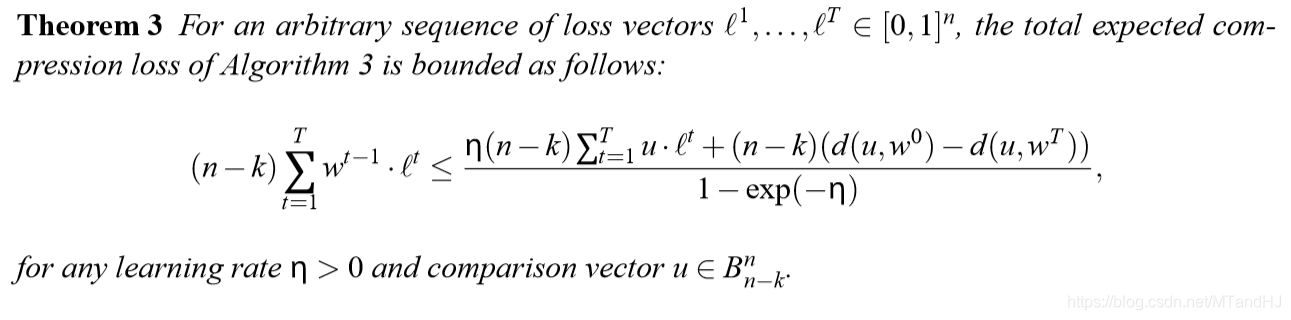
用于矩阵
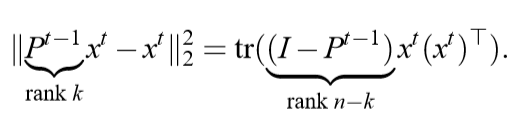
定义:
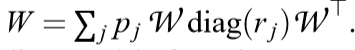
矩阵\(d\)-corner是指\(A\)的特征值,有且仅有\(d\)个非零项,且均为\(\frac{1}{d}\)。
其他的类似定义。
这里的\(W\)是密度矩阵:对称正定矩阵,且迹为1。
则:

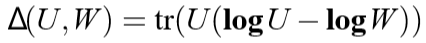
\(\mathbf{log}A=\mathop{\sum}\limits_ilog(\lambda_i)a_ia_i^{\top}\), 如果\(A=\mathop{\sum}\limits_i\lambda_ia_ia_i^{\top}\)
\(\mathbf{exp}A\)同理。
这个算法貌似是为了将\(W\)投影到\(B_d^{n}\)中的理论依据。
下面的算法五,就是关于如何利用\(W\)进行PCA:

\(rounding()\)
那么如何将上面的种种算法应用到之前提到的文章呢。之前的文章说,算法二就可以了,所以是这么理解吗?
最后得到的矩阵,根据特征值,得到概率向量\(\mathbf{w}\),然后再进行分解,通过概率\(p_i\),得到\(r_i\),接着,舍弃这些特征向量,得到最后的投影矩阵\(P\)?
但是,用特征值,总觉得和上面的不大相符,可不用特征值又能用什么呢?因为他们都是在最后一步利用这个\(rounding()\)。但是,用算法五,就和他们本身的算法不一致了,具体如何,不得而知了。
Randomized Online PCA Algorithms with Regret Bounds that are Logarithmic in the Dimension的更多相关文章
- Stochastic Optimization of PCA with Capped MSG
目录 Problem Matrix Stochastic Gradient 算法(MSG) 步骤二(单次迭代) 单步SVD \(project()\)算法 \(rounding()\) 从这里回溯到此 ...
- [转载]Maximum Flow: Augmenting Path Algorithms Comparison
https://www.topcoder.com/community/data-science/data-science-tutorials/maximum-flow-augmenting-path- ...
- 主成分分析(PCA)学习笔记
这两天学习了吴恩达老师机器学习中的主成分分析法(Principal Component Analysis, PCA),PCA是一种常用的降维方法.这里对PCA算法做一个小笔记,并利用python完成对 ...
- 近年Recsys论文
2015年~2017年SIGIR,SIGKDD,ICML三大会议的Recsys论文: [转载请注明出处:https://www.cnblogs.com/shenxiaolin/p/8321722.ht ...
- Beginners Guide To Learn Dimension Reduction Techniques
Beginners Guide To Learn Dimension Reduction Techniques Introduction Brevity is the soul of wit This ...
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
- 3D点云配准算法简述
蝶恋花·槛菊愁烟兰泣露 槛菊愁烟兰泣露,罗幕轻寒,燕子双飞去. 明月不谙离恨苦,斜光到晓穿朱户. 昨夜西风凋碧树,独上高楼,望尽天涯路. 欲寄彩笺兼尺素.山长水阔知何处? --晏殊 导读: 3D点云 ...
- 【转载】VC维的来龙去脉
本文转载自 火光摇曳 原文链接:VC维的来龙去脉 目录: 说说历史 Hoeffding不等式 Connection to Learning 学习可行的两个核心条件 Effective Number o ...
- Support Vector Machines for classification
Support Vector Machines for classification To whet your appetite for support vector machines, here’s ...
随机推荐
- MySQL并行复制的一个坑
早上巡检数据库,发现一个延迟从库的sql_thread中断了. Last_SQL_Errno: 1755 Last_SQL_Error: Cannot execute the current even ...
- Zabbix Agent安装与卸载
cmd /c "C:\zabbix\bin\win64\zabbix_agentd.exe -c c:\zabbix\conf\zabbix_agentd.win.conf -i" ...
- Linux 自动化部署Rsyslog服务
Linux 自动化部署Rsyslog服务 源码如下: #/bin/bash #该脚本用于自动化部署Ryslog服务配置 #作者:雨中落叶 #博客:https://www.cnblogs.com/yuz ...
- LeetCode算法题-Power of Four(Java实现-六种解法)
这是悦乐书的第205次更新,第216篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第72题(顺位题号是342).给定一个整数(带符号的32位),写一个函数来检查它是否为4 ...
- ORM版学员管理系统3
老师信息管理 思考 三种方式创建多对多外键方式及其优缺点. 通过外键创建 class Class(models.Model): id = models.AutoField(primary_key=Tr ...
- 15.scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- spark SQL读取ORC文件从Driver启动到开始执行Task(或stage)间隔时间太长(计算Partition时间太长)且产出orc单个文件中stripe个数太多问题解决方案
1.背景: 控制上游文件个数每天7000个,每个文件大小小于256M,50亿条+,orc格式.查看每个文件的stripe个数,500个左右,查询命令:hdfs fsck viewfs://hadoop ...
- 5.03-requests_ssl
import requests url = 'https://www.12306.cn/mormhweb/' headers = { 'User-Agent': 'Mozilla/5.0 (Macin ...
- iterable与iterator
1.迭代器的感性认识 对于Collection类下的集合如各种List各种Set,用于实现这些集合的数据结构各不相同,比如数组实现的ArrayList.链表实现的LinkedList,当客户端知道要使 ...
- Python 绑定 C,C++ 参考工具介绍
https://wiki.python.org/moin/IntegratingPythonWithOtherLanguages 完.