【原创】分布式之elk日志架构的演进
引言
好久没写分布式系列的文章了,最近刚好有个朋友给我留言,想看这方面的知识。其实这方面的知识,网上各种技术峰会的资料一抓一大把。博主也是凑合着写写。感觉自己也写不出什么新意,大家也凑合看看。
日志系统的必要性?
我15年实习的时候那会,给某国企做开发。不怕大家笑话,生产上就两台机器。那会定位生产问题,就是连上一台机器,然后用使用 grep / sed / awk 等 Linux 脚本工具去日志里查找故障原因。如果发现不在这台机器上,就去另一台机器上查日志。有经历过上述步骤的童鞋们,请握个抓!
然而,当你的生产上是一个有几千台机器的集群呢?你要如何定位生产问题呢?又或者,你哪天有这么一个需求,你需要收集某个时间段内的应用日志,你应该如何做?
为了解决上述问题,我们就需要将日志集中化管理。这样做,可以提高我们的诊断效率。同时也有利于我们全面理解系统。
正文
组件简介
这里大概介绍一下ELK组件在搭建日志系统过程中所扮演的角色,这边了解一下即可,具体的会在后文进行说明。
大家应该都知道ELK指的是:(Elasticsearch+Logstash+Kibana)。其中
Logstash:负责采集日志Elasticsearch:负责存储最终数据、建立索引、提供搜索功能Kibana:负责提供可视化界面
好了,知道上面的定义,可以开始讲演进过程了
实习版
OK,这版算是Demo版,各位开发可以在自己电脑上搭建练练手,如下图所示。
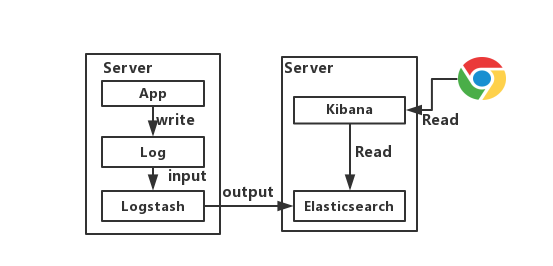
这种架构下我们把 Logstash实例与Elasticsearch实例直接相连,主要就是图一个简单。我们的程序App将日志写入Log,然后Logstash将Log读出,进行过滤,写入Elasticsearch。最后浏览器访问Kibana,提供一个可视化输出。
缺点
该版的缺点主要是两个
- 在大并发情况下,日志传输峰值比较大。如果直接写入ES,ES的HTTP API处理能力有限,在日志写入频繁的情况下可能会超时、丢失,所以需要一个缓冲中间件。
- 注意了,Logstash将Log读出、过滤、输出都是在应用服务器上进行的,这势必会造成服务器上占用系统资源较高,性能不佳,需要进行拆分。
于是,我们的初级版诞生了!
初级版
在这版中,加入一个缓冲中间件。另外对Logstash拆分为Shipper和Indexer。先说一下,LogStash自身没有什么角色,只是根据不同的功能、不同的配置给出不同的称呼而已。Shipper来进行日志收集,Indexer从缓冲中间件接收日志,过滤输出到Elasticsearch。具体如下图所示

说一下,这个缓冲中间件的选择。
大家会发现,早期的博客,都是推荐使用redis。因为这是ELK Stack 官网建议使用 Redis 来做消息队列,但是很多大佬已经通过实践证明使用Kafka更加优秀。原因如下:
Redis无法保证消息的可靠性,这点Kafka可以做到Kafka的吞吐量和集群模式都比Redis更优秀Redis受限于机器内存,当内存达到Max,数据就会抛弃。当然,你可以说我们可以加大内存啊?但是,在Redis中内存越大,触发持久化的操作阻塞主线程的时间越长。相比之下,Kafka的数据是堆积在硬盘中,不存在这个问题。
因此,综上所述,这个缓存中间件,我们选择使用Kafka。
缺点
主要缺点还是两个
Logstash Shipper是jvm跑的,非常占用JAVA内存! 。据《ELK系统使用filebeat替代logstash进行日志采集》这篇文章说明,8线程8GB内存下,Logstash常驻内存660M(JAVA)。因此,这么一个巨无霸部署在应用服务器端就不大合适了,我们需要一个更加轻量级的日志采集组件。- 上述架构如果部署成集群,所有业务放在一个大集群中相互影响。一个业务系统出问题了,就会拖垮整个日志系统。因此,需要进行业务隔离!
中级版
这版呢,引入组件Filebeat。当年,Logstash的作者用golang写了一个功能较少但是资源消耗也小的轻量级的Logstash-forwarder。后来加入Elasticsearch后,以logstash-forwarder为基础,研发了一个新项目就叫Filebeat。
相比于Logstash,Filebeat更轻量,占用资源更少,所占系统的 CPU 和内存几乎可以忽略不计。毕竟人家只是一个二进制文件。那么,这一版的架构图如下,我直接画集群版

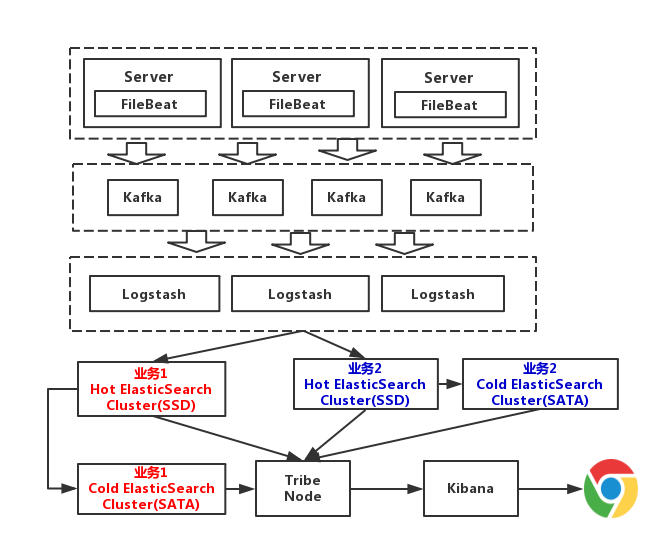
从上图可以看到,Elasticsearch根据业务部了3个集群,他们之间相互独立。避免出现,一个业务拖垮了Elasticsearch集群,整个日志系统就一起宕机的情况。而且,从运维角度来说,这种架构运维起来也更加方便。
至于这个Tribe Node,中文翻译为部落结点,它是一个特殊的客户端,它可以连接多个集群,在所有连接的集群上执行搜索和其他操作。在这里呢,负责将请求路由到正确的后端ES集群上。
缺点
这套架构的缺点在于对日志没有进行冷热分离。因为我们一般来说,对一个礼拜内的日志,查询的最多。以7天作为界限,区分冷热数据,可以大大的优化查询速度。
高级版
这一版,我们对数据进行冷热分离。每个业务准备两个Elasticsearch集群,可以理解为冷热集群。7天以内的数据,存入热集群,以SSD存储索引。超过7天,就进入冷集群,以SATA存储索引。这么一改动,性能又得到提升,这一版架构图如下(为了方便画图,我只画了两个业务Elasticsearch集群)
隐患
这个高级版,非要说有什么隐患,就是敏感数据没有进行处理,就直接写入日志了。关于这点,其实现在JAVA这边,现成的日志组件,比如log4j都有提供这种日志过滤功能,可以将敏感信息进行脱敏后,再记录日志。
【原创】分布式之elk日志架构的演进的更多相关文章
- 分布式实时日志分析解决方案ELK部署架构
一.概述 ELK 已经成为目前最流行的集中式日志解决方案,它主要是由Beats.Logstash.Elasticsearch.Kibana等组件组成,来共同完成实时日志的收集,存储,展示等一站式的解决 ...
- 架构之ELK日志分析系统
ELK多种架构及优劣 既然要谈ELK在大数据运维系统中的应用,那么ELK架构就不得不谈.本章节引出四种笔者曾经用过的ELK架构,并讨论各种架构所适合的场景和优劣供大家参考. 先大致介绍ELK组件.EL ...
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
- (五):C++分布式实时应用框架——微服务架构的演进
C++分布式实时应用框架--微服务架构的演进 上一篇:(四):C++分布式实时应用框架--状态中心模块 版权声明:本文版权及所用技术归属smartguys团队所有,对于抄袭,非经同意转载等行为保留法律 ...
- ElasticSearch实战系列九: ELK日志系统介绍和安装
前言 本文主要介绍的是ELK日志系统入门和使用教程. ELK介绍 ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件.新增了一 ...
- ELK日志分析系统的应用
收集和分析日志是应用开发中至关重要的一环,互联网大规模.分布式的特性决定了日志的源头越来越分散, 产生的速度越来越快,传统的手段和工具显得日益力不从心.在规模化场景下,grep.awk 无法快速发挥作 ...
- ELK 日志采集 实战教程
概要 带着问题去看教程: 不是用logstash来监听我们的日志,我们可以使用logback配置来使用TCP appender通过TCP协议将日志发送到远程Logstash实例. 我们可以使用Logs ...
- 从 ELK 到 EFK 的演进
背景 作为中国最大的在线教育站点,目前沪江日志服务的用户包含网校,交易,金融,CCTalk 等多个部门的多个产品的日志搜索分析业务,每日产生的各类日志有好十几种,每天处理约10亿条(1TB)日志,热数 ...
- ELK基础架构解说-运维笔记
一.ELK日志分析工具介绍1) Elasticsearch1.1) Elasticsearch介绍ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索 ...
随机推荐
- 转载:python生成以及打开json、csv和txt文件
原文地址:https://blog.csdn.net/weixin_42555131/article/details/82012642 生成txt文件: mesg = "hello worl ...
- ELk(Elasticsearch, Logstash, Kibana)的安装配置
目录 ELk(Elasticsearch, Logstash, Kibana)的安装配置 1. Elasticsearch的安装-官网 2. Kibana的安装配置-官网 3. Logstash的安装 ...
- 2019年Web前端入门的自学路线
本文最初发表于博客园,并在GitHub上持续更新前端的系列文章.欢迎在GitHub上关注我,一起入门和进阶前端. 以下是正文.本文内容不定期更新. 我前几天写过一篇文章:<裸辞两个月,海投一个月 ...
- mssql sqlserver 使用sql脚本检测数据表中一列数据是否连续的方法分享
原文地址:http://www.maomao365.com/?p=7335 摘要: 数据表中,有一列是自动流水号,由于各种操作异常原因(或者插入失败),此列数据会变的不连续,下文将讲述使用sql ...
- IIS ip访问限制插件
Dynamic IP Restrictions Overview The Dynamic IP Restrictions Extension for IIS provides IT Professio ...
- python 爬虫(一) requests+BeautifulSoup 爬取简单网页代码示例
以前搞偷偷摸摸的事,不对,是搞爬虫都是用urllib,不过真的是很麻烦,下面就使用requests + BeautifulSoup 爬爬简单的网页. 详细介绍都在代码中注释了,大家可以参阅. # -* ...
- HTTP1.0 、1.1
网上有很多资料说明这个,但都很长的,觉得东西太多也记不住,就记点东西,权当笔记. HTTP 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一 ...
- Alpha阶段 - 博客链接合集
Alpha阶段 - 博客链接合集 项目Github地址 安卓端(Stardust):https://github.com/StardustProject/Stardust 服务器端(Gravel):h ...
- 创建两个SAP系统之间的RFC信任关系
一种常见的场景是企业运行着多个SAP系统(ERP/SRM/CRM),用户希望在AA1系统中使用BB1系统的事务.如果直接使用RFC调用另一系统的事务的话,则会弹出登陆框,让用户再次输入帐号密码... ...
- 转:Java中的String,StringBuilder,StringBuffer三者的区别
最近在学习Java的时候,遇到了这样一个问题,就是String,StringBuilder以及StringBuffer这三个类之间有什么区别呢,自己从网上搜索了一些资料,有所了解了之后在这里整理一下, ...