Java多线程-详细版
基本概念解释
并发:一个处理器处理多个任务,这些任务对于处理器来说是交替运行的,每个时间点只有一个任务在进行。
并行:多个处理器处理多个任务,这些任务是同时运行的。每个时间点有多个任务同时进行。
进程与线程:一个进程可以拥有多个线程,线程是系统调度的最小单位。理论上一个进程可用的虚拟空间是2G,默认最多可以拥有2048个线程。
CPU上下文切换:CPU给每个任务一定的执行时间,当时间片轮转的时候,需要把当前状态保存下来,同时加载下一个任务,这个过程叫做上下文切换。
线程安全性
可见性,原子性,有序性
线程故障
死锁
鹬蚌相争:鹬啄住蚌的肉,蚌夹住鹬的嘴。鹬对蚌说:“你先放了我的嘴,我就不啄你的肉”,蚌对鹬说:“你先放了我的肉我就不夹你的嘴”。最终谁也不放开谁。也就是说两个线程互相持有对方的锁。
锁死
青蛙变王子的条件是公主吻了他,如果公主被我抱走了,那么他就一直是青蛙。
活锁
二哈追着咬自己的尾巴,虽然它一直追,可是总也咬不到。线程表现的很活跃,但是做的任务却没有进展。
饥饿
母鸟给小鸟喂食,食物总被强壮的幼鸟抢走,导致弱小的幼鸟总是处于饥饿状态。也就是有的线程得不到调度的机会,一直阻塞。
锁
对共享数据进行保护的一种措施,将多个线程对共享数据的并发访问转换为串行访问,同一时间只能有一个线程访问,访问结束后才能被其它线程访问。医院挂号,同一时间专家只能服务一个患者,解决完专家喊,“下一位!”,这个专家就是共享数据。
锁具有排他性,也就是一次只能被一个线程持有。这种锁被称为排它锁或者互斥锁。锁是通过互斥来保障原子性的。锁的互斥性和可见性保证临界区内的代码能读取到共享数据的最新值。注意锁的可见性,原子性和有序性是有条件的:
这些线程在访问同一共享数据的时候必须使用同一个锁;这些线程,即使是读取而不更改,也要在读取的时候持有相应的锁。
可重入性
如果说一个线程在持有一个锁的前提下还能继续成功的申请该锁,那么就称这个锁是可重入的。
如何实现的:可重入锁可以看成一个对象,这个对象有个计数器,初始状态为0,当有线程持有它的时候,计数器+1,当线程释放锁的时候,计数器-1。一个可重入锁被初次持有的时候开销是比较大的,因为线程要竞争该锁以获得它;线程继续获得它的开销就要小得多,因为只需要将计数器+1即可。
锁的调度
Java平台有两种锁,一种是内部锁,例如Synchronized关键字实现的;另外一种是显式锁,例如ReentrantLock。
锁的调度有两种:公平策略和非公平策略,相应的锁被称为公平锁和非公平锁。内部锁是非公平锁,显式锁支持二者。
锁的开销
组成:申请开销+释放开销+线程上下文切换开销=锁的开销
锁的分类
乐观锁:认为不会产生并发问题,每次去读数据都认为不会有其它线程修改,因此不上锁,但是在更新的时候会判断之前有没有线程对这个数据进行修改。可用CAS来实现(判断当前内存值是否与预期值相等,如果相等则用新值更新)。适用于读取频繁的情况。
悲观锁:每次读数据都认为其它线程会修改,所以都会加锁。Java中的Synchronized就是悲观锁。适用于写入频繁的情况。
内部锁(Synchronized)
synchronized关键字可以修饰方法或者代码块({})。synchronized关键字修饰的方法叫做同步方法,synchronized关键字修饰的静态方法叫做同步静态方法,同步方法的方法体就是一个临界区。被synchronized关键字修饰的代码块被称为同步快。
public class Share {
private String name;
/**
* 同步方法
* @param s
* @return
*/
public synchronized String update(String s){
this.name = s;
return name;
}
}
同步代码块
synchronized (锁句柄){
// 访问共享数据
}
锁句柄就是一个对象的引用,比如可以写为this关键字。
同步方法=以this为句柄的同步块
/**
* 方法里的同步块
* @param s
* @return
*/
public String update2(String s){
synchronized (this){
this.name = s;
return name;
}
}
作为锁句柄的变量通常用private final修饰,因为如果锁句柄改变,会导致锁改变。
同步静态方法
同步静态方法=以类对象为句柄的同步块
/**
* 同步静态方法
*/
private static synchronized void update3(){
// 访问共享数据
} /**
* 静态方法里的同步块
*/
private static void update4(){
synchronized (Share.class){
// 访问共享数据
}
}
因为线程对内部锁的申请与释放都是由JVM负责实施,所以这是synchronized实现的锁被称为内部锁的原因。
内部锁申请原理
JVM为每一个内部锁分配一个入口集(Entry Set),用来存放等待获取锁的线程。多个线程申请同一个锁的时候,只有一个能申请成功,其它的申请失败,申请失败的不会抛出异常,而是被Blocked并存入入口集等待。当锁被释放,JVM会在入口集中随机选择一个线程唤醒,但是!因为是非公平锁,JVM并不能保证这个线程一定能拿到,因为此时可能有新的没进入入口集的线程来“争夺”。所以,很可能出现有的线程一直被冷落的情况。
显式锁(Lock)
ReentrantLock就是Lock接口的一个实现类。
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock; public class ShareLock { private final Lock lock = new ReentrantLock(); public void deal(){
lock.lock();
try {
// 访问共享数据
} finally {
// 释放锁,避免锁泄露
lock.unlock();
}
}
}
在lock() 和 unlock() 之间的代码就是临界区。
内部锁与显式锁简单对比
灵活性:内部锁的申请和释放只能在一个方法内进行,而显式锁可以在一个方法内申请,在另一个方法内释放。
简单易用:内部锁不用担心锁泄露的问题,显式锁容易被错用导致锁泄露。
调度:内部锁仅支持非公平锁,显示锁支持公平和非公平锁。
读写锁
前面的锁无法以线程安全的方式在同一时刻对共享数据进行读取,对于并发情况下不是很乐观。这时候出现的读写锁:允许多个线程同时读取共享数据(只读),但是一次只允许一个线程对共享数据进行更改。任何线程读取的时候不允许其他线程修改,一个线程修改的时候,任何其它线程不允许读取。
读锁:可以被多个线程同时持有,是共享的。但是任何其它线程不能拥有相应的写锁,因为要保证读取的时候数据不被更改。
写锁:只能被一个线程持有,其他线程不能获得读锁和写锁。
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock; public class ShareReadWriteLock { private final ReadWriteLock lock = new ReentrantReadWriteLock();
private final Lock readLock = lock.readLock();
private final Lock writeLock = lock.writeLock(); /**
* 读数据
*/
public void read(){
readLock.lock();
try {
// 访问共享数据(只读)
} finally {
readLock.unlock();
}
} /**
* 写数据
*/
public void write(){
writeLock.lock();
try {
// 访问共享数据(读写)
} finally {
writeLock.unlock();
}
}
}
使用场景(必须同时满足)
1. 读多写少
2. 读耗时大于写
volatile关键字
这个关键字都说烂了,一句话:只能保证变量的可见性和有序性,不能保证原子性。也就是说它不是线程安全的。比如count++(读取,+1,写回),这个操作不是原子的,多线程操作就会出问题。如果要保障对volatile变量赋值操作的线程安全,那么赋值操作右边的表达式不能涉及任何共享变量,包括被赋值的变量本身。
开销:volatile变量的读写操作都不会导致上下文的切换,所以开销要比锁小。
使用场景
1. 使用volatile变量作为状态标志。
public class ChangeStatus implements Runnable {
private volatile Boolean status = true;
@Override
public void run() {
while (status){
// do something
}
}
public void change(){
status = false;
}
}
2. 在合适的场合替代锁。只要该变量的操作为原子操作,就可以不用锁。
3. 简易版的读写锁
public class Counter {
private volatile long count;
public long getCount(){
return count;
}
public void increment(){
synchronized (this){
++count;
}
}
}
原子类
原子类是基于CAS实现的能够保障对共享变量进行read-modify-write更新操作的原子性和可见性的工具类。那么说,像线程安全的不加锁的自增操作得以实现。
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicCounter {
private AtomicInteger count = new AtomicInteger(0);
public void increment(){
count.incrementAndGet();
}
public int getValue(){
return count.get();
}
public static void main(String[] args){
// 共享数据
AtomicCounter atomicCounter = new AtomicCounter();
// 多线程
Thread a = new Thread(new Dealing(atomicCounter));
Thread b = new Thread(new Dealing(atomicCounter));
a.start();
b.start();
try {
a.join();
b.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(atomicCounter.getValue());
}
}
class Dealing implements Runnable{
private final AtomicCounter atomicCounter;
public Dealing(AtomicCounter atomicCounter) {
this.atomicCounter = atomicCounter;
}
@Override
public void run() {
for (int i = 0; i < 10; i++){
atomicCounter.increment();
}
}
}
使用多线程一定能提高效率吗?
不一定,因为使用多线程增加了:上下文切换的开销、线程创建与销毁的开销、锁的争用开销。
线程间协作
Object(notify/notifyAll/wait)
Object.wait()方法使当前线程释放锁,变为等待状态;Object.notify()方法随机唤醒一个等待的线程;Object.notifyAll()方法唤醒全部等待的线程;notify不释放锁,它的内部锁只有在临界区代码执行完才会被释放,所以一般把notify放在临界区结束的地方;
synchronized (this){
while (不满足条件){
this.wait();
}
// 执行逻辑代码
}
synchronized (this){
// 执行逻辑代码
this.notify();
}
notify/wait注意问题
1. 过早唤醒问题
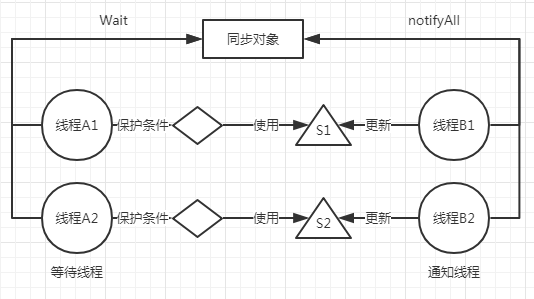
线程B1更新完S1条件即调用notifyAll,导致线程A1,A2被唤醒,这个时候只有A1满足条件,A2所依赖的条件S2不满足所以就算被唤醒仍然继续等待,造成了资源浪费。过早唤醒使得无需唤醒的线程也被唤醒,就好像你喊一声美女,大家都回头,连男的也回头了。
2. 信号丢失问题
也就是说等待线程不先判断保护条件是否成立,直接执行wait方法。那么它错过了保护条件这个“信号”,就叫做信号丢失。解决方法很简单,只需要把wait放在保护条件的while循环即可。
3. 上下文切换问题
wait/notify会导致较多的上下文切换。等待线程执行wait会导致至少两次内部锁的申请与释放。notify的执行需要持有内部锁,所以它会导致一次锁的申请。而锁的申请与释放会导致上下文切换。另外,等待线程从暂停到被唤醒这个过程本身就会导致上下文切换。过早唤醒会导致额外的上下文切换,因为你把猫弄醒了猫不理你又睡回去了,你白费劲了。
如何优化:使用notify代替notifyAll;执行完notify后尽快释放持有的内部锁(就像老板说赶快来,你到公司后发现还要等半个小时。别让线程长时间去等待)。
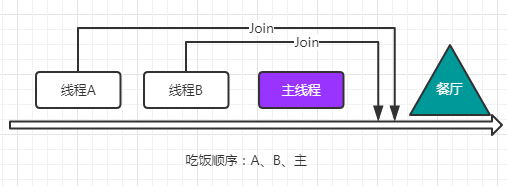
Thread.join()
Join使得当前线程等待目标线程执行完毕之后才继续运行。类似于插队。
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicCounter {
private AtomicInteger count = new AtomicInteger(0);
public void increment(){
count.incrementAndGet();
}
public int getValue(){
return count.get();
}
public static void main(String[] args){
// 共享数据
AtomicCounter atomicCounter = new AtomicCounter();
// 多线程
Thread a = new Thread(new Dealing(atomicCounter), "t-1");
Thread b = new Thread(new Dealing(atomicCounter), "t-2");
a.start();
b.start();
try {
a.join();
b.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(atomicCounter.getValue());
}
}
class Dealing implements Runnable{
private final AtomicCounter atomicCounter;
public Dealing(AtomicCounter atomicCounter) {
this.atomicCounter = atomicCounter;
}
@Override
public void run() {
for (int i = 0; i < 10; i++){
atomicCounter.increment();
}
System.out.println(Thread.currentThread().getName());
}
}
结果:
Condition(await/signal)
相对于内部锁使用wait/notify,显式锁使用await/signal,相比较起来,wait/notify更底层一些
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock; public class ConditionExample { private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition(); public void dealA() throws InterruptedException {
lock.lock();
try {
while (不满足保护条件){
condition.await();
}
// 执行其它逻辑
} finally {
lock.unlock();
}
} public void dealB(){
lock.lock();
try {
// 执行其他逻辑 & 更新保护条件
condition.signal();
} finally {
lock.unlock();
}
}
}
CountDownLatch & CyclicBarrier
CountDownLatch用来实现:一个(多个)线程在其它线程完成特定任务之后才继续执行。比如分配一系列子任务出去,等子任务执行完才能执行汇总操作。内部维护一个计数器,每完成一个任务调用一次CountDown()方法使得计数器-1,只有计数器为0才会执行await之后的代码。并且,CountDownLatch是一次性的。调用await/countDown方法无需加锁。
import java.util.Random;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicLong; public class Statistics { public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(5);
AtomicLong count = new AtomicLong(0); Random rand = new Random();
Thread t1 = new Thread(new Task(latch, rand.nextInt(1000), count));
Thread t2 = new Thread(new Task(latch, rand.nextInt(1000), count));
Thread t3 = new Thread(new Task(latch, rand.nextInt(1000), count));
Thread t4 = new Thread(new Task(latch, rand.nextInt(1000), count));
Thread t5 = new Thread(new Task(latch, rand.nextInt(1000), count));
t1.start();
t2.start();
t3.start();
t4.start();
t5.start(); latch.await();
System.out.println("总耗时:" + count.get());
}
} class Task implements Runnable{ private final CountDownLatch latch;
private final int times;
private final AtomicLong count; public Task(CountDownLatch latch, int times, AtomicLong count) {
this.latch = latch;
this.times = times;
this.count = count;
} @Override
public void run() {
long begin = System.currentTimeMillis();
try {
Thread.sleep(times);
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
long total = end-begin;
count.addAndGet(total);
System.out.println("线程:" + Thread.currentThread().getName() + "执行完毕!耗时:" + total + "(" + times + ")");
latch.countDown();
}
}
输出:

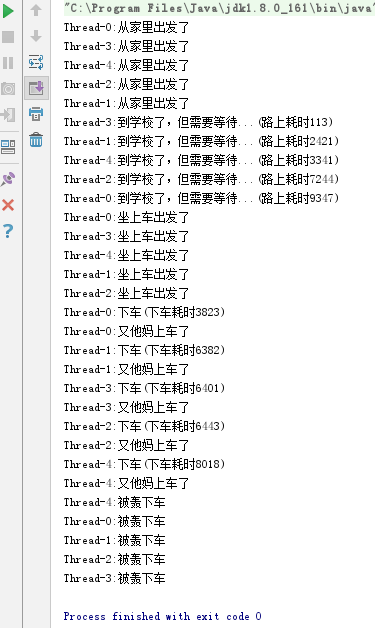
CycleBarrier用来实现:多个线程需要互相等待对方执行到代码中的某一个地方,然后才能继续执行。类似于出去郊游,小学生需要先到学校集合,然后再由老师带着一起出去玩。
CycleBarrier内部维护了一个显式锁,让CycleBarrier能够知道所有参与者中,最后执行await方法的是哪一个线程。当最后一个线程调用await方法时,其它所有参与者都会被唤醒,而最后一个线程并不会被暂停。与CountDownLatch不同的是,CycleBarrier是可重复利用的,所有人被唤醒后,任何一个人再调用await,又会进入等待状态,直到最后一个人调用await。
它的内部使用一个条件变量来实现等待/通知。通过分代的概念实现了可重复利用:当前分代的初始状态是parties等于参与者总数,每执行一次await,这个计数器-1,最后一个线程执行的时候也就变成了0,。接着,开始下一个分代,即使得parties恢复初始值。
import java.util.Random;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier; public class OutdoorPlay { public static void main(String[] args) throws InterruptedException {
CyclicBarrier homeBarrier = new CyclicBarrier(5);
CyclicBarrier busBarrier = new CyclicBarrier(5);
Thread[] t = new Thread[5];
for(int i = 0; i < 5; i++){
t[i] = new Thread(new LittleStudent(homeBarrier, busBarrier));
t[i].start();
} } } class LittleStudent implements Runnable{ private final CyclicBarrier homeBarrier;
private final CyclicBarrier busBarrier; public LittleStudent(CyclicBarrier homeBarrier, CyclicBarrier busBarrier) {
this.homeBarrier = homeBarrier;
this.busBarrier = busBarrier;
} @Override
public void run() {
try {
System.out.println(Thread.currentThread().getName() + ":从家里出发了");
int times = new Random().nextInt(10000);
Thread.sleep(times); // 模拟路上耗时
System.out.println(Thread.currentThread().getName() + ":到学校了,但需要等待...(路上耗时" + times + ")");
homeBarrier.await();
System.out.println(Thread.currentThread().getName() + ":坐上车出发了");
busBarrier.await();
times = new Random().nextInt(10000);
Thread.sleep(times); // 虽然一起下车,但是要遵守秩序
System.out.println(Thread.currentThread().getName() + ":下车(下车耗时" + times + ")");
System.out.println(Thread.currentThread().getName() + ":又他妈上车了");
busBarrier.await(); // 验证可重复利用
System.out.println(Thread.currentThread().getName() + ":被轰下车");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
}
输出:
阻塞队列
手机充电,现在都是智能手机,电充满了不拔电源也没事。我小时候用的不是智能手机,一直充电可能会把电池充爆。反映到线程,消费者的消费速度小于生产者的生产速度,如果不采取措施,会导致生产的东西占用内存越来越多,直到崩溃;相反会让消费线程比较清闲。
Java提供了阻塞队列,生产者向队列添加,消费者从队列里拿,当队列满了,生产者进入等待状态,消费者成功取出产品后通知生产者继续生产;相反,当队列空的时候,消费者进入等待状态,当生产者成功添加后通知消费者可以继续拿了。常用的阻塞队列有ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue。
import java.util.Random;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.SynchronousQueue; public class BlockedFoodFactory { public static void main(String[] args) throws InterruptedException {
// new LinkedBlockingQueue<>();
// new SynchronousQueue<>();
BlockingQueue<Food> queue = new ArrayBlockingQueue<>(5);
Thread[] A = new Thread[5];
Thread[] B = new Thread[5];
for (int i = 0; i < 5; i++){
A[i] = new Thread(new Eat(queue), "消费-" + i);
B[i] = new Thread(new Provide(queue), "生产-" + i);
A[i].start();
B[i].start();
}
Thread.sleep(Long.MAX_VALUE);
}
}
class Food {
public String name; public Food(String name) {
this.name = name;
}
} /**
* 吃
*/
class Eat implements Runnable{ private final BlockingQueue<Food> queue; public Eat(BlockingQueue<Food> queue) {
this.queue = queue;
} @Override
public void run() {
while (true) {
try {
Thread.sleep(new Random().nextInt(5000)); // 消费一个
Food food = queue.take();
ThreadGroup threadGroup = Thread.currentThread().getThreadGroup();
int count = threadGroup.activeCount();
Thread[] all = new Thread[count];
String state = ""; // 存储每个状态
threadGroup.enumerate(all);
for (int i = 0; i < count; i++){
state += (all[i].getName() + "~" + all[i].getState().name() + ",");
}
System.out.println("梁非凡吃:" + food.name + ",还剩:" + queue.size() + ",线程:" + Thread.currentThread().getName() +
",全部线程状态:" + state);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
} /**
* 供货
*/
class Provide implements Runnable{ private final BlockingQueue<Food> queue; public Provide(BlockingQueue<Food> queue) {
this.queue = queue;
} @Override
public void run() {
while (true) {
try {
Thread.sleep(new Random().nextInt(5000)); // 生产一个
Food food = new Food("屎-" + System.currentTimeMillis());
queue.put(food);
System.out.println("刘醒生产:" + food.name + ",库存:" + queue.size() + ",线程:" + Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
输出:
刘醒生产:屎-1540524209993,库存:1,线程:生产-4
梁非凡吃:屎-1540524209993,还剩:0,线程:消费-4全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,消费-0~TIMED_WAITING,生产-0~TIMED_WAITING,消费-1~TIMED_WAITING,生产-1~TIMED_WAITING,消费-2~TIMED_WAITING,生产-2~TIMED_WAITING,消费-3~TIMED_WAITING,生产-3~TIMED_WAITING,消费-4~RUNNABLE,生产-4~TIMED_WAITING,
刘醒生产:屎-1540524210922,库存:1,线程:生产-0
梁非凡吃:屎-1540524210922,还剩:0,线程:消费-2全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,消费-0~TIMED_WAITING,生产-0~TIMED_WAITING,消费-1~TIMED_WAITING,生产-1~TIMED_WAITING,消费-2~RUNNABLE,生产-2~TIMED_WAITING,消费-3~TIMED_WAITING,生产-3~TIMED_WAITING,消费-4~TIMED_WAITING,生产-4~TIMED_WAITING,
刘醒生产:屎-1540524212176,库存:1,线程:生产-4
梁非凡吃:屎-1540524212176,还剩:0,线程:消费-3全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,消费-0~TIMED_WAITING,生产-0~TIMED_WAITING,消费-1~TIMED_WAITING,生产-1~TIMED_WAITING,消费-2~TIMED_WAITING,生产-2~TIMED_WAITING,消费-3~RUNNABLE,生产-3~TIMED_WAITING,消费-4~TIMED_WAITING,生产-4~RUNNABLE,
刘醒生产:屎-1540524212670,库存:1,线程:生产-1
梁非凡吃:屎-1540524212670,还剩:0,线程:消费-0全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,消费-0~RUNNABLE,生产-0~TIMED_WAITING,消费-1~TIMED_WAITING,生产-1~TIMED_WAITING,消费-2~TIMED_WAITING,生产-2~TIMED_WAITING,消费-3~TIMED_WAITING,生产-3~TIMED_WAITING,消费-4~TIMED_WAITING,生产-4~TIMED_WAITING,
刘醒生产:屎-1540524213888,库存:1,线程:生产-0
刘醒生产:屎-1540524213950,库存:2,线程:生产-3
刘醒生产:屎-1540524214261,库存:3,线程:生产-2
通过打印可以知道:同一时刻,只能有一个线程能访问阻塞队列。这也是阻塞队列线程安全的原因。
根据存储容量大小可分为有界队列和无界队列,ArrayBlockingQueue是有界队列,LinkedBlockingQueue二者都可。ArrayBlockingQueue的put操作和take操作使用的是同一个锁,导致过多的上下文切换,根据上面的打印也可以发现。它内部使用的是一个数组,数组的空间是预先分配的,因此不会增加垃圾回收的负担;LinkedBlockingQueue使用了两个锁,分别对应Put操作和Take操作。因为内部使用的是链表,put,take操作都涉及链表节点的添加和移除,所以可能增加辣鸡回收的负担。由于使用了两个锁,导致无法使用一个普通的int变量维护当前队列的长度,因而用了一个原子变量,可是这个原子变量会被生产者线程和消费者线程争用,会出现额外的开销。SynchronousQueue是一种特殊的队列,内部没有用于存储队列元素的存储空间。生产者线程执行put操作的时候如果没有消费者执行take,那么该生产者线程会被暂停,直到消费者执行了take;相反,如果消费者执行take操作的时候如果没有生产者执行put,消费者会被暂停直到生产者执行了put。说白了,生产者生产完一个产品,会等待消费者取走,然后再继续生产下一个产品。
使用场景:
ArrayBlockingQueue:生产者线程和消费者线程并发程度低的情况
LinkedBlockingQueue:生产者线程和消费者线程并发程度高的情况
SynchronousQueue:生产者线程和消费者线程处理能力相差不多的情况
信号量(Semaphore['sɛməfɔr])
使用无界队列的好处是生产者线程不会被阻塞,但是会导致队列积压,最终你懂得。因此使用无界队列的同时可以限制生产者的生产速率,也就是进行流量控制避免积压过多的产品。Semaphore可以用来控制同一时间内对虚拟资源的访问次数。因此相关代码在访问虚拟资源之前必须先申请相应的配额,访问之后也要返还这些资源。Semaphore.acquire()/release()可以用来申请/释放。如果申请配额的时候配额不足,信号量会让这个线程暂停。Semaphore内部维护一个等待队列用于存储这些被暂停的线程,acquire()执行成功会将当前的可用配额减少1/release()会将当前的可用配额增加1,并唤醒等待队列中任何一个线程。
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.Semaphore; public class SemaphoreControl { public static void main(String[] args) throws InterruptedException {
int limit = 3;
BlockingQueue<String> queue = new LinkedBlockingQueue<>(); // 无界队列
Semaphore semaphore = new Semaphore(limit); // 信号量
Thread[] t = new Thread[10];
for (int i = 0; i < 10; i++){
t[i] = new Thread(new Production(queue, semaphore));
t[i].start();
}
Thread.sleep(Long.MAX_VALUE);
}
}
class Production implements Runnable{ private final BlockingQueue<String> queue;
private final Semaphore semaphore; public Production(BlockingQueue<String> queue, Semaphore semaphore) {
this.queue = queue;
this.semaphore = semaphore;
} @Override
public void run() {
while (true) {
try {
semaphore.acquire();
queue.put("P-" + System.currentTimeMillis());
ThreadGroup threadGroup = Thread.currentThread().getThreadGroup();
int count = threadGroup.activeCount();
Thread[] all = new Thread[count];
String state = ""; // 存储每个状态
threadGroup.enumerate(all);
for (int i = 0; i < count; i++){
state += (all[i].getName() + "~" + all[i].getState().name() + ",");
}
System.out.println("当前队列长度:" + queue.size() + ",当前线程:" + Thread.currentThread().getName() + ",全部线程状态:" + state);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
}
}
}
输出:每过2秒,三个一组输出。可以看出,流量成功的控制在3个。
RUNNABLE:线程运行中
TIMED_WAITING:设置了超时
WAITING:等待唤醒
证明了同时能够进入信号量临界区的只能有三个。而在同一时刻能操作Queue的仍然只有一个线程,否则就不安全了。
当前队列长度:1,当前线程:Thread-2,全部线程状态:main~RUNNABLE,Monitor Ctrl-Break~RUNNABLE,Thread-0~RUNNABLE,Thread-1~RUNNABLE,Thread-2~RUNNABLE,Thread-3~RUNNABLE,Thread-4~RUNNABLE,Thread-5~RUNNABLE,Thread-6~RUNNABLE,Thread-7~RUNNABLE,
当前队列长度:3,当前线程:Thread-0,全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,Thread-0~RUNNABLE,Thread-1~RUNNABLE,Thread-2~TIMED_WAITING,Thread-3~RUNNABLE,Thread-4~RUNNABLE,Thread-5~RUNNABLE,Thread-6~RUNNABLE,Thread-7~RUNNABLE,Thread-8~RUNNABLE,Thread-9~RUNNABLE,
当前队列长度:2,当前线程:Thread-5,全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,Thread-0~RUNNABLE,Thread-1~RUNNABLE,Thread-2~TIMED_WAITING,Thread-3~RUNNABLE,Thread-4~RUNNABLE,Thread-5~RUNNABLE,Thread-6~RUNNABLE,Thread-7~RUNNABLE,Thread-8~RUNNABLE,Thread-9~RUNNABLE,
当前队列长度:4,当前线程:Thread-2,全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,Thread-0~TIMED_WAITING,Thread-1~WAITING,Thread-2~RUNNABLE,Thread-3~WAITING,Thread-4~WAITING,Thread-5~TIMED_WAITING,Thread-6~WAITING,Thread-7~WAITING,Thread-8~WAITING,Thread-9~WAITING,
当前队列长度:5,当前线程:Thread-5,全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,Thread-0~TIMED_WAITING,Thread-1~WAITING,Thread-2~TIMED_WAITING,Thread-3~WAITING,Thread-4~WAITING,Thread-5~RUNNABLE,Thread-6~WAITING,Thread-7~WAITING,Thread-8~WAITING,Thread-9~WAITING,
当前队列长度:6,当前线程:Thread-0,全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,Thread-0~RUNNABLE,Thread-1~WAITING,Thread-2~TIMED_WAITING,Thread-3~WAITING,Thread-4~WAITING,Thread-5~TIMED_WAITING,Thread-6~WAITING,Thread-7~WAITING,Thread-8~WAITING,Thread-9~WAITING,
当前队列长度:7,当前线程:Thread-2,全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,Thread-0~TIMED_WAITING,Thread-1~WAITING,Thread-2~RUNNABLE,Thread-3~WAITING,Thread-4~WAITING,Thread-5~TIMED_WAITING,Thread-6~WAITING,Thread-7~WAITING,Thread-8~WAITING,Thread-9~WAITING,
当前队列长度:8,当前线程:Thread-8,全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,Thread-0~RUNNABLE,Thread-1~WAITING,Thread-2~TIMED_WAITING,Thread-3~WAITING,Thread-4~WAITING,Thread-5~TIMED_WAITING,Thread-6~WAITING,Thread-7~WAITING,Thread-8~RUNNABLE,Thread-9~WAITING,
当前队列长度:9,当前线程:Thread-5,全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,Thread-0~WAITING,Thread-1~WAITING,Thread-2~TIMED_WAITING,Thread-3~WAITING,Thread-4~WAITING,Thread-5~RUNNABLE,Thread-6~WAITING,Thread-7~WAITING,Thread-8~TIMED_WAITING,Thread-9~WAITING,
当前队列长度:10,当前线程:Thread-2,全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,Thread-0~WAITING,Thread-1~WAITING,Thread-2~RUNNABLE,Thread-3~WAITING,Thread-4~WAITING,Thread-5~TIMED_WAITING,Thread-6~WAITING,Thread-7~WAITING,Thread-8~TIMED_WAITING,Thread-9~WAITING,
当前队列长度:11,当前线程:Thread-8,全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,Thread-0~WAITING,Thread-1~WAITING,Thread-2~TIMED_WAITING,Thread-3~WAITING,Thread-4~WAITING,Thread-5~TIMED_WAITING,Thread-6~WAITING,Thread-7~WAITING,Thread-8~RUNNABLE,Thread-9~WAITING,
当前队列长度:12,当前线程:Thread-5,全部线程状态:main~TIMED_WAITING,Monitor Ctrl-Break~RUNNABLE,Thread-0~WAITING,Thread-1~WAITING,Thread-2~TIMED_WAITING,Thread-3~WAITING,Thread-4~WAITING,Thread-5~RUNNABLE,Thread-6~WAITING,Thread-7~WAITING,Thread-8~TIMED_WAITING,Thread-9~WAITING,
管道(PipedOutputStream/PipedInputStream)
这个玩意用来实现线程间直接的输入输出,从代码的角度来看,一个线程的输出可以作为另外一个线程的输入,而不必借助文件、数据库、网络连接等其它数据交换中介。PipedOutputStream相当于生产者,生产的是字节形式的数据,PipedInputStream是消费者。
使用场景:单生产者-单消费者的情况。
Exchanger
双缓冲技术
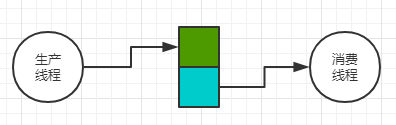
其中一个缓冲区充满来自生产线程的数据后供消费线程消费,而另外一个空的则用来填充来自新的生产线程生产的数据。这样就实现了数据生成与消费的并发。这就是双缓冲技术。
Java引入的Exchanger可以用来实现双缓冲。生产者与消费者分别维护一个缓冲区,双方通过执行Exchanger.exchange()来交换各自持有的缓冲区。
import java.util.concurrent.Exchanger;
public class ExchangeFood {
public static void main(String[] args) throws InterruptedException {
Exchanger<String> exchanger = new Exchanger<>();
Thread producer = new Thread(new ExchangeProducerTask(exchanger));
Thread consumer = new Thread(new ExchangeConsumerTask(exchanger));
producer.start();
consumer.start();
Thread.sleep(Long.MAX_VALUE);
}
}
/**
* 生产者
*/
class ExchangeProducerTask implements Runnable{
private final Exchanger<String> exchanger;
public ExchangeProducerTask(Exchanger<String> exchanger) {
this.exchanger = exchanger;
}
@Override
public void run() {
try {
String data = exchanger.exchange("鱼香肉丝");
System.out.println("生产者得到:" + data);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* 消费者
*/
class ExchangeConsumerTask implements Runnable{
private final Exchanger<String> exchanger;
public ExchangeConsumerTask(Exchanger<String> exchanger) {
this.exchanger = exchanger;
}
@Override
public void run() {
try {
String data = exchanger.exchange("宫保鸡丁");
System.out.println("消费者得到:" + data);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
输出:

使用场景:单生产者-单消费者。如果人多了就不能控制收发。
ThreadLocal<T>(线程本地变量)
对于多线程共享一个非线程安全的对象,往往需要加锁来保障线程安全。事实上,我们可以不共享,每个线程都创建一个该对象的实例,每个线程仅访问各自线程的实例,线程之间不能互相访问各自的实例。被线程独自持有的对象叫线程特有对象,线程特有对象可能是有状态对象,但是由于这个对象不会被多个线程共享,所以也就不存在线程安全问题。
优点:保障了非线程安全对象访问的线程安全,避免了锁的开销,减少对象的创建次数。
缺点:可能导致内存泄漏、伪内存泄漏。
线程本地变量通常被设置成某个类的静态常量。如果你设置为实例变量,意味着每创建一个该类的实例都会导致新的ThreadLocal变量被创建,会导致当前线程中同一个类型的线程特有对象被多次创建。虽然不会带来错误,但是会造成资源浪费。
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier; import static java.lang.Long.MAX_VALUE; public class ThreadLocalTest { private static final ThreadLocal<String> threadLocal = new ThreadLocal<>(); public static String getValue() {
String v = threadLocal.get();
if (v == null){
v = Thread.currentThread().getName();
threadLocal.set(v);
}
System.out.println("当前线程:" + Thread.currentThread().getName() + ",本地变量:" + v);
return v;
} public static void main(String[] args) throws InterruptedException {
CyclicBarrier barrier = new CyclicBarrier(50);
for (int i = 0; i < 50; i++){
new Thread(new SimpleTask(barrier)).start();
}
Thread.sleep(MAX_VALUE);
}
}
class SimpleTask implements Runnable{ private final CyclicBarrier barrier; public SimpleTask(CyclicBarrier barrier) {
this.barrier = barrier;
} @Override
public void run() {
try {
barrier.await();
ThreadLocalTest.getValue();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
}
这里用了栏栅,为了模拟高并发情况一起访问。

每个线程都拥有自己的变量。
如果不这么办呢?下面这段代码明显就有问题,共享的v没有任何保护措施。
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier; import static java.lang.Long.MAX_VALUE; public class ThreadLocalTest { private static String v = null; public static String getValue() {
if (v == null){
v = Thread.currentThread().getName();
}
System.out.println("当前线程:" + Thread.currentThread().getName() + ",本地变量:" + v);
return v;
} public static void main(String[] args) throws InterruptedException {
CyclicBarrier barrier = new CyclicBarrier(50);
for (int i = 0; i < 50; i++){
new Thread(new SimpleTask(barrier)).start();
}
Thread.sleep(MAX_VALUE);
}
}
class SimpleTask implements Runnable{ private final CyclicBarrier barrier; public SimpleTask(CyclicBarrier barrier) {
this.barrier = barrier;
} @Override
public void run() {
try {
barrier.await();
ThreadLocalTest.getValue();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
}
通过结果可以看到,完全乱套了。

如果变量可以被线程本身独占,那么就应该考虑使用ThreadLocal。Java8提供了一个初始化的方法:
private static final ThreadLocal<String> threadLocal = ThreadLocal.withInitial(() -> {
return "Init Value";
});
原理:每个线程内部都会维护一个类似于HashMap的实例,我们叫它ThreadLocalMap。每个ThreadLocalMap内部包含若干Entry,Entry的Key是ThreadLocal实例,Value是一个线程特有对象。
Java集合类&并发包
常用的工具类
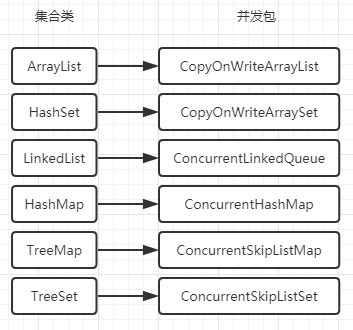
ArrayList && LinkedList
大家都知道,面试也重复了N遍,但是你确定你了解嘛。
1. 二者随机查询一个值的效率,哪一个高?
我知道你会脱口而出:ArrayList高!!!“高你个鸟啊,我问的不是按照下标访问,而是一个值,你不知道它的位置,这个时候二者是怎样查询的!”(这个是当初毕业去某东面试遇到的问题)
分析一波,根据问题我们会想到一个方法,contains
ArrayList<Object> arrayList = new ArrayList<>();
arrayList.contains(null);
LinkedList<Object> linkedList = new LinkedList<>();
linkedList.contains(null);
我们知道ArrayList内部是一个数组,那么如果让你实现这个方法你怎么实现?就告诉你,从一群萝莉里边把血小板找出来。最保险的方式:一个一个拿出来看,直到找到。事实上ArrayList也是这么做的。
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
一句话:从头遍历直到找到并返回所在的位置
那么LinkedList呢?也一样,从头遍历链表。
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
综上,二者在这种情况下效率差别不大,最优第一个就是血小板,最差血小板在最后或者根本没有血小板。
2. 随机读取 & 添加 & 删除
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
ArrayList先检查是否超出了范围,如果是就抛异常 IndexOutOfBoundsException,之后根据下标直接拿数据,很快,不复杂
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
LinkedList也要先检查范围
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
然后根据index,从头开始遍历链表,直到index所在的位置并将node返回。最优读取第一个,最差读取中间值。为什么是中间值:【 index < (size >> 1) :左移一位相当于乘以2,右移一位相当于除以2】因为内部是个双向链表,如果小于中间值,从头开始读;大于中间值,从尾开始读。所以目标位于中间最差劲。
随机读取:ArrayList优于LinkedList。
===========================
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
size:当前数组已有的数据数量
minCapacity:最少需要的空间
elementData.length:数组的实际存储容量
ArrayList添加之前会去确保有足够的空间。首先传入minCapacity(当前的数据量size+1),然后判断当前的内部容器(elementData)是不是等于初始的默认数组(DEFAULTCAPACITY_EMPTY_ELEMENTDATA),如果是的话,就从默认数组大小(DEFAULT_CAPACITY=10)和 minCapacity 之间选择一个最大的作为扩容条件,如果不是则直接将minCapacity返回。
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
确定好最少需要的空间大小(minCapacity)后,如果当前空间不足,就要进行扩容操作
if (minCapacity - elementData.length > 0)
grow(minCapacity);
..扩容
private void grow(int minCapacity) {
// 目前的容量
int oldCapacity = elementData.length;
// 新容量=1.5*老容量
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 如果新容量不足以装下需要的数据量,新容量置为minCapacity
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果新容量大于最大数组容量(Integer.MAX_VALUE - 8),将新容量置为Int类型最大值
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win: 作者得意的说,这是个胜利。最后将老数组的内容复制到新数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
再来看LinkedList
public boolean add(E e) {
linkLast(e);
return true;
}
简单的很,直接添加为尾节点,没啥好讲的
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
添加:LinkedList优于ArrayList
===========================
最后来看删除:
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work。这句代码我十分佩服,看起来很简单,但是没几个人想到GC
return oldValue;
}
还有一个根据值来删除的,效率差在不仅要顺序找到目标还要移动数组内容(java.util.ArrayList#remove(java.lang.Object))
通过下标删除要移动数组内容
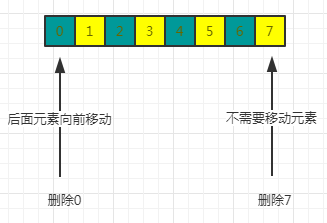
看LinkedList
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
首先检查是否越界,然后从头找到index位置的值,移动指针即可完成元素的删除,不需要移动元素。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
它也可以按照值来删除,要先从头遍历找到值,然后再删除,移动指针。(java.util.LinkedList#remove(java.lang.Object))
删除:LinkedList优于ArrayList
HashMap & HashTable
变量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 初始容量16 static final int MAXIMUM_CAPACITY = 1 << 30; // 最大容量 static final float DEFAULT_LOAD_FACTOR = 0.75f; // 当容量被占满0.75,就执行扩容操作 static final int TREEIFY_THRESHOLD = 8; // 当链表长度达到8,就转换成红黑树 static final int UNTREEIFY_THRESHOLD = 6; // 当红黑树size减少到6,就变成链表
put(1.8之前内部结构是数组+链表;1.8之后是数组+链表-红黑树)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 当table为空或者长度为0,执行resize
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 根据hash计算对应数组下标
if ((p = tab[i = (n - 1) & hash]) == null)
// 如果没有值,直接插入
tab[i] = newNode(hash, key, value, null);
else {
// 如果有值
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// key存在,直接覆盖
e = p;
else if (p instanceof TreeNode)
// 如果是树节点,插入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 插入链表
for (int binCount = 0; ; ++binCount) {
// 插入到链表末尾
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 此时如果 binCount大于等于7(因为是从0开始),则将链表转变成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 找到元素,break
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
// 向后遍历
p = e;
}
}
// 修改e所在位置的值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 容量达到阈值,扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
HashTable每个操作方法上都加了一个synchronized关键字,以此保证了线程安全。并且HashTable没有数据结构的变换。
public synchronized V put(K key, V value) {
// value不能为null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
// 如果key已存在,新值覆盖,老值返回
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
// 插入
addEntry(hash, key, value, index);
return null;
}
CopyOnWriteArrayList
这部分待续
ConcurrentHashMap
版本变化:1.8之前是众所周知的“锁分段机制”,即一个Segment数组+HashEntry,每个Segment存储HashEntry数组+链表。1.8之后摒弃了这种机制,直接采用Node数组,然后以数组元素作为锁,实现对每一行数据的加锁,同时也利用了数组-链表-红黑树这种结构。
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key value 不能为null
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
// 遍历Node数组
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
// 为空或者长度为0,初始化数组
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 目标位置值为null,利用CAS设置value,返回。
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 加锁进入
synchronized (f) {
if (tabAt(tab, i) == f) {
// 链表结构
if (fh >= 0) {
binCount = 1;
// 遍历链表节点
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 插入到最后
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 红黑树结构
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 链表size大于等于8,转为树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
线程池
线程是一种昂贵的资源,开销来自于:
- 线程的创建与启动,并且还占用了额外的空间--栈空间。
- 线程的销毁。
- 线程调度的开销,线程的调度会导致上下文切换,从而增加处理器资源的消耗。
数据库连接池:内部维护一定数量的对象,当客户端需要对象的时候向连接池申请,使用完再归还。
线程池:内部预先创建一定数量的工作线程,客户端并不需要申请线程而是把需要执行的任务作为一个对象交给线程池,该任务可能立即被执行也可能被放到缓存队列中等待工作线程取出并执行。
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit; public class ThreadPoolTest { public static void main(String[] args){
BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(5);
ThreadPoolExecutor pool = new ThreadPoolExecutor(1,3,60L, TimeUnit.SECONDS,queue);
for (int i = 1; i <= 9; i++){
pool.submit(new PrintTask(i));
}
pool.shutdown();
}
}
class PrintTask implements Runnable{ private final int t; public PrintTask(int t) {
this.t = t;
} @Override
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(t);
}
}
看构造方法

执行流程:进来的任务先满足corePoolSize,corePoolSize满了之后进入阻塞队列,阻塞队列满了之后在corePoolSize的基础上去填满maximumPoolSize,之后进来的任务会启动拒绝策略。
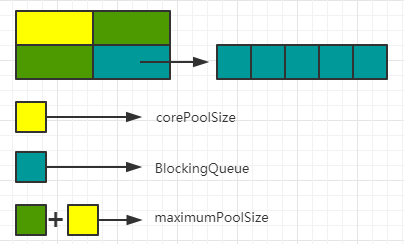
SO,打印顺序为。因为1号直接执行,2-6号进入队列,7,8也直接执行,最后从队列取出任务执行。而9号没有他的位置了,直接拒绝。

对于拒绝策略有四种:

下面仅仅测试一种拒绝策略,
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit; public class ThreadPoolTest { public static void main(String[] args){
BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(5);
ThreadPoolExecutor pool = new ThreadPoolExecutor(1,3,60L,
TimeUnit.SECONDS, queue, new ThreadPoolExecutor.DiscardOldestPolicy());
for (int i = 1; i <= ; i++){
pool.submit(new PrintTask(i));
}
pool.shutdown();
}
}
class PrintTask implements Runnable{ private final int t; public PrintTask(int t) {
this.t = t;
} @Override
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(t);
}
}
输出:看得出来仍然只有8个任务成功执行,2和3属于队列中最老的任务被丢弃,被拒绝的任务9 和 10有了执行的机会

submit与execute
java.util.concurrent.ExecutorService#submit(java.lang.Runnable) 可查看执行结果
Future<?> submit(Runnable task); java.util.concurrent.Executor#execute 无法查看返回结果
void execute(Runnable command);
工具类Executors提供了四种创建线程池的静态方法。

测试newFixedThreadPool
import java.util.concurrent.*;
public class ThreadPoolTest {
public static void main(String[] args){
ExecutorService pool = Executors.newFixedThreadPool(5);
for (int i = 1; i <= 10; i++){
pool.submit(new PrintTask(i));
}
pool.shutdown();
}
}
class PrintTask implements Runnable{
private final int t;
public PrintTask(int t) {
this.t = t;
}
@Override
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(t);
}
}
输出:五个一组

测试Schedule
import java.text.DateFormat;
import java.util.Date;
import java.util.concurrent.*; public class ThreadPoolTest { public static void main(String[] args){
ScheduledExecutorService pool = Executors.newScheduledThreadPool(2);
// 延迟1秒后,每隔3秒执行一次任务
pool.scheduleAtFixedRate(() -> {
System.out.println("执行时间:" + DateFormat.getTimeInstance().format(new Date()));
},1, 3, TimeUnit.SECONDS);
System.out.println("开始时间:" + DateFormat.getTimeInstance().format(new Date()));
}
}
输出:

测试Single
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors; public class ThreadPoolTest { public static void main(String[] args){
ExecutorService pool = Executors.newSingleThreadExecutor();
for (int i = 1; i <= 10; i++){
pool.submit(new PrintTask(i));
}
pool.shutdown();
}
}
class PrintTask implements Runnable{ private final int t; public PrintTask(int t) {
this.t = t;
} @Override
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(t);
}
}
输出:每隔2秒输出一个

异步任务
同步任务:同步任务发起之后必须等待该任务执行结束才能执行其他操作,这种等待往往意味着阻塞。
异步任务:其任务的发起和任务的执行是在不同时间线上的,也就是说发起任务之后可以继续做其他事情而不必等待任务执行结束,异步往往意味着非阻塞。
我们知道实现线程的方法:继承Thread或者实现Runnable接口。还有另外一种,实现Callable<T>接口,这个接口能够抛异常还能返回结果。我们可以通过 Executors.callable(Runnable task, T result) 来包装Runnable,实现Callable的功能。
import java.util.Random;
import java.util.concurrent.*; public class CallableTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<String> future = executor.submit(new CallableTask(new Random().nextInt(5000)));
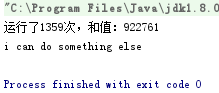
String s = "I CAN DO SOMETHING ELSE";
System.out.println(s.toLowerCase());
System.out.println(future.get());
executor.shutdown();
}
}
class CallableTask implements Callable<String> { private final int n; public CallableTask(int n) {
this.n = n;
} @Override
public String call() throws Exception {
int i = 0;
int result = 0;
while (i < n){
result += i;
i++;
}
return "运行了" + n + "次,和值:" + result;
}
}
输出:

注意:如果我们在提交一个任务后立即调用Future.get()来获得它的结果,尽管它是异步执行的,但是调用这个方法的线程可能被阻塞。
改变上面的代码:
public class CallableTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executor = Executors.newSingleThreadExecutor();
System.out.println(executor.submit(new CallableTask(new Random().nextInt(5000))).get());
String s = "I CAN DO SOMETHING ELSE";
System.out.println(s.toLowerCase());
executor.shutdown();
}
}
输出:由于阻塞,先输出了结果,后输出了英文。
比较:同步方式代码直观简单,缺点是限制系统的吞吐量。异步方式的代价是更为复杂的代码和更多的资源投入:额外的工作线程,线程的管理。
Java多线程-详细版的更多相关文章
- java 多线程详细笔记(原理理解到全部使用)
鸽了好久以后终于又更新了,看同学去实习都是先学源码然后修改之类,才发觉只是知道语法怎么用还远远不够,必须要深入理解以后不管是学习还是工作,才能举一反三,快速掌握. 目录 基础知识 进程与线程 线程原子 ...
- java线程详细版(未完待续)
1. Java线程:概念与原理 一.操作系统中线程和进程的概念 现在的操作系统是多任务操作系统.多线程是实现多任务的一种方式. 进程是指一个内存中运行的应用程序,每个进程都有自己独立的一块内存空间,一 ...
- java多线程学习笔记——详细
一.线程类 1.新建状态(New):新创建了一个线程对象. 2.就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法.该状态的线程位于可运行线程池中, ...
- 第十节:详细讲解一下Java多线程,随机文件
前言 大家好,给大家带来第十节:详细讲解一下Java多线程,随机文件的概述,希望你们喜欢 多线程的概念 线程的生命周期 多线程程序的设计 多线程的概念 多线程的概念:程序是静态的,进程是动态的.多进程 ...
- java 多线程超详细总结——阿里大牛熬夜整理
引 如果对什么是线程.什么是进程仍存有疑惑,请先Google之,因为这两个概念不在本文的范围之内. 用多线程只有一个目的,那就是更好的利用cpu的资源,因为所有的多线程代码都可以用单线程来实现.说这个 ...
- 转:Java多线程学习(总结很详细!!!)
Java多线程学习(总结很详细!!!) 此文只能说是java多线程的一个入门,其实Java里头线程完全可以写一本书了,但是如果最基本的你都学掌握好,又怎么能更上一个台阶呢? 本文主要讲java中多线程 ...
- Java多线程学习(吐血超详细总结)
Java多线程学习(吐血超详细总结) 林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka 写在前面的话:此文只能说是java多线程的一个入门,其实 ...
- java多线程编程详细总结
一.多线程的优缺点 多线程的优点: 1)资源利用率更好2)程序设计在某些情况下更简单3)程序响应更快 多线程的代价: 1)设计更复杂虽然有一些多线程应用程序比单线程的应用程序要简单,但其他的一般都更复 ...
- Java学习路线(完整详细版)
Java学习路线(完整详细版) https://jingyan.baidu.com/article/c1a3101e110864de656deb83.html
随机推荐
- 浅谈基于Prism的软件系统的架构设计
很早就想写这么一篇文章来对近几年使用Prism框架来设计软件来做一次深入的分析了,但直到最近才开始整理,说到软件系统的设计这里面有太多的学问,只有经过大量的探索才能够设计出好的软件产品,就本人的理解, ...
- DButils实现数据库表下划线转bean中驼峰格式
准备: QueryRunner queryRunner = new QueryRunner();//开启下划线->驼峰转换所用BeanProcessor bean = new GenerousB ...
- JarvisOJ BASIC -.-字符串
请选手观察以下密文并转换成flag形式 ..-. .-.. .- --. ..... ..--- ..--- ----- .---- ---.. -.. -.... -.... ..... ...-- ...
- windows新增/修改/删除系统环境变量bat示例,一键配置JAVA_HOME
setx JAVA_HOME "C:\Program Files\java\jdk1.6.0_27" /m setx classpath = ".;%JAVA_HOME% ...
- [BZOJ 3498] [PA 2009] Cakes
Description \(n\) 个点 \(m\) 条边,每个点有一个点权 \(a_i\). 对于任意一个三元环 \((i,j,k)(i<j<k)\),它的贡献为 \(\max(a_i, ...
- Codeforces Round #542 Div. 1
A:显然对于起点相同的糖果,应该按终点距离从大到小运.排个序对每个起点取max即可.读题花了一年还wa一发,自闭了. #include<iostream> #include<cstd ...
- PHP——生成唯一序列号UUID
<?php function uuid($uid = '') { $chars = md5(uniqid(mt_rand(), true)); $uuid = substr($chars, 0, ...
- Git初始化及配置
>>>>Git简介 >>>>官网下载Git >>>>安装,一路next 安装成功后,鼠标右键里就有Git bash here和G ...
- 「HNOI2016」最小公倍数
链接 loj 一道阔爱的分块 题意 边权是二元组(A, B),每次询问u, v, a, b,求u到v是否存在一条简单路径,使得各边权上\(A_{max} = a, B_{max} = b\) 分析 对 ...
- 使用页面Cookie做ABTest测试
背景介绍: 公司为了提升网站销售,做了2种不同风格的Bug页面,需要测试哪个页面的销售效果更好,使用了ABTest. 原理: 当用户访问www.website.com/buy.php时,生成一个随机数 ...