日志收集(ElasticSearch)串联查询 MDC
之前写过将应用程序或服务程序产生的日志直接写入搜索引擎的博客 其中基本过程就是 app->redis->logstash->elasticsearch 整个链路过程 本来想将redis替换成kafka的 无奈公司领导不让(不要问我为什么没有原因不想回答,哦也!就这么酷!!!)
然后又写了相关的优化,其实道理很简单 就是 部署多个redis 多个logstash就ok了 (注意redis建议不要部署集群单节点就OK因为他只承担了消息传输的功能别无其他,架集群的好处就是APP应用自己分发负载了,如果是多个redis单节点需要个类似nginx的东西做负载转发,其实最好使用F5这类的硬件会更好)好了不多说废话下面直奔主题。
遇到的问题
1、去ES(ElasticSearch 以下简称ES)查询日志用关键字搜索要搜索好几次才能定位的问题?
2、多线程调用公用的方法很多时候是不是有点迷糊找不着北等等 不止这些
想要达到的目的
通过关键字(关键字可以是订单号,操作码等可以标识一条信息,一般在数据库里面都是主键)一次查询出来所有的整个链路的相关日志
好,我们的目的很明确,不想各种过滤条件一大堆去定位真正想要的日志,一个关键搞定多所有。
说道这里可能有很多童鞋对日志框架比较了解第一就会想到MDC,没错就是他。下面才是真正的主题,哈哈!
MDC我就不多介绍这里我在网上随便找了一个介绍的 如果熟悉可以略过(https://blog.csdn.net/liubo2012/article/details/46337063)
MDC其实就是在方法里面前后标记一下,然后在这个标记范围内(包括中间调用的方法嵌套)所有的日志都会打上相应的标签记录方便查询
那怎么和我们之前的 方案结合和 我们之前用的是下面这个包,这个包是支持MDC传输的具体源码大家可以参看github实现https://github.com/kmtong/logback-redis-appender
<dependency>
<groupId>com.cwbase</groupId>
<artifactId>logback-redis-appender</artifactId>
<version>1.1.5</version>
</dependency>
当我们引入这个包之后logback.xml文件是如下配置的
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false" scan="true" scanPeriod="1 seconds">
<include resource="org/springframework/boot/logging/logback/base.xml" />
<!-- <jmxConfigurator/> -->
<contextName>logback</contextName> <property name="log.path" value="\logs\logback.log" /> <property name="log.pattern"
value="%d{yyyy-MM-dd HH:mm:ss.SSS} -%5p ${PID} --- traceId:[%X{mdc_trace_id}] [%15.15t] %-40.40logger{39} : %m%n" /> <appender name="file"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}</file> <encoder>
<pattern>${log.pattern}</pattern>
</encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>info-%d{yyyy-MM-dd}-%i.log
</fileNamePattern> <timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <maxFileSize>10MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<maxHistory>10</maxHistory>
</rollingPolicy> </appender> <appender name="redis" class="com.cwbase.logback.RedisAppender"> <tags>test</tags>
<host>10.10.12.21</host>
<port>6379</port>
<key>spp</key>
<mdc>true</mdc>
<callerStackIndex>0</callerStackIndex>
<location>true</location> <!-- <additionalField>
<key>traceId</key>
<value>@{destination}</value>
</additionalField> -->
</appender> <root level="info">
<!-- <appender-ref ref="file" /> -->
<!-- <appender-ref ref="UdpSocket" /> -->
<!-- <appender-ref ref="TcpSocket" /> -->
<appender-ref ref="redis" />
</root> <!-- <logger name="com.example.logback" level="warn" /> --> </configuration>
我们把<mdc>true</mdc>标签设置为true 默认是false就可以了,下面我们看下我们的测试代码
package com.zjs.canal.client.client; import org.junit.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC; public class testaa {
protected final static Logger logger = LoggerFactory.getLogger(testaa.class); @Test
public void test(){ MDC.put("destination", "123456789");
for (int i = 0; i < 10; i++) {
logger.info("aaaaaaaa"+i);
test1();
}
MDC.remove("destination");
}
public void test1()
{
for (int i = 0; i < 10; i++) {
logger.info("bbbbbbbb"+i);
}
}
}
上面的测试有两层嵌套下面是ES日志输出
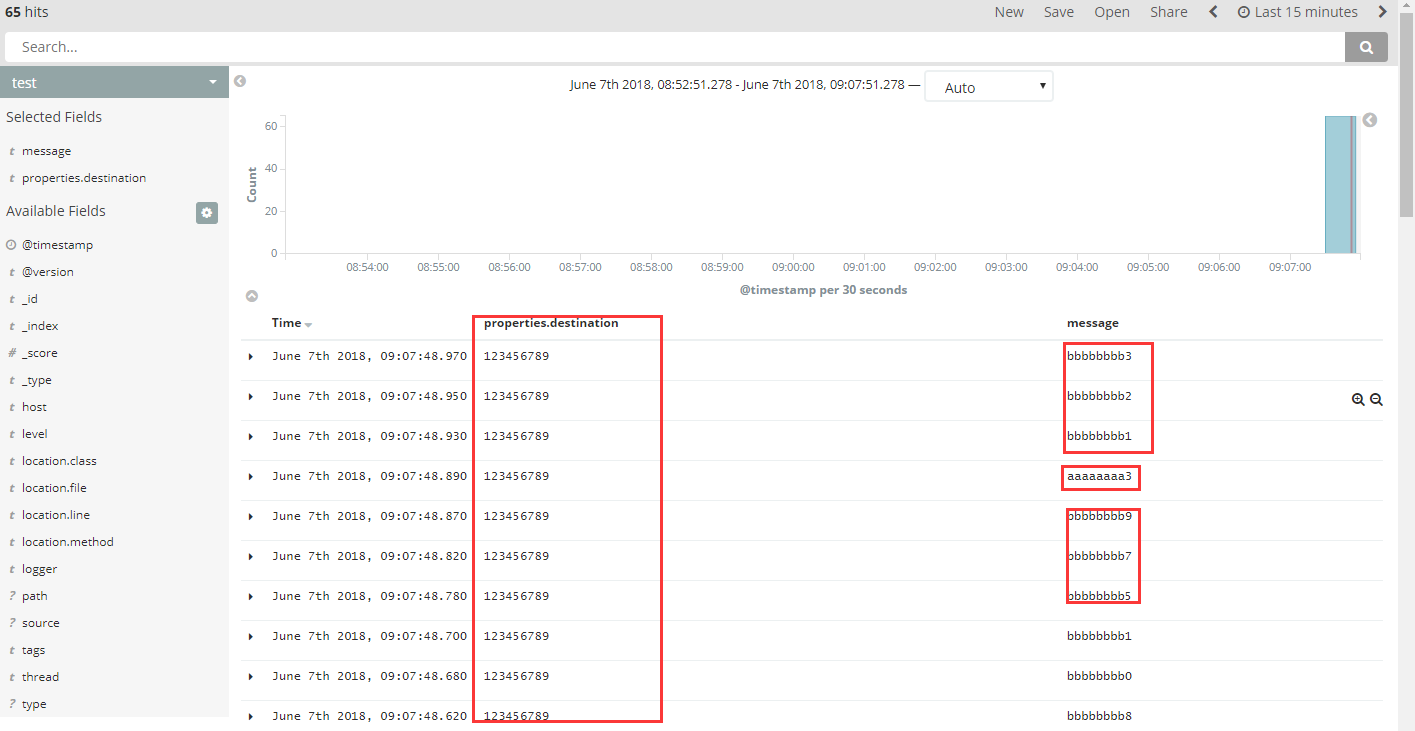
大家可以看到日志输出内容包含了两个方法,都包含相应的properties.destination字段并且值也是一样的(当然真正使用的时候destination MDC的关键字是动态的,选查询的主要关键字)
这样通过关键字一下就能把所有相关的日志都查询出来就能看出数据整个处理流程,这样就非常方便我们的查询定位排查问题
我上面的代码有一段注释不知道大家有没有注意到
就是下面这段
<!-- <additionalField>
<key>traceId</key>
<value>@{destination}</value>
</additionalField> -->
其实我们把<mdc>true</mdc>这句设为false也是可以了不过需要添加一个字段来引用数据(把上面的配置取消注释)这样我们就可以自定义命名跟踪字段的名称了(本人更倾向使用这种)
然后配置就办成下面这样
<appender name="redis" class="com.cwbase.logback.RedisAppender">
<tags>test</tags>
<host>10.10.12.21</host>
<port>6379</port>
<key>spp</key>
<!-- <mdc>true</mdc> -->
<callerStackIndex>0</callerStackIndex>
<location>true</location>
<additionalField>
<key>traceId</key>
<value>@{destination}</value>
</additionalField>
</appender>
然后看下效果
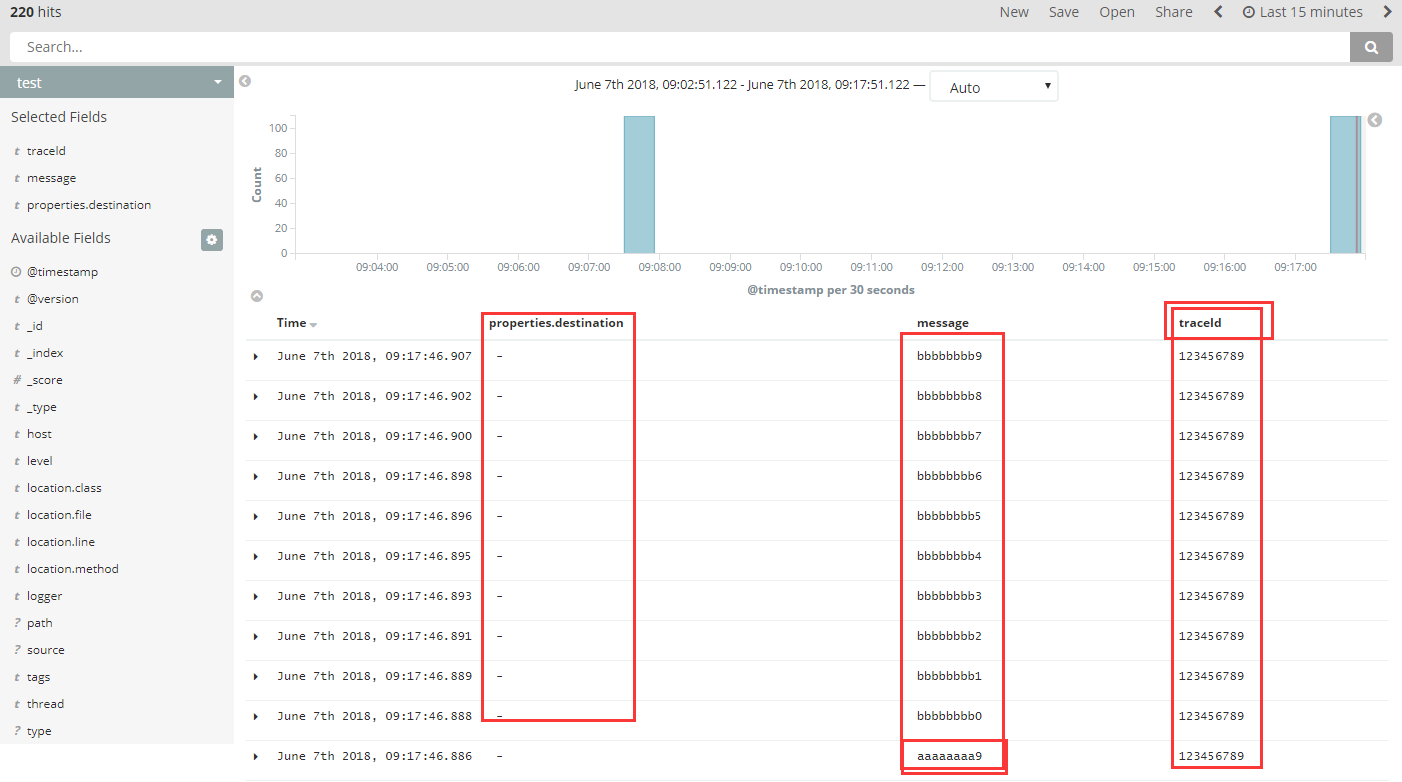
这是之前的默认字段就没有值了mdc引用的值变成我们新的字段里面去了
其实都可以开启 但是会打印两份MDC和自定义字段,这样就会重复了,所以说没必要了
好了 今天就说的这里希望对看博客的你有所帮助
日志收集(ElasticSearch)串联查询 MDC的更多相关文章
- 利用ELK构建一个小型的日志收集平台
利用ELK构建一个小型日志收集平台 伴随着应用以及集群的扩展,查看日志的方式总是不方便,我们希望可以有一个便于我们查询及提醒功能的平台:那么首先需要剖析有几步呢? 格式定义 --> 日志收集 - ...
- 快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana)
快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana) 概要说明 需求场景,系统环境是CentOS,多个应用部署在多台服务器上,平时查看应用日志及排查问题十 ...
- GlusterFS + lagstash + elasticsearch + kibana 3 + redis日志收集存储系统部署 01
因公司数据安全和分析的需要,故调研了一下 GlusterFS + lagstash + elasticsearch + kibana 3 + redis 整合在一起的日志管理应用: 安装,配置过程,使 ...
- 用ElasticSearch,LogStash,Kibana搭建实时日志收集系统
用ElasticSearch,LogStash,Kibana搭建实时日志收集系统 介绍 这套系统,logstash负责收集处理日志文件内容存储到elasticsearch搜索引擎数据库中.kibana ...
- Elasticsearch + Logstash + Kibana +Redis +Filebeat 单机版日志收集环境搭建
1.前置工作 1.虚拟机环境简介 Linux版本:Linux localhost.localdomain 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:2 ...
- ABP 使用ElasticSearch、Kibana、Docker 进行日志收集
ABP 使用ElasticSearch.Kibana.Docker 进行日志收集 后续会根据公司使用的技术,进行技术整理分享,都是干货哦别忘了关注我!!! 最近领导想要我把项目日志进行一个统一收集,因 ...
- 日志收集之--将Kafka数据导入elasticsearch
最近需要搭建一套日志监控平台,结合系统本身的特性总结一句话也就是:需要将Kafka中的数据导入到elasticsearch中.那么如何将Kafka中的数据导入到elasticsearch中去呢,总结起 ...
- logstash收集MySQL慢查询日志
#此处以收集mysql慢查询日志为准,根据文件名不同添加不同的字段值input { file { path => "/data/order-slave-slow.log" t ...
- 基于logstash+elasticsearch+kibana的日志收集分析方案(Windows)
一 方案背景 通常,日志被分散的储存不同的设备上.如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志.这样是不是感觉很繁琐和效率低下.开源实时日志分析ELK平台能够完美的 ...
随机推荐
- Go Web:Cookie
Cookie用来解决http协议无状态的问题. 首先,在服务端生成Cookie,然后在http响应header中设置Set-Cookie字段,客户端会读取到Set-Cookie字段后,会将cookie ...
- 自定义了一个email模块,符合大多数人的使用习惯
# coding: utf-8 import smtplib from email.mime.multipart import MIMEMultipart from email.mime.text i ...
- 脚本解决.NET MVC按钮重复提交问题
见于:Avoiding Duplicate form submission in Asp.net MVC by clicking submit twice 脚本代码: $(document).on(' ...
- 《C#并发编程经典实例》学习笔记—异步编程关键字 Async和Await
C# 5.0 推出async和await,最早是.NET Framework 4.5引入,可以在Visual Studio 2012使用.在此之前的异步编程实现难度较高,async使异步编程的实现变得 ...
- [转]windows BLE编程 net winform 连接蓝牙4.0
本文转自:https://www.cnblogs.com/webtojs/p/9675956.html winform 程序调用Windows.Devices.Bluetoot API 实现windo ...
- 【转载】 Sqlserver查看数据库死锁的SQL语句
在Sqlsever数据库中,有时候操作数据库过程中会进行锁表操作,在锁表操作的过程中,有时候会出现死锁的情况出现,这时候可以使用SQL语句来查询数据库死锁情况,主要通过系统数据库Master数据库来查 ...
- Linux日志 系统日志及分析
Linux系统拥有非常灵活和强大的日志功能,可以保存几乎所有的操作记录,并可以从中检索出我们需要的信息. 大部分Linux发行版默认的日志守护进程为 syslog,位于 /etc/syslog 或 / ...
- 25.QT-模型视图
模型视图设计模式的核心思想 使模型(数据)与视图(显示)相分离 模型只需要对外提供标准接口存取数据,无需数据如何显示 视图只需要自定义数据的显示方式,无需数据如何组织存储 当数据发生改变时,会通过信号 ...
- OpenLiveWriter.exe已停止工作---解决办法
一.起因 在win10的系统中成功的安装了OpenLiveWriter,但是在家里win7的电脑上装不上.点击 OpenLiveWriterSetup.exe的安装包后出现 OpenLiveWrite ...
- 【软工神话】第五篇(Beta收官)
前言:这应该是最后一章了,故事虽然到这就结束了,但现实里还要继续下去,希望在很久的以后来回顾时,能因自己学生时代有这样的经历而欣慰. 说明:故事中的人物均是化名,故事情节经过些许加工,故事情节并没有针 ...