彻底弄懂python编码
在编写python程序的过程中,中英文混用经常会出现编码问题。围绕此问题,本文首先介绍编码的含义及常用编码,随后列举几个python经常遇到的编码异常及解决方法,接着列举笔者在实践中遇到的异常出现的情景及原因,最后针对编码问题提出最佳实践。
一 常见编码
1.1 unicode编码
在文本文件中,看到的所有字符,包括中文,都需要在计算机中存储,而计算机只能存储0和1这样的二进制位,所以需要一种方法,将字符映射成数字,然后将数字转化为二进制位存储在计算机中。针对字符和数字的映射的问题,产生了unicode编码,unicode将世界上的所有字符映射为唯一的数字。unicode数字并不是直接就可以转化为二进制存储,比如假设中文字符‘中’映射为数字1(00000001),‘国’映射为数字2(00000010),由于汉字很多,单字节并不能表示完所有的汉字,故可能会有汉字的unicode数字为258(00000001 00000010),假设为‘京’,现在在字符串中碰到存储为00000001 00000010的二进制串,不能区分出其实际代表的是“中国”还是“京”。
针对unicode数字和二进制的映射问题,有两种解决方法:一种是每个unicode数字用固定宽度的二进制位表示,比如都用两字节,由此产生了ASCII、GB2312、GBK编码;另一种是存储的二进制位除了表示数字之外,还表示每个unicode数字的长度,由此产生了utf-8编码。
1.2 ASCII编码
ASCII编码用单字节表示字符,最高位固定为0,故最多只能表示128个字符,当编程只涉及到英文字符或数字时,不涉及中文字符时,可以使用ASCII编码。
1.3 GB2312编码、GBK
GB(GuoBiao)为国标,GBK(GuoBiao Kuozhan)表示国标扩展。GB2312兼容ASCII编码,对于ASCII可以表示的字符,如英文字符‘A’、‘B’等,在GB2312中的编码和ASCII编码一致,占一个字节,对于ASCII不能表示的字符,GB2312用两个字节表示,且最高位不为0,以防和ASCII字符冲突。例如:‘A’在GB2312中存储的字节十六进制为41,在ASCII中也是41,中文字符‘中’在GB2312中存储的两个字节十六进制为D6D0,最高位为1不为0。
GB2312只有6763个汉字,而汉字特别多。GBK属于GB2312的扩展,增加了很多汉字,同时兼容GB2312,同样用两个字节表示非ASCII字符。
1.4 UTF-8编码
和GB系列不同,UTF-8可以将全世界所有的unicode数字表示出来。UTF-8兼容ASCII编码,不兼容GB系列编码,因此,若文本中UTF-8和GB系列编码混用,会出现乱码问题。UTF-8对于每个字符的存储,用最高二进制位开始连续1的个数表示字的长度,最高位为0表示单字节,用来兼容ASCII字符,为110表示双字节,非字符首字节的字节都以10开始,如下表格所示。例如:字符‘中’的unicode编码为2D4E(00101101 01001110),用UTF-8存储的二进制为E4B8AD(11100100 10111000 10101101 ),存储在计算机中的首字节为1110开头,表示此字符占三个字节,去掉开始字节表示长度的1110和其余字节开头的10,可以得到01001110 00101101(4E2D),可以看到和unicode数字刚好相反,是因为是大端存储方式,高字节存储在内存中的低地址端,反过来即为unicode编码。
| 字节数 | 二进制编码格式 |
|---|---|
| 单字节 | 0XXXXXXX |
| 双字节 | 110XXXXX 10XXXXXX |
| 三字节 | 1110XXXX 10XXXXXX 10XXXXXX |
| 四字节 | 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX |
| 五字节 | 111110XX 10XXXXXX 10XXXXXX 10XXXXXX 10XXXXXX |
| 六字节 | 1111110X 10XXXXXX 10XXXXXX 10XXXXXX 10XXXXXX 10XXXXXX |
二 python字符序列及编码问题
上一节对几种常见的编码原理做出了介绍,以便理解python由于编码引起的异常,本节将对python中的字符串作出介绍,并在此基础上提出几种常见的编码异常,并提供解决方案。
2.1 python2和python3字符序列
python2中字符序列有两种类型:unicode和str。unicode字符序列存储的元素为unicode字符。如图2.1所示,unicode_string代表unicode字符序列“中国”,其长度为2,恰好表示两个unicode字符。
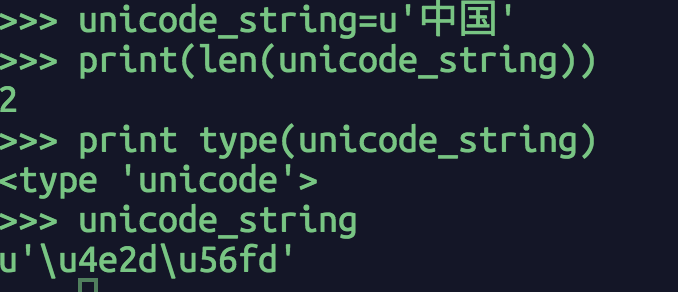
图2.1 unicode字符序列
python2中的另一种字符序列是str类型,str类型的字符序列其实是unicode字符序列encode之后的值,用不同的编码类型encode,得出的值不一样。str字符序列的元素为字节,如图2.2所示,“中国” 的str字符序列长度为6,为UTF-8编码后所占字节长度。
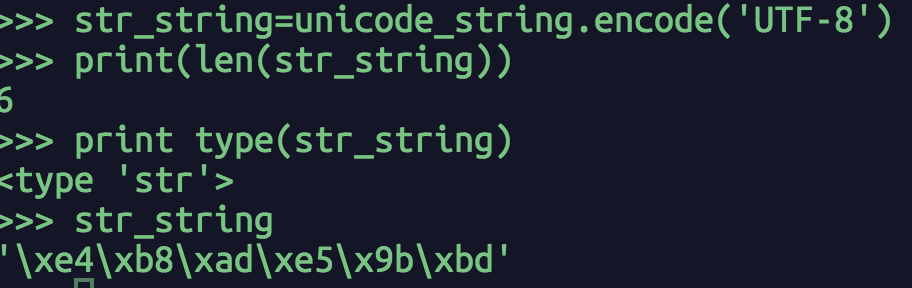
图2.2 str字符序列
与unicode字符串转化为str类型用encode相反,str类型的字符序列转化为unicode字符串,可以通过decode方法,如图2.3所示:
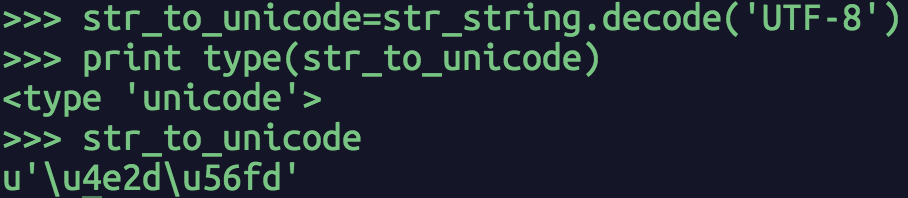
图2.3 str转化为unicode
python3中的字符序列也有两种类型:bytes和str。python3中的bytes和python2中的str相似,str和python2中的unicode相似。这里要注意,str类型在python3和python2中都有,但含义完全变了。
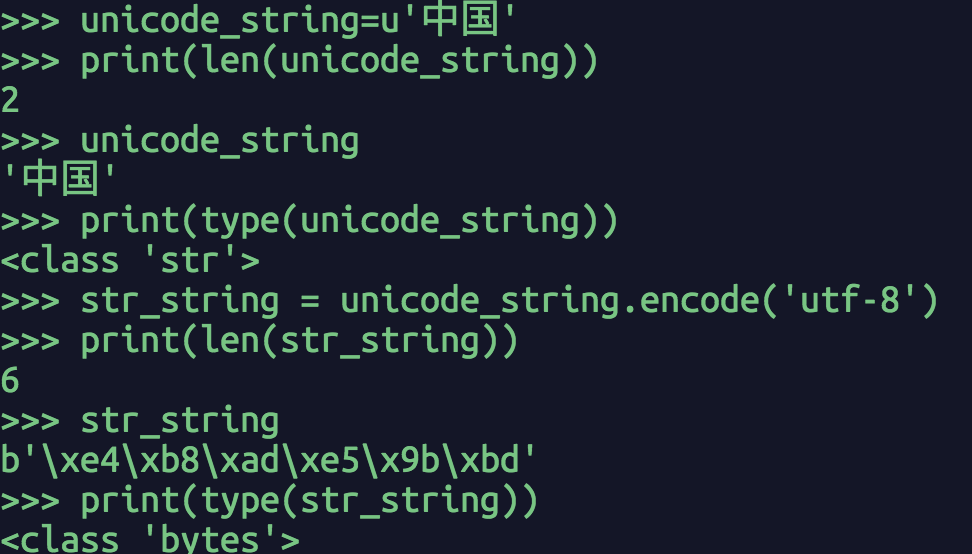
图2.4 python3的str和bytes字符序列
2.2常见编码问题
2.2.1 UnicodeEncoderError
将文本转化为字节序列时,若有字符在目标编码中没有定义,则会出现UnicodeEncoderError。如图2.5所示,由于中文字符在ascii编码中无定义,则会报出编码错误。对于此类问题,需选择合适的编码类型,比如含有中文字符,一般用UTF-8编码类型对unicode字符串编码。

图2.5 UnicodeEncodeError示例
2.2.2 UnicodeDecodeError
把二进制序列转化为文本时,遇到无法转换的字节序列,则会发生此异常。比如用UTF-8编码后的二进制序列,用GB2312解码,由于两种编码不兼容,用GB2312不能识别字节序列,则会出现异常,如图2.6所示。

图2.6 UnicodeDecodeError示例
碰到这种异常,是由于decode使用的编码和字节序列的编码不一致,可以用字符编码侦测包chardet检测字节序列的编码,然后再用此编码解码。如图2.7所示:

图2.7 编码检测
三 实践中常见编码异常场景
3.1 字符串连接
python代码
# -*- coding: utf-8 -*-
unicode_string=u'中国'
str_string='中国'
merge_string= str_string+unicode_string #UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
python代码
# -*- coding: utf-8 -*-
unicode_string=u'中国'
str_string='中国'
"中国:%s" % str_string
#两种字符序列混用,相当于"中国:%s".decode('ascii')%unicode_string
"中国:%s" % unicode_string #UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
u"中国:%s"%unicode_string
#两种字符序列混用,相当于u"中国:%s"%str_string.decode('ascii')
u"中国:%s"%str_string #UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
当str类型字符串和unicode类型字符串混合运算时,python默认会将str类型字符串转化为unicode字符串,由于不知道str类型字符串的编码格式,会使用 sys.getdefaultencoding() ,而默认的defaultencoding一般是ascii,故会出错。
3.2 print中文问题
如图3.1,python打印变量时,操作系统会对变量进行相应的处理,若变量是str类型,则操作系统直接发送到终端显示,若变量是unicode类型,则操作系统会对变量用sys.stdout.encoding编码对变量encode,若变量中含有sys.stdout.encoding未定义字符,则会出现UnicodeEncodeError。编码后字节序列被发送给终端,假若终端设置的编码和str编码不一致,终端就会显示出乱码。

图3.1 print过程
四 最佳实践
编写python程序时,为避免不同类型字符串混用出现编解码异常,要把编码和解码操作放在程序的最外围来做,程序的核心逻辑统一使用unicode字符类型。下面分别对python2和python3编写了外围编码转换工具类。
#python2,unicode和utf-8类型的str互相转换
#file:python2_endecode_helper.py # -*- coding: utf-8 -*-
def to_unicode(unicode_or_str):
if isinstance(unicode_or_str, str):
value = unicode_or_str.decode('UTF-8')
else:
value = unicode_or_str
return value def to_str(unicode_or_str):
if isinstance(unicode_or_str, unicode):
value = unicode_or_str.encode('UTF-8')
else:
value = unicode_or_str
return value if __name__=='__main__':
unicode_string = u'中国'
value = to_str(unicode_string)
print type(value) #<type 'str'>
value = to_unicode(value)
print type(value) #<type 'unicode'>
#python3,str和bytes类型相互转换工具类
#file:python3_endecode_helper.py
def to_str(bytes_or_str):
if isinstance(bytes_or_str,bytes):
value = bytes_or_str.decode('UTF-8')
else:
value = bytes_or_str
return value def to_bytes(bytes_or_str):
if isinstance(bytes_or_str,str):
value = bytes_or_str.encode('UTF-8')
else:
value = bytes_or_str
return value if __name__=='__main__':
str_string = u'中国'
value = to_bytes(str_string)
print(type(value)) #<class 'bytes'>
value = to_str(value)
print(type(value)) #<class 'str'>
参考文献
[1] Brett Slatkin. Effective Python[M]. 北京: 机械工业出版社, 2016: 5-7
[2] Luciano Ramalho. Fluent Python[M]. 北京: 人民邮电出版社, 2017: 89- 91
[3] Jinhaolin. python2编码总结. https://www.cnblogs.com/jinhaolin/p/5128973.html
[4] In355hz. 也谈 Python 的中文编码处理. http://in355hz.iteye.com/blog/1860787
[5] 董公子. python中文编码问题:print打印中文异常及显示乱码问题分析与解决. https://blog.csdn.net/qq_26580757/article/details/79922043
彻底弄懂python编码的更多相关文章
- 彻底弄懂 Unicode 编码
彻底弄懂 Unicode 编码 今天,在学习 Node.js 中的 Buffer 对象时,注意到它的 alloc 和 from 方法会默认用 UTF-8 编码,在数组中每位对应 1 字节的十六进制数. ...
- 一篇文章彻底弄懂Base64编码原理
在互联网中的每一刻,你可能都在享受着Base64带来的便捷,但对于Base64的基础原理又了解多少?今天这篇博文带领大家了解一下Base64的底层实现. Base64的由来 目前Base64已经成为网 ...
- 学以致用三十六-----弄懂python装饰器
看了海峰老师讲解的装饰器视频,讲解的非常棒.根据视频,记录笔记如下: 装饰器: 1.本质是函数,用def来定义.功能就是用来(装饰)其他函数,为其他函数添加附加功能 现有两个函数如下, def tes ...
- 一篇文章彻底弄懂Base64编码原理(转载)
在互联网中的每一刻,你可能都在享受着Base64带来的便捷,但对于Base64的基础原理又了解多少?今天这篇博文带领大家了解一下Base64的底层实现. Base64的由来 目前Base64已经成为网 ...
- 知识扩展——(转)一篇文章彻底弄懂Base64编码原理
在互联网中的每一刻,你可能都在享受着Base64带来的便捷,但对于Base64的基础原理又了解多少?今天这篇博文带领大家了解一下Base64的底层实现. 一.Base64的由来 目前Base64已经成 ...
- 如何用最快的速度读出大小为10G的文件的行数?弄懂 python 的迭代器
with open('rm_keys.txt', 'r', encoding = 'utf-8') as f: count = 0 for line in f: 7 count += 1 print( ...
- python中self与__init__怎么解释能让小白弄懂?
python中self与__init__怎么解释能让小白弄懂? 这个问题其实没那么简单. 只说一下自己的理解. python 里所有的 object 都有三个属性, 标识(identity), 类型( ...
- 我终于弄懂了Python的装饰器(一)
此系列文档: 1. 我终于弄懂了Python的装饰器(一) 2. 我终于弄懂了Python的装饰器(二) 3. 我终于弄懂了Python的装饰器(三) 4. 我终于弄懂了Python的装饰器(四) 一 ...
- 我终于弄懂了Python的装饰器(二)
此系列文档: 1. 我终于弄懂了Python的装饰器(一) 2. 我终于弄懂了Python的装饰器(二) 3. 我终于弄懂了Python的装饰器(三) 4. 我终于弄懂了Python的装饰器(四) 二 ...
随机推荐
- vue-cli入门
这也仅仅是入门而已了☺ 自己也在慢慢学习中,不对的地方希望大佬可以多多指教,请不吝赐教,感激不尽. 这章主要是搭建环境: 1.安装node环境 从官网下载并安装node,傻瓜操作,安装完成之后,命令行 ...
- 模板基础model
一.Django-model基础 1.1ORM 映射关系: 表名<---------->类名 字段<---------->属性 表记录<---------->类实例 ...
- 洛谷P1746 离开中山路
https://www.luogu.org/problemnew/show/P1746 思路:用广搜从起点开始,遍历所有可达的点,再往下遍历直到到达终点,所以能保证得到的结果一定是最优解 #inclu ...
- 文本超过控件长度自动显示省略号的css
overflow: hidden; white-space: nowrap; text-overflow: ellipsis;
- js:函数与变量作用域的提升
一.要彻底理解JS的作用域和Hoisting,只要记住以下三点即可: 1.所有申明都会被提升到作用域的最顶上 2.同一个变量申明只进行一次,并且因此其他申明都会被忽略 3 ...
- 使用Spring+MySql实现读写分离(一)关于windows下安装mysql5.6
前面讲过关于mysql的优化,主要是建表时对于大量数据的表添加索引机制,提高查询效率,以及一些sql语句的简单优化,毕竟我也不是专业的数据库管理员,大牛勿喷. 今天写两章关于javaweb项目中,对于 ...
- [转] Linux 内核中的 Device Mapper 机制
本文结合具体代码对 Linux 内核中的 device mapper 映射机制进行了介绍.Device mapper 是 Linux 2.6 内核中提供的一种从逻辑设备到物理设备的映射框架机制,在该机 ...
- 微服务中Feign快速搭建
在微服务架构搭建声明性REST客户端[feign].Feign是一个声明式的Web服务客户端.这使得Web服务客户端的写入更加方便 要使用Feign创建一个界面并对其进行注释.它具有可插入注释支持,包 ...
- 吴恩达机器学习笔记3-代价函数II(cost function)
本节学习内容:通过使得θ = 0从而简化代价函数来初步了解代价函数的特性及作用原理.
- python zeros用法实例
编程就是踩坑的过程.今天又踩了一个坑,做个积累吧. 在给数组赋初始值的时候,经常会用到0数组,而Python中,我们使用zero()函数来实现.在默认的情况下,zeros创建的数组元素类型是浮点型的, ...