HBase最佳实践之Scan
一.简介
二.ScanAPI

整个流程可以分为如下几个步骤:
- next请求首先会检查客户端缓存中是否存在还没有读取的数据行,如果有就直接返回,否则需要将next请求给HBase服务器端【RegionServer】。
- 如果客户端缓存已经没有扫描结果,就会将next请求发送给HBase服务器端。默认情况下,一次next请求仅可以请求100行数据【或者返回结果集总大小不超过2M】。
- 服务器端接收到next请求之后就开始从BlockCache、HFile以及memcache中一行一行进行扫描,扫描的行数达到100行之后就返回给客户端,客户端将这100条数据缓存到内存并返回一条给上层业务。
- HBase本身存储了海量数据,所以很多场景下一次scan请求的数据量都会比较大。如果不限制每次请求的数据集大小,很可能会导致系统带宽吃紧从而造成整个集群的不稳定。
- 如果不限制每次请求的数据集大小,很多情况下可能会造成客户端缓存OOM掉。
- 如果不限制每次请求的数据集大小,很可能服务器端扫描大量数据会花费大量时间,客户端和服务器端的连接就会timeout。
这样的设计有没有瑕疵?next策略可以避免在大数据量的情况下发生各种异常情况,但这样的设计对于扫描效率似乎并不友好,这里举两个例子:
- scan并没有并发执行。这里可能很多看官会问:扫描数据分布在不同的region难道也不会并行执行扫描吗?是的,确实不会,至少在现在的版本中没有实现。这点一定出乎很多读者的意料,我们知道get的批量读请求会将所有的请求按照目标region进行分组,不同分组的get请求会并发执行读取。然而scan并没有这样实现。
- 大家有没有注意到上图中步骤3和步骤4之间HBase服务器端扫描数据的时候HBase客户端在干什么?阻塞等待是吧。确实,所以从客户端视角来看整个扫描时间=客户端处理数据时间+服务器端扫描数据时间,这能不能优化?
ScanAPI应用场景
- 批量OLAP扫描业务建议不要使用ScanAPI,ScanAPI适用于少量数据扫描场景(OLTP场景)
- 建议所有scan尽可能都设置startkey以及stopkey减少扫描范围
- 建议所有仅需要扫描部分列的scan尽可能通过接口setFamilyMap设置列族以及列
三.TableScanMR
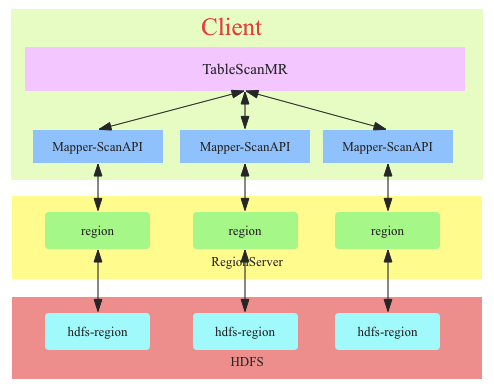
- TableScanMR设计为OLAP场景使用,因此在离线扫描时尽可能使用该中方式
- TableScanMR原理上主要实现了ScanAPI的并行化,将scan按照region边界进行切分。这种场景下整个scan的时间基本等于最大region扫描的时间。在某些有数据倾斜的场景下可能出现某一个region上有大量待扫描数据,而其他大量region上都仅有很少的待扫描数据。这样并行化效果并不好。针对这种数据倾斜的场景TableScanMR做了平衡处理,它会将大region上的scan切分成多个小的scan使得所有分解后的scan扫描的数据量基本相当。这个优化默认是关闭的,需要设置参数”hbase.mapreduce.input.autobalance”为true。因此建议大家使用TableScanMR时将该参数设置为true。
- 尽量将扫描表中相邻的小region合并成大region,而将大region切分成稍微小点的region
- TableScanMR中Scan需要注意如下两个参数设置:
|
1
2
3
|
Scan scan = new Scan();scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobsscan.setCacheBlocks(false); // don't set to true for MR jobs |
四.SnapshotScanMR
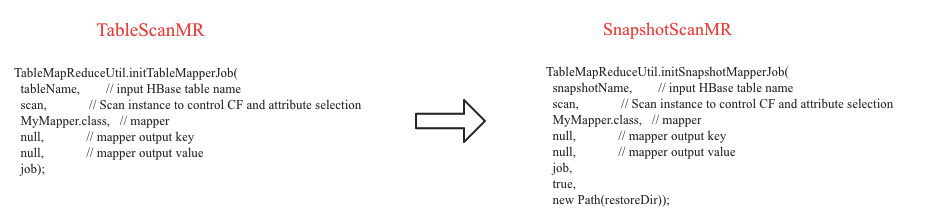
- 从命名来看就知道,SnapshotScanMR扫描于原始表对应的snapshot之上(更准确来说根据snapshot restore出来的hfile),而TableScanMR扫描于原始表。
- SnapshotScanMR直接会在客户端打开region扫描HDFS上的文件,不需要发送Scan请求给RegionServer,再有RegionServer扫描HDFS上的文件。是的,你没看错,是在客户端直接扫描HDFS上的文件,这类scanner称之为ClientSideRegionScanner。
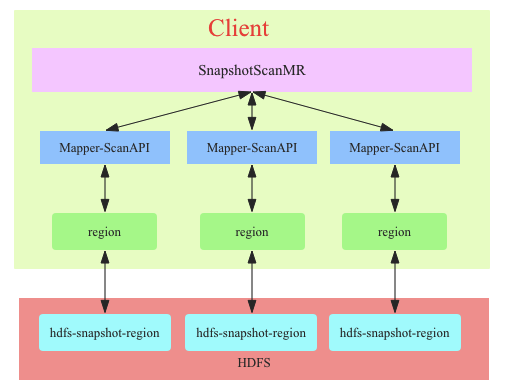
- 减小对RegionServer的影响。很显然,SnapshotScanMR这种绕过RegionServer的实现方式最大限度的减小了对集群中其他业务的影响。
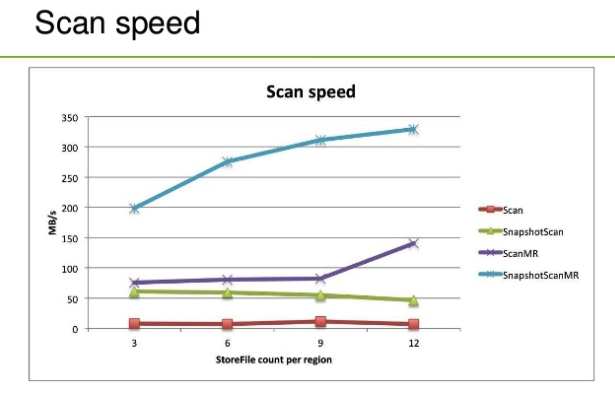
- 极大的提升了扫描效率。SnapshotScanMR相比TableScanMR在扫描效率上会有2倍~N倍的性能提升(下一小节对各种扫描用法性能做个对比评估)。有人又要问了,为什么会有这么大的性能提升?个人认为主要有如下两个方面的原因:
- 扫描的过程少了一次网络传输,对于大数据量的扫描,网络传输花费的时间是非常庞大的,这主要可能牵扯到数据的序列化以及反序列化开销。
- TableScanMR扫描中RegionServer很可能会成为瓶颈,而SnapshotScanMR扫描并没有这个瓶颈点。
基本性能对比

HBase最佳实践之Scan的更多相关文章
- HBase最佳实践(好文推荐)
HBase最佳实践-写性能优化策略 HBase最佳实践-管好你的操作系统 HBase最佳实践之列族设计优化 [大数据]HBase最佳实践 – 集群规划
- 「从零单排HBase 06」你必须知道的HBase最佳实践
前面,我们已经打下了很多关于HBase的理论基础,今天,我们主要聊聊在实际开发使用HBase中,需要关注的一些最佳实践经验. 1.Schema设计七大原则 1)每个region的大小应该控制在10G到 ...
- HBase最佳实践-列族设计优化
本文转自hbase.收藏学习下. 随着大数据的越来越普及,HBase也变得越来越流行.会用HBase现在已经变的并不困难,然而,怎么把它用的更好却并不简单.那怎么定义'用的好'呢?很简单,在保证系统稳 ...
- HBase最佳实践 - 集群规划
本文由 网易云发布. 作者:范欣欣 本篇文章仅限本站分享,如需转载,请联系网易获取授权. HBase自身具有极好的扩展性,也因此,构建扩展集群是它的天生强项之一.在实际线上应用中很多业务都运行在一个 ...
- HBase最佳实践-写性能优化策略
本篇文章来说道说道如何诊断HBase写数据的异常问题以及优化写性能.和读相比,HBase写数据流程倒是显得很简单:数据先顺序写入HLog,再写入对应的缓存Memstore,当Memstore中数据大小 ...
- HBase最佳实践-读性能优化策略
任何系统都会有各种各样的问题,有些是系统本身设计问题,有些却是使用姿势问题.HBase也一样,在真实生产线上大家或多或少都会遇到很多问题,有些是HBase还需要完善的,有些是我们确实对它了解太少.总结 ...
- HBase最佳实践-管好你的操作系统
本文由 网易云发布. 作者:范欣欣 本篇文章仅限本站分享,如需转载,请联系网易获取授权. 操作系统这个话题其实很早就想拿出来和大家分享,拖到现在一方面是因为对其中各种理论理解并不十分透彻,怕讲不好: ...
- HBase最佳实践-用好你的操作系统
终于又切回HBase模式了,之前一段时间因为工作的原因了解接触了一段时间大数据生态的很多其他组件(诸如Parquet.Carbondata.Hive.SparkSQL.TPC-DS/TPC-H等),虽 ...
- Bulk Load-HBase数据导入最佳实践
一.概述 HBase本身提供了非常多种数据导入的方式,通常有两种经常使用方式: 1.使用HBase提供的TableOutputFormat,原理是通过一个Mapreduce作业将数据导入HBase 2 ...
随机推荐
- sql server 索引阐述系列五 索引参数与碎片
-- 创建聚集索引 create table [dbo].[pub_stocktest] add constraint [pk_pub_stocktest] primary key clustered ...
- 详解CSS的Flex布局
本文由云+社区发表 Flex是Flexible Box 的缩写,意为"弹性布局",是CSS3的一种布局模式.通过Flex布局,可以很优雅地解决很多CSS布局的问题.下面会分别介绍容 ...
- 【mac】ansible安装及基础使用
安装 环境释放 mac 10.12.5 #more /System/Library/CoreServices/SystemVersion.plist 安装命令 #ruby -e "$(cur ...
- shell编程基础(六): 透彻解析查找命令find
find 由于find具有强大的功能,所以它的选项也很多,其中大部分选项都值得我们花时间来了解一下.即使系统中含有网络文件系统( NFS),find命令在该文件系统中同样有效,只要你具有相应的权限. ...
- [转]分别使用Node.js Express 和 Koa 做简单的登录页
本文转自:https://blog.csdn.net/weixin_38498554/article/details/79204240 刚刚学了Koa2,由于学的不是很深,并没有感受到网上所说的Koa ...
- 【转载】ASP.NET实现文件下载的功能
文件下载是很多网站中含有的常用功能,在ASP.NET中可以使用FileStream类.HttpRequest对象.HttpResponse对象相互结合,实现输出硬盘文件的功能.该方法支持大文件.续传. ...
- 怎样监听vue.js中v-for全部渲染完成?
vue里面本身带有两个回调函数: 一个是Vue.nextTick(callback),当数据发生变化,更新后执行回调. 另一个是Vue.$nextTick(callback),当dom发生变化,更新后 ...
- element-ui el-input只显示下划线
只需要增加样式 .el-input__inner { width: 220px; border-top-width: 0px; border-left-width: 0px; border-right ...
- 【转载】.NET开源快速开发框架Colder(NET452+AdminLTE版)
.NET开源快速开发框架Colder(NET452+AdminLTE版) 简介 本框架旨在为.NET开发人员提供一个Web后台快速开发框架,采用本框架,能够极大的提高项目开发效率. 本版本框架采后端采 ...
- curl模拟ip和来源进行网站采集的实现方法
对于限制了ip和来源的网站,使用正常的采集方式是不行的.这里说我的一种方法吧,使用php的curl类实现模拟ip和来源,可以实现采集限制ip和来源的网站. 1.设置页面限制ip和来源访问比如服务端的s ...