Python爬虫之ip代理池
可能在学习爬虫的时候,遇到很多的反爬的手段,封ip 就是其中之一。
对于封IP的网站。需要很多的代理IP,去买代理IP,对于初学者觉得没有必要,每个卖代理IP的网站有的提供了免费IP,可是又很少,写了个IP代理池 。学习应该就够了
ip代理池:
1,在各大网站爬去免费代理ip
2,检查ip可用 可用存入数据库1和2
3,在数据库1中拿出少量代理ip存入数据库2(方便维护)
4,定时检查数据库1和数据库2的代理数量,以及是否可用
5,调用端口
1,在各大网站爬去免费代理ip
def IPList_61():
for q in [1,2]:
url='http://www.66ip.cn/'+str(q)+'.html'
html=Requestdef.get_page(url)
if html!=None:
#print(html)
iplist=BeautifulSoup(html,'lxml')
iplist=iplist.find_all('tr')
i=2
for ip in iplist:
if i<=0:
loader=''
#print(ip)
j=0
for ipport in ip.find_all('td',limit=2):
if j==0:
loader+=ipport.text.strip()+':'
else:
loader+=ipport.text.strip()
j=j+1
Requestdef.inspect_ip(loader)
i=i-1
time.sleep(1)
多写几个这样的方法

2,检查ip可用 可用存入数据库1,和2 3,在数据库1中拿出少量代理ip存入数据库2(方便维护)
def inspect_ip(ipprot):
2 time.sleep(1)
3 herder={
4 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
5 'Accept-Encoding':'gzip, deflate',
6 'Accept-Language':'zh-CN,zh;q=0.9',
7 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
8 'Upgrade-Insecure-Requests':'1'
9
10 }
11
12 url='https://www.baidu.com'
13 proxies = { "http": "http://"+str(ipprot) }
14 request=requests.get(url,headers=herder,proxies=proxies)
15 if request.status_code==200:
16 print('可用代理'+ipprot)
17 if Db.r.llen('Iplist')<=50:
18 Db.add_ip(ipprot)
19 #Alt.iplist.append(ipprot)
20
21 else:
22 Db.add_ips(ipprot)
23 else:
24 print('不可用代理'+ipprot)
我这里是用的www.baidu.com检测的 给主IP的数据库长度是50 (太多了不好维护)
4,定时检查数据库1和数据库2的代理数量,以及是否可用
#检查ip池数量
def time_ip(): while True:
time.sleep(5)
Db.act_lenip() #检查备用池数量
def time_ips():
while True:
time.sleep(30)
#当备用池数量小于100 再次获取
if Db.len_ips()<100:
print('填数据')
Acting_ip.iplist()
#程序入口
if __name__ == '__main__': t1=threading.Thread(target=time_ip)
t1.start()
t2=threading.Thread(target=time_ips)
t2.start()
t1.join()
t2.join()
给他2个线程
Db.py
1 #coding:utf-8
2 import redis
3 import Requestdef
4 r = redis.Redis(host='127.0.0.1', port=6379)#host后的IP是需要连接的ip,本地是127.0.0.1或者localhost
5 #主ip池
6 def add_ip(ip):
7 r.lpush('Iplist',ip)
8 #备用ip池
9 def add_ips(ip):
10 r.lpush('Iplists',ip)
11 #备用ip池第一个开始取出
12 def app_ips():
13 i=str(r.lindex('Iplists',1),encoding='utf-8')
14 r.lrem('Iplists',i,num=0)
15 return i
16 def len_ips():
17 return r.llen('Iplists')
18 def len_ip():
19 return r.llen('Iplist')
20 #第一个开始取出
21 def app_ip():
22 i=str(r.lpop('Iplist'),encoding='utf-8')
23 return i
24 #取出从最后一个开始
25 def rem_ip():
26 i=str(r.rpop('Iplist'),encoding='utf-8')
27 return i
28 #检查主ip池
29 def act_db():
30 for i in range(int(r.llen('Iplist')/2)):
31 Requestdef.inspect_ip(rem_ip())
32
33 #如果ip池数量少于25个 则填满
34 def act_lenip():
35 if r.llen('Iplist')<25:
36 print('填ip')
37 while r.llen('Iplist')<=50:
38 Requestdef.inspect_ip(app_ips())
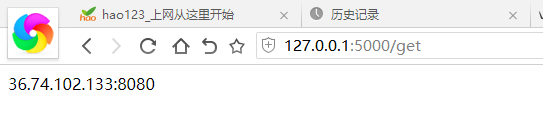
5,调用端口 使用flask库创建接口
1 from flask import Flask
2 import Db
3
4 app = Flask(__name__)
5
6 @app.route('/', methods=['GET'])
7 def home():
8 return 'What is?'
9
10 @app.route('/get', methods=['GET'])
11 def homsse():
12 return Db.app_ip()
13 #线程池数量
14 @app.route('/count', methods=['GET'])
15 def homsssse():
16 return str(Db.len_ip())
17 app.run(debug=True)
就完成了
运行api
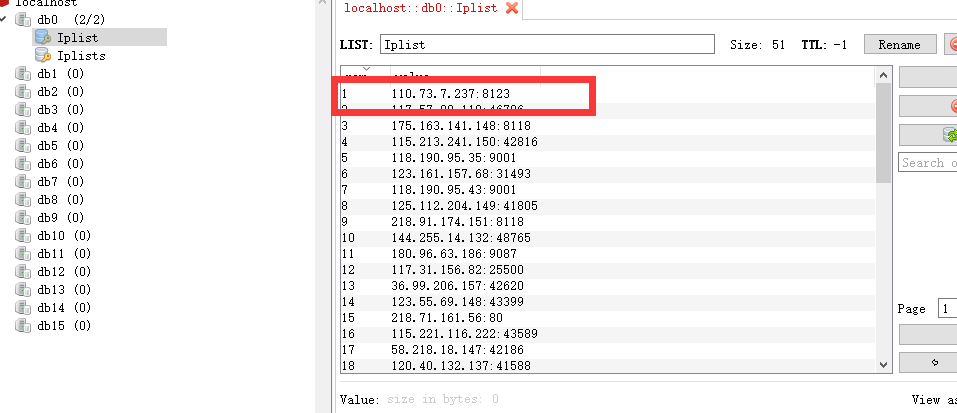
数据库里面的 Iplist为主Ip池 iplist 为备用ip池
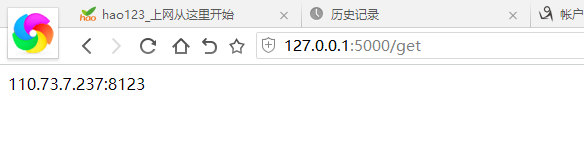
用get调用 用一次就删一个
小白代码
Python爬虫之ip代理池的更多相关文章
- python爬虫实战(三)--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)
在学习scrapy爬虫框架中,肯定会涉及到IP代理池和User-Agent池的设定,规避网站的反爬. 这两天在看一个关于搜狗微信文章爬取的视频,里面有讲到ip代理池和用户代理池,在此结合自身的所了解的 ...
- python爬虫18 | 就算你被封了也能继续爬,使用IP代理池伪装你的IP地址,让IP飘一会
我们上次说了伪装头部 ↓ python爬虫17 | 听说你又被封 ip 了,你要学会伪装好自己,这次说说伪装你的头部 让自己的 python 爬虫假装是浏览器 小帅b主要是想让你知道 在爬取网站的时候 ...
- python爬虫(3)——用户和IP代理池、抓包分析、异步请求数据、腾讯视频评论爬虫
用户代理池 用户代理池就是将不同的用户代理组建成为一个池子,随后随机调用. 作用:每次访问代表使用的浏览器不一样 import urllib.request import re import rand ...
- 静听网+python爬虫+多线程+多进程+构建IP代理池
目标网站:静听网 网站url:http://www.audio699.com/ 目标文件:所有在线听的音频文件 附:我有个喜好就是听有声书,然而很多软件都是付费才能听,免费在线网站虽然能听,但是禁ip ...
- python开源IP代理池--IPProxys
今天博客开始继续更新,谢谢大家对我的关注和支持.这几天一直是在写一个ip代理池的开源项目.通过前几篇的博客,我们可以了解到突破反爬虫机制的一个重要举措就是代理ip.拥有庞大稳定的ip代理,在爬虫工作中 ...
- 反爬虫之搭建IP代理池
反爬虫之搭建IP代理池 听说你又被封 ip 了,你要学会伪装好自己,这次说说伪装你的头部.可惜加了header请求头,加了cookie 还是被限制爬取了.这时就得祭出IP代理池!!! 下面就是requ ...
- ip代理池的爬虫编写、验证和维护
打算法比赛有点累,比赛之余写点小项目来提升一下工程能力.顺便陶冶一下情操 本来是想买一个服务器写个博客或者是弄个什么FQ的东西 最后刷知乎看到有一个很有意思的项目,就是维护一个「高可用低延迟的高匿IP ...
- 打造IP代理池,Python爬取Boss直聘,帮你获取全国各类职业薪酬榜
爬虫面临的问题 不再是单纯的数据一把抓 多数的网站还是请求来了,一把将所有数据塞进去返回,但现在更多的网站使用数据的异步加载,爬虫不再像之前那么方便 很多人说js异步加载与数据解析,爬虫可以做到啊,恩 ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
随机推荐
- 【redis 基础学习】(六)Redis HyperLogLog
摘自:http://www.mayou18.com/detail/o6M0v9mi.html Redis HyperLogLog 结构讲解 Redis 在 2.8.9 版本添加了 HyperLogL ...
- 关于Linux虚拟化技术KVM的科普 科普三(From OenHan)
http://oenhan.com/archives,包括<KVM源代码分析1:基本工作原理>.<KVM源代码分析2:虚拟机的创建与运行>.<KVM源代码分析3:CPU虚 ...
- SpringBoot如何新建一个项目 2017.12.14
http://blog.csdn.net/q649381130/article/details/77875736 从入门到精通
- springboot集成schedule(深度理解)
背景 在项目开发过程中,我们经常需要执行具有周期性的任务.通过定时任务可以很好的帮助我们实现. 我们拿常用的几种定时任务框架做一个比较: 从以上表格可以看出,Spring Schedule框架功能完善 ...
- Nginx多虚拟主机下泛域名配置
http://www.tuicool.com/articles/F3Azuq 近上一个应用,让用户可以自定义二级域名,所以要配置一个泛域名来解析用户的自定义域名. 首先来说说nginx下的泛域名配置 ...
- anguments
anguments是一个对象,长得很像数组的对象,但不是数组,而是伪数组. arguments的内容是函数运行时的实参列表 (function(d, e, f) { console.log(argum ...
- 连接Redis后执行命令错误 MISCONF Redis is configured to save RDB snapshots
今天在redis中执行setrange name 1 chun 命令时报了如下错误提示: (error) MISCONF Redis is configured to save RDB snapsho ...
- CentOS 7.2 关闭防火墙
CentOS7 的防火墙配置跟以前版本有很大区别,CentOS7这个版本的防火墙默认使用的是firewall,与之前的版本使用iptables不一样 1.关闭防火墙: systemctl stop f ...
- 用spark导入数据到hbase
集群环境:一主三从,Spark为Spark On YARN模式 Spark导入hbase数据方式有多种 1.少量数据:直接调用hbase API的单条或者批量方法就可以 2.导入的数据量比较大,那就需 ...
- 如何去掉word中的回车符??
打开word界面,点击页面左上角的"文件"按钮,进入到文件栏目中,进行设置. 进入文件之后,在左下角找到并点击"选项",进入到word的设置界面中 进入到wor ...