基于爬取百合网的数据,用matplotlib生成图表
爬取百合网的数据链接:http://www.cnblogs.com/YuWeiXiF/p/8439552.html
总共爬了22779条数据。第一次接触matplotlib库,以下代码参考了matplotlib官方文档:https://matplotlib.org/users/index.html。
数据查询用到了两个方法:getSexNumber(@sex varchar(2),@income varchar(30))、gethousingNumber(@sex varchar(2),@housing varchar(6))来简化查询语句的长度,代码如下:
go
create function getSexNumber(@sex varchar(),@income varchar())
returns int
as
begin
return(select count(id) from users where sex = @sex and income = @income)
end
go
go
create function gethousingNumber(@sex varchar(),@housing varchar())
returns int
as
begin
return(select count(id) from users where sex = @sex and housing = @housing)
end
go
以下代码为SQL Server 数据库操作:
#__author: "YuWei"
#__date: 2018/2/11
import numpy as np
import matplotlib.pyplot as plt
import pymssql def db(sql):
"""
数据库相关操作 :param sql: sql语句
:return: 查询的结果集,list封装
"""
conn = pymssql.connect(host='localhost', user='sa', password='123456c', database='Baihe', charset="utf8")
cur = conn.cursor()
cur.execute(sql)
row = cur.fetchone() # 指向结果集的第一行,
data = [] # 返回的list
while row:
rows = list(row)
for i in range(len(rows)): # 针对rows的每项编码
try:
rows[i] = rows[i].encode('latin-1').decode('gbk')
except AttributeError:pass
data.append(rows) # 向data加数据
row = cur.fetchone() #
print(data)
cur.close()
conn.close()
return data
生成各工资段人数占总人数比图:
def builder_income_ratio():
"""
生成各工资段人数占总人数比图 :return: 无
"""
data_list = db("select income,count(id) from users group by income")
income_data_list = [] # 数据
income_labels_list = [] # 图例
for data in data_list:
income_data_list.append(data[1])
income_labels_list.append(data[0])
income_data_list.remove(income_data_list[6]) # 删掉不要的数据
income_labels_list.remove(income_labels_list[6]) # 删掉不要的数据
# 画饼图
plt.pie(income_data_list,labels=income_labels_list,colors=['c','m','r','g'],startangle=30,
shadow=True,explode=(0, 0, 0.1, 0, 0, 0, 0.1, 0, 0.1, 0, 0, 0),autopct='%.1f%%')
plt.title('各工资段人数占总人数比') # 标题
plt.show() # 显示
执行效果如下:
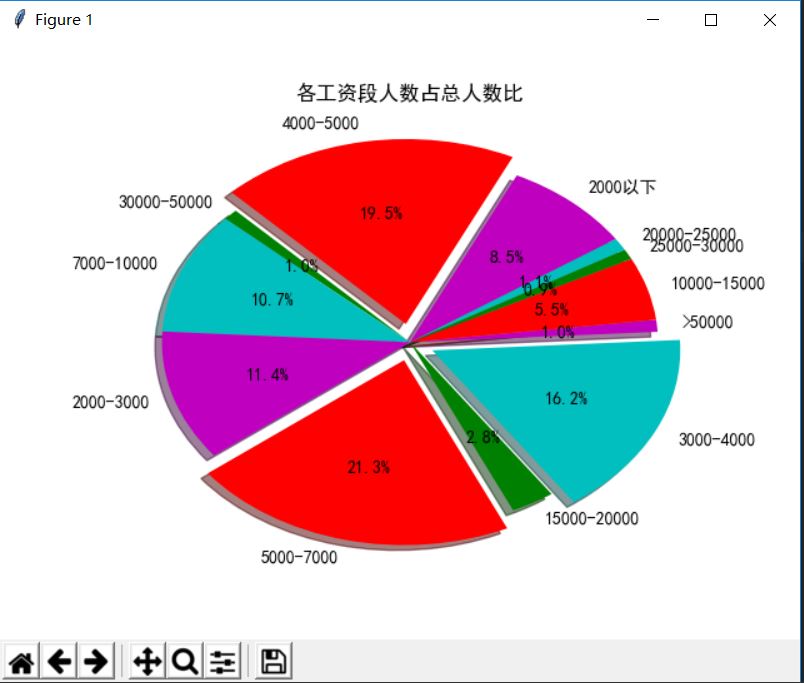
生成各工资段男,女人数图:
def builder_sex_ratio():
"""
生成各工资段男,女人数图 :return: 无
"""
data_list = db("select income,dbo.getSexNumber('男',income) as 男 ,dbo.getSexNumber('女',income) as 女 "
"from users group by income")
men = [] # 男
women = [] # 女
labels =[] # 图例
for data in data_list:
labels.append(data[0])
men.append(data[1])
women.append(data[2])
men.remove(men[6]) # 删掉不要的数据
women.remove(women[6]) # 删掉不要的数据
labels.remove(labels[6]) # 删掉不要的数据
max_line = 12 # 12个
fig,ax = plt.subplots()
line = np.arange(max_line) # [0,1,2,3,4,5,6,7,8,9,10,11]
bar_width = 0.4 # 条形之间的宽度
# 画条形图
ax.bar(line, men, bar_width,alpha=0.3, color='b',label='男')
ax.bar(line+bar_width, women, bar_width,alpha=0.3, color='r',label='女')
ax.set_xlabel('工资段')
ax.set_ylabel('人数')
ax.set_title('各工资段男,女人数图')
ax.set_xticks(line + bar_width / 2) # 保证条形居中
ax.set_xticklabels(labels)
# 画两条线
plt.plot([0.04, 1.04, 2.04, 3.04, 4.04, 5.04, 6.04, 7.04, 8.04, 9.04, 10.04, 11.04], men, label='男')
plt.plot([0.4, 1.4, 2.4, 3.4, 4.4, 5.4, 6.4, 7.4, 8.4, 9.4, 10.4, 11.4], women, label='女')
ax.legend()
fig.tight_layout()
# fig.savefig("1.png") # 生成图片
plt.show()
执行效果如下:
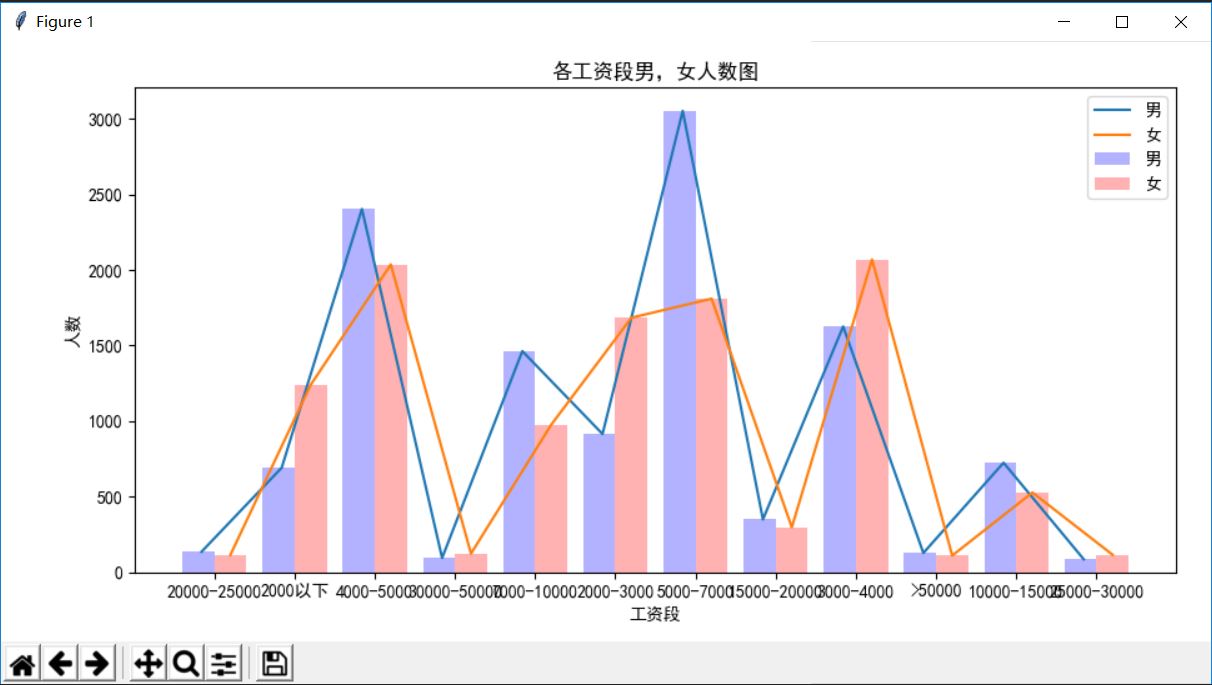
生成男,女平均身高图:
def builder_age_ratio():
"""
生成男,女平均身高图 :return:
"""
data_list = db("select sex,avg(height) as 平均升高 from users group by sex")
sex = [] # 性别
number = [] # 人数
for data in data_list:
sex.append(data[0])
number.append(data[1])
# 画条形图
plt.bar(sex[0], number[0], label="男", color='g',width=0.03)
plt.bar(sex[1], number[1], label="女", color='r',width=0.03)
plt.legend()
plt.xlabel('性别')
plt.ylabel('身高')
plt.title('男女平均身高图')
plt.show()
执行效果如下:

生成有房与无房的人数比例图:
def builder_housing_sum_ratio():
"""
生成有房与无房的人数比例图 :return:
"""
data_list = db("select housing,count(id) from users group by housing")
housing_data_list = []
housing_labels_list = []
for data in data_list:
housing_data_list.append(data[1])
housing_labels_list.append(data[0])
# 画饼图
plt.pie(housing_data_list, labels=housing_labels_list, colors=['g', 'r'], startangle=30,
shadow=True, explode=(0, 0), autopct='%.0f%%')
plt.title('有房与无房的人数比例图')
plt.show()
执行效果如下:
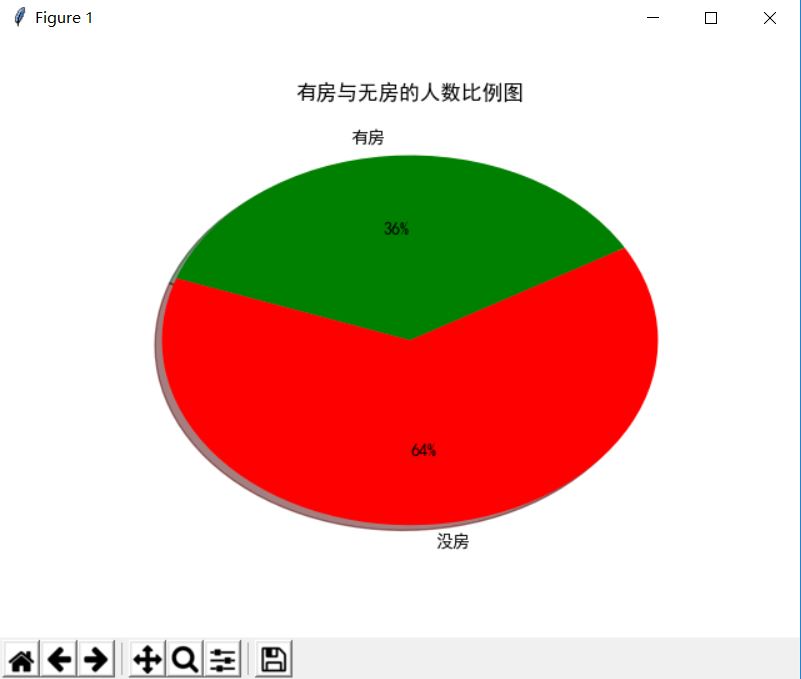
生成有无房男女人数图:
def builder_housing_ratio():
"""
生成有无房男女人数图 :return:
"""
data_list = db("select dbo.gethousing('女',housing),dbo.gethousing('男',housing) from users group by housing")
homey = [] # 有房
homem = [] # 无房
for data in data_list:
homey.append(data[0])
homem.append(data[1])
max_line = 2 # 两个
fig, ax = plt.subplots()
line = np.arange(max_line) # [0,1]
bar_width = 0.1 # 条形之间的宽度
# 画条形
ax.bar(line,homey , bar_width, alpha=0.3,color='b',label='女')
ax.bar(line+bar_width, homem, bar_width,alpha=0.3,color='r',label='男')
ax.set_xlabel('有无房')
ax.set_ylabel('人数')
ax.set_title('有无房男女人数图')
ax.set_xticks(line + bar_width / 2) # 保持居中
ax.set_xticklabels(['有房','无房'])
ax.legend()
fig.tight_layout()
plt.show()
执行效果如下:
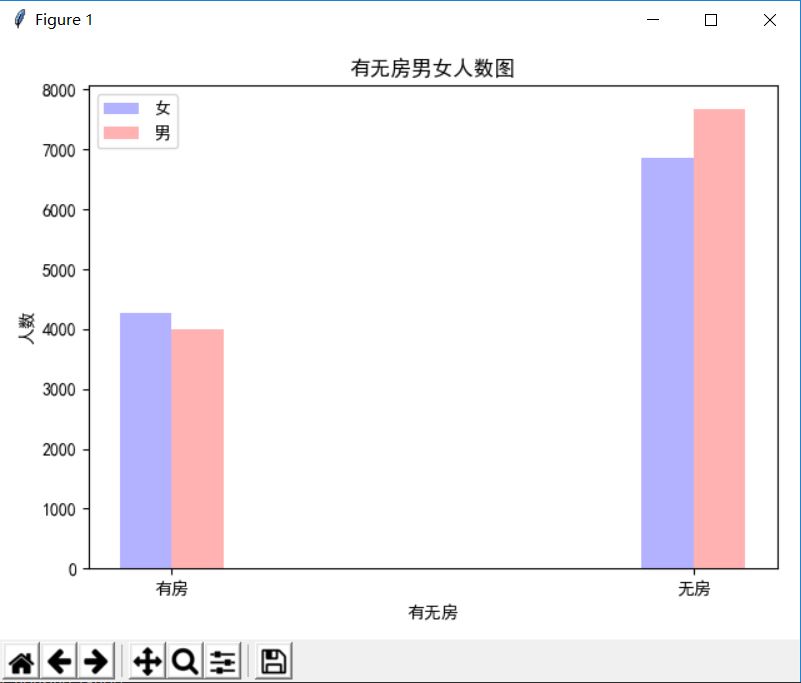
基于爬取百合网的数据,用matplotlib生成图表的更多相关文章
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- 使用python抓取婚恋网用户数据并用决策树生成自己择偶观
最近在看<机器学习实战>的时候萌生了一个想法,自己去网上爬一些数据按照书上的方法处理一下,不仅可以加深自己对书本的理解,顺便还可以在github拉拉人气.刚好在看决策树这一章,书里面的理论 ...
- python3 爬取百合网的女人们和男人们
学Python也有段时间了,目前学到了Python的类.个人感觉Python的类不应称之为类,而应称之为数据类型,只是数据类型而已!只是数据类型而已!只是数据类型而已!重要的事情说三篇. 据书上说一个 ...
- Python爬虫 爬取百合网的女人们和男人们
学Python也有段时间了,目前学到了Python的类.个人感觉Python的类不应称之为类,而应称之为数据类型,只是数据类型而已!只是数据类型而已!只是数据类型而已!重要的事情说三篇. 据书上说一个 ...
- 实例学习——爬取豆瓣网TOP250数据
开发环境:(Windows)eclipse+pydev 网址:https://book.douban.com/top250?start=0 from lxml import etree #解析提取数据 ...
- 使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- 八爪鱼采集器︱爬取外网数据(twitter、facebook)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 要想采集海外数据有两种方式:云采集+单机采集. ...
- [转]使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
随机推荐
- js取整并保留两位小数的方法
js 四舍五入函数 toFixed(),里面的参数 就是保留小数的位数.注意 toFixed()方法只针对数字类型,如果是字符类型需要使用Number()等方法先转换数字类型再使用 document. ...
- 完整CentOS搭建OpenVPN服务详细教程
一.介绍 1.定义 ① OpenVPN是一个用于创建虚拟专用网络加密通道的软件包,最早由James Yonan编写.OpenVPN允许创建的VPN使用公开密钥.电子证书.或者用户名/密码来进行身份验证 ...
- iframe及与页面之间的通信
获取iframe对象 iframe元素本身是位于父级页面中的,所以你可以像一个普通元素一样的使用和操作它 代表了iframe内容window对象是作为一个页面的属性加入到iframe中的, 为了让父级 ...
- 从零开始学习前端JAVASCRIPT — 5、JavaScript基础BOM
1:BOM(Browser Object Model)概念 window对象是BOM中所有对象的核心. 2:window属性(较少用) self:self代表自己,相当于window. windo ...
- 把VueThink整合到已有ThinkPHP 5.0项目中
享 关键字: VueThink ThinkPHP5.0 Vue2.x TP5 管理后台扩展 VueThink初认识 VueThink,是一个很不错的技术框架,由广州洪睿科技的技术团队2016年研发( ...
- 【开发技术】web.xml vs struts.xml
web.xml用来配置servlet,监听器(Listener),过滤器(filter),还有404错误跳转页面,500,等还配置欢迎页面等,总之一句话,就是系统总配置方案写在web.xml中 str ...
- mysql 分组和聚合函数
mysql 分组和聚合函数 Mysql 聚集函数有5个: 1.COUNT() 记录个数(count(1),count(*)统计表中行数,count(列名)统计列中非null数) 2.MAX() 最大值 ...
- Python3基础知识之元组、集合、字典
1.元组 元组特点元组是不可变的两个元组可以做加法,不能做减法 元组的方法 >>> S('a', 'b', 'c', 'd', 'e')>>> S=('a','b' ...
- python3 第五章 - 什么是变量、运算符、表达式
在读这一章时,运算符的内容比较多,不要去死记.现在记不住也没有关系,现在只要有这个印象.在后面的学习中,会慢慢加深理解,在理解中去记就容易得多了 1.变量 什么是变量?通俗的讲,就是存储在内存中可以变 ...
- CentOS7.3 ARM虚拟机扩容系统磁盘
由于扩容磁盘的操作非同小可,一旦哪一步出现问题,就会导致分区损坏,数据丢失等一系列严重的问题,因此建议:在进行虚拟机分区扩容之前,一定要备份重要数据文件,并且先在测试机上验证以下步骤,再应用于您的生产 ...