python爬虫(4)——正则表达式(一)
在前几篇文章中我们使用了python的urllib模块,做了一些访问网页的工作。现在介绍一个非常强大的工具——正则表达式。在讲述正则的时候,我参考了《精通正则表达式(第三版) ---Jeffrey E.F.Friedl》这本书,虽然本书的参考语言并没有python,但相通之处颇多,可以细读一部分。
通常我们在制作爬虫收集数据的时候,需要对服务器传输的数据进行匹配筛选,例如在第二篇文章中下载链家二手房页面的时候,我们只需要房址location和价格price。这时正则表达式就派上用场了。所谓正则表达式,就是一种描述字符串结构模式的形式化表达方法。最初,这套方法用于描述正则文本的,后期发展它的功能变得非常强大。python自从1.5版本起就加入了正则模块re。一方面,正则描述的是一个对象序列,即当今计算机世界的本质数据结构,另一方面,正则有着极强的结构描述能力。基于这两点,我们需要好好学习一下正则表达式。
这次我们使用另外一个模块——requests,来验证。首先pip install requests,安装上这个package。requests的使用看起来比urllib要简单一些:
- #首先我们导入这个包
- import requsets
- url="http://www.17jita.com/tab/img/8088.html"
- #GET方法
- response=requests.get(url)
- #POST方法
- response=requests.post(url)
- #其他
- response=requests.put(url)
- response=requests.delete(url)
- response=requests.head(url)
- response=requests.options(url)
- #获取内容
- html=response.text
- print(html)
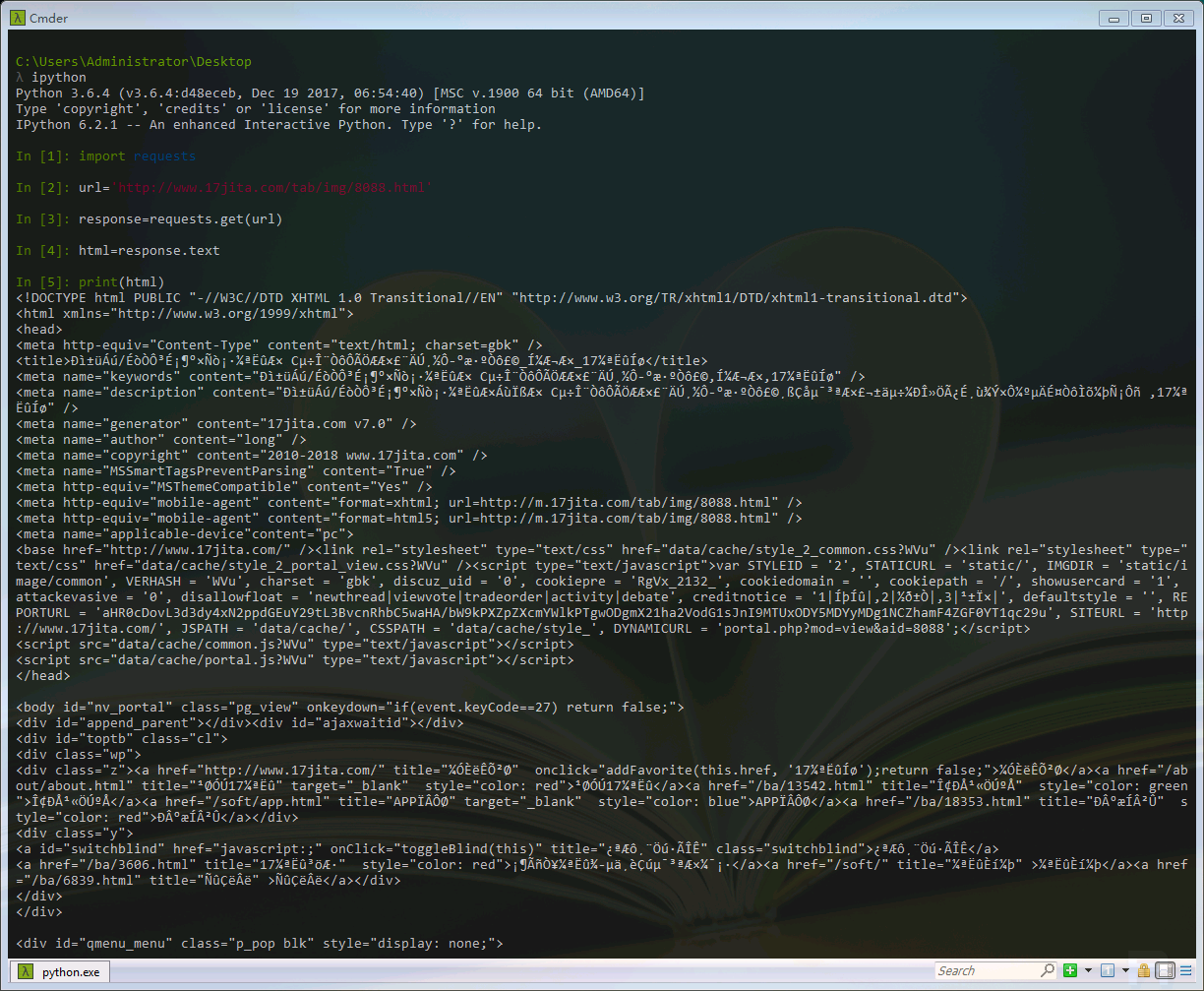
关于requests模块,我们可以在以后使用过程中继续学习。下面我们来看基于正则表达式的re模块,然后可以用re来匹配网页上的内容了。
一、正则表达式的规则
正则表达式有以下几个元字符,他们各自都有着特殊的含义: . ^ $ * + { } [ ] \ | ( ) 。 例如点号(.)表示匹配除换行符以外的任何字符,管道符(|)则有点类似于逻辑或操作。我们可以在 http://tool.oschina.net/uploads/apidocs/jquery/regexp.html 这个网站上查看正则的手册。help(re),我们可以看到这些方法:match,fullmatch,search,split,findall......等。
下面我们来举几个例子。例如我们要对以下这些数据进行匹配“ 1305101765@qq.com advantage 314159265358 1892673 3.14 little Girl try_your_best 56 123456789@163.com python3”
1、匹配advantage,我们用search方法来实现,如果匹配成功它会返回位置。
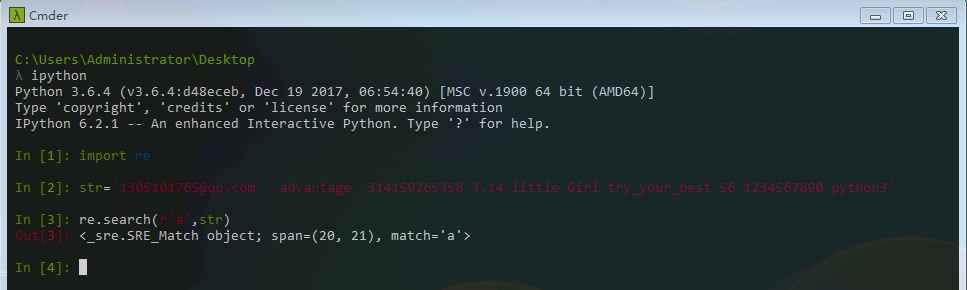
可以看到,我们只找到了advantage第一个字母a的位置span=(21,22)。如果要想匹配整个单词呢?
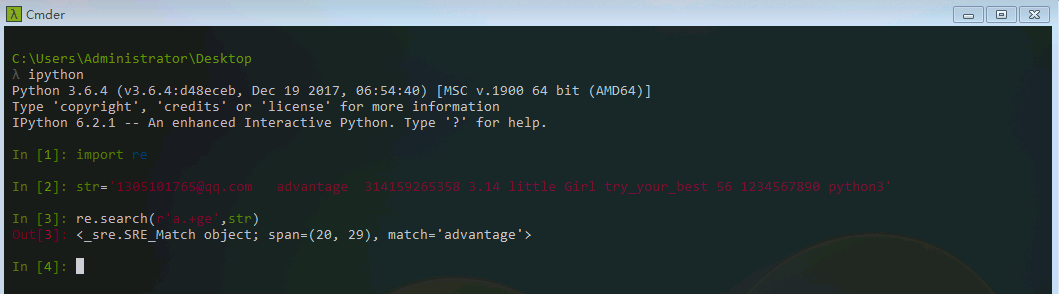
可以看到我们match到了advantage。其中 (.) 表示匹配除了换行符体外的任何字符, (+) 表示匹配前面的子表达式一次或者多次。
2、匹配邮箱地址
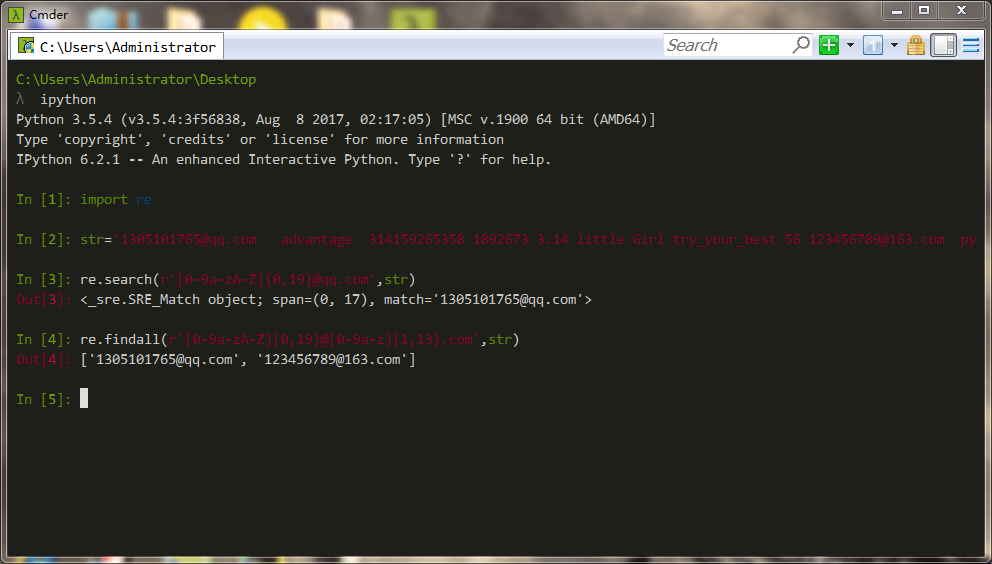
其中中括号里面的0-9表示0123456789,a-z表示26个字母,{}表示匹配里面的内容一次或多次。这次我们用findall(),他能找出所有满足正则规则的字符串,并返回这些字符串。当然,上面的规则可以继续完善,以至于可以匹配任何的邮箱。
在下一篇我们将解决匹配ip地址的问题,并且从网站上爬取可用ip。
python爬虫(4)——正则表达式(一)的更多相关文章
- 玩转python爬虫之正则表达式
玩转python爬虫之正则表达式 这篇文章主要介绍了python爬虫的正则表达式,正则表达式在Python爬虫是必不可少的神兵利器,本文整理了Python中的正则表达式的相关内容,感兴趣的小伙伴们可以 ...
- 【Python爬虫】正则表达式与re模块
正则表达式与re模块 阅读目录 在线正则表达式测试 常见匹配模式 re.match re.search re.findall re.compile 实战练习 在线正则表达式测试 http://tool ...
- python 爬虫之-- 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 正则表达式非python独有,python 提供了正则表达式的接口,re模块 一.正则匹配字符简介 模式 描述 \d ...
- python爬虫训练——正则表达式+BeautifulSoup爬图片
这次练习爬 传送门 这贴吧里的美食图片. 如果通过img标签和class属性的话,用BeautifulSoup能很简单的解决,但是这次用一下正则表达式,我这也是参考了该博主的博文:传送门 所有图片的s ...
- 【python爬虫和正则表达式】爬取表格中的的二级链接
开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的.前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个 ...
- Python爬虫运用正则表达式
我看到最近几部电影很火,查了一下猫眼电影上的数据,发现还有个榜单,里面有各种经典和热映电影的排行榜,然后我觉得电影封面图还挺好看的,想着一张一张下载真是费时费力,于是突发奇想,好像可以用一下最近学的东 ...
- Python爬虫之正则表达式(3)
# re.sub # 替换字符串中每一个匹配的子串后返回替换后的字符串 import re content = 'Extra strings Hello 1234567 World_This is a ...
- Python爬虫之正则表达式(1)
廖雪峰正则表达式学习笔记 1:用\d可以匹配一个数字:用\w可以匹配一个字母或数字: '00\d' 可以匹配‘007’,但是无法匹配‘00A’; ‘\d\d\d’可以匹配‘010’: ‘\w\w\d’ ...
- python爬虫之正则表达式
一.简介 正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达式.常规表示法(英语:Regular Expression,在代码中常简写为regex.regexp或RE),计算机科学的一个概念 ...
- Python爬虫基础——正则表达式
说到爬虫,不可避免的会牵涉到正则表达式. 因为你需要清晰地知道你需要爬取什么信息?它们有什么共同点?可以怎么去表示它们? 而这些,都需要我们熟悉正则表达,才能更好地去提取. 先简单复习一下各表达式所代 ...
随机推荐
- thinkphp3.2.2邮箱发送
浏览:7510 最后更新:2017-03-18 14:21 分类:类库 关键字: PHPMailer 第一步:准备PHPMailer 将下载的PHPMailer放到ThinkPHP/library/V ...
- eclipse 按住ctrl 按钮没有反映
以下是修改为XML Editior打开方法Window -> Preferences -> General -> Editors -> File Associations Fi ...
- “Project 'MyFunProject' is not a J2SE 5.0 compliant project.”
- CCF系列之模板生成系统( 201509-3 )
试题名称: 模板生成系统 试题编号: 201509-3 时间限制: 1.0s 内存限制: 256.0MB 问题描述 成成最近在搭建一个网站,其中一些页面的部分内容来自数据库中不同的数据记录,但是页面的 ...
- Java数据持久层框架 MyBatis之API学习四(xml配置文件详解)
摘录网址: http://blog.csdn.net/u010107350/article/details/51292500 对于MyBatis的学习而言,最好去MyBatis的官方文档:http:/ ...
- Schema与数据类型优化
良好的逻辑设计和物理设计是高性能的基石,应该根据系统将要执行的查询数据来设计schema,这往往需要权衡各种因素. MySQL支持的数据类型非常多,选择正确的数据类型对于获得高性能至关重要. 更小的通 ...
- scrapy_开发环境
scrapy开发所具备的环境 IDE pycharm 数据库 mysql, redis 开发环境 python 3.5
- 爬取知名社区技术文章_setting_5
# -*- coding: utf-8 -*- # Scrapy settings for JobBole project # # For simplicity, this file contains ...
- junit3对比junit4
本文内容摘自junit实战,感谢作者的无私奉献. 个人觉得每个开源包的版本对比意义不大,闲来无事,这里就来整理一下好了.本文名为junit3对比junit4,但是我通过这篇博客主要也是想统一的来整理下 ...
- 流API--初体验
在JDK8新增的许多功能中,有2个功能最重要,一个是Lambda表达式,一个是流API.Lambda表达式前面我已经整理过了,现在开始整理流API.首先应该如何定义流API中的"流" ...