深入浅出Hadoop之mapreduce
卿哥原创,转载请注明出处,谢谢
之前已经作出预告,那么今天就聊聊mapreduce,起源于Google的map reduce paper, 而后经历了mapreduce 1,和构建于yarn上的mapreduce 2,mapreduce1 除了提供一定的历史演变价值和了解一下mapreduce最初的设计之外就没有必要学了哈,毕竟现在意义上的mapreduce2,spark都是在yarn上。当然mapreduce这项技术本身可能现在也是逐年衰落,不是我说的,是michael stonebraker3年前就说了(stonebraker认为程序员只需要了解sql就行了,nosql啥的都应该直接或间接支持用sql来查询交互),而且google自己也早就不用了,不过mapreduce还是有自身一定的学习价值,比如map, combiner, shuffle/sort, practiioner, reducer,消息传递, data locality(即把运算移动到数据旁,而不是传输数据来节省网络带宽提高运算效率)都是分布式系统运算框架的一个里程碑。很多分布式系统设计课程比如MIT研究生著名的分布式系统设计的前几章必然要讲mapreduce。
分布式系统前言
分布式系统由于包括很多node,所以它的根基是unreliable component包括node,network和clock,上层的设计必然需要考虑到这一点。Unreliable node有如下三种表现形式:
- fail-stop, 比如电力供应中断了(比如data center停电了,或者地震了发水灾了啥的),fail了就完了,无法恢复。
- fail-recovery,比如node升级kernel,os,software,需要重启
- 拜占庭 failure,这个比较狠,就是这个node看似正常,但是你说城门楼子它说胯骨轴子,你说往东,它往西走。相当于一个神经错乱的node或者说是被入侵了的node。
同时分布式系统涉及大量的网络传输,不管是RPC还是RESTFUL都是走网络,网络也是unreliable的,有如下三种表现形式:
- 完美传输,即%0 loss, 100% in order,俗称happy home,这个资源成本比较高,适用于特别重要的服务
- fair-loss, 这个最为常见,就是正常丢包,不已传输内容为转移。TCP/IP就是为了解决这个事儿而设计了3 way handshake,retry,sliding window,congestion control啥的
- 拜占庭 failure,这个就基本相当于被man in the middle 了,anything is possible,good luck :)思考题:SSL/TLS 能有效解决man in the middle吗?
还没完,分布式系统还有一个问题就是clock,一方面每台机器的时间都可能不一样,俗称clock skew,另一方面,每台机器对每一秒的感知也不一样,俗称clock drift。所以伟大的lamport(2013图灵奖得主,分布式大神,latex,vector clock,paxos,etc)发明了logical clock,其中最著名的是vector clock。相当于让每个event有了自己的先后顺序。这个可以单独聊一次它的具体原理。插一句嘴,我觉得分布式系统这么多年敢称大神的只有两个,理论大师lamport和实战天王Jeff Dean(Jeff Dean当年在MIT淡定的给我们介绍谷歌分布式系统设计经验,然后说自己一个周末现学maching learning,搞出了个猫图片识别,当时我就在想他学machine learning干啥,然后tensor flow这个项目就横空出世了。。。orz)
还有就是分布式系统实现分为synchronous和asynchronous两种model,synchronous就是blocking callback with optional timeout,asynchronous就是event call back with optional timeout。
下面我们把以上几种情形组合一下:
- fail-stop + 完美传输 + synchronous,比如超级计算机每个processor由local high speed bus相连,user case是OpenMP 和 MPI
- fail-recovery + fair-loss + asynchronous,就是我们最近一直聊的hadoop eco system了
- 拜占庭 node + 拜占庭网络+asynchronous,这就是分布于untrusted computer和untrusted network之中的grid computing了
map
先看一下python的map function,接下来会聊hadoop streaming
>>> map(lambda x: x*x, [1,2,3,4,5])
[1, 4, 9, 16, 25] or>>> items = (1,2,3,4,5) >>> def sqr(x): return x**2>>> map(sqr,items) [1, 4, 9, 16, 25]
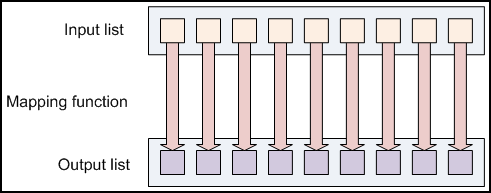
reduce
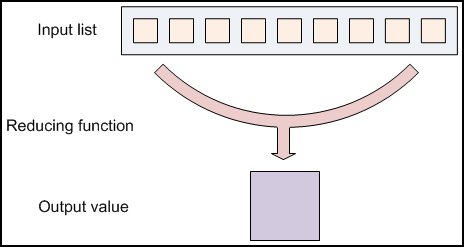
先看一下python的reduce function
>>> reduce(operator.iadd, [1,4,9,16,25])
55 or >>> reduce(lambda x,y: x+y, [1,4,9,16,25])
55
data flow
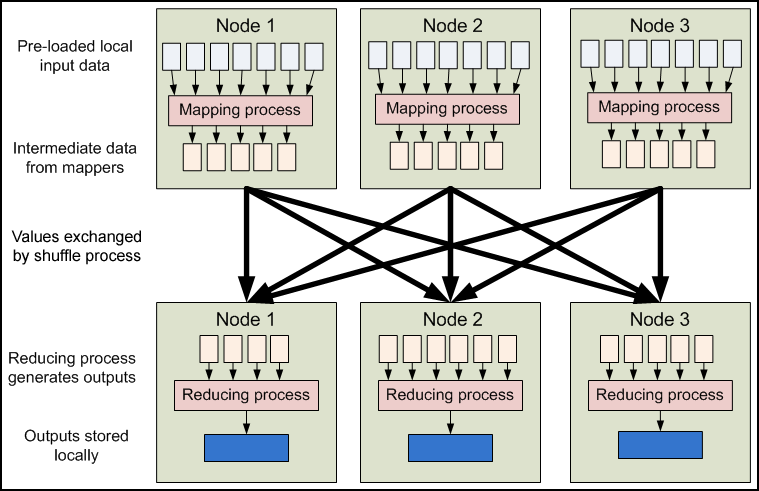
map 和 reduce的input/output都是key/value pair。注意map或者reduce不一定都需要,比如grep,map=grep,reduce=None
在sort和shuffling阶段,sorting用的是external sorting,所以不用担心内存爆了。
实现
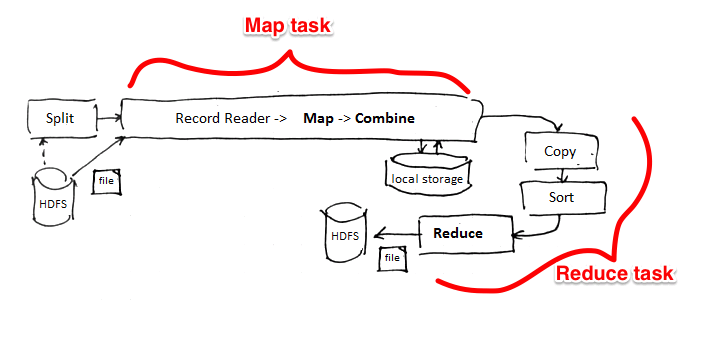
上图中,intermidiate result是存放在local disk中而不是HDFS,因为就算丢了,也可以通过map重新得到,所以不用使用HDFS做multiple copy。
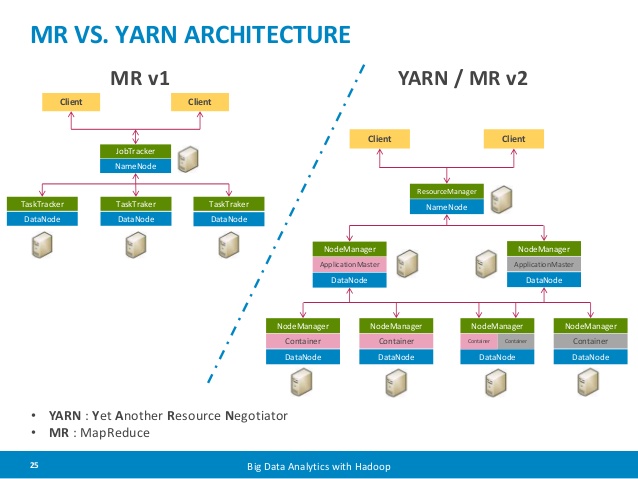
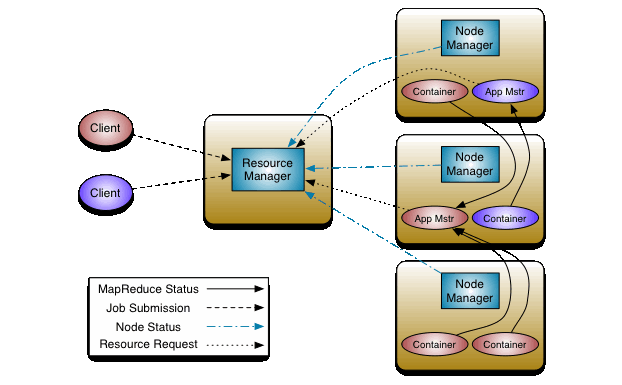

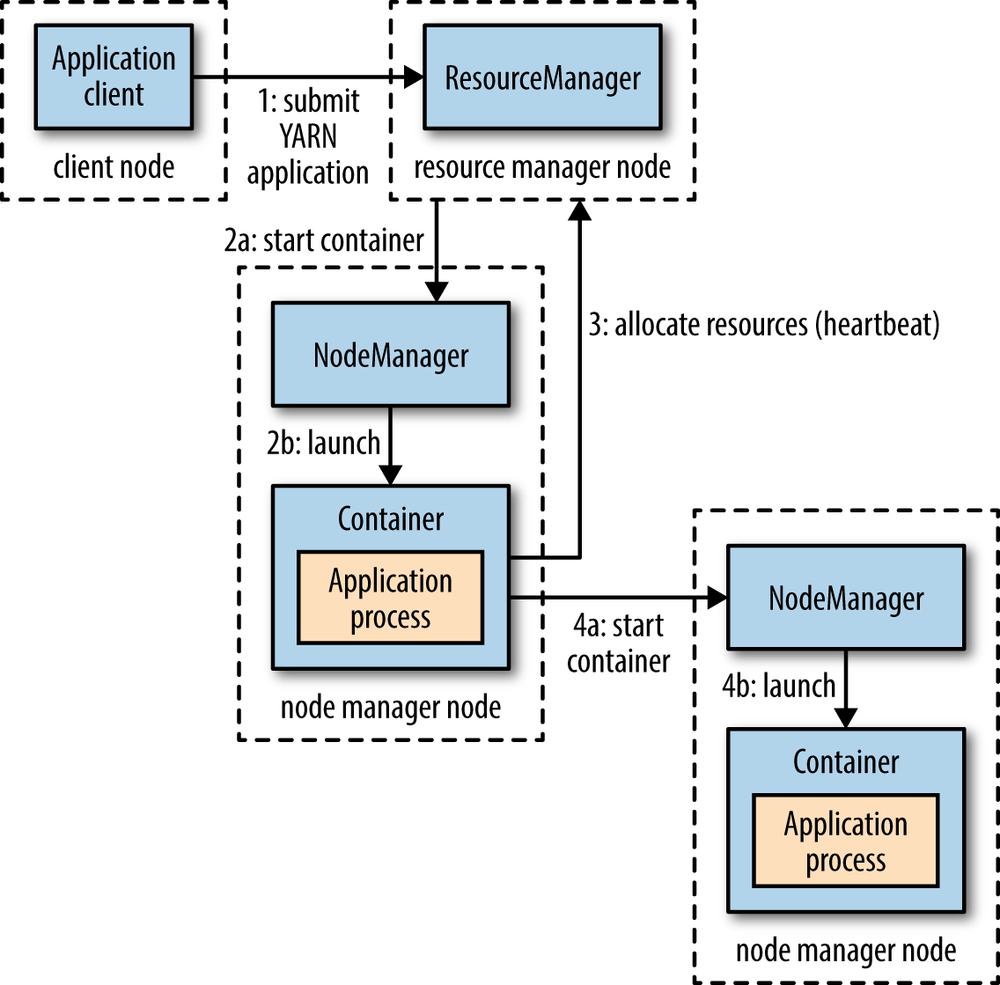
上图可以看出yarn分为resource manager和node manager,resource manager会launch application master,application master会请求resource根据resource富余程度launch application process。
下面这张图也是这个意思:
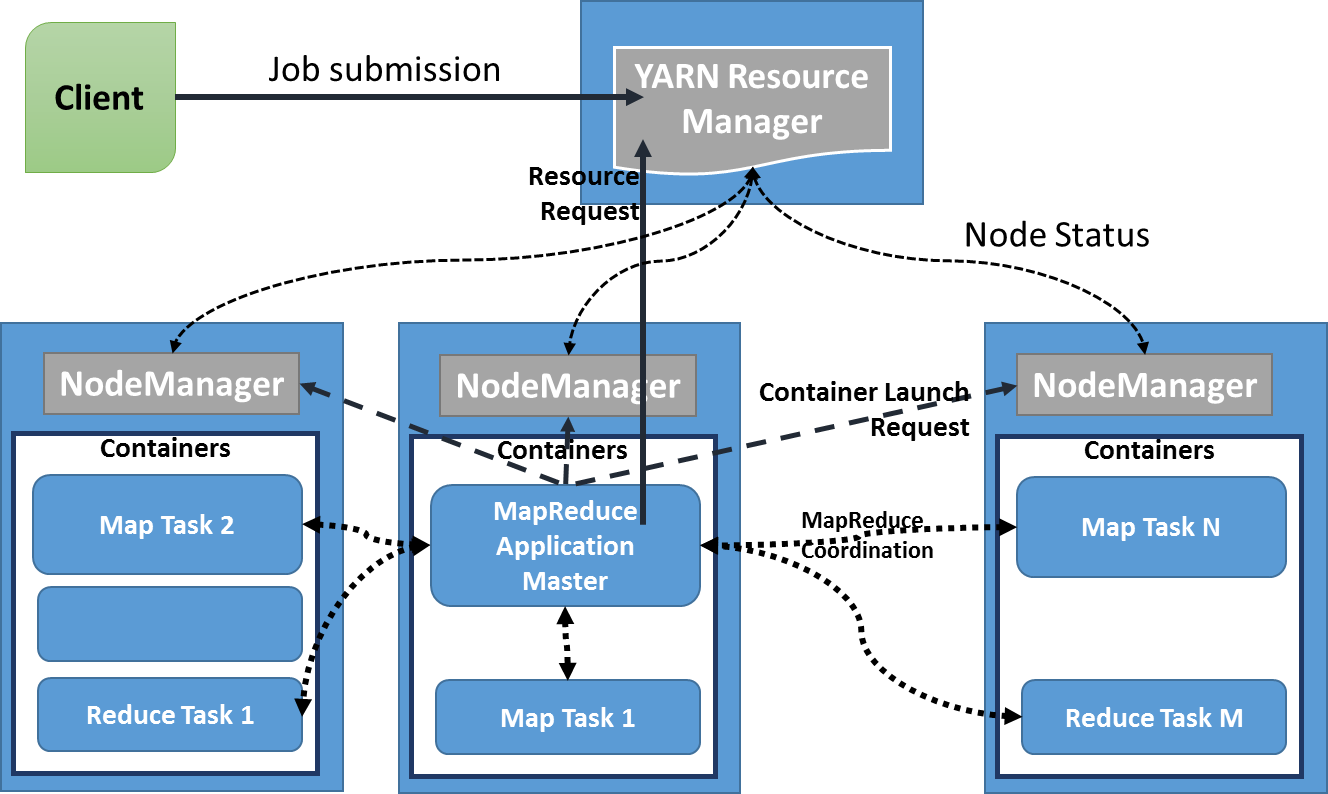
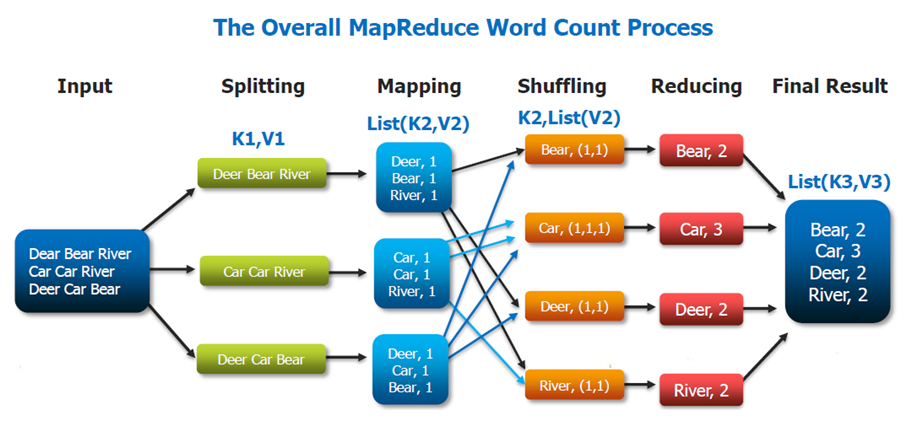
具体来说,input data会被Hadoop切割为固定大小的input splits,Hadoop 会为每个split creates一个map task,map task会对split中的每一个record运行user-defined map function. 对于大部分job来说,a good split size是一个HDFS block,128MB。Hadoop尽量通过data locality optimization来让map task运行在存有input data的节点上。如果不行,就选择同一个rack上的其它node,如果还不行,就选择旁边rack上的node。
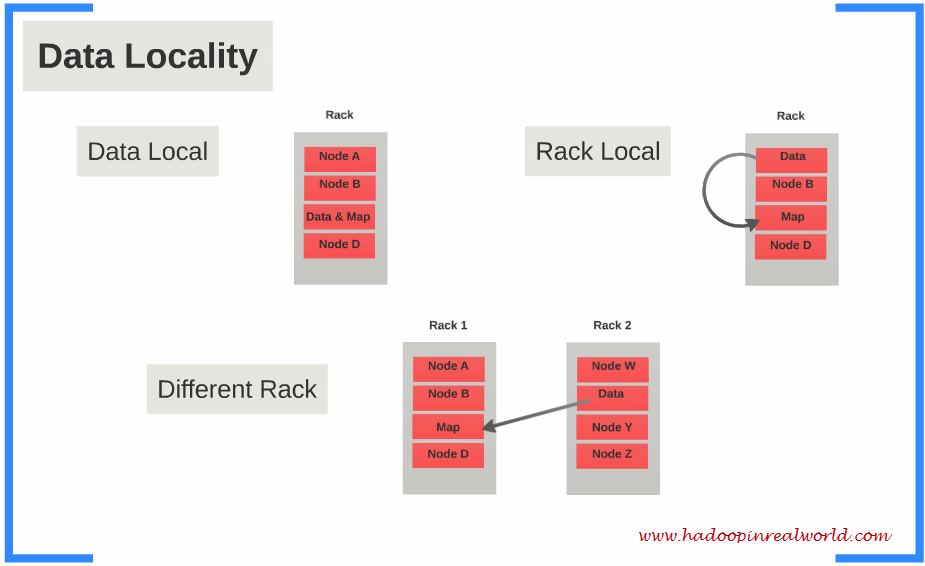
reduce就没有data locality一说了,input都是通过网络传过去的。这中间还会有一个shuffle&&sort的过程,通常就是通过一个hash function来把相同的key放在一起,保证对于每一个given key来说,所有的records都在一个partition里。所以当reducer处理的时候可以保证input data都是按照key sorting好的了。
Hadoop Streaming
首先,说说distributed cache, 比如你有个文件需要在运算的时候用到如何传给map/reduce task呢?答,是通过-files/-archives/-libjars 传过去的,比如-files mapper.py, reducer.py, some_file.txt, 此时some_file.txt会被传到需要的node上,每个node只需要一个copy,注意some_files.txt是read only的,所以可以被tasks共享。 archives是打包传输,libjars是传jar格式。
following method 可以创建archive文件:
tar -cf pack.tar a.txt b.txt c.txt
读的时候就用如下path:
pack.tar/a.txt,pack.tar/b.txt, pack.tar/c.txt
其次,说说environment variable, hadoop streaming可以通过-D some_var="some value"的方式把变量传给nodes。
第三,从task的角度可以通过reporter:status: 的方式把report传回去。
下面举个word count的实际例子,比如统计wikipedia的word count:
mapper.py
#!/usr/bin/python import sys
import re reload(sys)
sys.setdefaultencoding('utf-8') # required to convert to unicode for line in sys.stdin:
try:
article_id, text = unicode(line.strip()).split('\t', 1)
except ValueError as e:
continue
words = re.split("\W*\s+\W*", text, flags=re.UNICODE)
for word in words:
print "%s\t%d" % (word.lower(), 1)
reducer.py
#!/usr/bin/python import sys current_key = None
word_sum = 0 for line in sys.stdin:
try:
key, count = line.strip().split('\t', 1)
count = int(count)
except ValueError as e:
continue
if current_key != key:
if current_key:
print "%s\t%d" % (current_key, word_sum)
word_sum = 0
current_key = key
word_sum += count if current_key:
print "%s\t%d" % (current_key, word_sum)
本机运行:
cat wiki.txt | ./mapper.py | sort | ./reducer.py
Hadoop streaming:
OUT_DIR="wiki_wordcount_result_"$(date +"%s%6N")
NUM_REDUCERS= hdfs dfs -rm -r -skipTrash ${OUT_DIR} > /dev/null yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-streaming.jar \
-D mapred.jab.name="Streaming wordCount" \
-D mapreduce.job.reduces=${NUM_REDUCERS} \
-files mapper.py,reducer.py \
-mapper "python mapper.py" \
-combiner "python reducer.py" \
-reducer "python reducer.py" \
-input /wiki/en_articles_part \
-output ${OUT_DIR} > /dev/null
好了,今天就写到这,happy mapreduce!
深入浅出Hadoop之mapreduce的更多相关文章
- 升级版:深入浅出Hadoop实战开发(云存储、MapReduce、HBase实战微博、Hive应用、Storm应用)
Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储.Hadoop实现了一个分布式文件系 ...
- 从Hadoop骨架MapReduce在海量数据处理模式(包括淘宝技术架构)
从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显兴奋,认为它们非常是神奇.而神奇的东西常能勾 ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- 用PHP编写Hadoop的MapReduce程序
用PHP编写Hadoop的MapReduce程序 Hadoop流 虽然Hadoop是用Java写的,但是Hadoop提供了Hadoop流,Hadoop流提供一个API, 允许用户使用任何语言编 ...
- Hadoop之MapReduce程序应用三
摘要:MapReduce程序进行数据去重. 关键词:MapReduce 数据去重 数据源:人工构造日志数据集log-file1.txt和log-file2.txt. log-file1.txt内容 ...
- 对于Hadoop的MapReduce编程makefile
根据近期需要hadoop的MapReduce程序集成到一个大的应用C/C++书面框架.在需求make当自己主动MapReduce编译和打包的应用. 在这里,一个简单的WordCount1一个例子详细的 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础-MapReduce的Join操作
Hadoop基础-MapReduce的Join操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.连接操作Map端Join(适合处理小表+大表的情况) no001 no002 ...
随机推荐
- 解决sql和beans中名字不一致问题
第二图使用别名 tid为sql中的名字,id为beans中的名字,推荐此方式
- js实现深拷贝和浅拷贝
浅拷贝: 思路----------把父对象的属性,全部拷贝给子对象,实现继承. 问题---------如果父对象的属性等于数组或另一个对象,那么实际上,子对象获得的只是一个内存地址,不会开辟新栈,不是 ...
- 基于TypeScript装饰器定义Express RESTful 服务
前言 本文主要讲解如何使用TypeScript装饰器定义Express路由.文中出现的代码经过简化不能直接运行,完整代码的请戳:https://github.com/WinfredWang/expre ...
- 访问网时出现403 Forbidden错误的原因:
1.你的IP被列入黑名单.2.你在一定时间内过多地访问此网站(一般是用采集程序),被防火墙拒绝访问了.3.网站域名解析到了空间,但空间未绑定此域名.4.你的网页脚本文件在当前目录下没有执行权限.5.在 ...
- 怎么看vue版本
查看vue版本号是 vue -V 而不是npm vue -v ,npm vue -v 等同于npm -v vue -V: 后面那个V是大写的.
- java垃圾回收的分类
1.线程数 分为串行垃圾回收器和并行垃圾回收器.串行垃圾回收器一次只使用一个线程进行垃圾回收:并行垃圾回收器一次将开启多个线程同时进行垃圾回收.在并行能力较强的 CPU 上,使用并行垃圾回收器可以缩短 ...
- 一句话 Servlet
Servlet是用来完成B/S架构下,客户端请求的响应处理. web.xml其实就是servlet的一个配置文件,通过他来寻找对应的servlet
- Thrift compiler代码生成类解析
代码生成类解析: Thrift--facebook RPC框架,介绍就不说了,百度,google一大把,使用也不介绍,直接上结构和分析吧. Hello.thrift文件内容如下: namespace ...
- C#读取固定文本格式的txt文件
C#读取固定文本格式的txt文件 一个简单的C#读取txt文档的程序,文档中用固定的格式存放着实例数据. //判断关键字在文档中是否存在 ] == "设备ID:107157061" ...
- Hyperledger Fabric Transaction Flow——事务处理流程
Transaction Flow 本文概述了在标准资产交换过程中发生的事务机制.这个场景包括两个客户,A和B,他们在购买和销售萝卜(产品).他们每个人在网络上都有一个peer,通过这个网络,他们发送自 ...