从前端开发看HTTP协议的应用
一、Chrome Developer Network Tab
Cheome Developer作为现在前端开发者最常用的开发调试工具,其具有前端可以涉及到的各方面的强大功能,为我们的开发和定位问题提供了极大地便利。其中Network Tab是相当常用的一个功能板块。通过它的XHR、JS、CSS、Img等子Tab我们可以捕获到所有基于应用层的HTTP/HTTPS协议的网络请求,可以查看到该次请求和响应的所有头信息和内容。
Network Tab

展示了针对每一个HTTP请求的所有属性,包括:
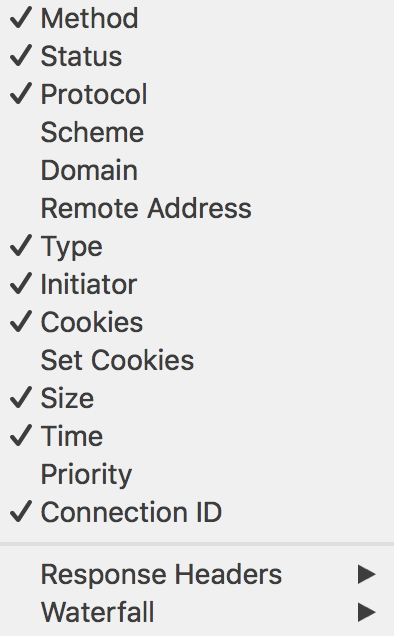
其中Connection ID为传输层TCP协议的连接ID。关于这点会在下一个章节提到。
Headers主要展示了此次请求的状态,还有请求和响应的头部信息,头部信息是HTTP交互双方进行作业的依据:

Headers中的大多数Key对于有经验开发者来说并不陌生,不需要在这里介绍了。但还是需要提到两个key:
content-type作为描述交互内容数据MIME格式的key意义相当重大,我们在实际开发中发出请求缺接收到不到任何东西,如果请求其他部分没问题的话,很可能就是因为前后端的content-type不匹配的原因导致的。
referer作为描述请求发起者所属域的key,也是非常有用的。
1.通过它我们可以对网站进行访问量统计;
2.可以对任何资源的访问做域的限制(防盗链),比如说:我引用一个QQ空间的图片URL放到我自己HTTP服务器serve的网页的<img />上,当我访问该页面的时候并没有拿到这个图片,取而代之的是一个访问受限制的站位图片。也就是说QQ空间的服务器在接收到资源请求的时候,是对referer做了检测的,如果非QQ空间的页面发起的请求是无法正常获取到目标图片的。referer本身是个错误的单词,正确写法应该为referrer,译为介绍人,描述了是在哪个域下进行请求资源或者跳转到某个URL的操作。后来为了向下兼容HTTP协议,这个错误的单词一直没有被修改。
需要注意的是:当我们直接从浏览器地址栏访问某资源时,此时referer为空,因为此时并不存在有真正的介绍人,这是一个凭空产生的请求,并不是从其他任何地方链过去的。
Response展示了服务端响应的内容,Preview是根据Headers中的双方的Content-Type的MIME类型加工后的方便开发者浏览的带格式的数据内容:

Cookie展示了在此次请求中浏览器Headers中所带Cookie,以及HTTP服务器端对浏览器端Cookie的设置:

Timing 整个请求从准备发出到结束的生命周期时序:

对于有经验的开发者来,从Headers、Preview与Response、Cookie中能获取到相当有用的信息。对于Timing Tab,它更接近底层,展示了浏览器端发起一个HTTP请求的全过程,按照Chrome官方解释,Timing中各阶段描述如下:
1. Queuing(排队中)
如果一个请求排队,则表明:
1)请求被渲染引擎推迟,因为它被认为比关键资源(如脚本/样式)的优先级低。这经常发生在 images(图像) 上。
2)这个请求被搁置,在等待一个即将被释放的不可用的TCP socket。
3)这个请求被搁置,因为浏览器限制。在HTTP 1协议中,每个源上只能有6个TCP连接,这个问题将在下一面的章节中提到。
4)正在生成磁盘缓存条目(通常非常快)。
2.Stalled/Blocking (停止/阻塞)
发送请求之前等待的时间。它可能因为进入队列的任何原因而被阻塞。这个时间包括代理协商的时间。
3.Proxy Negotiation (代理协商)
与代理服务器连接协商花费的时间
4.DNS Lookup (DNS查找)
执行DNS查找所用的时间。 页面上的每个新域都需要完整的往返(roundtrip)才能进行DNS查找。当本地DNS缓存没有的时候,这个时间可能是有一段长度的,但是比如你一旦在host中设置了DNS,或者第二次访问,由于浏览器的DNS缓存还在,这个时间就为0了。
5.Initial Connection / Connecting (初始连接/连接)
建立连接所需的时间, 包括TCP握手/重试和协商SSL。
6.SSL
完成SSL握手所用的时间,如果是HTTPS的话
7.Request Sent / Sending (请求已发送/正在发送)
发出网络请求所花费的时间。 通常是几分之一毫秒。
8.Waiting (TTFB) (等待)
等待初始响应所花费的时间,也称为`Time To First Byte`(接收到第一个字节所花费的时间)。这个时间除了等待服务器传递响应所花费的时间之外,还捕获到服务器发送数据的延迟时间。这些情况可能会导致高TTFB:1.客户端和服务器之间的网络条件差;2.服务器端程序响应很慢。
9.Content Download / Downloading (内容下载/下载)
接收响应数据所花费的时间。从接收到第一个字节开始,到下载完最后一个字节结束。
通过对请求发出和响应的每个阶段的理解,我们就能分析出当前HTTP请求存在的问题,并据此解决问题。
二、客户端与服务端通过HTTP协议的交互过程
在HTTP协议RFC2616的描述中,HTTP作为应用层协议,推荐并默认使用TCP/IP作为传输层协议,且其他任何可靠的传输层协议也都可以被HTTP协议采用和使用。也就是说假如UDP是"可靠"的,HTTP也可以走在UDP上面。目前市面上流行的浏览器的HTTP请求普遍遵守这个原则并采用TCP/IP作为传输层协议。
下面是捕获的一个对通过XMLHttpRequest对https://localhost:3000/api/syncsystemstatus发起的HTTPS GET请求:

在上个章节中有提到Connection ID是TCP连接的ID, 表明了此次资源的请求是通过哪一个TCP连接完成的。
通常情况下我们使用Fiddler、Charles或者Chome Developer工具只能对HTTP/HTTPS请求抓包,这里我们使用WireShark对更底层的协议连接进行封包抓取,并分析上面所提到的这个连接从建立到结束的整个过程。WireShark抓包截图如下:

说明:由于笔者使用Webpack的dev-server给localhost:3000做了正向代理,并开启了HTTPS,由于服务器并未开启HTTPS,所以dev-server到服务器并不是HTTPS而是HTTP1.1,192.168.11.94就是dev-server的IP,可以将其看作localhost:3000,也就是客户端浏览器。192.168.100.101为dev-server正向代理到的目的地,也是请求要发送到的HTTP服务器。简单来讲该例子就是从浏览器(192.168.11.14)通过XMLHttpRequest对象发起了一个到服务器(192.168.100.101)的HTTP1.1请求。
客户端和服务器交互过程如下:
No.x号为WireShark封包列表中最左侧的列,记录每个封包在该次抓取中的编号,并依次递增。
No.1:浏览器(192.168.11.94)向服务器(192.168.100.101)发出连接请求,并发送SYN包,进入SYN_SEND状态,等待服务器确认。这是TCP三次握手的第一次。

No.2:服务器(192.168.100.101)响应了浏览器(192.168.11.94)的请求,确认浏览器的SYN(ACK=J+1),并且自己也发送SYN包也就是SYN+ACK包,要求浏览器进行确认,此时了服务器进入SYN_RECV状态。这是TCP三次握手的第二次。
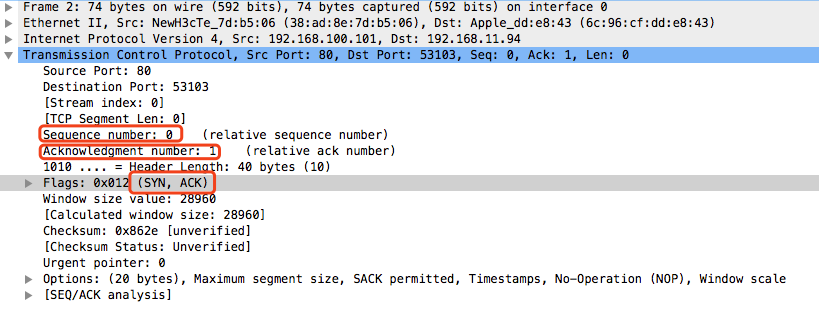
No.3:浏览器(192.168.11.94)响应了服务器(192.168.100.101)的SYN+ACK包,向服务器发送确认包ACK(ACK=K+1),此包发送完毕,浏览器和服务器进入ESTABLISHED状态,这是TCP三次握手的第三次,握手完成,TCP连接成功建立。
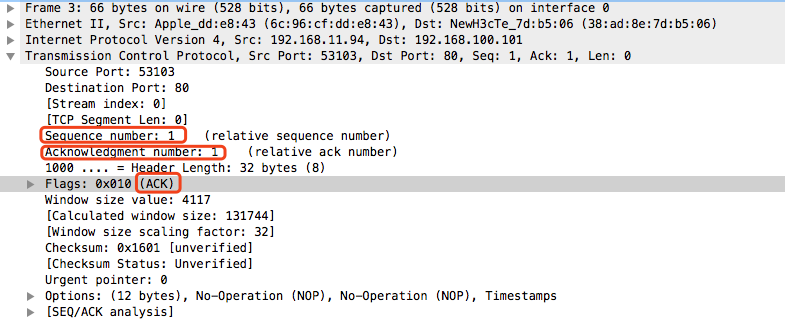
No.4:浏览器(192.168.11.94)发出一个HTTP请求到服务器(192.168.100.101)。
No.5:服务器(192.168.100.101)收到浏览器(192.168.11.94)发出的请求,并确认,然后开始发送数据。
No.6:服务器(192.168.100.101)发送状态响应码200到浏览器(192.168.11.94),表示数据传输成功并且完毕,content-type表明响应的内容文本需要被解析为JSON格式, OK结束。此时我们开发者通过判断XHR的readyState为4以及status为200就可以得到服务器完整的返回数据并应用在前端逻辑或页面展示上了。
对应第一章节中提到的Chrome Developer Network的请求时序图:
1.发起第一个请求并完成连接的建立:No.1至No.4 对应时序图中的第5步至第7步。XHR的readyState为0-2,初始化请求、发送请求并建立连接,
2.基于TCP连接的建立,通过HTTP协议进行数据传输:No.5对应时序图中的第8步至第9步,XHR的readyState为3,正在交互中,开始数据。数据传输完毕后,readyState为4,status为200。
对于Fetch对象发起的请求也是如此的,只不过Fetch基于Promise封装,readyState和status可以理解为是内部控制的,来决定resolve和reject的情况。笔者的项目其实是使用Fetch的,只是这里用XMLHttpRequest对象也就是Ajax来说明,容易理解一些。
针对No.1至No.3的TCP的三次握手示意图:

SYN:Synchronize Sequence Numbers 同步序列编号。
SYN_SEND:请求连接,当你要访问其它的计算机的服务时首先要发个同步信号给该端口,此时状态为SYN_SENT,如果连接成功了就变为ESTABLISHED。
ACK:Acknowledgement 确认字符。在数据通信中,接收站发给发送站的一种传输类控制字符。表示发来的数据已确认接收无误。在TCP/IP协议中,如果接收方成功的接收到数据,那么会回复一个ACK数据。通常ACK信号有自己固定的格式,长度大小,由接收方回复给发送方。
No.4才是是HTTP的包,这表明HTTP连接是基于TCP连接建立的。
三、因前序请求阻塞而导致后续请求没法发起的问题
笔者目前开发的这个项目,从底层Go的接口返回数据给Node.js层,Node.js层再返回给前端界面。在底层接口没优化的时候,一个请求完成最少都要耗时500ms,平均都在800ms左右,更有甚者达到了1s多。前端是基于React.j的SPA应用,,每个界面为了数据的准确性,在进入界面后会立即请求数据,并且后台还维持了一个每15s更新数据的CronJob。如果暴力的切换路由改变界面可以在短时间内创建大量的HTTP请求。在HTTP1.1下的性能表现极为糟糕,阻塞情况严重。HTTP1.1默认只能同时创建6条TCP连接,每条连接结束以后才能释放出来给对另外一个资源的请求来使用。虽然和HTTP1.0相比,在性能上已有较大提升,但是并没有本质的改变。以本项目为例,如果当瞬间发起满10个请求后,只有前6个请求能够分配6个不同的TCP连接进行处理,后续4个请求只有等待这6个请求有任何一个释放TCP连接资源以后,才能继续。也就是说前6个请求中如果最少耗时都在1s,那么后4个请求的最少Pending时间都在1s。在笔者这位暴躁老哥的操作下,这简直是噩梦:

可以发现阻塞现象相当严重,而且每个HTTP请求会创建一个独立的TCP连接进行处理,请求完成以后再关闭,再为下一次请求创建一个新的TCP连接,资源开销极大。
以getsnapshot这个接口为例,在不阻塞的情况下,其大致需要84ms来完成请求:

然而在发生阻塞后:

额...好恐怖。 
改用HTTPS后,浏览器默认启用HTTP2.0协议:

在笔者的暴力操作下,浏览器在短时间内发起大量的请求。可以看到ID为2693483的这个TCP连接并发处理了的所有的资源请求,并且一直保持open状态。可见在HTTP2.0下相对于HTTP1.X,并发处理请求的数量和吞吐量都被提升到了一个完全不同的量级上。极大节省了创建TCP连接的开销,并且提升了对网络带宽资源的利用率。有HTTP2.0多路复用功能的支持,浏览器对大量的并发请求的处理顺畅多了。
好了到此结束吧。
HTTP1.0、HTTP1.1、HTTP2.0之间还有很多的区别,每个版本之间的变化也很大,包括header压缩,keep-alive优化,二进制格式支持等。有兴趣的读者可以在网上搜索相关资料进行深入学习,本业也只是对在实际项目中遇到的一些案例进行介绍,而不是对HTTP协议本身的讲解。
从前端开发看HTTP协议的应用的更多相关文章
- python 之 前端开发(HTTP协议、head标签、img标签、a标签、列表标签)
第十一章前端开发 11.1 HTTP 1.1引入了许多关键性能优化:keepalive连接,请求流水线,chunked编码传输,字节范围请求等 1.keepalive连接: 1.长连接允许HTTP设备 ...
- 2019最新WEB前端开发小白必看的学习路线(附学习视频教程)
2019最新WEB前端开发小白必看的学习路线(附学习视频教程).web前端自学之路:史上最全web学习路线,HTML5是万维网的核心语言,标准通用标记语言下的一个应用超文本标记语言(HTML)的第五次 ...
- 绝对精品推荐做前端的看下:Web前端开发体会十日谈
20151208感悟: 前端人的角度来看的话,感觉像是阅读一个大牛前端的全部武功的一个秘籍说明,里面的思想高价值蛋白真是太多太多,推荐看. Web前端开发体会十日谈 一直想写这篇“十日谈”,聊聊我对W ...
- 基于gulp编写的一个简单实用的前端开发环境好了,安装完Gulp后,接下来是你大展身手的时候了,在你自己的电脑上面随便哪个地方建一个目录,打开命令行,然后进入创建好的目录里面,开始撸代码,关于生成的json文件请点击这里https://docs.npmjs.com/files/package.json,打开的速度看你的网速了注意:以下是为了演示 ,我建的一个目录结构,你自己可以根据项目需求自己建目
自从Node.js出现以来,基于其的前端开发的工具框架也越来越多了,从Grunt到Gulp再到现在很火的WebPack,所有的这些新的东西的出现都极大的解放了我们在前端领域的开发,作为一个在前端领域里 ...
- 仅以一个前端开发人员的角度看微信小程序
看了几天的小程序(当然也包括了上手书写),才有了这篇博文,非技术贴,只是发表下个人观点,仅以个人技术能力来看小程序. 首先说下优点: 调试工具:官方的工具还是做了很多工作,包括监听文件变动自动刷新,编 ...
- web前端开发初学者必看的学习路线(附思维导图)
很多同学想学习WEB前端开发,虽然互联网有很多的教程.网站.书籍,可是却又不知从何开始如何选取.看完网友高等游民白乌鸦无私分享的原标题为<写给同事的前端学习路线>这篇文章,相信你会有所收获 ...
- 25个Web前端开发工程师必看的国外大牛和酷站
逛了一周国外大牛们的博客与酷站,真是满满的钦佩.震撼.羡慕.惊喜………… Web设计是一个不断变化的领域,因此掌握最新的发展趋势及技术动向对设计师来说非常重要.无论是学习新技术,还是寻找免费资源与工具 ...
- 十分钟看懂,未来Web前端开发最新趋势
首先,展望未来趋势我们就要弄懂过去的一年,也就是18年,web前端开发的重要新闻.重要事件和JavaScript的各种流行框架.模式发展趋势. 我们来快速回顾一下. NPM热门前端框架下载 先来看最热 ...
- Web前端开发的四个阶段(小白必看)
第一阶段:HTML的学习 超文本标记语言(HyperText Mark-up Language 简称HTML)是一个网页的骨架,无论是静态网页还是动态网页,最终返回到浏览器端的都是HTML代码,浏览器 ...
随机推荐
- 海量数据挖掘MMDS week5: 聚类clustering
http://blog.csdn.net/pipisorry/article/details/49427989 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 数值分析:Hermite多项式
http://blog.csdn.net/pipisorry/article/details/49366047 Hermite埃尔米特多项式 在数学中,埃尔米特多项式是一种经典的正交多项式族,得名于法 ...
- 40个比较重要的Android面试题
1. Android的四大组件是哪些,它们的作用? 答:Activity:Activity是Android程序与用户交互的窗口,是Android构造块中最基本的一种,它需要为保持各界面的状态,做很多持 ...
- noSQL数据库相关软件介绍(大数据存储时候,必须使用)
目前图数据库软件七种较为流行:Neo4J, Infinite Graph, DEX,InfoGrid, HyperGraphDB, Trinity, AllegroGraph(http://tech. ...
- Linux信号实践(1) --Linux信号编程概述
中断 中断是系统对于异步事件的响应, 进程执行代码的过程中可以随时被打断,然后去执行异常处理程序; 计算机系统的中断场景:中断源发出中断信号 -> CPU判断中断是否屏蔽屏蔽以及保护现场 -&g ...
- 【一天一道LeetCode】索引目录 ---C++实现
[一天一道LeetCode]汇总目录 这篇博客主要收藏了博主所做题目的索引目录,帮助各位读者更加快捷的跳转到对应题目 目录按照难易程度:easy,medium,hard来划分,读者可以按照难易程度进行 ...
- Linux下ipconfig分析及C语言实现
在linux下使用ifconfigl命令能很方便的查看网卡与网线是否连通,运行ifconfig eth0命令大致输出如下: # ifconfig eth0 eth0 Link encap:Ethern ...
- Robust Locally Weighted Regression 鲁棒局部加权回归 -R实现
鲁棒局部加权回归 [转载时请注明来源]:http://www.cnblogs.com/runner-ljt/ Ljt 作为一个初学者,水平有限,欢迎交流指正. 算法参考文献: (1) Robust L ...
- Swift的基础之UILabel控件
对于UILabel的相关内容,其他控件可以相似创建 //设置全局变量,将下面的 let 去掉,然后替换即可 //var myLabel = UILabel(); //系统生成的view ...
- Cocos2D中的纹理大小计算
纹理占用的内存大小是纹理尺寸乘以颜色深度. 图片文件的大小一般很小.一个初学者常见的错误是假设纹理内存使用量和图片大小一致. 哎,纹理内存(对于非压缩格式)的大小可以用以下伪代码来计算: pixelW ...