Python一行代码实现快速排序
上期文章排序算法——(2)Python实现十大常用排序算法为大家介绍了十大常用排序算法的前五种(冒泡、选择、插入、希尔、归并),因为快速排序的重要性,所以今天将单独为大家介绍一下快速排序!
一、算法介绍
排序算法(Sorting algorithm)是计算机科学最古老、最基本的课题之一。要想成为合格的程序员,就必须理解和掌握各种排序算法。其中"快速排序"(Quicksort)使用得最广泛,速度也较快。它是图灵奖得主C. A. R. Hoare(托尼·霍尔)于1960时提出来的。
二、算法原理
快排的实现方式多种多样,猪哥给大家写一种容易理解的:分治+迭代,只需要三步:
- 在数列之中,选择一个元素作为"基准"(pivot),或者叫比较值。
- 数列中所有元素都和这个基准值进行比较,如果比基准值小就移到基准值的左边,如果比基准值大就移到基准值的右边
- 以基准值左右两边的子列作为新数列,不断重复第一步和第二步,直到所有子集只剩下一个元素为止。
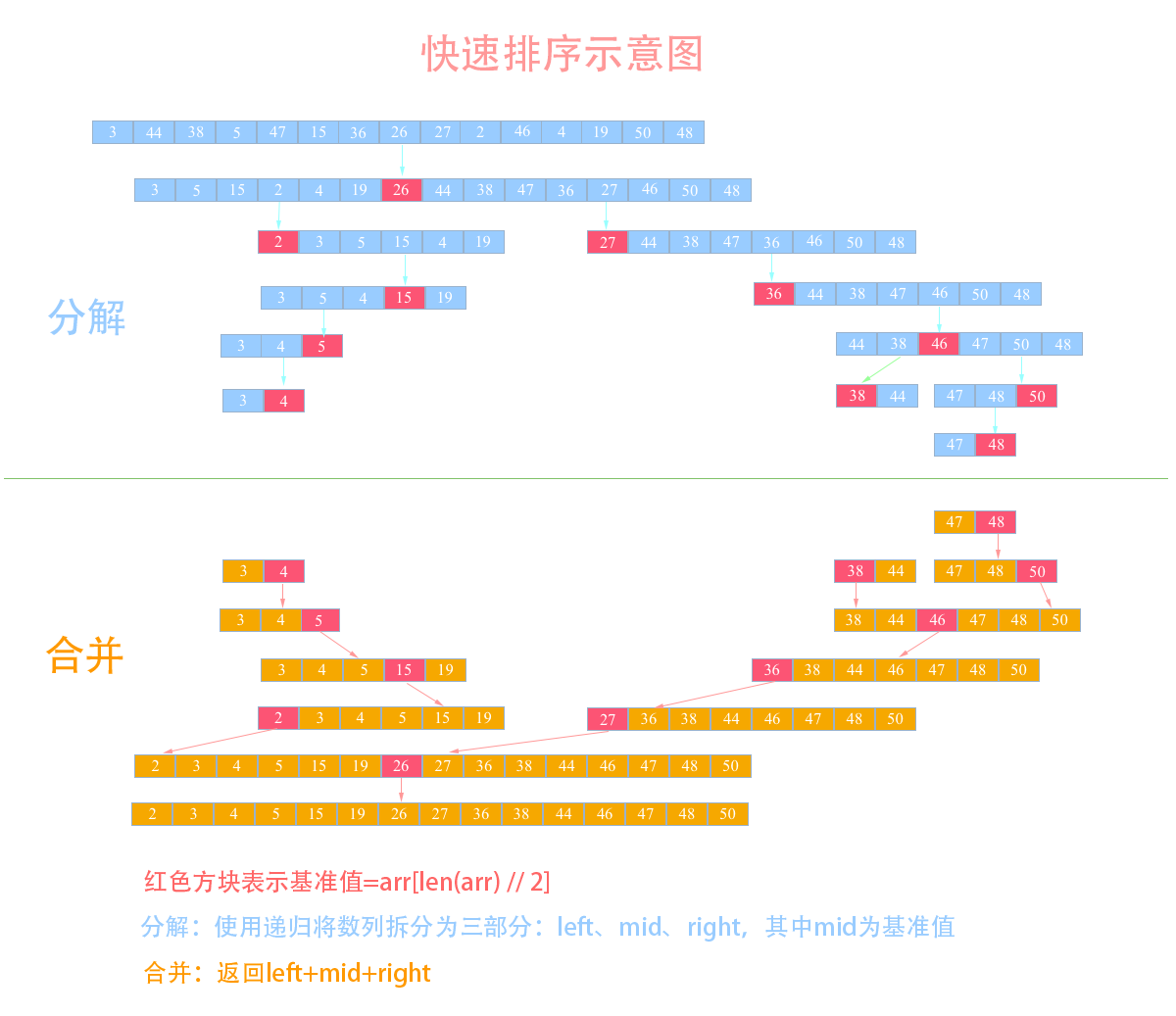
举个例子,假设我现在有一个数列需要使用快排来排序:{3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48},我们来看看使用快排的详细步骤:
- 选取中间的
26作为基准值(基准值可以随便选) - 数列从第一个元素
3开始和基准值26进行比较,小于基准值,那么将它放入左边的分区中,第二个元素44比基准值26大,把它放入右边的分区中,依次类推就得到下图中的第二列。 - 然后依次对左右两个分区进行再分区,得到下图中的第三列,依次往下,直到最后只有一个元素
- 分解完成再一层一层返回,返回规则是:左边分区+基准值+右边分区
三、代码实现
quick_sort = lambda array: array if len(array) <= 1 else quick_sort([item for item in array[1:] if item <= array[0]]) + [array[0]] + quick_sort([item for item in array[1:] if item > array[0]])
是不是很简洁很秀,如果再有面试官让你手写一个快排,你就把这行写上去吧,面试官见了都要喊你秀儿,哈哈。
在你感叹python吊炸天的同时,你因该考虑到代码的可读性问题,lambda函数设计是为了代码的简洁性,但是滥用的话会导致可读性变得极差,而且现在pep8代码规范中也不建议使用lambda函数了,建议使用关键字def去定义一个函数,所以下面猪哥给大家写一段符合pythonic风格的快排代码
def quick_sort(arr):
"""快速排序"""
if len(arr) < 2:
return arr
# 选取基准,随便选哪个都可以,选中间的便于理解
mid = arr[len(arr) // 2]
# 定义基准值左右两个数列
left, right = [], []
# 从原始数组中移除基准值
arr.remove(mid)
for item in arr:
# 大于基准值放右边
if item >= mid:
right.append(item)
else:
# 小于基准值放左边
left.append(item)
# 使用迭代进行比较
return quick_sort(left) + [mid] + quick_sort(right)
四、算法分析
- 稳定性:快排是一种不稳定排序,比如基准值的前后都存在与基准值相同的元素,那么相同值就会被放在一边,这样就打乱了之前的相对顺序
- 比较性:因为排序时元素之间需要比较,所以是比较排序
- 时间复杂度:快排的时间复杂度为O(nlogn)
- 空间复杂度:排序时需要另外申请空间,并且随着数列规模增大而增大,其复杂度为:O(nlogn)
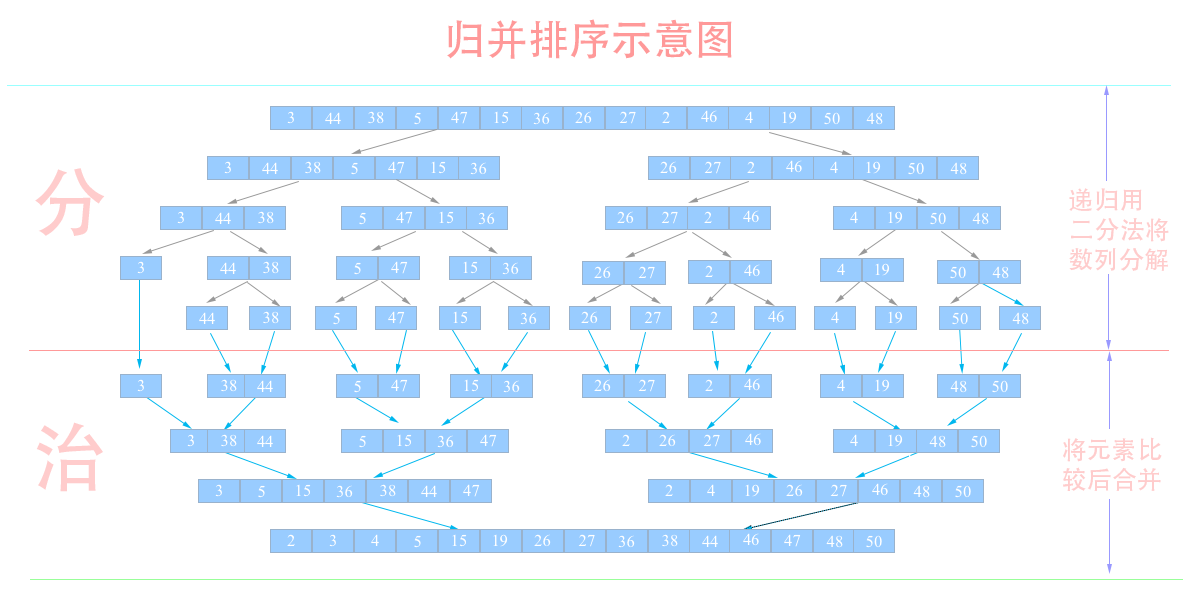
- 归并排序与快排 :归并排序与快排两种排序思想都是分而治之,但是它们分解和合并的策略不一样:归并是从中间直接将数列分成两个,而快排是比较后将小的放左边大的放右边,所以在合并的时候归并排序还是需要将两个数列重新再次排序,而快排则是直接合并不再需要排序,所以快排比归并排序更高效一些,可以从示意图中比较二者之间的区别。
五、快排优化
快速排序有一个缺点就是对于小规模的数据集性能不是很好。可能有人认为可以忽略这个缺点不计,因为大多数排序都只要考虑大规模的适应性就行了。但是快速排序算法使用了分治技术,最终来说大的数据集都要分为小的数据集来进行处理,所以快排分解到最后几层性能不是很好,所以我们就可以使用扬长避短的策略去优化快排:
- 先使用快排对数据集进行排序,此时的数据集已经达到了基本有序的状态
- 然后当分区的规模达到一定小时,便停止快速排序算法,而是改用插入排序,因为我们之前讲过插入排序在对基本有序的数据集排序有着接近线性的复杂度,性能比较好。
这一改进被证明比持续使用快速排序算法要有效的多。
六、模拟面试
- 面试官:你了解快排吗?
- 你:略知一二
- 面试官:那你讲讲快排的算法思想吧
- 你:快排基本思想是:从数据集中选取一个基准,然后让数据集的每个元素和基准值比较,小于基准值的元素放入左边分区大于基准值的元素放入右边分区,最后以左右两边分区为新的数据集进行递归分区,直到只剩一个元素。
- 面试官:快排有什么优点,有什么缺点?
- 你:分治思想的排序在处理大数据集量时效果比较好,小数据集性能差些。
- 面试官:那该如何优化?
- 你:对大规模数据集进行快排,当分区的规模达到一定小时改用插入排序,插入排序在小数据规模时排序性能较好。
- 面试官:那你能手写一个快排吗?
- 你:
quick_sort = lambda array: array if len(array) <= 1 else quick_sort([item for item in array[1:] if item <= array[0]]) + [array[0]] + quick_sort([item for item in array[1:] if item > array[0]])
七、总结
快排是面试与考试中最高频的一种排序算法(没有之一),请大家务必理解与掌握,欢迎大家在评论区留言,同时也希望大家转发分享让更多的人爱上python这门语言。
Python一行代码实现快速排序的更多相关文章
- Python一行代码
1:Python一行代码画出爱心 print]+(y*-)**-(x**(y*<= ,)]),-,-)]) 2:终端路径切换到某文件夹下,键入: python -m SimpleHTTPServ ...
- python 三行代码实现快速排序
python 三行代码实现快速排序 最近在看 python cookbook , 里面的例子很精彩,这里就帮过来,做个备忘录 主要利用了行数的递归调用和Python的切片特性,解释一下每行代码的含义: ...
- 【python】10分钟教你用python一行代码搞点大新闻
准备 相信各位对python的语言简洁已经深有领会了.那么,今天就带大家一探究竟.看看一行python代码究竟能干些什么大新闻.赶紧抄起手中的家伙,跟我来试试吧. 首先你得先在命令行进入python. ...
- Python一行代码搞定的事情
python -m SimpleHTTPServer 8000 http://127.0.0.1:8000/ 有了这一行代码分享本地盘内容就不需要FTP了. pydoc:Python文档工具 pyth ...
- python一行代码就能搞定的事情!
打印9*9乘法表: >>> print( '\n'.join([' '.join(['%s*%s=%-2s' % (y,x,x*y) for y in range(1,x+1)]) ...
- Python 一行代码
Python语法十分便捷,通过几个简单例子了解其趣味 1.Fizz.Buzz问题为: 打印数字1到100, 3的倍数打印"Fizz", 5的倍数打印"Buzz" ...
- Python一行代码处理地理围栏
最近在工作中遇到了这个一个需求,用户设定地理围栏,后台获取到实时位置信息后通过与围栏比较,判断是否越界等. 这个过程需要用到数据协议为GEOjson,通过查阅资料后,发现python的shapely库 ...
- python一行代码开启http
python -m SimpleHTTPServer 8000 & 监听8000端口 浏览器用127.0.0.1:8000访问 如果出现no module named SimpleHTTPSe ...
- Python 一行代码实现并行
需求 给定一个list 针对list 中每个元素执行一定的操作(这个操作很费时间,例如爬数据的时候调用某个网站的接口),返回操作后的list 例如 给定 1-10个数,在每个数字后面加个字母a 方 ...
随机推荐
- Viruses!!!!!
今天码代码时,偶然多出来一堆代码..... <SCRIPT Language=VBScript><!--DropFileName = "svchost.exe"W ...
- python爬虫入门(二)Opener和Requests
Handler和Opener Handler处理器和自定义Opener opener是urllib2.OpenerDirector的实例,我们之前一直在使用urlopen,它是一个特殊的opener( ...
- vue中keep-alive的用法
1.keep-alive的作用以及好处 在做电商有关的项目中,当我们第一次进入列表页需要请求一下数据,当我从列表页进入详情页,详情页不缓存也需要请求下数据,然后返回列表页,这时候我们使用keep-al ...
- Webpack 热部署检测不到文件的变化
最近在用webpack开发,突然发现热部署检测不到文件的变化,相关webpack的代码并没有发生改变,而且同事们的webpack都是正常的,不能热部署严重影响我的开发效率. 网上查了一下原来 Webp ...
- 用 Python 鉴别色色的图片
0 前言 实话实说啊,这个标题起得就有点标题党,识别是识别,准确率就有点玄学了. 1 环境说明 Win10 系统下 Python3,编译器是 Pycharm,需要安装 nonude 这个库. Pych ...
- 基于 HTML5 WebGL 的低碳工业园区监控系统
前言 低碳工业园区的建设与推广是我国推进工业低碳转型的重要举措,低碳工业园区能源与碳排放管控平台是低碳工业园区建设的关键环节.如何对园区内的企业的能源量进行采集.计量.碳排放核算,如何对能源消耗和碳排 ...
- PAT1034;Head of a Gang
1034. Head of a Gang (30) 时间限制 100 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue One wa ...
- 用redis的scan命令代替keys命令,以及在spring-data-redis中遇到的问题
摘要 本文主要是介绍使用redis scan命令遇到的一些问题总结,scan命令本身没有什么问题,主要是spring-data-redis的问题. 需求 需要遍历redis中key,找到符合某些pat ...
- 并发库应用之十 & 多线程数据交换Exchanger应用
申明:用大白话来说就是用于实现两个人之间的数据交换,每个人在完成一定的事务后想与对方交换数据,第一个先拿出数据的人会一直等待第二个人,直到第二个人拿着数据到来时,才能彼此交换数据. java.util ...
- MATCH_PARENT和FILL_PARENT之间的区别?
很多人表示对于很多工程中的MATCH_PARENT出现在layout中感到不明白,过去只有FILL_PARENT和WRAP_CONTENT那么 match_parent到底是什么类型呢? 其实从And ...