HashMap源码分析(一)
前言:相信不管在生产过程中还是面试过程中,HashMap出现的几率都非常的大,因此有必要对其源码进行分析,但要注意的是jdk1.8对HashMap进行了大量的优化,因此笔者会根据不同版本对HashMap进行分析,首先我们来看jdk1.7中HashMap的原理。
注:本文jdk源码版本为jdk1.7.0_80。
1.从demo入手
public class HashMapTest {
public static void main(String[] args) {
String key_Aa = "Aa";
String key_BB = "BB";
// 注意这里的hashCode值
System.out.println("key_Aa hashCode=" + key_Aa.hashCode());
System.out.println("key_BB hashCode=" + key_BB.hashCode());
Map<String, String> hashMap = new HashMap<String, String>();
hashMap.put(key_Aa,"Aa");
hashMap.put(key_Aa,"Aa");
// hashMap.put(key_BB,"Aa");
System.out.println(hashMap);
}
}
先直接看运行结果:
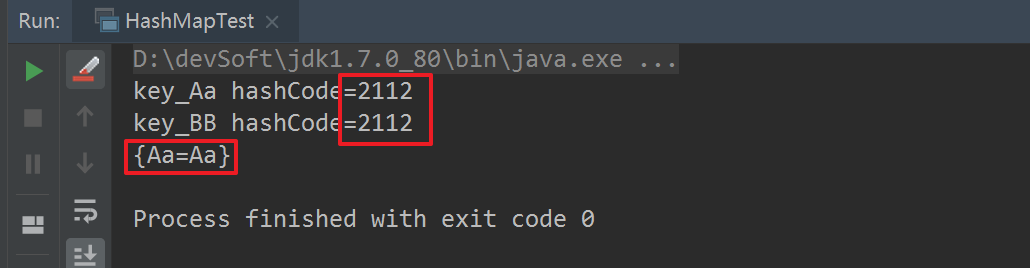
然后打开16行代码的注释,再次运行:
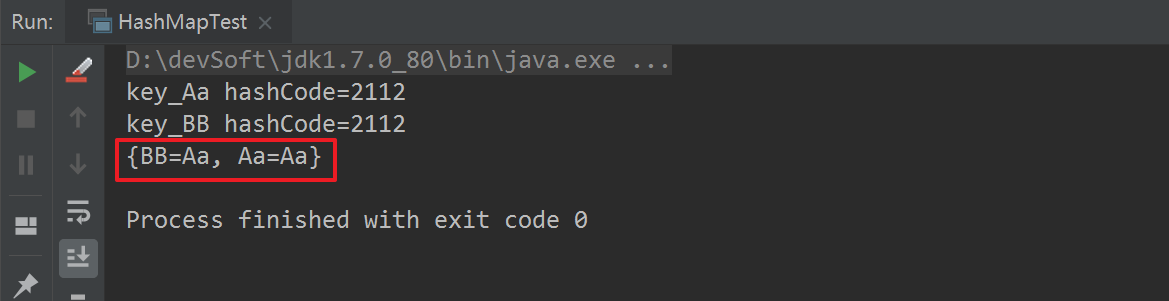
通过以上两组运行结果,我们可以得出如下结论:
#1.不同内容的字符串,其hashCode值可能是相等的。
#2.HashMap在进行put操作时,key相同时(注:hashCode和内容都是一样的),进行了覆盖;key不同时(注:【hashCode不同】或【hashCode相同,内容不同】)进行了插入(直接插入table上,或进行链表式插入数据)操作。
#3.对于HashMap来说,重要的是key,而不是value,value相当于key的一个附属值。
有了以上结论,接下来我们对其源码进行分析就比较有针对性了。
2.源码分析
2.1 put操作
public V put(K key, V value) {
// 如果table为空,则初始化
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null) // 从这里可看出HashMap是可以插入null值的,key,value都可以为null
return putForNullKey(value);
int hash = hash(key); // 对key进行hash操作
int i = indexFor(hash, table.length); // 找出key的hash值在table中对应的位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 如果该位置上元素的hash值与插入元素的hash值相等,并且key也相等或者内容相等,这里就进行覆盖操作 这里与demo中结论相吻合
// 注意这里的写法,比较巧妙
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 插入新元素,并且modCount++,modCount表示HashMap修改的次数
modCount++;
addEntry(hash, key, value, i);
return null;
}
分析:
#1.HashMap的元素是存储在table中,table的类型为Entry数组,先了解下Entry结构:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next; // 存储下一个元素的值,这不就是一个链表吗,因此HashMap的底层数组结构为数组+链表的形式
int hash;
/**
* Creates new entry.
*/
// 从Entry的构造函数可以得出结论,在创建一个new Entry的时候,会将old Entry(在table位置上的元素)放在new Entry的next位置,形成链表。从其构造形式可以得出结论:在插入元素时采用的是头插入,新元素都是放在链表头(table上)的,将原来的头元素放在新元素的next位置,形成一个新的链表
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;// 当前新元素value
next = n; // next表示原来的old Entry
key = k; // 当前新元素key
hash = h;
}
.......
.......
.......
}
要点:头插法
#2.inflateTable方法,初始化table。
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
/**
* HashMap的容量都是2的n次方的,这里表示计算出比传入参数最小的2的n次方的值
*/
/**
* HashMap的默认容量:
* The default initial capacity - MUST be a power of two.
* static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
*/
int capacity = roundUpToPowerOf2(toSize);
/**
* 扩容阈值,通过HashMap容量与扩容因子计算出来
* 默认扩容因子为0.75
* The load factor used when none specified in constructor.
* static final float DEFAULT_LOAD_FACTOR = 0.75f;
*/
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
// 该函数主要在扩容中使用,判断是否需要重新计算hash值
initHashSeedAsNeeded(capacity);
}
#3.从put函数可以看出HashMap是可以存储key为null的元素的,由于value为key的附属值,所以value也可以为null。
private V putForNullKey(V value) {
// 循环找出key=null的元素,然后将其值覆盖,从这里可以看出HashMap中key=null时,是不会形成链表的
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果没有key为null的元素,则增加一个元素
modCount++;
addEntry(0, null, value, 0);
return null;
}
#4.在putForNullKey中出现了addEntry函数,因此这里对其进行分析。
/**
* HashMap增加元素
*
* @param hash key的hash值
* @param key key值
* @param value value值
* @param bucketIndex 插入元素在table中的位置
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果当前HashMap的容量大于扩容阈值并且当前插入元素的位置在table上对应的值不为null
// 注意这里的table[bucketIndex]非常重要,如果当前位置上为空,是不需要扩容的
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容,将新容量扩容为原来的2倍
resize(2 * table.length);
// 再次计算key的hash值,然后找出元素在新table中对应的位置
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
// 创建新元素
createEntry(hash, key, value, bucketIndex);
}
重点:在判断是否需要扩容时,需要判断当前位置在table上的元素是否为null,只有不为null才进行扩容。
#5.resize函数,这里先不忙分析,先看createEntry函数。
/**
* 创建元素
*
* @param hash key的hash值
* @param key key值
* @param value value值
* @param bucketIndex 插入元素在table中的位置
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
// 取出要插入位置上的元素,可能为null,也可能有具体元素
Entry<K, V> e = table[bucketIndex];
// 在插入位置上直接创建新元素,注意这里传入的参数e,在Entry构造函数中会放在next中,从而形成链表,从这里也可以看出在出现hash碰撞的时候,HashMap在插入元素的时候,采用的是头插法
table[bucketIndex] = new Entry<>(hash, key, value, e);
// size++,表示容量增加1个
size++;
}
重点:插入元素时采用的头插法。因为采用头插法,所以在hash碰撞的时候,才会出现demo中的结果,注意理解,这里交相呼应。
#6.在put方法中有两个方法值得我们注意hash(Object k)和indexFor(int h, int length)。
final int hash(Object k) {
int h = hashSeed;
// 如果使用了再次hash,并且key的类型为String,则直接使用String的hash算法返回其hash值
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
// 如果走到这里h可能为0或者为1,再次异或上k的hashCode,如果h为1,表示再hash,则这里的h可能会±1,h为0的时候,h就表示k的hashCode
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
// 这里进行两次hash主要是为了最大可能的解决hash碰撞,防止低位不变,而高位变化时,产生hash碰撞
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
这里为什么要进行了两次hash,通过如下计算过程可以大致了解一下:
假设目前hashMap的容量为
-------------------------------------------------------------------
h_1: 0101 1000 1101 0011 1110 1001 1011
h_1>>>20: 0000 0000 0000 0000 0000 0101 1000 1101
h_1>>>12: 0000 0000 0000 0101 1000 1101 0111 0011
h_1>>>20^h_1>>>12: 0000 0000 0000 0101 1000 1000 1111 1110
h_1: 0101 1000 1101 0111 0011 1110 1001 1011
h_1^h_1>>>20^h_1>>>12: 0101 1000 1101 0010 1011 0110 0100 0101
h_1>>>7: 0000 0000 1011 0001 1010 0101 0110 1100
h_1>>>4: 0000 0101 1000 1101 0010 1011 0110 0100
h_1^h_1>>>7: 0101 1000 0110 0011 0001 0011 0010 1001
h_1^h_1>>>7^h_1>>>4 0101 1101 1110 1110 0011 1000 0100 1101
&table.length-1: 0000 0000 0000 0000 0000 0000 0000 1111
result: 0000 0000 0000 0000 0000 0000 0000 1101=13
---------------------------------------------------------------------
h_2: 0101 1000 1101 0011 1110 1001 1011
h_2>>>20: 0000 0000 0000 0000 0000 0101 1000 1101
h_2>>>12: 0000 0000 0000 0101 1000 1101 1111 0011
h_2>>>20^h_2>>>12: 0000 0000 0000 0101 1000 1000 1111 1110
h_2: 0101 1000 1101 1111 0011 1110 1001 1011
h_2^h_2>>>20^h_2>>>12: 0101 1000 1101 1010 1011 0110 0110 0101
h_2>>>7: 0000 0000 1011 0001 1011 0101 0110 1100
h_2>>>4: 0000 0101 1000 1101 1010 1011 0110 0110
h_2^h_2>>>7: 0101 1000 0110 1011 0000 0011 0000 1001
h_2^h_2>>>7^h_2>>>4 0101 1101 1110 0110 1010 1000 0110 1111
&table.length-1: 0000 0000 0000 0000 0000 0000 0000 1111
result: 0000 0000 0000 0000 0000 0000 0000 1111=15
分析:
注意上述计算过程中h_1和h_2只有高位中有一位不同,其余全都相同。
如果不采用二次hash这种方式,而是直接和table.length-1进行与操作,得到的结果都是11,造成hash碰撞;采用二次hash的方式,将高位加入运算,对key的hashCode进行了扰动计算,防止低位不变,而高位变化时造成hash碰撞,从而尽可能的减少hash碰撞。
再看indexFor函数:
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
// 这里采用位运算来进行操作,求出元素在table中的位置,相当于mod运算,但是位运算效率更高
// 从这里可以了解到为什么HashMap的容量必须为2的n次方,因为2的n次方-1的二进制永远全部是1,这样会减少hash碰撞
/**
* h & (table.length-1) hash table.length-1
*
* 8 & (15-1): 0100 & 1110 = 0100
*
* 9 & (15-1): 0101 & 1110 = 0100
*
* ----------------------------------------------------------------------------------
*
* 8 & (16-1): 0100 & 1111 = 0100
*
* 9 & (16-1): 0101 & 1111 = 0101
*/
return h & (length-1);
}
重点:从这里反推出:为什么HashMap的容量为什么会是2的n次方,因为这样可以尽量减少hash碰撞。
#7.接下来进入HashMap的扩容函数resize(int newCapacity):
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
// 判断是否允许扩容
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 创建一个新的Entry数组,容量为原来的2倍
Entry[] newTable = new Entry[newCapacity];
// 扩容主要函数transfer
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
// 更新扩容阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
注意:HashMap扩容后容量变为原来的2倍,在resize中的核心函数就是transfer:
/**
* 扩容核心函数
*
* @param newTable 新的Entry数组
* @param rehash 是否需要再次hash
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
// 循环原table
for (Entry<K, V> e : table) {
// 当元素为null时,循环结束
while (null != e) {
// 存储当前元素的next,因为可能存在链表结构,所以必须存储next元素
Entry<K, V> next = e.next;
// 判定是否需要再次对key进行hash操作
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 得到元素在newTable中的位置
int i = indexFor(e.hash, newCapacity);
/*
* #1.将newTabe[i]位置上的元素放入e的next位置
* #2.将e放入newTable[i]位置
* #3.将next元素赋值给e,继续进行循环
* 注意:这里会将原链表(如果存在)进行反序
* 原:3->7->5
* 第一次循环:newTable[i]=3,其next=null
* 第二次循环:newTable[i]=7,其next=newTable[i]=3(上一次的)
* 第三次循环:newTable[i]=5,其next=newTable[i]=7,next.next=3
* 最终结果:5->7->3,进行了反序
*/
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
注意:transfer函数为扩容的核心函数,并且会将原table上的链表(如果存在)进行反序,这里也是HashMap在多线程中线程不安全的体现,具体线程不安全体现分析传送门:HashMap线程不安全的体现
至此HashMap的put源码已经分析完毕,下面继续分析HashMap中的其他源码。
2.2 get操作
public V get(Object key) {
// 如果key=null,则通过getForNullKey函数返回值,这里也侧面反映出HashMap的key可以为null的
if (key == null)
return getForNullKey();
// 通过key取得具体的元素
Entry<K,V> entry = getEntry(key);
// 返回值,这里也反映出HashMap的值也可以是null的
return null == entry ? null : entry.getValue();
}
分析:
通过HashMap的get函数,可得出结论:HashMap的key可以为null,其value也可以为null,因为value相当于key的一个附属值,既然key可以为null,value当然也可以。
#1.getForNullKey函数
private V getForNullKey() {
// 如果HashMap中还未put元素,则直接返回null
if (size == 0) {
return null;
}
// 在table中循环,找到key为null的元素,直接返回去value
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
// 如果在table中未找到,则直接返回null
return null;
}
getForNullKey函数逻辑简单,通过以上注释,基本上可以理解清楚。
#2.getEntry(Object key) 函数
final Entry<K,V> getEntry(Object key) {
// 如果HashMap中没有元素,则直接返回null
if (size == 0) {
return null;
}
// 注意这里再次判断了key是否为null,然后通过hash算法计算出hashCode
int hash = (key == null) ? 0 : hash(key);
// 由于可能table上可能存在链表,所以这里要从table[index]开头进行循环
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
// 当元素的hashCode和key相同时,直接返回元素
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
// 如果未找到,则返回null
return null;
}
要点:通过key找元素的时候,由于HashMap的底层结构是数组+链表的形式,所以这里要进行循环。
2.3 其他重要函数
#1.removeEntryForKey(Object key),该函数为remove的核心函数。
final Entry<K,V> removeEntryForKey(Object key) {
// 如果HashMap中没有元素,则直接返回null
if (size == 0) {
return null;
}
// 计算key的hash值
int hash = (key == null) ? 0 : hash(key);
// 找到key在table上的位置
int i = indexFor(hash, table.length);
// prev记录table[i]的前一个元素,初始时等于table[i]
Entry<K,V> prev = table[i];
// e记录要删除元素开始处,初始时等于table[i]
Entry<K,V> e = prev;
// 循环寻找要删除的元素
while (e != null) {
// 由于table中可能存在链表,所以需要记录一下next的值。
Entry<K,V> next = e.next;
Object k;
// 当e的hashCode和key与入参相同时,则找到要删除的元素
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++; // 修改次数加1
size--; // HashMap包含元素减1
// 因为初始时,prev=e,也就是说要移除的元素就是table[i]上,则直接将table[i]指向e.next,后面的都不需要移动
if (prev == e)
table[i] = next;
else
prev.next = next; // 如果prev!=null,prev记录的是当前准备删除元素的前一个元素,这里直接将prev.next存储e的next值,就把e踢出了,prev和e的后一个元素形成了链表
e.recordRemoval(this);
return e;
}
// 如果上述未找到,则prev=e,记录当前准备删除元素的前一个元素
prev = e;
// e赋值为next继续删除操作
e = next;
}
return e;
}
分析:
removeEntryForKey函数用得非常巧妙,只修改了一个节点的next值,就进行了删除操作,注意理解具体的删除逻辑。
为了更直观的了解remove的过程,笔者这里通过源码的调试来展示其具体过程:
public static void main(String[] args) {
String key_Aa = "Aa";
String key_BB = "BB";
// 注意这里的hashCode值
System.out.println("key_Aa hashCode=" + key_Aa.hashCode());
System.out.println("key_BB hashCode=" + key_BB.hashCode());
Map<String, String> hashMap = new HashMap<String, String>();
hashMap.put(key_Aa, "Aa");
hashMap.put(key_Aa, "Aa");
hashMap.put(key_BB, "Aa");
hashMap.remove(key_BB);
// hashMap.remove(key_Aa);
System.out.println(hashMap);
}
将上述代码Debug:

注意:由于“Aa”和“BB”的hashCode相等,所以此时HashMap是链式存储,顺序为key:BB->Aa。
直接进入remove函数内部:
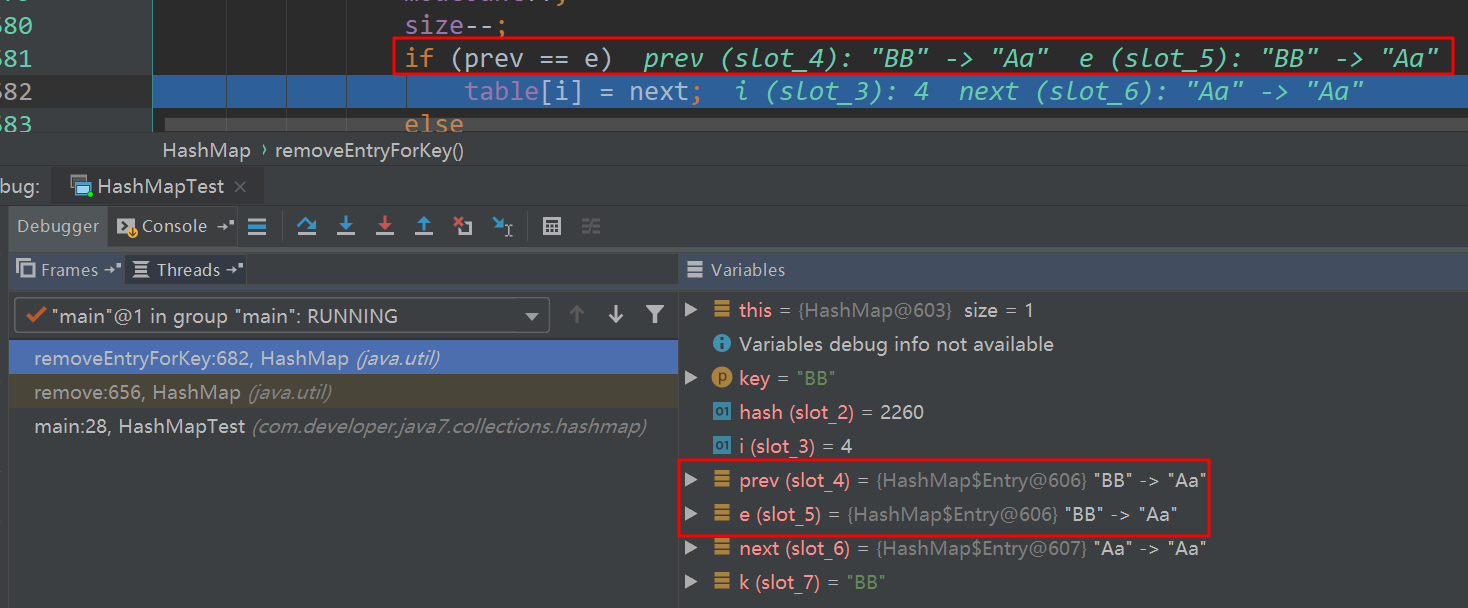
此时找到了删除元素,并且prev与e是相等的,所以直接将table[i]=next就移除了e了。
将上述代码15行注释,打开16行,再次进入remove内部:
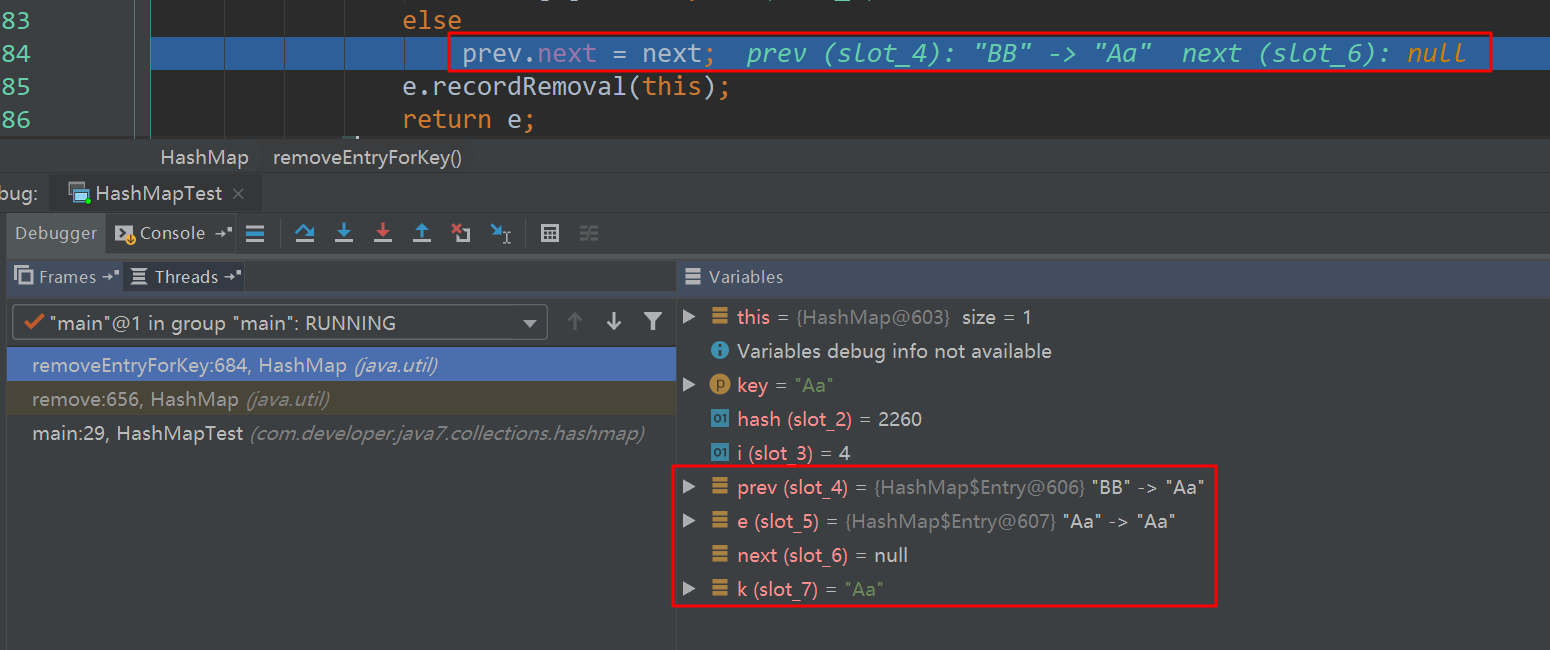
分析:
由于table[i]头上放置的是key为BB的元素,所以在第一次比较的时候,直接跳过,此次prev=BB,e=Aa,从这里可以看出,prev存储的是当前将要删除元素的前一个元素,所以删除时直接使用prev.next=next就踢出e了。
通过以上Debug过程,删除元素的过程应该非常清晰了。
#2.HashMap的fail-fast机制。
还是通过代码入手:
package com.developer.java7.collections.hashmap; import java.util.HashMap;
import java.util.Map; /**
* @author: developer
* @date: 2019/3/3 9:29
* @description: hashmap测试
*/ public class HashMapTest { public static void main(String[] args) { String key_Aa = "Aa";
String key_BB = "BB";
String key_Cc = "Cc";
String key_Dd = "Dd"; // 注意这里的hashCode值
System.out.println("key_Aa hashCode=" + key_Aa.hashCode());
System.out.println("key_BB hashCode=" + key_BB.hashCode()); Map<String, String> hashMap = new HashMap<String, String>(); hashMap.put(key_Aa, "Aa");
hashMap.put(key_Aa, "Aa");
hashMap.put(key_BB, "Aa");
hashMap.put(key_Cc, "Cc");
hashMap.put(key_Dd, "Dd");
for (String key : hashMap.keySet()) {
if (key_Dd.equals(key)) {
hashMap.remove(key);
}
}
System.out.println(hashMap); } }
运行结果如下:
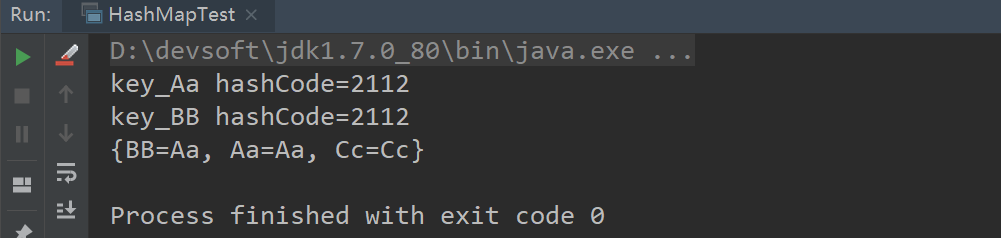
将代码稍微修改一下:
public static void main(String[] args) {
String key_Aa = "Aa";
String key_BB = "BB";
String key_Cc = "Cc";
String key_Dd = "Dd";
// 注意这里的hashCode值
System.out.println("key_Aa hashCode=" + key_Aa.hashCode());
System.out.println("key_BB hashCode=" + key_BB.hashCode());
Map<String, String> hashMap = new HashMap<String, String>();
hashMap.put(key_Aa, "Aa");
hashMap.put(key_Aa, "Aa");
hashMap.put(key_BB, "Aa");
hashMap.put(key_Cc, "Cc");
hashMap.put(key_Dd, "Dd");
for (String key : hashMap.keySet()) {
if (key_Cc.equals(key)) {
hashMap.remove(key);
}
}
System.out.println(hashMap);
}
运行结果如下:
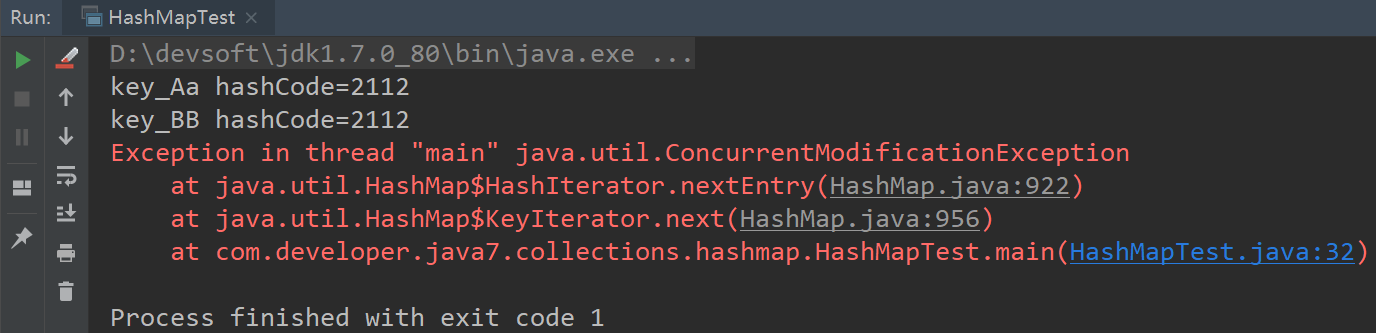
出现异常了,接着修改代码,依次移除key_Aa,key_BB都会报该异常,只有删除最后一个元素不会报异常,这是HashMap的fail-fast机制。
为什么删除最后一个元素不会报错呢,这里简要分析一下:
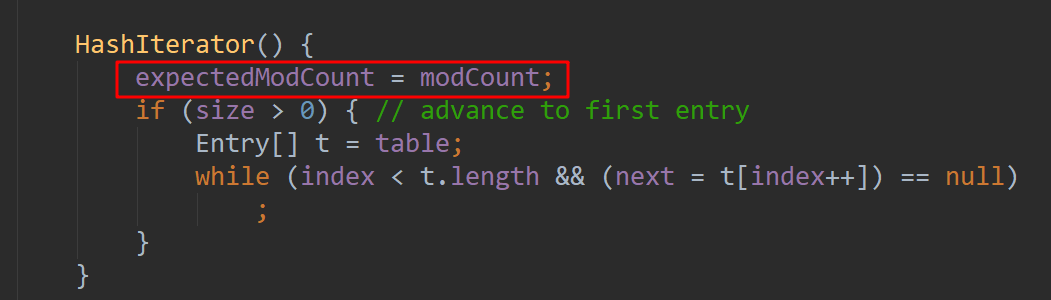
在循环初始化Iterator时,会先记录HashMap修改的次数。
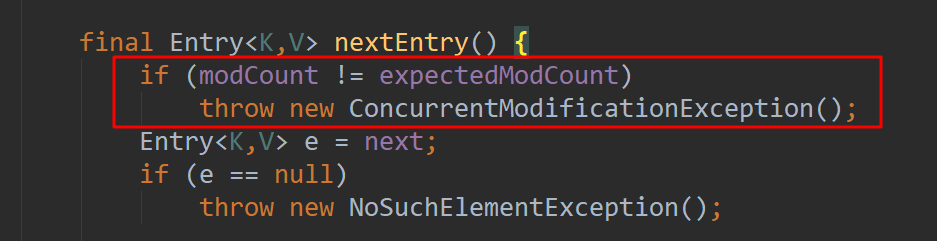
每次去获取nextEntry元素时,会判断modCount是否和expectedModCount是否相等,如果不相等则直接抛出异常。因为expectedModCount只是初始化的时候保存了modCount的值,后续modCount修改后并不会更新expectedModCount,所以remove时抛出异常。
但是为什么删除最后一个元素不抛异常呢?
这里的next已经为null了,不会往下走了,所以不抛异常,但是如果next不为null,也会抛异常的。
HashMap本身线程不安全,所以出现fail-fast也是正常的,在面对并发修改时,迭代器很快就会抛出异常,从而确定修改方法。
总结
至此,HashMap源码基本分析完了,后续如果还有一些重要的点,再加上。这里将源码分析中的重点再次总结一下:
#1.HashMap无序,通过源码调试的截图可知,因为HashMap是根据key的hash值来进行存储的,从这里也可以确定HashMap是无序的。
#2.HashMap线程不安全。
#3.HashMap可以存储key=null和value=null的值。
by Shawn Chen,2019.03.05,下午。
HashMap源码分析(一)的更多相关文章
- 【JAVA集合】HashMap源码分析(转载)
原文出处:http://www.cnblogs.com/chenpi/p/5280304.html 以下内容基于jdk1.7.0_79源码: 什么是HashMap 基于哈希表的一个Map接口实现,存储 ...
- Java中HashMap源码分析
一.HashMap概述 HashMap基于哈希表的Map接口的实现.此实现提供所有可选的映射操作,并允许使用null值和null键.(除了不同步和允许使用null之外,HashMap类与Hashtab ...
- JDK1.8 HashMap源码分析
一.HashMap概述 在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的节点都存储在一个链表里.但是当位于一个桶中的元素较多,即hash值相等的元素较多时 ...
- HashMap源码分析和应用实例的介绍
1.HashMap介绍 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射.HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io.S ...
- 【Java】HashMap源码分析——常用方法详解
上一篇介绍了HashMap的基本概念,这一篇着重介绍HasHMap中的一些常用方法:put()get()**resize()** 首先介绍resize()这个方法,在我看来这是HashMap中一个非常 ...
- 【Java】HashMap源码分析——基本概念
在JDK1.8后,对HashMap源码进行了更改,引入了红黑树.在这之前,HashMap实际上就是就是数组+链表的结构,由于HashMap是一张哈希表,其会产生哈希冲突,为了解决哈希冲突,HashMa ...
- Java BAT大型公司面试必考技能视频-1.HashMap源码分析与实现
视频通过以下四个方面介绍了HASHMAP的内容 一. 什么是HashMap Hash散列将一个任意的长度通过某种算法(Hash函数算法)转换成一个固定的值. MAP:地图 x,y 存储 总结:通过HA ...
- Java源码解析——集合框架(五)——HashMap源码分析
HashMap源码分析 HashMap的底层实现是面试中问到最多的,其原理也更加复杂,涉及的知识也越多,在项目中的使用也最多.因此清晰分析出其底层源码对于深刻理解其实现有重要的意义,jdk1.8之后其 ...
- HashMap源码分析(史上最详细的源码分析)
HashMap简介 HashMap是开发中使用频率最高的用于映射(键值对 key value)处理的数据结构,我们经常把hashMap数据结构叫做散列链表: ObjectI entry<Key, ...
- HashMap 源码分析 基于jdk1.8分析
HashMap 源码分析 基于jdk1.8分析 1:数据结构: transient Node<K,V>[] table; //这里维护了一个 Node的数组结构: 下面看看Node的数 ...
随机推荐
- CTF取证方法大汇总,建议收藏!
站在巨人的肩头才会看见更远的世界,这是一篇来自技术牛人的神总结,运用多年实战经验总结的CTF取证方法,全面细致,通俗易懂,掌握了这个技能定会让你在CTF路上少走很多弯路,不看真的会后悔! 本篇文章大约 ...
- HTML之常用标签及属性
标签 标签分类 标签名 英文 英文含义 标签类型 备注 HTML页面结构 < html> HyperText Markup Language 超文本标记语言 < head> h ...
- 【Netty】(6) ---源码ServerBootstrap
[Netty]6 ---源码ServerBootstrap 之前写了两篇与Bootstrap相关的文章,一篇是ServerBootstrap的父类,一篇是客户端Bootstrap类,博客地址: [Ne ...
- GC参考手册 —— GC 算法(实现篇)
学习了GC算法的相关概念之后, 我们将介绍在JVM中这些算法的具体实现.首先要记住的是, 大多数JVM都需要使用两种不同的GC算法 —— 一种用来清理年轻代, 另一种用来清理老年代. 我们可以选择JV ...
- OA发展史:由点到生态
在当今无边界组织的商业背景下,企业与员工关系已经转化为联盟关系,以往通过工作场所.劳动合同等约束的形式已经逐步弱化,管理行为空前复杂,OA正是将一个个散点整合起来的看不见的手.那么,推动OA发展的核心 ...
- kernel 进阶API
1. #define cond_resched() ({ \ ___might_sleep(__FILE__, __LINE__, ); \ _cond_resched(); \ }) int __s ...
- asp.net core系列 30 EF管理数据库架构--必备知识 迁移
一.管理数据库架构概述 EF Core 提供两种主要方法来保持 EF Core 模型和数据库架构同步.一是以 EF Core 模型为基准,二是以数据库为基准. (1)如果希望以 EF Core 模型为 ...
- C# 30分钟完成百度人脸识别——进阶篇(文末附源码)
距离上次入门篇时隔两个月才出这进阶篇,小编惭愧,对不住关注我的卡哇伊的小伙伴们,为此小编用这篇博来谢罪. 前面的准备工作我就不说了,注册百度账号api,创建web网站项目,引入动态链接库引入. 不了解 ...
- C#根据屏幕分辨率改变图片尺寸
最近工作中遇到一个问题,就是需要将程序文件夹中的图片根据此时电脑屏幕的分辨率来重新改变图片尺寸 以下为代码实现过程: 1.获取文件夹中的图片,此文件夹名为exe程序同目录下 //读取文件夹中文件 Di ...
- 2019/1.7 js面向对象笔记
面向对象 1.构造函数里的属性怎么看?看this,谁前面有this谁就是属性. num不是属性,是私有作用域下的私有变量. 2.如何查找面向对象中的this 1.构造函数的this指向实例对象 2.如 ...