论文笔记(4):Fully Convolutional Networks for Semantic Segmentation
一、FCN中的CNN
首先回顾CNN测试图片类别的过程,如下图:
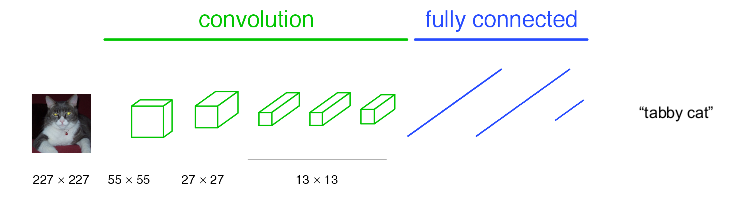
主要由卷积,pool与全连接构成,这里把卷积与pool都看作图中绿色的convolution,全连接为图中蓝色的fully connected。卷积主要是获取高维特征,pool使图片缩小一半,全连接与传统神经网络相似作为权值训练,最后通过softmax输出概率最高的类别。上图中nxn表示feature map(特征图)大小, 如原图大小为227x227,经过卷积与pool后得到55x55的特征图(一层的特征图可以有多个类别)。注意,不同的卷积操作可能会对图片大小产生影响,而pool永远使图片缩小1/2。经过多次卷积后特征图大小为13x13,特征图的权值展开为1维与后面的权值实现全连接,最后使用softmax输出类别。这就是CNN的大致网络结构与分类过程。
经过CNN改造的FCN如下图:
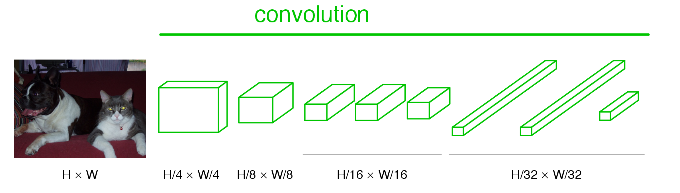
可以看到蓝色的全连接层全部换成了卷积层,对于CNN的过程就是做了这么简单直白的替换,全卷积的名字由此而来,这就是FCN。图中nxn是表示特征图的大小,可以看到最后特征图的大小为原图的1/32(这与FCN论文中解释upsample实现end to end 的32stride,16stride,8stride有莫大的关系)。
二、FCN中的upsample
upsample意为上采样,简单来说就是pooling的逆过程,所以pooling又叫下采样。
下采样(pooling)后数据量减少;上采样(upsample)后数据量增多。
FCN作者在论文中讨论了3种upsample方法,最后选用的是反卷积的方法(FCN作者称其为后卷积)使图像实现end to end,可以理解为unsample就是使大小比原图像小得多的特征图变大,使其大小达到原图像的大小。
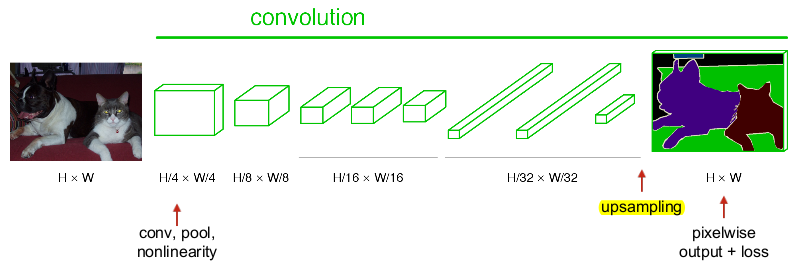
下面解释FCN中如何实现unsample,对于FCN-32s,FCN-16s,FCN-8s,论文中有一个图是描述这个三个过程的,如下图:
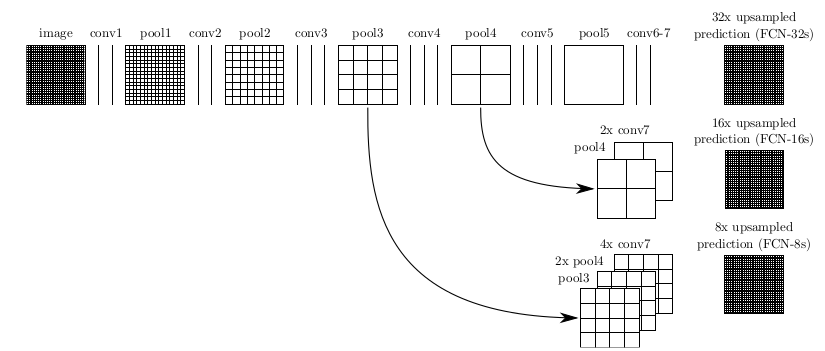
image是原图像,conv1,conv2..,conv5为卷积操作,pool1,pool2,..pool5为pool操作(pool就是使得图片变为原图的1/2),注意conv6-7是最后的卷积层,最右边一列是upsample后的end to end结果。必须说明的是图中nx是指对应的特征图上采样n倍(即变大n倍),并不是指有n个特征图,如32x upsampled 中的32x是图像只变大32倍,不是有32个上采样图像,又如2x conv7是指conv7的特征图变大2倍。
第一行对应FCN-32s,第二行对应FCN-16s,第三行对应FCN-8s。
先从FCN-32s开始说明upsample过程,只需要留意第一行,网络里面有5个pool,所以conv7的特征图是原始图像1/32,可以发现最左边image的是32x32,同时我们知道在FCN中的卷积是不会改变图像大小的(或者只有少量像素的减少,特征图大小基本不会小很多),看到pool1是16x16,pool2是8x8,pool3是4x4,pool4是2x2,pool5是1x1,所以conv7对应特征图大小为1x1,然后再经过32x upsampled prediction 图片变回32x32。FCN作者在这里增加一个卷积层,卷积后的大小为输入图像的32(2^5)倍,我们简单假设这个卷积核大小也为32,这样就是需要通过反馈训练32x32个权重变量即可让图像实现end to end,完成了一个32s的upsample,FCN作者称做后卷积,他也提及可以称为反卷积。事实上在源码中卷积核的大小为64,同时没有偏置bias。还有一点就是FCN论文中最后结果都是21x…,这里的21是指FCN使用的数据集分类,总共有21类。
现在我们把1,2两行一起看,忽略32x upsampled prediction,说明FCN-16s的upsample过程。FCN作者在conv7先进行一个2x conv7操作,其实这里也只是增加1个卷积层,这次卷积后特征图的大小为conv7的2倍,可以从pool5与2x conv7中看出来,此时2x conv7与pool4的大小是一样的,FCN作者提出对pool4与2x conv7进行一个fuse操作(事实上就是将pool4与2x conv7相加),fuse结果进行16x upsampled prediction,与FCN-32s一样,也是增加一个卷积层,卷积后的大小为输入图像的16(2^4)倍,我们知道pool4的大小是2x2,放大16倍,就是32x32,这样最后图像大小也变为原来的大小,至此完成了一个16s的upsample。现在我们可以知道,FCN中的upsample实际是通过增加卷积层,通过bp反馈的训练方法训练卷积层达到end to end,这时卷积层的作用可以看作是pool的逆过程。
最后,我们看第1行与第3行,忽略32x upsampled prediction,conv7经过一次4x upsample,即使用一个卷积层,特征图输出大小为conv7的4倍,所以4x conv7的大小为4x4,然后pool4需要一次2x upsample,变成2x pool4,大小也为4x4,最后把4x conv7,2x pool4与pool3进行fuse,得到求和后的特征图,最后增加一个卷积层,使得输出图片大小为pool3的8倍,也就是8x upsampled prediction的过程,最后也得到一个end to end的图像。同时FCN-8s优于FCN-16s和FCN-32s。
可以发现,如果继续仿照FCN作者的步骤,我们可以对pool2,pool1实现同样的方法,可以有FCN-4s,FCN-2s,最后得到end to end的输出。这里作者给出了明确的结论,超过FCN-8s之后,结果并不能继续优化。
综合上述的FCN全卷积与upsample,在upsample最后加上softmax,就可以对不同类别的大小概率进行估计,实现end to end,最后输出的图是一个概率估计,对应像素点的值越大,其像素为该类的可能性也越大。
FCN的核心贡献在于提出使用卷积层通过学习让图片实现end to end 分类。事实上,FCN有一些短处,例如使用了较浅层的特征,因为fuse操作会加上较上层的pool特征值,这导致高维特征不能很好地得以使用,同时也因为使用较上层的pool特征值导致FCN对图像大小变化有所要求,如果测试集的图像远大于或小于训练集的图像,FCN的效果就会变差。但是,也由于FCN提出了一种新的语义分割方法,才有了后面韩国Hyeonwoo Noh的对称反卷积网络,剑桥的SegNet等优秀用于语义分割的CNN网络。
论文笔记(4):Fully Convolutional Networks for Semantic Segmentation的更多相关文章
- 论文笔记《Fully Convolutional Networks for Semantic Segmentation》
一.Abstract 提出了一种end-to-end的做semantic segmentation的方法,也就是FCN,是我个人觉得非常厉害的一个方法. 二.亮点 1.提出了全卷积网络的概念,将Ale ...
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
- Fully Convolutional Networks for Semantic Segmentation 译文
Fully Convolutional Networks for Semantic Segmentation 译文 Abstract Convolutional networks are powe ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
- 【Semantic segmentation】Fully Convolutional Networks for Semantic Segmentation 论文解析
目录 0. 论文链接 1. 概述 2. Adapting classifiers for dense prediction 3. upsampling 3.1 Shift-and-stitch 3.2 ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文阅读笔记十三:The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation(FC-DenseNets)(CVPR2016)
论文链接:https://arxiv.org/pdf/1611.09326.pdf tensorflow代码:https://github.com/HasnainRaz/FC-DenseNet-Ten ...
- VGGNet论文翻译-Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition Karen Simonyan[‡] & Andrew Zi ...
- 中文版 R-FCN: Object Detection via Region-based Fully Convolutional Networks
R-FCN: Object Detection via Region-based Fully Convolutional Networks 摘要 我们提出了基于区域的全卷积网络,以实现准确和高效的目标 ...
随机推荐
- datatables行编辑中,某个字段用户显示和用于行编辑名称不同时的处理。
比如tag这个字段,对应服务端bean的tag,但是在页面显示时需要为String类型的tagName,那么在行编辑时可以用以下的方式处理.
- maven排除jar包冲突
首先查看mvn中冲突的包 使用命令:mvn dependency:tree -Dverbose | grep "omitted for conflict with" windows ...
- iOS实现从服务器请求json数据并转化成NSDictionary
NSURL *url = [NSURL URLWithString:URL]; NSURLRequest *request = [NSURLRequest requestWithURL:url cac ...
- Java文件及文件夹的创建与删除
功能 这个实例实现了在D盘创建一个文件和文件夹,并删除它们. 函数介绍 createNewFile():当文件不存在时,根据绝对路径创建该文件. delete():删除文件或者文件夹. ...
- Windows 窗体中的事件顺序(WinForm)
引用MSDN,以便以后查看 引用:https://msdn.microsoft.com/zh-cn/library/86faxx0d.aspx 应用程序启动和关闭事件 Form 和 Control ...
- css y轴溢出滚动条,x轴溢出显示
这个是我工作中遇到的一个问题,困扰了我好几天,彻底理解了什么叫思路很重要. 黄色盒子里的内容是要超出出现滚动条的,红色的方块是根据另外的元素去定位的,于是呢 我就加上了 overflow-y:auto ...
- Web开发框架推导
本文欲回答这样一个问题:在 「特定环境 」下,如何规划Web开发框架,使其能满足 「期望 」? 假设我们的「特定环境 」如下: 技术层面 使用Java语言进行开发 通过Maven构建 基于Spring ...
- dwr3+spring实现消息实时推送
最近项目要实现一个消息推送的功能,主要就是发送站内信或者系统主动推送消息给当前在线的用户.每次的消息内容保存数据库,方便用户下次登录后也能看到.如果当前用户在线,收到站内信就主动弹出提示.一开始想到的 ...
- Hive分区和桶
SMB 存在的目的主要是为了解决大表与大表间的 Join 问题,分桶其实就是把大表化成了“小表”,然后 Map-Side Join 解决之,这是典型的分而治之的思想.在聊 SMB Join 之前,我们 ...
- H3C无线路由器安装与设置
一.电脑与路由器的连接利用一根cat5e网线一头连接到电脑上笔记本或台式机都可以,另一头连接到无线路由器的LAN口任意LAN口都可以二.设置无线路由器完成路由器安装与电脑连接后,接下首次使用就需要设置 ...