排序算法的C语言实现(上 比较类排序:插入排序、快速排序与归并排序)
总述:排序是指将元素集合按规定的顺序排列。通常有两种排序方法:升序排列和降序排列。例如,如整数集{6,8,9,5}进行升序排列,结果为{5,6,8,9},对其进行降序排列结果为{9,8,6,5}。虽然排序的显著目的是排列数据以显示它,但它往往可以用来解决其他的问题,特别是作为某些成型算法的一部分。
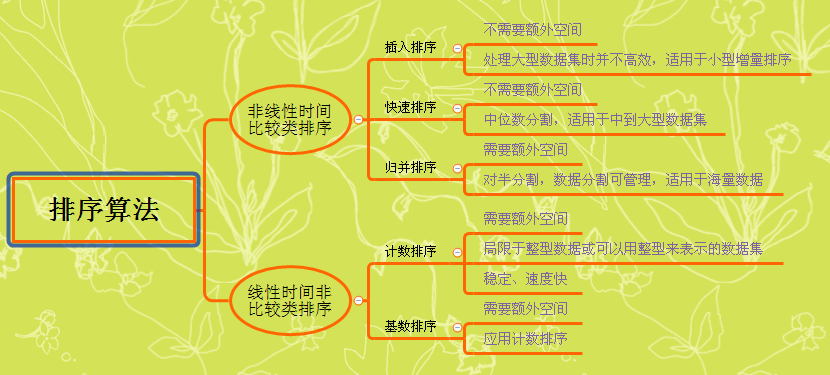
总的来说,排序算法分为两大类:比较排序 和 线性时间排序。
- 比较排序依赖于比较和交换来将元素移动到正确的位置上。它们的运行时间往往不可能小于O(nlgn)。
- 对于线性时间排序,它的运行时间往往与它处理的数据元素个数成正比,即为O(n)。线性排序的缺点是它需要依赖于数据集合中的某些特征,所以我们并不是在所有的场合都能够使用它。
某些算法只使用数据本身的存储空间来处理和输出数据(这些称为就地排序或内部排序),
而有一些则需要额外的空间来处理和输出数据(虽然可能最终结果还是会拷贝到原始内存空间中)(这些称之为外部排序)。
一、插入排序
插入排序是最简单的排序算法。正式表述为:插入排序每次从无序数据集中取出一个元素,扫描已排好序的数据集,并将它插入有序集合的合适位置上(像我们打扑克牌摸牌时的操作)。虽然乍一看插入排序需要独立为有序和无序的元素预留足够的存储空间,但实际上它是不需要额外的存储空间的。
插入排序是一种较为简单的算法,但它在处理大型数据集时并不高效。因为在决定将元素插入哪个位置之前,需要将被插入元素和有序数据集中的其他元素进行比较,这会随着的数据集的增大而增加额外的开销。插入排序的优点是当将元素插入一个有序数据集中时,只需对有序数据集最多进行一次遍历,而不需要完整的运行算法,这个特性使得插入排序在增量排序中非常高效。
接口定义
issort
int issort(void *data, int size, int esize, int (*compare)(const void *key1, const void *key2));
返回值:如果排序成功返回0,否则返回-1。
描述:利用插入排序将数组data中的元素进行排序。data中的元素个数由size决定。而每个元素的大小由esize决定。
函数指针compare会指向一个用户定义的函数来比较元素的大小。在递增排序中,如果key1>key2,函数返回1;如果key1=key2,函数返回0;如果key1<key2,函数返回-1。在背叛排序中,返回值相反。当issort返回时,data包含已排好序的元素。
复杂度:O(n2),n为要排序的元素的个数。
插入排序的实现与分析
从根本上讲,插入排序就是每次从未排序的数据集中取出一个元素,插入已经排好序的数据集中。在下面的实现中,两个数据集都存放在data中,data是一块连续的存储区域。
最初,data包含size个无序元素,随着issort的运行,data逐渐被有序数据集所取代,直到issort返回,此时data已经是一个有序数据集。虽然插入排序使用的是连续的存储空间,但它仍能用链表来实现,并且效率也不差。
插入排序使用一个嵌套循环,外部循环使用标号j来控制元素,使元素从无序数据集中插入有序数据集中。由于待插入的元素总是在有序数据集的右边,因此也可以认为j是data中分隔有序元素集和无序元素集的界线。对于每个处理位置j的元素,都会使用变量i来在有序数据集中向后查找元素将要放置的位置。当向后查找数据时,每个处于位置i的元素都要向右移动一位,以保证留出足够的空间来插入新元素。一旦j到达无序数据集的尾部,data就是一个有序数据集了。
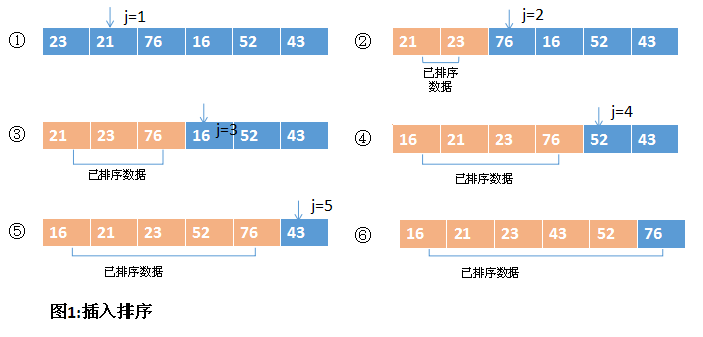
插入排序的时间复杂度关键在于它的嵌套循环部分。外部循环运行时间T(n)=n-1,乘以一段固定的时间,其中n为要排序元素的个数。考虑内部循环运行在最坏的情况,假设在插入元素之前必须从右到左遍历完所有的元素。这样的话,内部循环对于第一个元素迭代一次,对于第二个元素迭代两次,以此类推。直到外部循环终止。嵌套循环的运行时间表示为1到n-1数据的和,即运行时间T(n)=n(n+1)/2 - n,乘以一段固定时间(这是由1到n的求和公式推导出的)。为O表示法可以简化为O(n2)。当在递增排序中使用插入排序时,其时间复杂度为O(n)。插入排序不需要额外的空间,因此它只使用无序数据集本身的空间即可。
示例:插入排序的实现
/*issort.c*/
#include <stdlib.h>
#include <string.h> #include "sort.h" /*issort 插入排序*/
int issort(void *data, int size, int esize, int (*compare)(const void *key1, const void *key2))
{
char *a = data;
void *key;
int i,j; /*为key元素分配一块空间*/
if((key =(char *)malloc(esize)) == NULL)
return -; /*将元素循环插入到已排序的数据集中*/
for(j=; j < size; j++)
{
/*取无序数据集中的第j个元素,复制到key中*/
memcpy(key, &a[j*esize], esize);
/*设i为j紧邻的前一个元素*/
i = j - ; /*从i开始循环查找可以插入key的正确位置*/
/*key和第i个元素对比,如果小于第i个元素就复制i元素到i+1的位置;i递减循环对比*/
while(i >= && compare(&a[i*esize],key)>)
{
memcpy(&a[(i+)*esize],&a[i*esize],esize);
i--;
}
/*将key元素的值(也就是要插入的值)复制到while循环后i+1的位置,也就是要插入的位置*/
memcpy(&a[(i+)*esize],key,esize);
}
/*释放key的空间*/
free(key); return ;
}
二、快速排序
快速排序是一种分治算法。
广泛地认为它是解决一般问题的最佳算法。同插入排序一样,快速排序也属于比较排序的一种,而且不需要额外的存储空间。在处理中到大型数据集时,快速排序是一个比较好的选择。
我们来看一个人工对一堆作废的支票进行排序的例子,可以将未排序的支票分为两堆。其中一堆专门用来放小于或等于某个编号的支票,而另一堆用来放大于这个编号的支票(假设这个支票大概是所有支票编号的中间值)。当以这种方式得到两堆支票后,又可以以同样的方式将它们分为四堆,不断的重复这个过程直到每个堆中只放有一张支票。这时,所有的支票就已经排好序了。
由于快速排序属于分治算法的一种,我们用分治的思想将排序分为三个步骤:
1、分:设定一个分割值,将数据分为两部分;
2、治:分别在两个部分用递归的方式继续使用快速排序法;
3、合:对分割部分排序直至完成。
快速排序最坏情况下的性能不会比插入排序的最坏情况好。通过一点点修改可以大大改善快速排序最怀情况的效率,使其表现得与其平均情况相当。如何做到这一点,关键在于如何选择分割值。
所选的分割值需要尽可能的将元素平均分开。如果分割值会将大部分的元素放到其中一堆中,那么此时快速排序的性能会非常差。例如:如果用10作为数据值{15,20,18,51,36,10,77,43}的分割值,其结果为{10}和{15,20,18,51,36,77,43},明显不平衡。如果将分割值选为36,其结果为{36,51,77,43}和{15,20,18,10},就比较平衡。
选择分割值的一种有效的方法是通过 随机选择法 来选取。随机选择法能够有效的防止被分割的数据极度不平衡。同时,还可以改进这种随机选择法,方法是:首先随机选择三个元素,然后选择三个元素中的中间值。这就是所谓的中位数方法,可以保证平均情况下的性能。由于这种分割方法依赖随机数的统计特性,从而保证快速排序的整体性能,因此快速排序也是随机算法的一个好例子。
快速排序的接口定义
qksort
int qksort(void *data, int size, int esize, int i, int k, int (*compare)(const void *key1, const void *key2);
返回值:如果排序成功,返回0;否则返回-1。
描述: 利用快速排序将数组data中的元素进行排序。数组中的元素个数由size决定。而每个元素的大小由esize决定。参数i和k定义当前进行排序的两个部分,其值分别初始为0和size-1。函数指针compare会指向一个用户定义的函数来比较元素大小,其函数功能与issort中描述的一样。当qksort返回时,data包含已经排好序的元素。
复杂度: O(n lg n),n为要被排序的元素的个数。
快速排序的实现与分析
快速排序本质上就是不断地将无序元素集递归分割,直到所有的分区都只包含单个元素。
在以下的实现方法中,data包含size个无序元素,并存放在单块连续的存储空间中,快速排序不需要额外的存储空间,所以所有分割过程都在data中完成。当qksort返回时,data就是一个有序的数据集了。
快速排序的关键部分是如何分割数据。这部分工作由函数partition完成。函数分割data中处于i和k之间的元素(i小于k)。
首先,用前面提到的中位数法选取和个分割值。一旦选定分割值,就将k往data的左边移动,直到找到一个小于或等于分割值的元素。这个元素属于左边分区。接下来,将i往右边移动,直到找到一个大于或等于分割值的元素。这个元素属于右边分区。一旦找到的两个元素处于错误的位置,就交换它们的位置。重复这个过程,直到i和k重合。一旦i和k重合,那么所有处于左边的元素将小于等于它,所有处于右边的元素将大于等于它。
qksort中处理递归的过程:在初次调用qksort时,i设置为0,k设置为size-1。首先调用partition将data中处于i和k之间的元素分区。当partition返回时,把j赋于分割点的元素。接下来,递归调用qksort来处理左边的分区(从i到j)。左边的分区继续递归,直到传入qksort的一个分区只包含单个元素。此时i不会比k小,所以递归调用终止。同样,分区的右边也在进行递归处理,处理的区间是从j+1至k。总的来说,以这种递归的方式继续运行,直到首次达到qksort终止的条件,此时,数据就完全排好了。

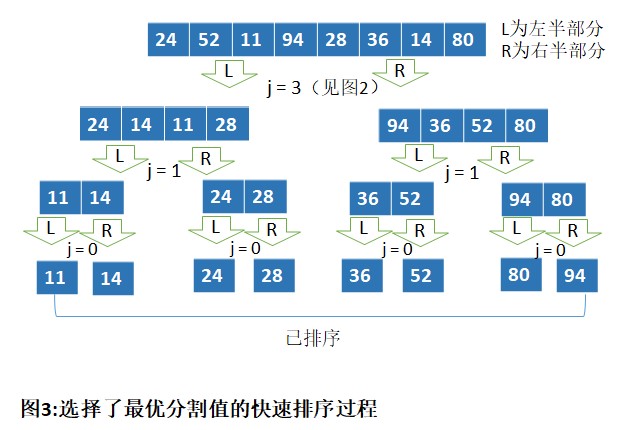
围绕其平均情况下的性能分析是快速排序的重点,因为一致认为平均情况是它复杂度的度量。虽然在最坏情况下,其运行时间O(n2)并不比插入排序好,但快速排序的性能一般能比较有保障地接近其平均性能O(nlgn),其中n为要排序的元素个数。
快速排序在平均情况下的时间复杂度取决于均匀分布的情况,即数据是否分割为平衡或不平衡的分区。如果使用中位数法,那么此平衡分区将有保障。在这种情况下,当不断分割数组,在图3中用树(高度为(lgn)+1)的方式直观地表示出来。由于顶部为lgn层的树,因此必须遍历所有n个元素,以形成新的分区,这样快速排序的运行时间为O(nlgn)。快速排序不需要额外的存储空间,因此它只使用无序数据本身的存储空间即可。
/*qksort.c*/
#include <stdlib.h>
#include <string.h> #include "sort.h" /*compare_int 比较函数*/
static int compare_int(const void *int1, const void *int2)
{
/*对比两个整数的大小(用于中位数分区)*/
if(*(const int *)int1 > *(const int *)int2)
return ;
else if(*(const int *)int1 < *(const int *)int2)
return -;
else
return ;
} /*partition 分割函数*/
static int partition(void *data, int esize, int i, int k, int (*compare)(const void *key1, const void *key2))
{
char *a=data;
void *pval,
*temp;
int r[]; /*为分割值和交换值变量分配空间*/
if((pval = malloc(esize)) == NULL)
return -; if((temp = malloc(esize)) == NULL)
{
/*如果为交换变量分配空间失败,则将分割变量的空间一起释放掉*/
free(pval);
return -;
} /*用中位数法找到分割值*/
r[] = (rand()%(k-i+))+i;
r[] = (rand()%(k-i+))+i;
r[] = (rand()%(k-i+))+i;
/*调用插入排序函数对三个随机数排序*/
issort(r,,sizeof(int),compare_int);
/*把排好序的三个数的中间值复制给分割值*/
memcpy(pval,&a[r[]*esize,esize); /*围绕分割值把数据分割成两个分区*/
/*准备变量范围,使i和k分割超出数组边界*/
i--;
k++; while()
{
/*k向左移动,直到找到一个小于或等于分割值的元素,这个元素处于错误的位置*/
do
{
k--;
}
while(compare(&a[k*esize],pval)>); /*i向右移动,直到找到一个大于或等于分割值的元素,这个元素处于错误的位置*/
do
{
i++;
}
while(compare(&a[i*esize],pval)<); /*直到i和k重合,跳出分区,否则交换处于错误位置的元素*/
if(i >= k)
{
break;
}
else
{
memcpy(temp, &a[i*esize], esize);
memcpy(&a[i*esize], &a[k*esize], esize);
memcpy(&a[k*esize], temp, esize);
}
} /*释放动态分配的空间*/
free(pval);
free(temp); /*返回两个分区中间的分割值*/
return k;
} /*qksort 快速排序函数*/
int qksort(void *data, int size, int esize, int i, int k, int(*compare)(const void *key1, const void *key2))
{
int j; /*递归地继续分区,直到不能进一步分区*/
while(i < k)
{
/*决定从何处开始分区*/
if((j = partition(data,esize,i,k,compare))<)
return -; /*递归排序左半部分*/
if(qksort(data,size,esize,i,j,compare) < )
return -; /*递归排序右半部分*/
i=j+;
}
return ;
}
快速排序的例子:目录列表
在一个层次结构的文件系统中,文件通常分目录进行组织。在任何一个目录中,我们会看到此目录包含的文件列表和子目录。例如,在UNIX系统中,可以通过命令ls来显示目录。在windows的命令行中,通过dir来显示目录。
本节展示一个函数directls,它能实现与ls同样的功能。它调用系统函数readdir来创建path路径中指定的目录列表。directls默认将文件按照名字排序,这一点与ls一样。由于在建立列表时调用了realloc来分配空间,因此一旦不再使用列表时,也需要用free来释放空间。
directls的时间复杂度为O(nlgn),其中n为目录中要列举的条目数。这是因为调用qksort来对条目进行排序是一个O(nlgn)级的操作,所以总的来说,遍历n个目录条目是一个O(n)级别的操作。
示例:获取目录列表的头文件
/*directls.h*/
#ifndef DIRECTLS_H
#define DIRECTLS_H #include <dirent.h> /*为目录列表创建一个数据结构*/
typedef struct Directory_
{
char name[MAXNAMLEN+];
}Directory; /*函数接口定义*/
int directls(const char *path,Directory **dir); #endif // DIRECTLS_H
示例:获取目录列表的实现
/*directls.c*/
#include <dirent.h> /*是POSIX.1标准定义的unix类目录操作的头文件,包含了许多UNIX系统服务的函数原型,例如opendir函数、readdir函数. */
#include <stdio.h>
#include <stdlib.h>
#include <string.h> #include "directls.h"
#include "sort.h" /*compare_dir 目录比较*/
static int compare_dir(const void *key1,const void key2)
{
int retval;
if((retval = strcmp(((const Directort *)key1)->name,((const Directory *)key2)->name))>)
return ;
else if (retval < )
return -;
else
return ;
} /*directls*/
int directls(const char *path,Directory **dir)
{
DIR *dirptr;
Directory *temp;
struct dirent *curdir;
int count,i; /*打开目录*/
if((dirptr = opendir(path)) == NULL )
return -;
/*获取目录列表*/
*dir = NULL;
count =; while((curdir = readdir(dirptr)) != NULL /*readdir()返回参数dir目录流的下个目录进入点*/ )
{
count ++;
if((temp = (Directory*)realloc(*dir,count*sizeof(Directory))) == NULL)
{
free(*dir);
return -;
}
else
{
*dir = temp;
} strcpy(((*dir)[count - ]).name, curdir->d_name);
}
closedir(dirptr); /*将目录列表按名称排序*/
if(qksort(*dir,count,sizeof(Directory),,count-,compare_dir) != )
return -; /*返回目录列表的数目*/
return count;
}
三、归并排序
归并排序也是一种运用分治法排序的算法。与快速排序一样,它依赖于元素之间的比较来排序。但是归并排序需要额外的存储空间来完成排序过程。
我们还是以支票排序的例子说明。首先,将一堆未排序的支票对半分为两堆。接着,分别又将两堆支票对半分为两堆,以此类推,重复此过程,直到每一堆支票只包含一张支票。然后,开始将堆两两合并,这样每个合并出来的堆就是两个有序的合集,也是有序的。这个合并过程一直持续下去,直到一堆新的支票生成。此时这堆支票就是有序的。
由于归并排序也是一种分治算法,因此可以使用分治的思想把排序分为三个步骤:
1、分:将数据集等分为两半;
2、治:分别在两个部分用递归的方式继续使用归并排序法;
3、合:将分开的两个部分合并成一个有序的数据集。
归并排序与其他排序最大的不同在于它的归并过程。这个过程就是将两个有序的数据集合并成一个有序的数据集。合并两个有序数据的过程是高效的,因为我们只需要遍历一次即可。根据以上事实,再加上该算法是按照可预期的方式来划分数据的,这使得归并排序在所有的情况下都能达到快速排序的平均性能。
归并排序的缺点是它需要额外的存储空间来运行。因为合并过程不能在无序数据集本身中进行,所以必须要有两倍于无序数据集的空间来运行算法。这点不足极大的降低了归并排序在实际中的使用频率,因为通常可以使用不需要额外存储空间的快速排序来代替它。
然而,归并排序对于处理海量数据处理还是非常有价值的,因为它能够按预期将数据集分开。这使得我们能够将数据集分割为更加可管理的数据,接着用归并排序法处理数据,然后不断的合并数据,在这个过程中并不需要一次存储所有的数据。
归并排序的接口定义
mgsort
int mgsort(void *data, int size, int esize, int i, int k, int (*compare)(const void *key1,const void key2));
返回值:如果排序成功,返回0;否则,返回-1。
描述: 利用归并排序将数组data中的元素进行排序。数据中的元素个数由size决定。每个元素的大小由esize决定。i和k定义当前排序的两个部分,其值分别初始化为0和size-1。函数指针compare指向一个用户定义的函数来比较元素的大小。其函数功能同issort中描述的一样。当mgsort返回时,data中包含已经排好序的元素。
复杂度:O(n lg n),n为要排序的元素个数。
归并排序的实现与分析
归并排序本质上是将一个无序数据集分割成许多个只包含一个元素的集,然后不断地将这些小集合并,直到一个新的大有序集生成。在以下介绍的实现方法中,data最初包含size个无序元素,并放在单块连续的存储空间中。因为归并过程需要额外的存储空间,所以函数要为合并过程分配足够的内存。在函数返回后,最终通过合并得到的有序数据集将会拷贝回data。
归并排序最关键的部分是如何将两个有序集合并成一个有序集。这部分工作交由函数merge完成。它将data中i到j之间的数据集与j+1到k之间的数据集合并成一个i到k的有序数据集。
最初,ipos和jpos指向每个有序集的头部。只要数据集中还有元素存在,合并过程就将持续下去。如果数据集中没有元素,进行如下操作:如果一个集合没有要合并的元素,那么将另外一个集合中要合并的元素全部放到合并集合中。否则,首先比较两个集合中的首元素,判断哪个元素要放到合并集合中,然后将它放进去,接着根据元素来自的集合移动ipos或jpos的位置(如图4),依此类推。

现在我们来看看mgsort中如何来处理递归。在初次调用mgsort时,i设置为0,k设置为size-1。首先,分割data,此时j处于数据中间元素的位置。然后,调用mgsort来处理左边分区(从i到j)。左边的分区继续递归分割,直到传入mgsort的一个分区只包含单个元素。在此过程中,i不再小于k,因此调用过程终止。在前一个mgsort的过程中,在分区的右边也在调用mgsort,处理的分区从j+1到k。一旦调用过程终止,就开始归并两个数据集。总的来说,以这种递归方式继续,直到最后一次归并过程完成,此时数据就完全排好序了。
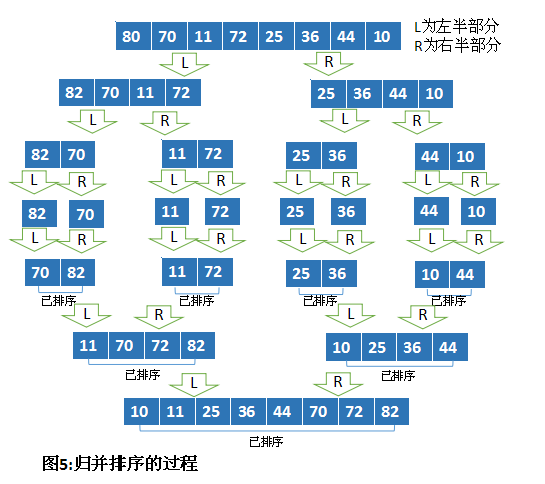
将数据集不断地对半分割,在分到每个集合只有一个元素前,需要lgn级分割(n为要排序的元素个数)。对于两个分别包含q和p个元素的有序集来说,归并耗费的时长为O(p+q),因为产生了一个合并的集,必须遍历两个集的每个元素。由于对应每个lgn级的分割,都需要遍历n个元素合并该集,因此归并排序的时间复杂度为O(nlgn)。又因为归并排序需要额外的存储空间,所以必须要有两倍于要排序数据的空间来处理此算法。
示例:归并排序的实现
/*mgsort.c*/
#include <stdlib.h>
#include <string.h>
#include "sort.h" /*merge 合并两个有序数据集*/
static int merge(void *data, int esize, int i, int j, int k, int (*compare)(const void *key1,const void *key2))
{
char *a = data,
*m;
int ipos ,jpos,mpos; /*初始化用于合并过程中的计数器*/
ipos = i;
jpos = j+;
mpos = ; /*首先,为要合并的元素集分配空间*/
if((m = (char *)malloc(esize * ((k-i)+))) == NULL)
return -; /*接着,只要任一有序集有元素需要合并,就执行合并操作*/
while(ipos <= j || jpos <=k)
{
if(ipos > j)
{
/*左集中没有元素要合并,就将右集中的元素放入目标集(合并集)*/
while(jpos <= k)
{
memcpy(&m[mpos * esize],&a[jpos * esize],esize);
jpos++;
mpos++;
}
continue;
}
else if(jpos > k)
{
/*右集没有要合并的元素,就将左集中的元素放入目标集(合并集)*/
while(ipos <= j)
{
memcpy(&m[mpos * esize],&a[ipos *esize],esize);
ipos++;
mpos++;
}
continue;
} /*追加下一个有序元素到合并集中*/
if(compare(&a[ipos * esize],*a[jpos *esize])<)
{
memcpy(&m[mpos * esize],&a[ipos * esize],esize);
ipos++;
mpos++;
}
else
{
memccpy(&m[mpos * esize],&a[jpos * esize],esize);
jpos++;
mpos++;
}
}
/*将已经排序的数据集拷贝到原数组中*/
memcpy(&a[i * esize],m,esize * ((k-i)+1)); /*释放为排序分配的存储空间*/
free(m);
return 0;
} /*mgsort 归并排序(递归调用)*/
int mgsort(void *data, int size, int esize, int i, int k, int(*compare)(const void *key1,const void *key2))
{
int j; /*递归调用mgsort持续分割,直到没有可以再分割的数据集*/
if(i < k)
{
/*计算对半分割的位置下标*/
j = (int)(((i+k-1)) / 2); /*递归排序两边的集合*/
if(mgsort(data, size, esize, i, j, compare) < 0)
return -1;
if(mgsort(data, size, esize, j+1, k, compare) <0)
return -1; /*将两个有序数据集合并成一个有序数据集*/
if(meger(data, esize, i, j, k compare) < 0)
return -1;
}
return 0;
}
排序算法的C语言实现(上 比较类排序:插入排序、快速排序与归并排序)的更多相关文章
- 排序算法的C语言实现(下 线性时间排序:计数排序与基数排序)
计数排序 计数排序是一种高效的线性排序. 它通过计算一个集合中元素出现的次数来确定集合如何排序.不同于插入排序.快速排序等基于元素比较的排序,计数排序是不需要进行元素比较的,而且它的运行效率要比效率为 ...
- [answerer的算法课堂]简单描述4种排序算法(C语言实现)
[answerer的算法课堂]简单描述4种排序算法(C语言实现) 这是我第一次写文章,想要记录自己的学习生活,写得不好请包涵or指导,本来想一口气写好多种,后来发现,写太多的话反而可读性不强,而且,我 ...
- 几种经典排序算法的R语言描述
1.数据准备 # 测试数组 vector = c(,,,,,,,,,,,,,,) vector ## [] 2.R语言内置排序函数 在R中和排序相关的函数主要有三个:sort(),rank(),ord ...
- 【最全】经典排序算法(C语言)
算法复杂度比较: 算法分类 一.直接插入排序 一个插入排序是另一种简单排序,它的思路是:每次从未排好的序列中选出第一个元素插入到已排好的序列中. 它的算法步骤可以大致归纳如下: 从未排好的序列中拿出首 ...
- 【转载】常见十大经典排序算法及C语言实现【附动图图解】
原文链接:https://www.cnblogs.com/onepixel/p/7674659.html 注意: 原文中的算法实现都是基于JS,本文全部修改为C实现,并且统一排序接口,另外增加了一些描 ...
- 排序算法总结(C语言版)
排序算法总结(C语言版) 1. 插入排序 1.1 直接插入排序 1.2 Shell排序 2. 交换排序 2.1 冒泡排序 2.2 快速排序 3. 选择 ...
- Java常用排序算法+程序员必须掌握的8大排序算法+二分法查找法
Java 常用排序算法/程序员必须掌握的 8大排序算法 本文由网络资料整理转载而来,如有问题,欢迎指正! 分类: 1)插入排序(直接插入排序.希尔排序) 2)交换排序(冒泡排序.快速排序) 3)选择排 ...
- 必须知道的八大种排序算法【java实现】(一) 冒泡排序、快速排序
冒泡排序 冒泡排序是一种简单的排序算法.它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成.这个 ...
- Java常用排序算法+程序员必须掌握的8大排序算法
概述 排序有内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存. 我们这里说说八大排序就是内部排序. 当n较大, ...
随机推荐
- Extensions in UWP Community Toolkit - SurfaceDialTextbox
概述 UWP Community Toolkit Extensions 中有一个为TextBox 提供的 SurfaceDial 扩展 - SurfaceDialTextbox,本篇我们结合代码详细讲 ...
- WKWebView使用
WKWebView比之之前使用的UIWebView更加具有优势,UIWebView更加的笨重,UIWebView占用更多的内存,且内存的峰值更加的夸张,WKWebView加载的速度也更快,而且其更多的 ...
- 基于session认证 相亲小作业
基于session认证 相亲小作业 用户登录 如果男用户登录,显示女生列表 如果女用户登录,显示男生列表 urls ===========================urls========== ...
- html超文本标记语言的由来
万维网上的一个超媒体文档称为一个页面:page,作为一个组织或者个人在万维网上放置开始点的页面称为主页:homepage或者首页,主页中通常有指向其他相关页面或者其他节点的指针,就是通常所说的超链接, ...
- Spring源码分析:Spring IOC容器初始化
概述: Spring 对于Java 开发来说,以及算得上非常基础并且核心的框架了,在有一定开发经验后,阅读源码能更好的提高我们的编码能力并且让我们对其更加理解.俗话说知己知彼,百战不殆.当你对Spri ...
- 盒子浮动float
一.float的基本规律 规律1: 标准流模型中的块级盒子,默认宽度100%: 而浮动的块级盒子,宽度不会自动伸展,而是由内容(文字.padding)撑开: 浮动后的行级元素,可以设置宽度高度等属性. ...
- WebGL文字渲染的那些问题
THREE.js开发的应用运行在iphone5下发现有些时候会崩溃,跟了几天发现是因为Sprite太多频繁更新纹理占用显存导致的.通常解决纹理频繁更新问题就要用到one draw all方法,放到纹理 ...
- 从零开始系列之vue全家桶(6)实战前的设计
搭建好基本框架后我们应该先想一想个人博客应该有哪些功能呢? 为了更好的适应企业的要求,这里我将搭建一个非典型的博客. 在全部采用单页开发的情况下,使用vue-router,路由分别设置home.abo ...
- 原生js代码挑战之动态添加双色球
var ballArr = []; //存放已有的红球,用来排除重复和排序window.onload = function(){ var btn = document.createElement(&q ...
- SpringMVC 自定义类型转换器
先准备一个JavaBean(Employee) 一个Handler(SpringMVCTest) 一个converters(EmployeeConverter) 要实现的输入一个字符串转换成一个emp ...