强化学习(七)时序差分离线控制算法Q-Learning
在强化学习(六)时序差分在线控制算法SARSA中我们讨论了时序差分的在线控制算法SARSA,而另一类时序差分的离线控制算法还没有讨论,因此本文我们关注于时序差分离线控制算法,主要是经典的Q-Learning算法。
Q-Learning这一篇对应Sutton书的第六章部分和UCL强化学习课程的第五讲部分。
1. Q-Learning算法的引入
Q-Learning算法是一种使用时序差分求解强化学习控制问题的方法,回顾下此时我们的控制问题可以表示为:给定强化学习的5个要素:状态集$S$, 动作集$A$, 即时奖励$R$,衰减因子$\gamma$, 探索率$\epsilon$, 求解最优的动作价值函数$q_{*}$和最优策略$\pi_{*}$。
这一类强化学习的问题求解不需要环境的状态转化模型,是不基于模型的强化学习问题求解方法。对于它的控制问题求解,和蒙特卡罗法类似,都是价值迭代,即通过价值函数的更新,来更新策略,通过策略来产生新的状态和即时奖励,进而更新价值函数。一直进行下去,直到价值函数和策略都收敛。
再回顾下时序差分法的控制问题,可以分为两类,一类是在线控制,即一直使用一个策略来更新价值函数和选择新的动作,比如我们上一篇讲到的SARSA, 而另一类是离线控制,会使用两个控制策略,一个策略用于选择新的动作,另一个策略用于更新价值函数。这一类的经典算法就是Q-Learning。
对于Q-Learning,我们会使用$\epsilon-$贪婪法来选择新的动作,这部分和SARSA完全相同。但是对于价值函数的更新,Q-Learning使用的是贪婪法,而不是SARSA的$\epsilon-$贪婪法。这一点就是SARSA和Q-Learning本质的区别。
2. Q-Learning算法概述
Q-Learning算法的拓补图入下图所示:
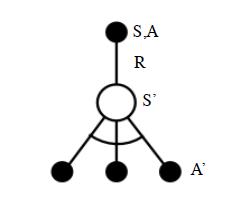
首先我们基于状态$S$,用$\epsilon-$贪婪法选择到动作$A$, 然后执行动作$A$,得到奖励$R$,并进入状态$S'$,此时,如果是SARSA,会继续基于状态$S'$,用$\epsilon-$贪婪法选择$A'$,然后来更新价值函数。但是Q-Learning则不同。
对于Q-Learning,它基于状态$S'$,没有使用$\epsilon-$贪婪法选择$A'$,而是使用贪婪法选择$A'$,也就是说,选择使$Q(S',a)$最大的$a$作为$A'$来更新价值函数。用数学公式表示就是:$$Q(S,A) = Q(S,A) + \alpha(R+\gamma \max_aQ(S',a) - Q(S,A))$$
对应到上图中就是在图下方的三个黑圆圈动作中选择一个使$Q(S',a)$最大的动作作为$A'$。
此时选择的动作只会参与价值函数的更新,不会真正的执行。价值函数更新后,新的执行动作需要基于状态$S'$,用$\epsilon-$贪婪法重新选择得到。这一点也和SARSA稍有不同。对于SARSA,价值函数更新使用的$A'$会作为下一阶段开始时候的执行动作。
下面我们对Q-Learning算法做一个总结。
3. Q-Learning算法流程
下面我们总结下Q-Learning算法的流程。
算法输入:迭代轮数$T$,状态集$S$, 动作集$A$, 步长$\alpha$,衰减因子$\gamma$, 探索率$\epsilon$,
输出:所有的状态和动作对应的价值$Q$
1. 随机初始化所有的状态和动作对应的价值$Q$. 对于终止状态其$Q$值初始化为0.
2. for i from 1 to T,进行迭代。
a) 初始化S为当前状态序列的第一个状态。
b) 用$\epsilon-$贪婪法在当前状态$S$选择出动作$A$
c) 在状态$S$执行当前动作$A$,得到新状态$S'$和奖励$R$
d) 更新价值函数$Q(S,A)$:$$Q(S,A) + \alpha(R+\gamma \max_aQ(S',a) - Q(S,A))$$
e) $S=S'$
f) 如果$S'$是终止状态,当前轮迭代完毕,否则转到步骤b)
4. Q-Learning算法实例:Windy GridWorld
我们还是使用和SARSA一样的例子来研究Q-Learning。如果对windy gridworld的问题还不熟悉,可以复习强化学习(六)时序差分在线控制算法SARSA第4节的第二段。
完整的代码参见我的github: https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/q_learning_windy_world.py
绝大部分代码和SARSA是类似的。这里我们可以重点比较和SARSA不同的部分。区别都在episode这个函数里面。
首先是初始化的时候,我们只初始化状态$S$,把$A$的产生放到了while循环里面, 而回忆下SARSA会同时初始化状态$S$和动作$A$,再去执行循环。下面这段Q-Learning的代码对应我们算法的第二步步骤a和b:
# play for an episode
def episode(q_value):
# track the total time steps in this episode
time = 0 # initialize state
state = START while state != GOAL:
# choose an action based on epsilon-greedy algorithm
if np.random.binomial(1, EPSILON) == 1:
action = np.random.choice(ACTIONS)
else:
values_ = q_value[state[0], state[1], :]
action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)])
接着我们会去执行动作$A$,得到$S'$, 由于奖励不是终止就是-1,不需要单独计算。,这部分和SARSA的代码相同。对应我们Q-Learning算法的第二步步骤c:
next_state = step(state, action)
def step(state, action):
i, j = state
if action == ACTION_UP:
return [max(i - 1 - WIND[j], 0), j]
elif action == ACTION_DOWN:
return [max(min(i + 1 - WIND[j], WORLD_HEIGHT - 1), 0), j]
elif action == ACTION_LEFT:
return [max(i - WIND[j], 0), max(j - 1, 0)]
elif action == ACTION_RIGHT:
return [max(i - WIND[j], 0), min(j + 1, WORLD_WIDTH - 1)]
else:
assert False
后面我们用贪婪法选择出最大的$Q(S',a)$,并更新价值函数,最后更新当前状态$S$。对应我们Q-Learning算法的第二步步骤d,e。注意SARSA这里是使用$\epsilon-$贪婪法,而不是贪婪法。同时SARSA会同时更新状态$S$和动作$A$,而Q-Learning只会更新当前状态$S$。
values_ = q_value[next_state[0], next_state[1], :]
next_action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)]) # Sarsa update
q_value[state[0], state[1], action] += \
ALPHA * (REWARD + q_value[next_state[0], next_state[1], next_action] -
q_value[state[0], state[1], action])
state = next_state
跑完完整的代码,大家可以很容易得到这个问题的最优解,进而得到在每个格子里的最优贪婪策略。
5. SARSA vs Q-Learning
现在SARSA和Q-Learning算法我们都讲完了,那么作为时序差分控制算法的两种经典方法吗,他们都有说明特点,各自适用于什么样的场景呢?
Q-Learning直接学习的是最优策略,而SARSA在学习最优策略的同时还在做探索。这导致我们在学习最优策略的时候,如果用SARSA,为了保证收敛,需要制定一个策略,使$\epsilon-$贪婪法的超参数$\epsilon$在迭代的过程中逐渐变小。Q-Learning没有这个烦恼。
另外一个就是Q-Learning直接学习最优策略,但是最优策略会依赖于训练中产生的一系列数据,所以受样本数据的影响较大,因此受到训练数据方差的影响很大,甚至会影响Q函数的收敛。Q-Learning的深度强化学习版Deep Q-Learning也有这个问题。
在学习过程中,SARSA在收敛的过程中鼓励探索,这样学习过程会比较平滑,不至于过于激进,导致出现像Q-Learning可能遇到一些特殊的最优“陷阱”。比如经典的强化学习问题"Cliff Walk"。
在实际应用中,如果我们是在模拟环境中训练强化学习模型,推荐使用Q-Learning,如果是在线生产环境中训练模型,则推荐使用SARSA。
6. Q-Learning结语
对于Q-Learning和SARSA这样的时序差分算法,对于小型的强化学习问题是非常灵活有效的,但是在大数据时代,异常复杂的状态和可选动作,使Q-Learning和SARSA要维护的Q表异常的大,甚至远远超出内存,这限制了时序差分算法的应用场景。在深度学习兴起后,基于深度学习的强化学习开始占主导地位,因此从下一篇开始我们开始讨论深度强化学习的建模思路。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
强化学习(七)时序差分离线控制算法Q-Learning的更多相关文章
- 【转载】 强化学习(七)时序差分离线控制算法Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9669263.html ------------------------------------------------ ...
- 强化学习(六)时序差分在线控制算法SARSA
在强化学习(五)用时序差分法(TD)求解中,我们讨论了用时序差分来求解强化学习预测问题的方法,但是对控制算法的求解过程没有深入,本文我们就对时序差分的在线控制算法SARSA做详细的讨论. SARSA这 ...
- 【转载】 强化学习(六)时序差分在线控制算法SARSA
原文地址: https://www.cnblogs.com/pinard/p/9614290.html ------------------------------------------------ ...
- 强化学习8-时序差分控制离线算法Q-Learning
Q-Learning和Sarsa一样是基于时序差分的控制算法,那两者有什么区别呢? 这里已经必须引入新的概念 时序差分控制算法的分类:在线和离线 在线控制算法:一直使用一个策略选择动作和更新价值函数, ...
- 强化学习4-时序差分TD
之前讲到强化学习在不基于模型时可以用蒙特卡罗方法求解,但是蒙特卡罗方法需要在每次采样时生产完整序列,而在现实中,我们很可能无法生成完整序列,那么又该如何解决这类强化学习问题呢? 由贝尔曼方程 vπ(s ...
- 强化学习七 - Policy Gradient Methods
一.前言 之前我们讨论的所有问题都是先学习action value,再根据action value 来选择action(无论是根据greedy policy选择使得action value 最大的ac ...
- 强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning)
强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning) 学习笔记: Reinforcement Learning: An Introductio ...
- 强化学习之 免模型学习(model-free based learning)
强化学习之 免模型学习(model-free based learning) ------ 蒙特卡罗强化学习 与 时序查分学习 ------ 部分节选自周志华老师的教材<机器学习> 由于现 ...
- Flink + 强化学习 搭建实时推荐系统
如今的推荐系统,对于实时性的要求越来越高,实时推荐的流程大致可以概括为这样: 推荐系统对于用户的请求产生推荐,用户对推荐结果作出反馈 (购买/点击/离开等等),推荐系统再根据用户反馈作出新的推荐.这个 ...
随机推荐
- 【缩点+拓扑判链】POJ2762 Going from u to v or from v to u?
Description In order to make their sons brave, Jiajia and Wind take them to a big cave. The cave has ...
- BZOJ_2795_[Poi2012]A Horrible Poem_hash+暴力
Description 给出一个由小写英文字母组成的字符串S,再给出q个询问,要求回答S某个子串的最短循环节. 如果字符串B是字符串A的循环节,那么A可以由B重复若干次得到. Input 第一行一个正 ...
- BZOJ_3573_[Hnoi2014]米特运输_树形DP+hash
BZOJ_3573_[Hnoi2014]米特运输_树形DP+hash 题意: 给你一棵树每个点有一个权值,要求修改最少的权值,使得每个节点的权值等于其儿子的权值和且儿子的权值都相等. 分析: 首先我们 ...
- BZOJ_1503_[NOI2004]郁闷的出纳员_权值线段树
BZOJ_1503_[NOI2004]郁闷的出纳员_权值线段树 Description OIER公司是一家大型专业化软件公司,有着数以万计的员工.作为一名出纳员,我的任务之一便是统计每位员工的 工资. ...
- BZOJ_2157_旅游_树剖+线段树
BZOJ_2157_旅游_树剖+线段树 Description Ray 乐忠于旅游,这次他来到了T 城.T 城是一个水上城市,一共有 N 个景点,有些景点之间会用一座桥连接.为了方便游客到达每个景点但 ...
- 斜率优化入门学习+总结 Apio2011特别行动队&Apio2014序列分割&HZOI2008玩具装箱&ZJOI2007仓库建设&小P的牧场&防御准备&Sdoi2016征途
斜率优化: 额...这是篇7个题的题解... 首先说说斜率优化是个啥,额... f[i]=min(f[j]+xxxx(i,j)) ; 1<=j<i (O(n^2)暴力)这样一个式子,首 ...
- Solr的中英文分词实现
对于Solr应该不需要过多介绍了,强大的功能也是都体验过了,但是solr一个较大的问题就是分词问题,特别是中英文的混合分词,处理起来非常棘手. 虽然solr自带了支持中文分词的cjk,但是其效果实在不 ...
- 【爆料】-《维多利亚大学毕业证书》Victoria一模一样原件
☞维多利亚大学毕业证书[微/Q:865121257◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士&海归& ...
- html中 submit和button的区别?
前者是向数据库提交表单 后者是单纯的按钮功能
- 性能测试入门 — LoadRunner 使用初探
前言: 性能测试是利用产品.人员和流程来降低应用程序.升级程序或补丁程序部署风险的一种手段.性能测试的主要思想是通过模拟产生真实业务的压力对被测系统进行加压,验证被测系统在不同压力情况下的表现,找出其 ...