时间序列算法(平稳时间序列模型,AR(p),MA(q),ARMA(p,q)模型和非平稳时间序列模型,ARIMA(p,d,q)模型)的模型以及需要的概念基础学习笔记梳理
在做很多与时间序列有关的预测时,比如股票预测,餐厅菜品销量预测时常常会用到时间序列算法,之前在学习这方面的知识时发现这方面的知识讲解不多,所以自己对时间序列算法中的常用概念和模型进行梳理总结(但是为了内容的正确性有些内容我通过截图来记录吧),希望能有所帮助^.^

一、时间序列的预处理
在拿到基于时间的观测值序列后,需要首先进行两步预处理,一个是纯随机性检验,另一个是平稳性检验,然后根据这两步的检验结果再采取相应的时间序列模型进行分析。



简单来讲平稳序列就是指均值和方差不发生明显变化
注:时序图检验和自相关检验实际是通过绘制相应的图进行观察,在下面的内容会结合具体的图进行分析

二、平稳时间序列模型
在学习具体模型之前,我们需要了解两种相关系数
1.自相关系数

2.偏相关系数

不要小看这两个系数,它们对于模型的选择起着至关重要的作用,如果现在对这两个系数还不是很理解,请继续往下看吧~。~
(一)、自回归模型AR(p)


(二)、移动平均模型MA(q)

(三)、自回归移动平均模型ARMA(p,q)

三、非平稳时间序列模型
在实际环境中大多数序列都是非平稳的,这里主要学习ARIMA模型

从它的名字我们就可以看到在使用它时需要首先对数据进行差分运算将非平稳时间序列变为平稳时间序列,然后再运用ARIMA模型。
四、确定参数p,q的取值
现在还剩最后一个问题要解决了,我们已经知道时间序列都有哪些模型了,那么我们怎么确定使用哪个模型呢,确定了使用哪个模型后,就要特别注意我用绿色圈圈画出的p,q,怎么确定相应模型的参数取值呢?
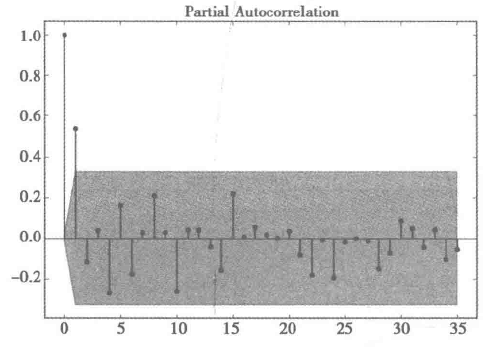
让我们看一下下面的这张图吧,它就是上面两个问题的key,现在直接看肯定是看不明白的,让我们先看列ACF,PACF,它们其实就是自相关系数和偏自相关系数(在上面已经提到了)的图,先知道一下什么是截尾的概念,截尾就是指ACF图,PACF图何时落入置信区间(这个是我自己理解的,大家可以自行查阅)
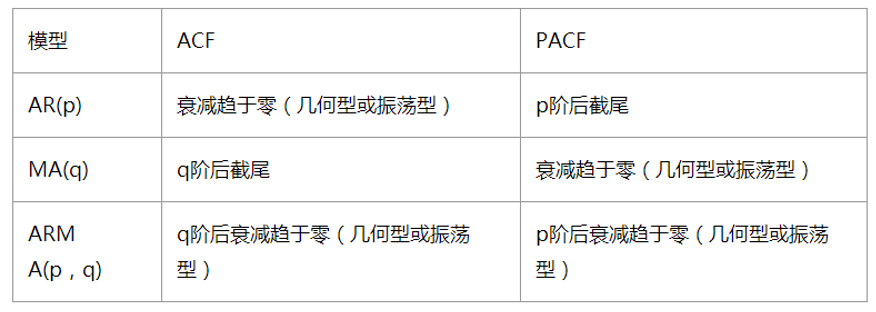
确定参数p,q的取值主要有两种方法:
1.肉眼观察ACF图和PACF图法
现在我们结合上面的原则观察下面的自相关图和偏自相关图,发现自相关图1阶截尾,偏自相关图具有拖尾性,所以可以确定为MA模型,并且取q为1,但是有时观察图并不是很准确,我们就可以使用下面的方法啦
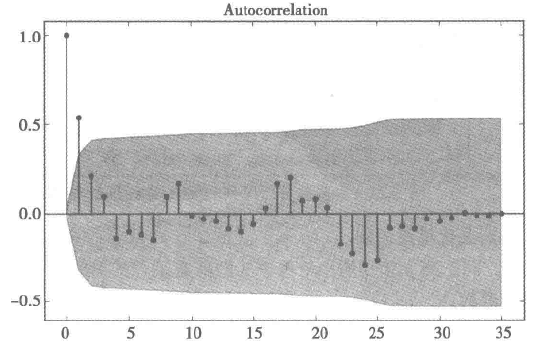
2.计算AIC,BIC,原则是使AIC和BIC越小越好(大家可以自己查阅具体详细的知识^.^)

终于写完这篇梳理笔记了,开心。
时间序列算法(平稳时间序列模型,AR(p),MA(q),ARMA(p,q)模型和非平稳时间序列模型,ARIMA(p,d,q)模型)的模型以及需要的概念基础学习笔记梳理的更多相关文章
- 第二章平稳时间序列模型——AR(p),MA(q),ARMA(p,q)模型及其平稳性
1白噪声过程: 零均值,同方差,无自相关(协方差为0) 以后我们遇到的efshow如果不特殊说明,就是白噪声过程. 对于正态分布而言,不相关即可推出独立,所以如果该白噪声如果服从正态分布,则其还将 ...
- 概率图模型学习笔记:HMM、MEMM、CRF
作者:Scofield链接:https://www.zhihu.com/question/35866596/answer/236886066来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
- OpenCV 学习笔记 04 深度估计与分割——GrabCut算法与分水岭算法
1 使用普通摄像头进行深度估计 1.1 深度估计原理 这里会用到几何学中的极几何(Epipolar Geometry),它属于立体视觉(stereo vision)几何学,立体视觉是计算机视觉的一个分 ...
- ARIMA模型——本质上是error和t-?时刻数据差分的线性模型!!!如果数据序列是非平稳的,并存在一定的增长或下降趋势,则需要对数据进行差分处理!ARIMA(p,d,q)称为差分自回归移动平均模型,AR是自回归, p为自回归项; MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数
https://www.cnblogs.com/bradleon/p/6827109.html 文章里写得非常好,需详细看.尤其是arima的举例! 可以看到:ARIMA本质上是error和t-?时刻 ...
- 时序分析:ARIMA模型(非平稳时间序列)
转载于一篇硕士论文.... ARIMA模型意为求和自回归滑动平均模型(IntergratedAut少regressive MovingAverageModel),简记为ARIMA(p,d,q),p,q ...
- HMM模型学习笔记(前向算法实例)
HMM算法想必大家已经听说了好多次了,完全看公式一头雾水.但是HMM的基本理论其实很简单.因为HMM是马尔科夫链中的一种,只是它的状态不能直接被观察到,但是可以通过观察向量间接的反映出来,即每一个观察 ...
- 深度学习在美团点评推荐平台排序中的应用&& wide&&deep推荐系统模型--学习笔记
写在前面:据说下周就要xxxxxxxx, 吓得本宝宝赶紧找些广告的东西看看 gbdt+lr的模型之前是知道怎么搞的,dnn+lr的模型也是知道的,但是都没有试验过 深度学习在美团点评推荐平台排序中的运 ...
- cips2016+学习笔记︱简述常见的语言表示模型(词嵌入、句表示、篇章表示)
在cips2016出来之前,笔者也总结过种类繁多,类似词向量的内容,自然语言处理︱简述四大类文本分析中的"词向量"(文本词特征提取)事实证明,笔者当时所写的基本跟CIPS2016一 ...
- 使用RStudio调试(debug)基础学习(二)和fGarch包中的garchFit函数估计GARCH模型的原理和源码
一.garchFit函数的参数--------------------------------------------- algorithm a string parameter that deter ...
随机推荐
- qtchooser
qtchooser 的配置目录: /usr/lib/x86_64-linux-gnu/qtchooser qtchooser 的真实配置目录: /usr/share/qtchooser qtchoos ...
- 咸鱼Chen
关于我 网名:咸鱼Chen 英文:nick chen 签名:I'm nothing but I must be everything. 标签:Python爱好(ma)者(nong),干过后端开发.算法 ...
- Scala脚本化-Ammonite
Scala语言定义: Scala combines object-oriented and functional programming in one concise, high-level lang ...
- 使用Scala IDE for Eclipse遇到build errors错误的解决办法
在编写第一个Scala语言的Spark程序时,在Scala IDE for Eclipse中运行程序时出现“Project XXXX contains build errors, Continue l ...
- 文本离散表示(一):词袋模型(bag of words)
一.文本表示 文本表示的意思是把字词处理成向量或矩阵,以便计算机能进行处理.文本表示是自然语言处理的开始环节. 文本表示按照细粒度划分,一般可分为字级别.词语级别和句子级别的文本表示.字级别(char ...
- 【机器学习基础】熵、KL散度、交叉熵
熵(entropy).KL 散度(Kullback-Leibler (KL) divergence)和交叉熵(cross-entropy)在机器学习的很多地方会用到.比如在决策树模型使用信息增益来选择 ...
- python接口自动化(十五)--参数关联接口(详解)
简介 我们用自动化新建任务之后,要想接着对这个新建任务操作,那就需要用参数关联了,新建任务之后会有一个任务的Jenkins-Crumb,获取到这个Jenkins-Crumb,就可以通过传这个任务Jen ...
- asp.net core系列 52 Identity 其它关注点
一.登录分析 在使用identity身份验证登录时,在login中调用的方法是: var result = await _signInManager.PasswordSignInAsync(Input ...
- Redux的中间件原理分析
redux的中间件对于使用过redux的各位都不会感到陌生,通过应用上我们需要的所有要应用在redux流程上的中间件,我们可以加强dispatch的功能.最近也有一些初学者同时和实习生在询问中间件有关 ...
- 如何在ASP.NET Core中自定义Azure Storage File Provider
文章标题:如何在ASP.NET Core中自定义Azure Storage File Provider 作者:Lamond Lu 地址:https://www.cnblogs.com/lwqlun/p ...