章节十、3-CSS Selector---用CSS Selector - ID定位元素
一、如果元素的 ID 不唯一,或者是动态的,或者 name 以及 linktext 属性值也不唯一,对于这样的元素,我们 就需要考虑用 xpath或者css selector 来查找元素了,然后再对元素执行操作。
二、不管用什么方式查找元素,id、Name、Xpath、css—>都需要在页面上查找到唯一的元素。 都应该只找到一个匹配的 node(节点),除非想要查找一批元素放集合里,然后来操作集合。
三、css语法
标签名[属性 = '属性值']
tag[attribute='value']
以该页面input输入框为例写一个css:

标签名tag:input
属性attribute:id
属性值value:displayed-text
input[id='displayed-text']
四、简写
我们以该网址为例(https://learn.letskodeit.com/p/practice)
id的简写:“#”(input[id=displayed-text] 、#displayed-text、 input#displayed-text)
class的简写:“.”(input[class=displayed-class]、 .displayed-class、input.displayed-class)
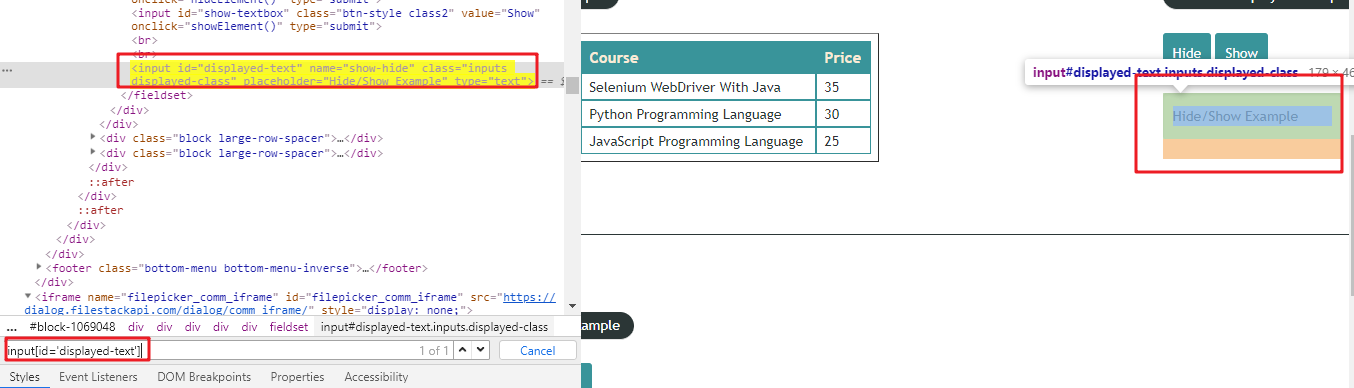
1、直接使用css样式查找谷歌浏览器验证元素是否唯一:(input[id='displayed-text'])
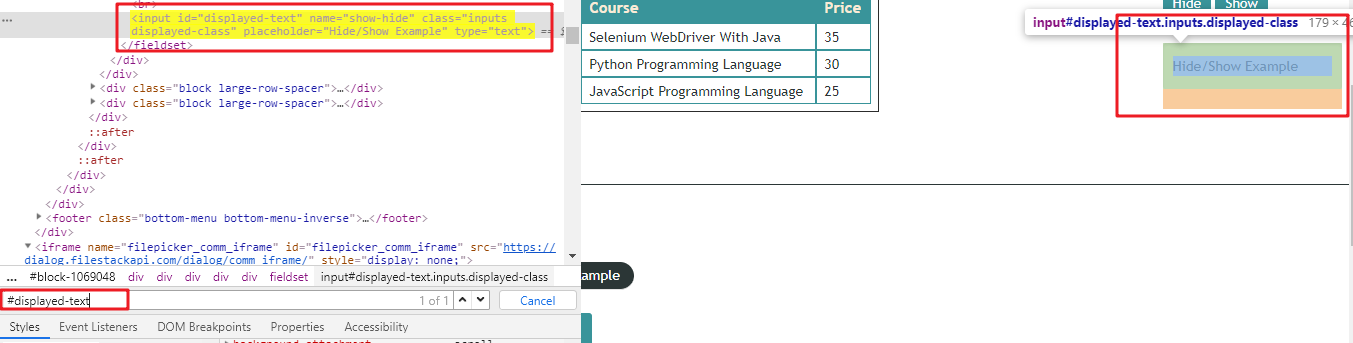
2、使用#代表id直接查找(#displayed-text)
章节十、3-CSS Selector---用CSS Selector - ID定位元素的更多相关文章
- python+selenium:解决上传文件<input type='file'>标签属性被css的visibility隐藏导致无法定位元素的问题
要想上传文件,需要找到在HTML中<input type="file" />这个标签,有它就可以利用send_keys上传文件,不过这里的<input>元素 ...
- 『心善渊』Selenium3.0基础 — 8、使用CSS选择器定位元素
目录 1.CSS选择器介绍 2.CSS选择器定位语法 3.Selenium中使用CSS选择器定位元素 (1)通过属性定位元素 (2)通过标签定位元素 (3)通过层级关系定位元素 (4)通过索引定位元素 ...
- Python+Selenium 利用ID,XPath,tag name,link text,partial link text,class name,css,name定位元素
使用firefox浏览器,查看页面元素,我们以“百度网页”为示例 一.ID定位元素 利用find_element_by_id()方法来定位网页元素对象 ①.定位百度首页,输入框的元素 ②.编写示 ...
- Scrapy学习系列(一):网页元素查询CSS Selector和XPath Selector
这篇文章主要介绍创建一个简单的spider,顺便介绍一下对网页元素的选取方式(css selector, xpath selector). 第一步:创建spider工程 打开命令行运行以下命令: sc ...
- css selector regexp css选择器 正则表达式 css 参考手册
jQuery 选择元素 a.text-success, a.text-danger, a.text-primary, a.text-info $("a[class^=text-]" ...
- 第十四章 校本化CSS
CSS(层叠样式表)是一种指定HTML文档视觉的表现的标准.CSS本来是让视觉设计师来使用的:它允许设计师精确的对文档元素的字体 ,颜色,外边距,缩进,边框甚至是定位.不过,客户端javascript ...
- CSS规范--春风十里不如写好CSS
先吟几句: 最近看了看春风十里不如你,本来很少看剧的,暑假有点闲就看了,感觉不错,挺喜欢这部剧,就套了个名字,嘿嘿嘿.剧里面印象深刻的是<致橡树>这首诗,念几句: 我如果爱你,绝不像攀援的 ...
- Python之路【第十九篇】:前端CSS
CSS 一.CSS概述 CSS是Cascading Style Sheets的简称,中文称为层叠式样式表,用来控制网页数据的表现,可以使网页的表现与数据内容分离. 学CSS后我们需要掌握的技能: 1. ...
- 爬虫(十五):Scrapy框架(二) Selector、Spider、Downloader Middleware
1. Scrapy框架 1.1 Selector的用法 我们之前介绍了利用Beautiful Soup.正则表达式来提取网页数据,这确实非常方便.而Scrapy还提供了自己的数据提取方法,即Selec ...
随机推荐
- 快速入门:弄懂Kafka的消息流转过程
大家都知道 Kafka 是一个非常牛逼的消息队列框架,阿里的 RocketMQ 也是在 Kafka 的基础上进行改进的.对于初学者来说,一开始面对这么一个庞然大物会不知道怎么入手.那么这篇文章就带你先 ...
- docker同时删除多个容器
查询所有容器 sudo docker ps -a 同时删除多个符合筛选条件的容器,例如删除状态为“exited”的容器 docker rm $(docker container ls -f " ...
- flex布局基本语法
注 : 本文章按照菜鸟教程 Flex布局语法教程为原型稍加修改,以方便自己学习. 菜鸟教程地址:http://www.runoob.com/w3cnote/flex-grammar.html 2009 ...
- java工作流引擎Jflow流程事件和流程节点事件设置
流程实例的引入和设置 关键词: 开源工作流引擎 Java工作流开发 .net开源工作流引擎 流程事件 工作流节点事件 应用场景: 在一些复杂的业务逻辑流程中需要在某个节点或者是流程结束后做一些 ...
- 一个能快速写出实体类的Api文档管理工具
今天各种MVC框架满天飞,大大降低了编码的难度,写实体类就没有办法回避的一件事了,花大把的时间去做一些重复而且繁琐的工作,实在不是一个优秀程序员的作风,所以多次查找和尝试后,找到一个工具类网站——Ap ...
- 【原】无脑操作:IDEA + maven + Shiro + SpringBoot + JPA + Thymeleaf实现基础授权权限
上一篇<[原]无脑操作:IDEA + maven + Shiro + SpringBoot + JPA + Thymeleaf实现基础认证权限>介绍了实现Shiro的基础认证.本篇谈谈实现 ...
- SUSE12SP3-Zookeeper安装
直接使用root账号 1.zookeeper安装 将zookeeper-3.4.13.tar.gz安装包放置指定目录 sudo tar -zxvf zookeeper-3.4.13.tar.gz -C ...
- 《深入理解 JVM 虚拟机》 --- 看书笔记
1.JVM 内存溢出 1.堆溢出:堆要不断的创建对象,如果避免了垃圾回收来清除这些对象,就会产生JVM内存溢出.一般手段是通过内存映像分析工具对Dump出来的堆转储快照进行分析,分清楚到底是内存泄露还 ...
- Git实际使用
初始化 git init — cd到目录,初始化仓库 git init name — 新建文件,并初始化仓库 .gitignore — 忽略文件(https://github.com/gi ...
- 开源图像标注工具labelme的安装使用及汉化
一 LabelMe简介 labelme是麻省理工(MIT)的计算机科学和人工智能实验室(CSAIL)研发的图像标注工具,人们可以使用该工具创建定制化标注任务或执行图像标注,项目源代码已经开源. 项目开 ...