Python数据处理与计算——概述
Python是一种面向对象的,动态的程序设计语言,具有非常简洁而清晰的语法,适合于完成各种高层任务。它既可以用来快速开发程序脚本,也可以用来开发大规模的软件。
随着NumPy、SciPy、Matplotlib、Enthoughtlibrarys等众多程序库的开发,Python越来越适合于做科学计算、绘制高质量的2D和3D图像。与科学计算领域最流行的商业软件MATLAB相比,Python是一门通用的程序设计语言,比MATLAB所采用的脚本语言的应用范围更广泛,有更多的程序库的支持。虽然MATLAB中的许多高级功能和toolbox目前还是无法替代的,不过在日常的科研开发之中仍然很多的工作是可以用Python代劳的。
常用的模块概览与导入
1.数值计算库
NumPy为Python提供了快速的多维数据处理的能力,而SciPy则在NumPy基础上添加了众多的科学计算所需的各种工具包,有利这两个库,Python就具有几乎与MATLAB一样的处理数据和计算的能力了。
NumPy和SciPy官方网址分别为http://www.numpy.org/和https://www.scipy.org/
NumPy为Python带来了真正的多维数据处理功能,并且提供了丰富的函数库处理这些数组。它将常用的数学函数进行数组化,使得这些数学函数能够直接对数组进行操作,将本来需要在Python级别进行的循环,放到C语言的运算中,明显地提高了程序的运算速度。
SciPy的核心计算部分都是一些久经考验的Fortran数值计算库,例如:
- 线性代数使用lapack库;
- 快速傅里叶变换使用fftpack库;
- 常微分方程求解使用odepack库;
- 非线性方程组求解及最小值求解等使用minpack库
2.符号计算库
SymPy是一套进行符号数学运算的Python函数库,它足够好用,可以帮助我们进行公式推导,进行符号求解。
SymPy官方网址:http://www.sympy.org/en/index.html
3.界面设计
制作界面一直都是一件十分复杂的工作,使用Traits库,将使得我们不必再界面设计上耗费大量精力,从而能把注意力集中到如何处理数据上去。
Traits官方网站:http://code.enthought.com/pages/traits.html
Traits库分为Traits和TraitsUI两大部分,Traits为Python添加了类型定义的功能,使用它定义的Traits属性具有初始化、校验、代理、事件等诸多功能。
TraitsUI库基于Traits库,使用MVC结构快速地定义用户界面,在最简单的情况下,编码者都不需要写一句关于界面的代码,就可以通过Traits属性定义获得一个可以工作的用户界面。使用TraitsUI库编写的程序自动支持wxPython和pyQt两个经典的界面库。
4.绘图与可视化
Chaco和Matplotlib是很优秀的2D绘图库,Chaco库和Traits库紧密相连,方便制作动态交互式的图表功能。而Matplotlib库则能够快速地绘制精美的图表,以各种格式输出,并且带有简单的3D绘图的功能。
Chaco官方网站:http://code.enthought.com/projects/chaco/
Matplotlib官方网站:https://matplotlib.org/
TVTK库在标准的VTK库之上用Traits库进行封装,如果要在Python下使用VTK,用TVTK是再好不过的选择。Mayavi2则在TVTK的基础上再添加了一套面向应用的方便工具,它既可以单独作为3D可视化程序使用,也可以快速地嵌入到用户的程序中去。
Mayavi官方网址:http://code.enthought.com/pages/mayavi-project.html
视觉化工具函式库(Visualization Toolkit,VTK)是一个开放源码,跨平台、支援平行处理(VTK曾用与处理大小近乎1个Petabyte的资料,其平台为美国Los Alamos国家实验室所有的具有1024个处理器之大型系统)的图形应用函式库。2005年曾被美国陆军研究实验室用于即时模拟俄罗斯制反导弹战车ZSU23-4受到平面波攻击的情形,其计算节点高达2.5兆之多。
此外,使用Visual库能够快速、方便地制作3D动画演示,使数据结果更有说服力。
Visual官方网站:http://vpython.org/
5.图像处理和计算机视觉
openCV由英特尔公司发起并参与开发,以BSD许可证授权发行,可以在商业和研究领域中免费使用。OpenCV可用于开发实时的图像处理、计算机视觉及模式识别程序。OpenCV提供的Python API方便我们快速实现算法,查看结果并且和其他的库进行数据交换。
Numpy简介
标准安装的Python中用列表(list)保存一组值,可以用来当做数组使用,但是由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针。这样为了保存一个简单的[1,2,3],需要有3个指针和3个整数对象。对于数值运算来说这种结构显然比较浪费内存和CPU计算时间。
此外,Python还提供了一个array模块,array对象和列表不同,它直接保存数值,与C语言的一维数组比较类似。但是由于它不支持多维,也没有各种运算函数,因此不适合做数值运算。
NumPy的诞生弥补了以上不足,NumPy提供了两种基本的对象:ndarray(N-dimensional array object)和ufunc(universal function object)。ndarray(后面内容统一称之为数组)是存储单一数据类型的多维数组,而ufunc则是能够对数组进行处理的函数。
1)Numpy库的导入
在进行Numpy相关操作时,在此需要先导入该库:
import numpy as np #导入numpy之后使用np可代替numpy
2)数组的创建与生产
首先需要创建数组才能对其进行其他操作。可以通过给array函数传递Python的序列对象来创建对象,如果传递的是多层嵌套的序列,将创建多维数组
1.直接复制创建数组:
#数组创建直接赋值 import numpy as np a=np.array([1,2,3,4]);
b=np.array([5,6,7,8]);
c=np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]]); print(a.shape);#a的shape属性
print(a);
print(b);
print(c);#多维数组
print(c.shape);#c的shape属性
print(c.dtype)#查看c的数据类型 #output:
# (4,)
# [1 2 3 4]
# [5 6 7 8]
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
# (3, 4)
# int32
2.改变数组的形式:通过shape属性查看并更改。数组a的shape只有一个元素,因此它是一维数组。而数组c的shape有两个元素,因此它是二维数组,其中第0轴的长度为3,第1轴的长度为4.还可以通过修改数组的shape属性,还保持数组元素个数不变的情况下,改变数组每个轴的长度。
下面的例子将数组c的shape改为(4,3),注意从(3,4)改为(4,3)并不是对数组进行转置,而只是改变每个轴的大小,数组元素在内存中的位置并没有改变:
#接上面程序
c.shape=3,4;
print(c.shape);
print(c)
c.shape=4,3;
print(c.shape);
print(c) # output:
# (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
# (4, 3)
# [[ 1 2 3]
# [ 4 5 6]
# [ 7 8 9]
# [10 11 12]]
3.使用reshape方法,重新改变数组的尺寸,而原数组的尺寸不变:
#接上面程序
print(a)
d=a.reshape(2,2)
print(d)
print(a) # output:
# [1 2 3 4]
# [[1 2]
# [3 4]]
# [1 2 3 4]
4.数组a和d其实是共享数据存储内存区域的,因此修改其中任意一个数组的元素都会同时修改另外一个数组的内容:
#接上面程序
print(d)
a[0]=1000000;#将数组a的一个元素改为1000000
print(d) # output:
# [[1 2]
# [3 4]]
# [[1000000 2]
# [ 3 4]]
5.前面所说的都是默认的dtype,现在改变其dtype参数:
# 指定数据类型
e=np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]],dtype=np.float);
print(e) # output:
# [[ 1. 2. 3. 4.]
# [ 5. 6. 7. 8.]
# [ 9. 10. 11. 12.]]
6.当然,到现在为止,所创建的array都是基于手动赋值操作,Python还提供一些函数可以自动化地创建数组。
# 利用函数创建数组 # numpy中的arange()函数类似于Python中的range()函数
# 通过指定开始值,终值和步长来创建一维数组,注意数组不包括终值
arr1=np.arange(0,10,1.0);
print(arr1);
# output:
# [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.] #linspace函数通过指定开始值,终值和元素的个数来创建一维数组
#可以通过endpoint关键字指定是否包括终值,缺省设置是包括终值
print(np.linspace(0,1,12));
# output:
# [0. 0.09090909 0.18181818 0.27272727 0.36363636 0.45454545
# 0.54545455 0.63636364 0.72727273 0.81818182 0.90909091 1. ] # logspace函数和linspace函数类似,不过它创建等比数列
#下面的例子产生1(10^0)到10(10^2),有10个元素的等比数列
print(np.logspace(0,2,10))
# output:
# [ 1. 1.66810054 2.7825594 4.64158883 7.74263683
# 12.91549665 21.5443469 35.93813664 59.94842503 100. ]
3)利用数组进行数据处理
1.多维数组
在具体的应用中我们更多的是使用多维数组进行数据处理,而多维数组的存取和一维数组类似,只是多维数组有多个轴,因此,它的下标需要多个值来表示。Numpy采用元组(tuple)作为数组的下标。
2.多维数组创建
| 0 | 1 | 2 | 3 | 4 | 5 |
| 10 | 11 | 12 | 13 | 14 | 15 |
| 20 | 21 | 22 | 23 | 24 | 25 |
| 30 | 31 | 32 | 33 | 34 | 35 |
| 40 | 41 | 42 | 43 | 44 | 45 |
| 50 | 51 | 52 | 53 | 54 | 55 |
《=======数组a
首先来看如何创建该数组,数组a实际上是一个加法表,纵轴的值为0,10,20,30,40,50;横轴的值为0,1,2,3,4,5。纵轴的每个元素与横轴的每个元素求和得到上表中所示的数组a。
arr2=np.arange(0,6)+np.arange(0,60,10).reshape(-1,1);
print(arr2); # output:
# [[ 0 1 2 3 4 5]
# [10 11 12 13 14 15]
# [20 21 22 23 24 25]
# [30 31 32 33 34 35]
# [40 41 42 43 44 45]
# [50 51 52 53 54 55]]
3.多维数组存取
多维数组同样也可以使用整数序列和布尔数组进行存取。
import numpy as np arr2=np.arange(0,6)+np.arange(0,60,10).reshape(-1,1);
print(arr2)
# output:
# [[ 0 1 2 3 4 5]
# [10 11 12 13 14 15]
# [20 21 22 23 24 25]
# [30 31 32 33 34 35]
# [40 41 42 43 44 45]
# [50 51 52 53 54 55]] # 第一种获取
a=arr2[(0,1,2,3,4),(1,2,3,4,5)];#相当于arr2[0][1],arr2[1][2]....
print(a);
# output:
# [ 1 12 23 34 45] # 第二种获取
# 注意:别忘了中间的逗号
a=arr2[3:,[0,2,5]];#相当于是从第3行到最后一行的第0列,第2列,第5列
print(a)
# output:
# [[30 32 35]
# [40 42 45]
# [50 52 55]] # 第三种获取(通过bool值获取数组的数据)
mask=np.array([1,0,1,0,0,1],dtype=np.bool)
print(mask)#mask制作的是bool型列表
print(arr2[mask,2])#相当于行都是布尔值(true表示显示,false表示不显示),列都是2
# 注意:在此处mask充当的是行,那么它的值的数量必须和行数相等,否则则报错
# output:
# [ True False True False False True]
# [ 2 22 52]
用于数组的文件输入输出
1)把数组数据写入file
保存数组数据的文件可以是二进制格式或者是文本格式。但不会保存数组数组形状和元素类型等信息。
a=np.arange(0,16).reshape(4,4);
a.tofile(r'C:\Users\123\Desktop\a.bin')#文件后缀是bin
a.tofile(r'C:\Users\123\Desktop\a.txt')#文件后缀是txt
保存的后文件内容似乎不能有价值的人工读取。

2)读取文件file中的数组
因为保存时就未保存数组形状和元素类型等信息,故读取时必须为你要使用的数组设置合适的形状和元素类型。
#! /usr/bin/env python
#coding=utf-8
import numpy as np a=np.arange(0,16).reshape(4,4);
print(a)
a.tofile(r'C:\Users\123\Desktop\a.bin')#文件后缀是bin
a.tofile(r'C:\Users\123\Desktop\a.txt')#文件后缀是txt
b=np.fromfile(r'C:\Users\123\Desktop\a.txt',dtype=np.int32);
print();
print("取出后的信息并未保存存入文件时的数组类型和元素类型信息:");
print(b);
b.shape=4,4;
print();
print("从txt文件中提取:");
print(b);
c=np.fromfile(r'C:\Users\123\Desktop\a.bin');
print();
print("从bin文件中提取:");
print(c);
# output:
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]
# [12 13 14 15]] # 取出后的信息并未保存存入文件时的数组类型和元素类型信息:
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15] # 从txt文件中提取:
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]
# [12 13 14 15]] # 从bin文件中提取:
# [2.12199579e-314 6.36598737e-314 1.06099790e-313 1.48539705e-313
# 1.90979621e-313 2.33419537e-313 2.75859453e-313 3.18299369e-313]
3)numpy.load和numpy.save
numpy.load和numpy.save函数以Numpy专用的二进制类型保存数据,这两个函数会自动处理元素类型和shape等信息,使用它们读写数组就方便多了,但是numpy.save输出的文件很难用其他语言编写的程序读入(因为数据读取问题,利用numpy.save进行保存到的文件,在使用其他编程语言进行读取时增加了难度)。
np.save(r'C:\Users\123\Desktop\a.npy',a);#后缀名称为.npy
d=np.load(r'C:\Users\123\Desktop\a.npy');
print(d);
# output:
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]
# [12 13 14 15]]
4)numpy.savetxt和numpy.loadtxt
使用numpy.savetxt和numpy.loadtxt可以读写一维和二维的数组。
a=np.arange(0,12,0.5).reshape(4,-1);
print(a);
np.savetxt(r'C:\Users\123\Desktop\aTxt.txt',a);#缺省值按照“%.18e”格式保存数据,以空格分隔
print("读取信息:")
print(np.loadtxt(r'C:\Users\123\Desktop\aTxt.txt'));
# output:
# [[ 0. 0.5 1. 1.5 2. 2.5]
# [ 3. 3.5 4. 4.5 5. 5.5]
# [ 6. 6.5 7. 7.5 8. 8.5]
# [ 9. 9.5 10. 10.5 11. 11.5]]
# 读取信息:
# [[ 0. 0.5 1. 1.5 2. 2.5]
# [ 3. 3.5 4. 4.5 5. 5.5]
# [ 6. 6.5 7. 7.5 8. 8.5]
# [ 9. 9.5 10. 10.5 11. 11.5]]
使用该方法得到的文件可以人工读取。

也可将数组该保存在整数。
np.savetxt(r'C:\Users\123\Desktop\aTxt.txt',a,fmt="%d",delimiter=",");#改保存为整数,以逗号分隔
#读入的时候也需要自定逗号分隔(可以看到这样的方式数据失真)
print(np.loadtxt(r'C:\Users\123\Desktop\aTxt.txt',delimiter=","))
# output:
# [[ 0. 0. 1. 1. 2. 2.]
# [ 3. 3. 4. 4. 5. 5.]
# [ 6. 6. 7. 7. 8. 8.]
# [ 9. 9. 10. 10. 11. 11.]]
此时,文件是这样的。
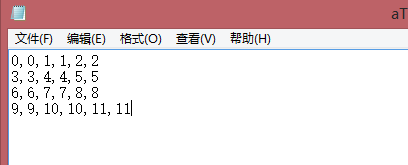
数组的算术和统计运算
1)数组的算术
数组的算术在实际的应用过程中大都通过矩阵matrix的运算来实现,Numpy和MATLAB不一样,对于多维数组的运算,缺省值的情况下并不使用矩阵运算,如果希望对数组的进行矩阵运算的话,可以调用相应的函数。之所以在Python中加入matrix运算是因为它的运算快,而且数组一般的表示就是一维、二维数组,值得注意的是虽然基于矩阵matrix运算代码较少,执行效率高,但是比较考验程序员的数学水平,而基于数组的运算可以多谢一堆代码,但是如果数据量大的情况下执行的运算容易崩溃,此处简单介绍matrix运算。
#可以把matrix理解为多维数组
ma=np.matrix([[1,2,3],[4,5,6],[7,8,9]]);
print(ma);
# output:
# [[1 2 3]
# [4 5 6]
# [7 8 9]]
2)基于矩阵matrix的运算
#可以把matrix理解为多维数组
ma=np.matrix([[1,2,3],[4,5,6],[7,8,9]]);
ma+ma #矩阵加法
# output:
# matrix([[ 2, 4, 6],
# [ 8, 10, 12],
# [14, 16, 18]]) ma-ma #矩阵减法
# output:
# matrix([[0, 0, 0],
# [0, 0, 0],
# [0, 0, 0]]) ma*ma #矩阵乘法
# ouput:
# matrix([[ 30, 36, 42],
# [ 66, 81, 96],
# [102, 126, 150]]) ma**-1 #矩阵求逆
# output:
# matrix([[ 3.15251974e+15, -6.30503948e+15, 3.15251974e+15],
# [-6.30503948e+15, 1.26100790e+16, -6.30503948e+15],
# [ 3.15251974e+15, -6.30503948e+15, 3.15251974e+15]])
3)基于矩阵matrix的统计运算
1.dot内积(可以基于一维数组,也可以基于两个矩阵)运算
a=np.arange(12).reshape(3,4);
b=np.arange(12,24).reshape(4,3);
c=np.dot(a,b);#求a和b的内积
print(a);
print();
print(b);
print();
print(c);
# output:
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]] # [[12 13 14]
# [15 16 17]
# [18 19 20]
# [21 22 23]] # [[114 120 126]
# [378 400 422]
# [642 680 718]]
2.inner运算
与dot乘积一样,对于两个一维数组,计算的是这两个数组对应下标元素的乘积和;对于多维数组,它计算的结果数组中的每个元素都是数组a和b的最后一维的内积,因此数组a和b的最后一维的长度必须相同。
a=np.arange(12).reshape(3,4);
b=np.arange(12,24).reshape(3,4);#注意此处和dot运算要求不一样
c=np.inner(a,b);#求a和b的内积
print(a);
print();
print(b);
print();
print(c);
# output:
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]] # [[12 13 14 15]
# [16 17 18 19]
# [20 21 22 23]] # [[ 86 110 134]
# [302 390 478]
# [518 670 822]]
3.outer运算
只按照一维数组进行运算,如果传入参数是多维数组,则先将此数组展平为一维数组之后再进行运算。outer乘积计算的是列向量和行向量的矩阵乘积:
a=np.arange(12).reshape(3,4);
b=np.arange(12,24).reshape(3,4);#注意此处和inner运算要求一样
c=np.outer(a,b);
print(c);
# output:
# [[ 0 0 0 0 0 0 0 0 0 0 0 0]
# [ 12 13 14 15 16 17 18 19 20 21 22 23]
# [ 24 26 28 30 32 34 36 38 40 42 44 46]
# [ 36 39 42 45 48 51 54 57 60 63 66 69]
# [ 48 52 56 60 64 68 72 76 80 84 88 92]
# [ 60 65 70 75 80 85 90 95 100 105 110 115]
# [ 72 78 84 90 96 102 108 114 120 126 132 138]
# [ 84 91 98 105 112 119 126 133 140 147 154 161]
# [ 96 104 112 120 128 136 144 152 160 168 176 184]
# [108 117 126 135 144 153 162 171 180 189 198 207]
# [120 130 140 150 160 170 180 190 200 210 220 230]
# [132 143 154 165 176 187 198 209 220 231 242 253]]
5.数组统计运算
针对数组进行统计计算,以下只是通过简单的例子来说明可以基于数组进行相应的统计计算,更多的统计函数参考Python手册(numpy部分)。
#统计数组
a=np.arange(12).reshape(3,4);
print("a矩阵:\n",a);
#以第0行数据为例进行统计运算
print("第0行:\n",a[0]);
print("和值:\n",np.sum(a[0]));
print("平均值:\n",np.mean(a[0]));
print("方差:\n",np.var(a[0]));
# output:
# a矩阵:
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
# 第0行:
# [0 1 2 3]
# 和值:
#
# 平均值:
# 1.5
# 方差:
# 1.25
参考书目:《数据馆员的Python简明手册》
Python数据处理与计算——概述的更多相关文章
- 【转】Python数据类型之“序列概述与基本序列类型(Basic Sequences)”
[转]Python数据类型之“序列概述与基本序列类型(Basic Sequences)” 序列是指有序的队列,重点在"有序". 一.Python中序列的分类 Python中的序列主 ...
- python数据处理技巧二
python数据处理技巧二(掌控时间) 首先简单说下关于时间的介绍其中重点是时间戳的处理,时间戳是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00 ...
- python数据处理书pdf版本|内附网盘链接直接提取|
Python数据处理采用基于项目的方法,介绍用Python完成数据获取.数据清洗.数据探索.数据呈现.数据规模化和自动化的过程.主要内容包括:Python基础知识,如何从CSV.Excel.XML.J ...
- 最全总结 | 聊聊 Python 数据处理全家桶(Redis篇)
1. 前言 前面两篇文章聊到了 Python 处理 Mysql.Sqlite 数据库常用方式,本篇文章继续说另外一种比较常用的数据存储方式:Redis Redis:Remote Dictionary ...
- 使用python做科学计算
这里总结一个guide,主要针对刚开始做数据挖掘和数据分析的同学 说道统计分析工具你一定想到像excel,spss,sas,matlab以及R语言.R语言是这里面比较火的,它的强项是强大的绘图功能以及 ...
- 使用Python做科学计算初探
今天在搞定Django框架的blog搭建后,尝试一下python的科学计算能力. python的科学计算有三剑客:numpy,scipy,matplotlib. numpy负责数值计算,矩阵操作等: ...
- 使用Python做科学计算初探(转)
今天在搞定Django框架的blog搭建后,尝试一下python的科学计算能力. python的科学计算有三剑客:numpy,scipy,matplotlib. numpy负责数值计算,矩阵操作等: ...
- Python数据处理PDF
Python数据处理(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1h8a5-iUr4mF7cVujgTSGOA 提取码:6fsl 复制这段内容后打开百度网盘手机A ...
- Python 数据处理库 pandas 入门教程
Python 数据处理库 pandas 入门教程2018/04/17 · 工具与框架 · Pandas, Python 原文出处: 强波的技术博客 pandas是一个Python语言的软件包,在我们使 ...
随机推荐
- Thymeleaf【快速入门】
前言:突然发现自己给自己埋了一个大坑,毕设好难..每一个小点拎出来都能当一个小题目(手动摆手..),没办法自己选的含着泪也要把坑填完..先一点一点把需要补充的知识学完吧.. Thymeleaf介绍 稍 ...
- 程序猿必知必会Linux命令之awk
前言 对于一名专业的程序员来说,Linux相关知识是必须要掌握的,其中对于文本的处理更是我们常见的操作,比如格式化输出我们需要的数据,这些数据可能会来源于文本文件或管道符,或者统计文本里面我们需要的数 ...
- 在Unity中实现小地图(Minimap)
小地图的基本概念众所周知,小地图(或雷达)是用于显示周围环境信息的.首先,小地图是以主角为中心的.其次,小地图上应该用图标来代替真实的人物模型,因为小地图通常很小,玩家可能无法看清真实的模型.大多数小 ...
- 第13章 Base64 URL编码 - IdentityModel 中文文档(v1.0.0)
JWT令牌使用Base64 URL编码进行序列化. IdentityModel包括Base64Url帮助编码/解码的类: var text = "hello"; var b64ur ...
- [PHP] ubuntu下使用uuid扩展获取uuid
1.php生成uuid网上大部分是使用随机数md5截取的,很有可能会重复冲突 2.uuid的组成中最重要的一个是机器码,大部分是网卡MAC地址, php无法获取到机器码,因此不能直接使用代码来生成一个 ...
- AI2(App Inventor 2)离线版服务器网络版
个人修改包括: 1.后台增加用户批量添加功能 https://gte.fsyz.net/node/1877 2.上传文件限制改为100M ,编译文件限制改为10M https ...
- Android中对已安装应用的管理实现
获取.管理手机中已安装的所有应用信息 1.创建应用的实体类AppInfo,属性有应用的名称.包名.图标.第一次安装时间和版本名称 public class AppInfo { private Stri ...
- Python之路【第一篇】:Python简介和入门
python简介: 一.什么是python Python(英国发音:/ pa θ n/ 美国发音:/ pa θɑ n/),是一种面向对象.直译式的计算机程序语言. 每一门语言都有自己的哲学: pyth ...
- Storm入门(七)可靠性机制代码示例
一.关联代码 使用maven,代码如下. pom.xml 参考 http://www.cnblogs.com/hd3013779515/p/6970551.html MessageTopology. ...
- linux中使用docker-compose部署软件配置分享
本篇将分享一些 docker-compose 的配置,可参考其总结自己的一套基于docker的开发/生产环境配置. 安装docker及docker-compose install docker cur ...