Apache kylin概览
一、Apache kylin的核心概念
- 表(Table ):表定义在hive中,是数据立方体(Data cube)的数据源,在build cube 之前,必须同步在 kylin中。
- 模型(model):模型描述了一个星型模式的数据结构,它定义了一个事实表(Fact Table: Wiki:Fact_table)和多个查找表(Lookup Table:Wiki:Lookup_table)的连接和过滤关系。
- 立方体(Cube):它定义了使用的模型、模型中的表的维度(dimension:Wiki:dimension)、度量(measure:Wiki:measure ,一般指聚合函数,如:sum、count、average等)、如何对段分区( segments partition)、合并段(segments auto-merge)等的规则。
- 立方体段(Cube Segment):它是立方体构建(build)后的数据载体,一个 segment 映射hbase中的一张表,立方体实例构建(build)后,会产生一个新的segment,一旦某个已经构建的立方体的原始数据发生变化,只需刷新(fresh)变化的时间段所关联的segment即可。
- 作业(Job):对立方体实例发出构建(build)请求后,会产生一个作业。该作业记录了立方体实例build时的每一步任务信息。作业的状态信息反映构建立方体实例的结果信息。如作业执行的状态信息为RUNNING 时,表明立方体实例正在被构建;若作业状态信息为FINISHED ,表明立方体实例构建成功;若作业状态信息为ERROR ,表明立方体实例构建失败!作业的所有状态如下:
- NEW - This denotes one job has been just created.
- PENDING - This denotes one job is paused by job scheduler and waiting for resources.
- RUNNING - This denotes one job is running in progress.
- FINISHED - This denotes one job is successfully finished.
- ERROR - This denotes one job is aborted with errors.
- DISCARDED - This denotes one job is cancelled by end users.
二、Apache kylin的工作机制
Apache kylin 能提供低延迟(sub-second latency)的秘诀就是预计算,即针对一个星型拓扑结构的数据立方体,预计算多个维度组合的度量,然后将结果保存在hbase中,对外暴露JDBC、ODBC、Rest API的查询接口,即可实现实时查询。
数据立方体一般由Hive中的一个事实表,多个查找表组成。预计算的过程在kylin中就是 Cube 的build过程,如下图:
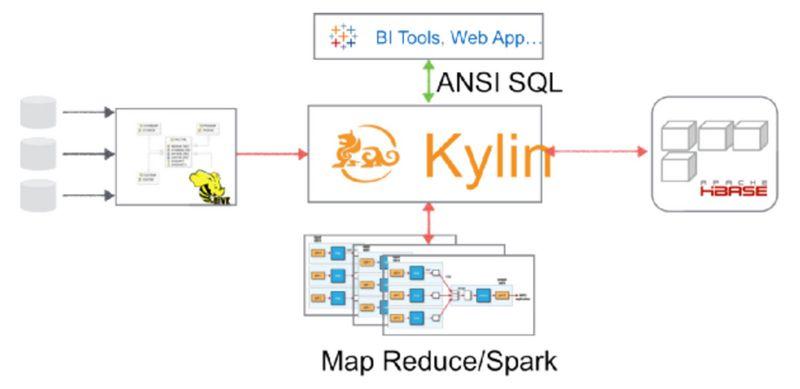 当前Apache kylin构建(build)数据立方体,采用逐层算法(By Layer Cubing)。未来的发布中将采用快速立方体算法(Fast Cubing)。下面简单介绍一下逐层算法:
当前Apache kylin构建(build)数据立方体,采用逐层算法(By Layer Cubing)。未来的发布中将采用快速立方体算法(Fast Cubing)。下面简单介绍一下逐层算法:
一个完整的数据立方体,由N-dimension立方体,N-1
dimension立方体,N-2维立方体,0
dimension立方体这样的层关系组成,除了N-dimension立方体,基于原数据计算,其他层的立方体可基于其父层的立方体计算。所以该算法的核心是N次顺序的MapReduce计算。
在MapReduce模型中,key由维度的组合的构成,value由度量的组合构成,当一个Map读到一个key-value对时,它会计算所有的子立方体(child cuboid),在每个子立方体中,Map从key中移除一个维度,将新key和value输出到reducer中。直到当所有层计算完毕,才完成数据立方体的计算。过程如下图:
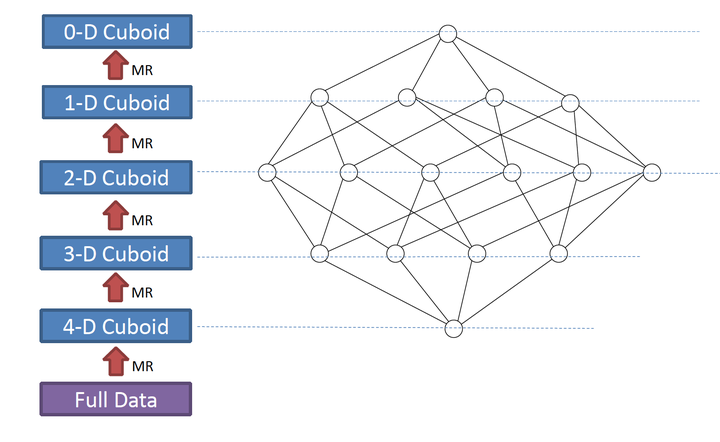 在数据立方体计算完毕后,有一个任务(Convert
在数据立方体计算完毕后,有一个任务(Convert
Cuboid Data to HFile),其职责是将reduce输出的运算结果(Cuboid
Data)转化成Hbase中的存储载体(HFile),最终将HFile
加载到Hbase表中便于查询。其中表的rowkey由维度组合而成,维度组合对应的度量值构成了column
family,为了查询减少存储空间,会对RowKey和column family的值进行编码,默认编码是Snappy。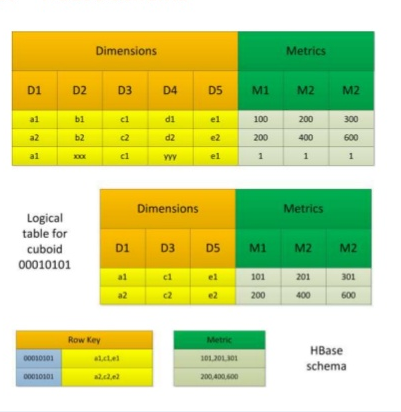 整个数据立方体的构建流程如下:
整个数据立方体的构建流程如下: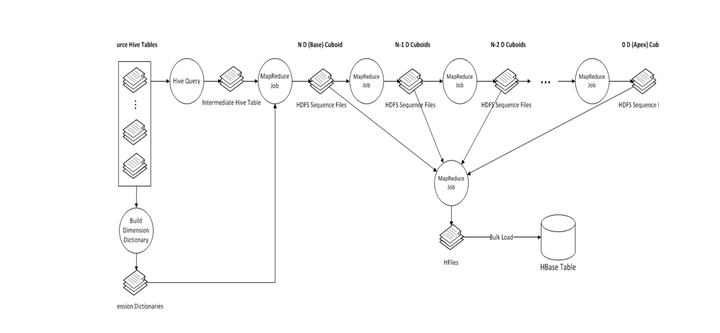
三、Apache kylin的架构及核心组件
Apache kylin 架构如下:
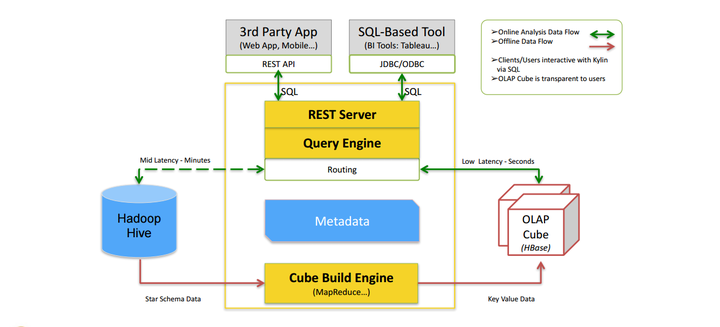 核心组件:
核心组件:
- 数据立方体构建引擎(Cube Build Engine):当前底层数据计算引擎支持MapReduce1、MapReduce2、Spark等。
- Rest Server:当前kylin采用的rest API、JDBC、ODBC接口提供web服务。
- 查询引擎(Query Engine):Rest Server接收查询请求后,解析sql语句,生成执行计划,然后转发查询请求到Hbase中,最后将结构返回给 Rest Server。
Apache kylin概览的更多相关文章
- APACHE KYLIN™ 概览
APACHE KYLIN™ 概览 Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发 ...
- APACHE KYLIN™ 概览(分布式分析引擎)
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区.它能 ...
- 《基于Apache Kylin构建大数据分析平台》
Kyligence联合创始人兼CEO,Apache Kylin项目管理委员会主席(PMC Chair)韩卿 武汉市云升科技发展有限公司董事长,<智慧城市-大数据.物联网和云计算之应用>作者 ...
- Apache Kylin 部署之不完全指南
1. 引言 Apache Kylin(麒麟)是由eBay开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据.底层存储用的是HBase,数据输入与cu ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- 大数据分析神兽麒麟(Apache Kylin)
1.Apache Kylin是什么? 在现在的大数据时代,越来越多的企业开始使用Hadoop管理数据,但是现有的业务分析工具(如Tableau,Microstrategy等)往往存在很大的局限,如难以 ...
- 【大数据安全】Apache Kylin 安全配置(Kerberos)
1. 概述 本文首先会简单介绍Kylin的安装配置,然后介绍启用Kerberos的CDH集群中如何部署及使用Kylin. Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spa ...
- apache kylin的单节点及多节点安装
Kylin的使用安装文档Kylin简介Kylin是什么Apache Kylin是一个开源的分布式分析引擎,最初由eBay开发贡献至开源社区.它提供Hadoop之上的SQL查询接口及多维分析(OLAP) ...
- Apache kylin 入门
本篇文章就概念.工作机制.数据备份.优势与不足4个方面详细介绍了Apache Kylin. Apache Kylin 简介 1. Apache kylin 是一个开源的海量数据分布式预处理引擎.它通过 ...
随机推荐
- DataPipeline联合Confluent Kafka Meetup上海站
Confluent作为国际数据“流”处理技术领先者,提供实时数据处理解决方案,在市场上拥有大量企业客户,帮助企业轻松访问各类数据.DataPipeline作为国内首家原生支持Kafka解决方案的“iP ...
- C++基础——类继承中方法重载
一.前言 在上一篇C++基础博文中讨论了C++最基本的代码重用特性——类继承,派生类可以在继承基类元素的同时,添加新的成员和方法.但是没有考虑一种情况:派生类继承下来的方法的实现细节并不一定适合派生类 ...
- python3 字符编码与转码的理解
额...上通识课讲到了NLP12条,感觉讲的挺好的,照着抄一条先... 1,没有两个人是一样的 没有两个人的人生经验会完全一样,所以没有两个人的信念,价值和规条系统会是一样. 因此没有两个人对同一件事 ...
- PTA 深入虎穴 (正解)和树的同构
在上一篇博客中分享了尝试用单链表修改程序,虽然在Dev上运行没有错误,但是PTA设置的测试点有几个没有通过,具体不清楚问题出现在哪里,所以现在把之前正确的程序放在这里. 7-2 深入虎穴 (30 分) ...
- MappedByteBuffer
计算机内存管理 原文链接 https://www.cnblogs.com/guozp/p/10470431.html MMC:CPU的内存管理单元. 物理内存:即内存条的内存空间. 虚拟内存:计算机系 ...
- springcloud之hystrix熔断器-Finchley.SR2版
本篇和大家分享的是springcloud-hystrix熔断器,其主要功能是对某模块调用失败做断路和降级,简单点就当某个模块程序出问题了并达到某阈值就限制后面请求,并降级的方式提供一个默认返回数据.最 ...
- mysql的学习笔记(六)
1.字符函数 (1).CONCAT(str1,str2,...)函数,将多列信息合并输出. SELECT CATCAT('hello','mysql') as test (2).CONCAT_WS(' ...
- windows安装IDEA
1.安装下载 https://www.jetbrains.com/idea/download/#section=windows 2.服务器激活地址: 39.129.9.34:8888 https:// ...
- KeyboardUtil【软键盘弹出后输入框上移一定的高度】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 演示获取软键盘高度并保存,然后根据输入框的原有位置是否被软键盘挡住了,如果被挡住了则将整体页面上移一定的高度,当软键盘隐藏的时候再下 ...
- JVM回收器与调优
定义: 使用编程语言将GC算法实现出来,产生的程序就是垃圾搜集器了 JVM给了三种选择:串行收集器.并行收集器.并发收集器 串行搜集器(serial collector):它只有一条GC线程,且就像前 ...