正则化(Regularization)本质
参考:
http://www.cnblogs.com/maybe2030/p/9231231.html
https://blog.csdn.net/wsj998689aa/article/details/39547771
https://charlesliuyx.github.io/2017/10/03/%E3%80%90%E7%9B%B4%E8%A7%82%E8%AF%A6%E8%A7%A3%E3%80%91%E4%BB%80%E4%B9%88%E6%98%AF%E6%AD%A3%E5%88%99%E5%8C%96/
1、正则化是什么
正则化看起来有些抽象,其直译"规则化",本质其实很简单,就是给模型加一些规则限制,约束要优化参数,目的是防止过拟合。其中最常见的规则限制就是添加先验约束,其中L1相当于添加Laplace先验,L相当于添加Gaussian先验。
2、L1正则和L2正则
L1正则是在原始的loss函数上加上一个L1正则化项,这个L1正则项实际就是在loss函数上添加一个结构化风险项,因此正则化其实和“带约束的目标函数”是等价的。而L1正则项就是一个1范数,本质相当于添加一个Laplace先验知识。同理,L2正则化项是一个2范数,本质却相当于添加一个Gaussian先验知识。
参考http://www.cnblogs.com/heguanyou/p/7582578.html。
3、范数
参考:https://charlesliuyx.github.io/2017/10/03/%E3%80%90%E7%9B%B4%E8%A7%82%E8%AF%A6%E8%A7%A3%E3%80%91%E4%BB%80%E4%B9%88%E6%98%AF%E6%AD%A3%E5%88%99%E5%8C%96/
我们知道,范数(norm)的概念来源于泛函分析与测度理论,wiki中的定义相当简单明了:范数是具有“长度”概念的函数,用于衡量一个矢量的大小(测量矢量的测度)
我们常说测度测度,测量长度,也就是为了表征这个长度。而如何表达“长度”这个概念也是不同的,也就对应了不同的范数,本质上说,还是观察问题的方式和角度不同,比如那个经典问题,为什么矩形的面积是长乘以宽?这背后的关键是欧式空间的平移不变性,换句话说,就是面积和长成正比,所以才有这个
没有测度论就没有(现代)概率论。而概率论也是整个机器学习学科的基石之一。测度就像尺子,由于测量对象不同,我们需要直尺量布匹、皮尺量身披、卷尺量房间、游标卡尺量工件等等。注意,“尺子”与刻度(寸、米等)是两回事,不能混淆。
范数分为向量范数(二维坐标系)和矩阵范数(多维空间,一般化表达),如果不希望太数学化的解释,那么可以直观的理解为:0-范数:向量中非零元素的数量;1-范数:向量的元素的绝对值;2-范数:是通常意义上的模(距离)
范数的图形表示如下:
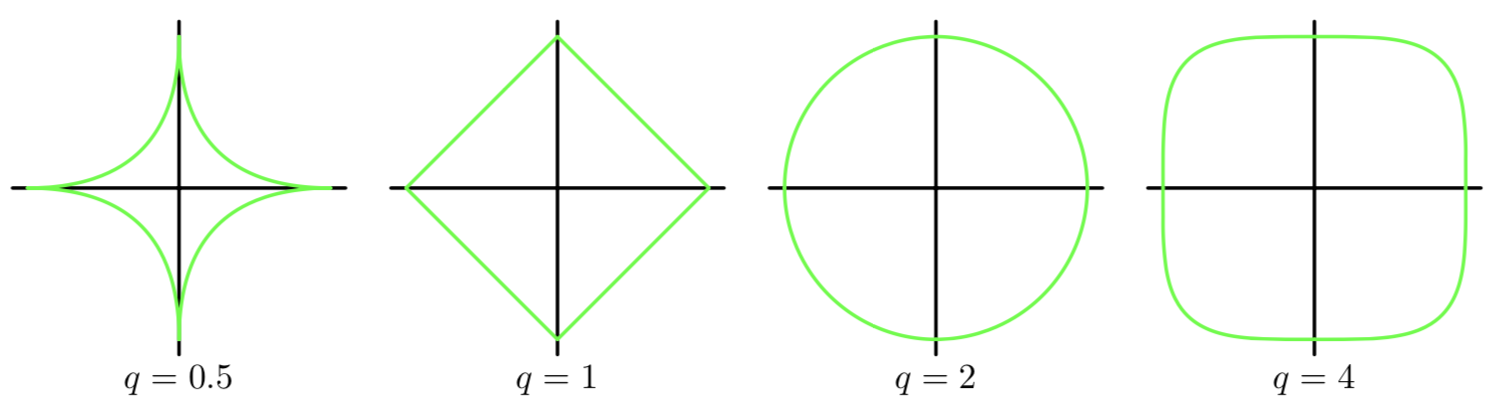
4、正则化为什么就能防止过拟合
参考:http://www.cnblogs.com/heguanyou/p/7582578.html
过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
从几何解释:
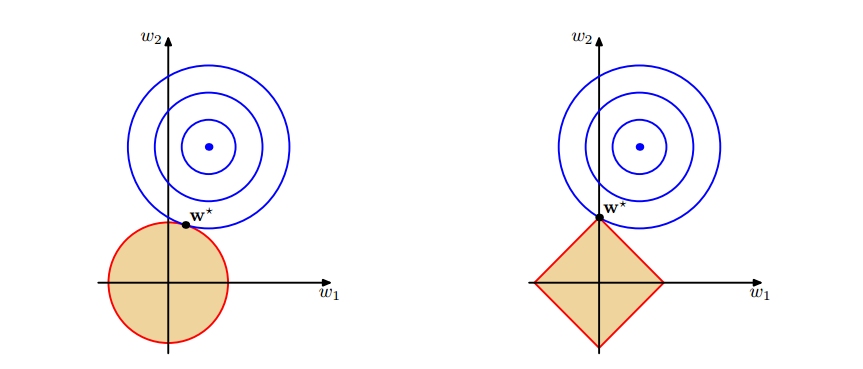
图1 上面中的蓝色轮廓线是没有正则化损失函数的等高线,中心的蓝色点为最优解,左图、右图分别为L2、L1正则化给出的限制。
可以看到在正则化的限制之下,L2正则化给出的最优解 $w^{*} $是使解更加靠近原点,也就是说L2正则化能降低参数范数的总和,使得模型的解偏向于 norm 较小的 W,通过限制 W 的 norm 的大小实现了对模型空间的限制,从而在一定程度上避免了 overfitting 。不过 L2正则化并不具有产生稀疏解的能力,得到的系数 仍然需要数据中的所有特征才能计算预测结果,从计算量上来说并没有得到改观。
L1正则化给出的最优解$w^{*}$是使解更加靠近某些轴,而其它的轴则为0,所以L1正则化能使得到的参数稀疏化。稀疏的解除了计算量上的好处之外,更重要的是更具有“可解释性”。比如说,一个病如果依赖于 5 个变量的话,将会更易于医生理解、描述和总结规律,但是如果依赖于 5000 个变量的话,基本上就超出人肉可处理的范围了。
因此正则化是通过约束参数的范数使其不要太大,使其在一定程度上减少过拟合情况。
5、Dropout与Batch Normalization
http://www.cnblogs.com/maybe2030/p/9231231.html
正则化(Regularization)本质的更多相关文章
- zzL1和L2正则化regularization
最优化方法:L1和L2正则化regularization http://blog.csdn.net/pipisorry/article/details/52108040 机器学习和深度学习常用的规则化 ...
- 7、 正则化(Regularization)
7.1 过拟合的问题 到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fittin ...
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- 斯坦福第七课:正则化(Regularization)
7.1 过拟合的问题 7.2 代价函数 7.3 正则化线性回归 7.4 正则化的逻辑回归模型 7.1 过拟合的问题 如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集( ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [笔记]机器学习(Machine Learning) - 03.正则化(Regularization)
欠拟合(Underfitting)与过拟合(Overfitting) 上面两张图分别是回归问题和分类问题的欠拟合和过度拟合的例子.可以看到,如果使用直线(两组图的第一张)来拟合训,并不能很好地适应我们 ...
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [C3] 正则化(Regularization)
正则化(Regularization - Solving the Problem of Overfitting) 欠拟合(高偏差) VS 过度拟合(高方差) Underfitting, or high ...
- 1.4 正则化 regularization
如果你怀疑神经网络过度拟合的数据,即存在高方差的问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,但是你可能无法时时准备足够多的训练数据,或者获取更多数据的代价很高.但正则 ...
- 机器学习(五)--------正则化(Regularization)
过拟合(over-fitting) 欠拟合 正好 过拟合 怎么解决 1.丢弃一些不能帮助我们正确预测的特征.可以是手工选择保留哪些特征,或者使用一 些模型选择的算法来帮忙(例如 PCA) 2.正则化. ...
随机推荐
- JavaScript夯实基础系列(三):this
在JavaScript中,函数的每次调用都会拥有一个执行上下文,通过this关键字指向该上下文.函数中的代码在函数定义时不会执行,只有在函数被调用时才执行.函数调用的方式有四种:作为函数调用.作为 ...
- Windows环境下安装配置Mosquitto服务及入门操作介绍
关键字:在windows安装mosquitto,在mosquitto中配置日志,在mosquitto中配置用户账号密码 关于Mosquitto配置的资料网上还是有几篇的,但是看来看去,基本上都是基于L ...
- 简简单单的Vue3(插件开发,路由系统,状态管理)
既然选择了远方,便只顾风雨兼程 __ HANS许 系列:零基础搭建前后端分离项目 系列:零基础搭建前后端分离项目 插件 路由(vue-router) 状态管理模式(Vuex) 那在上篇文章,我们讲了, ...
- Java建造者模式
建造者模式 建造者模式适用场景: 建造一个复杂的对象适用,将构建对象的过程分开,每个类单独构造对象的一部分,最后组装起来,返回我们需要的对象. 下面的例子主要讲解构造一个飞船 Demo: //要获得的 ...
- select设置text的值选中(兼容ios和Android)基于jquery
前一段时间改了一个bug,是因为select引起的.当时我没有仔细看,只是把bug改完了就完事了,今天来总结一下. 首先说option中我们通常会设置value的属性的,还有就是text值的,请参见下 ...
- Ajax的面试题
一.什么事Ajax?为什么要用Ajax?(谈谈对Ajax的认识) 什么是Ajax: Ajax是“Asynchronous JavaScript and XML”的缩写.他是指一种创建交互式网页应用的网 ...
- [代码笔记]JS保持函数单一职责,灵活组合
比如下面的代码,从服务端请求回来的订单数据如下,需要进行以下处理1.根据 status 进行对应值得显示(0-进行中,1-已完成,2-订单异常)2.把 startTime 由时间戳显示成 yyyy-m ...
- 超简单的canvas绘制地图
本文使用geojson数据,通过缩放和平移把地图的地理坐标系转换canvas的屏幕坐标系,然后将转换后的数据绘制到canvas上. 首先要计算数据的最大最小值,遍历所有坐标点的最大最小 ...
- Android为TV端助力:自定义view之太阳
先看效果图 package com.hhzt.iptv.lvb_w8.view; import android.content.Context;import android.graphics.Canv ...
- ext前后台数据传输的标准化
一.标准化的数据传输是什么 这里所说的标准化主要是指,使用代理提交数据时,格式必须统一化.标准化,而服务器返回的数据格式也必须是标准化的数据. 简言之,使用代理提交数据时,前台--->后台,后台 ...